1.必要な知識
相関ルール
相関ルールは、x-> yという形式の含意表現です。ここで、xとyは互いに素なアイテムセットです。X∩Y=∅
アイテムセット
0個以上のアイテムを保持するコレクションアイテムセットの数がkの場合、kアイテムセットと呼ばれます。
例:{egg、fruit、cake}は、3アイテムセットの空のセットです。
相関ルールの強さ
通常、サポートと信頼度によって測定されます
応援
| 取引注文 | 商品 |
|---|---|
| 0 | 卵乳コーラおむつ |
| 1 | ビール卵コーラ |
| 2 | 牛乳の卵 |
上記のリストで
は、卵のサポートは3/3、
牛乳は2/3、
おむつ1/3
コークス2/3
(卵、おむつ)は0
(卵コーラ)は1/3です
。つまり、アイテムセットのサポートは、すべてのアイテムに表示頻度
信頼性(信頼)
信頼性と数学的統計 条件付き確率同様に
、後で信頼Yが同時にはx購入
信頼(X-> Y)= P (Y / X)= P(X、Y)/ P(x)は= も購入Xは、Y / X買う
> -コーラを卵への信頼性
支援の(卵、コーラ) -も卵にコーラ= 1/3を購入
コークスの三分の二を購入する-のコークスのサポート
で割った-結果は1/2である
。同様の卵- >コークス
2 / 3
リフト(未使用)
リフト(x-> y)= P(x、y)/(P(x)* P(y)= P(y / x)/ P(y)購入
方法
xと購入方法yを参照する計算方法には多くの種類がありますリフティング効果はありますか、値が1より大きい場合、1は関連性がなく、1未満の負の相関関係がある場合に
役立ちます。コーラ->卵、昇進の程度は
1/3 /(2/3 * 1)= 2コークを購入すると、卵の購入にリフティング効果があります
プロジェクト
トランザクションデータベースのフィールド、
つまり、さまざまな商品はアイテム、卵はアイテム、牛乳はアイテムです
事業
1回のトランザクションのすべてのアイテムのコレクション、
つまり、1人が1度に購入するすべてのアイテム{eggs、milk}はトランザクションです。彼は通行人Aに代わってすべてを購入します
頻繁なアイテムセット
サポートが最小サポートよりも大きいすべてのアイテムセットが呼び出されます頻繁なアイテムセット、周波数セットと呼ばれます(最低限のサポートはユーザーが指定します)
最大頻度アイテムセット他の要素に含まれていない頻繁なアイテムセットです
アイテムセットの関連定理
定理(Apriori属性1)。
アイテムセットXが頻出アイテムセットの場合、空でないすべてのサブセットは頻出アイテムセット
定理(Apriori属性2)です。
アイテムセットXが非頻出アイテムセットの場合、そのすべてのスーパーセットどちらも頻度の低いアイテムセットです。
証明はシンプルで理解しやすく、定義から理解するだけです。
相関ルールマイニングの問題
相関ルールマイニングの問題は、2つのサブ問題に分けることができます。
- 頻出アイテムセットの検索:Minsupportを指定したユーザーを通じて、すべての頻出アイテムセットまたは最大頻出アイテムセットを見つけます。
- アソシエーションルールの生成:Minconfidenceを指定したユーザーを通じて、頻繁なプロジェクトセットでアソシエーションルールを見つけます。
強い相関ルール
DがIの最小サポート度と最小信頼度(Minconfidence)を満たす相関ルールは、強い相関ルール(Strong Association Rule)と呼ばれます。
つまり、最低限のサポートと最低限の信頼度に従ってルールを見つける必要があります。
2.例
1.最も頻度の高いアイテムセットを見つける
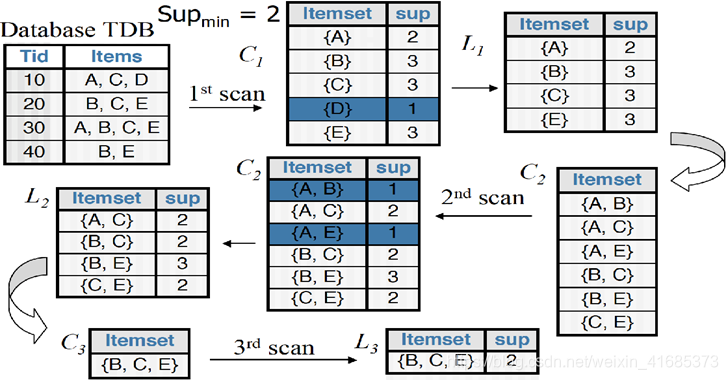
データベースがスキャンされるたびに、1つのアイテムセットから始めて、ユーザーが指定した最小サポート(ここでは2)を満たさないアイテムを除外します。サポート度は0.5で、2つのペアを組み合わせてi + 1アイテムセットを生成し、最後が一意になるまで除外します。最大の頻度の高いアイテムセット{B、C、E}が見つかりました他の3つのアイテムセットは最小サポートを満たしていません。この数字はマークされていません。C3に{A、B、C}、{A、C、Eがあります}、{A、B、E}は1/4のみをサポート
2.強い相関ルールを生成する
最小の信頼性を80%として0.8より大きいとすると、信頼できる
| 最大頻度アイテムセット(サポート) | サブセット(サポート) | 信頼性 | ルール | 強い関係かどうか |
|---|---|---|---|---|
| B、C、E(50%) | B、C(50%) | 100% | BC-> E | はい |
| B、C、E(50%) | B、E(75%) | 67% | BE-> C | いいえ |
| B、C、E(50%) | C、E(50%) | 100% | CE-> B | はい |
| B、C、E(50%) | B(75%) | 67% | B-> CE | いいえ |
| B、C、E(50%) | C(75%) | 67% | C-> BE | いいえ |
| B、C、E(50%) | E(75%) | 67% | E-> BC | いいえ |
このようにして、強い相関ルールBC-> EおよびCE-> Bが見つかります。
3.アルゴリズム
Pythonアルゴリズム、書き込みも他の人によってコピーされます。見栄えをよくするために辞書式順序を追加しました
コメントは自分で書いた
def load_data_set():
'''
给出数据库事务集
:return: data
'''
data_set = [
['A' ,'C' ,'D'],
['B' ,'C' ,'E'],
['A' ,'B' ,'C' ,'E'],
['B' ,'E']
]
data =[
['a','c','d','e','f'],
['b','c','f'],
['a','d','f'],
['a','c','d','e'],
['a','b','d','e','f']
]
return data_set
def Create_C1(data_set):
'''
生成候选1项集
'''
C1 = set()
for t in data_set: # 每一个事务
for item in t: #每一个商品
item_set = frozenset([item]) # { 'a' } 的形式,
# 用frozenset 是因为键值对的键要满足不可变 不然就破坏了键的唯一性和确定性
# 为生成频繁项目集时扫描数据库时以提供issubset()功能.
C1.add(item_set)
return C1 # 类似[ {'a'} ,{'b'}]
def is_apriori(Ck_item, Lk_sub_1):
'''
参数:候选频繁k项集,频繁k-1项集 原理是只要含有不频繁项集的项集就是不频繁的 用于剪枝
'''
for item in Ck_item: # 校验候选k项集中是否每一项的真子集是频繁k-1项集
sub_item = Ck_item - frozenset([item])
if sub_item not in Lk_sub_1:
return False
return True
def Create_Ck(Lk_sub_1, k):
'''
# 参数:频繁k-1项集,当前要生成的候选频繁几项集 切k>2
'''
Ck = set()
len_Lk_sub_1 = len(Lk_sub_1)
list_Lk_sub_1 = list(Lk_sub_1)
for i in range(0,len_Lk_sub_1): #遍历每一项 索引是i
for j in range(i + 1, len_Lk_sub_1): # 遍历接下来的每一项 索引是j 相当于两两组合 (自连接)
l1 = list(list_Lk_sub_1[i])
l2 = list(list_Lk_sub_1[j])
# 排序便于比较 顺序是字典序
l1.sort()
l2.sort()
# 判断l1的前k-1-1个元素与l2的前k-1-1个元素对应位是否全部相同
# 因为我们要产生的是 候选频繁k项集,所以对于频繁k-1项集 只需要k-2项相等,1项不相等连接才能产生
if l1[0:k - 2] == l2[0:k - 2]:
Ck_item = list_Lk_sub_1[i] | list_Lk_sub_1[j] # 求集合的并 相当于生成候选频繁k项集了
if is_apriori(Ck_item, Lk_sub_1): # 剪枝
Ck.add(Ck_item)
return Ck
def Generate_Lk_By_Ck(data_set, Ck, min_support, support_data):
'''
参数:数据库事务集,候选频繁k项集,最小支持度,项目集-支持度dic
'''
Lk = set()
# 通过dic记录候选频繁k项集的事务支持个数
item_count = {}
for t in data_set:
for Ck_item in Ck:
if Ck_item.issubset(t): # 候选频繁k项集中每一项 对事务集开始 统计支持度
if Ck_item not in item_count:
item_count[Ck_item] = 1
else:
item_count[Ck_item] += 1
data_num = float(len(data_set))
for item in item_count:
if (item_count[item] / data_num) >= min_support: # 满足最小支持度加入频繁k项集,把支持度也加入支持度字典中
Lk.add(item)
support_data[item] = item_count[item] / data_num
return Lk
def Generate_L(data_set, max_k, min_support): #求最大频繁项集 和所有的频繁项集
'''
参数:数据库事务集,求的最高项目集为k项,最小支持度
'''
# 创建一个频繁项目集为key,其支持度为value的dic
support_data = {}
C1 = Create_C1(data_set)
L1 = Generate_Lk_By_Ck(data_set, C1, min_support, support_data)
Lk_sub_1 = L1.copy() # 对L1进行浅copy
L = []
L.append(Lk_sub_1) # 末尾添加指定元素
for k in range(2, max_k + 1): # 结尾不包括 所以加1
Ck = Create_Ck(Lk_sub_1, k)
Lk = Generate_Lk_By_Ck(data_set, Ck, min_support, support_data)
Lk_sub_1 = Lk.copy()
L.append(Lk_sub_1)
return L, support_data
def Generate_Rule(L, support_data, min_confidence):
'''
参数:所有的频繁项目集,项目集-支持度dic,最小置信度
'''
rule_list = []
sub_set_list = []
for i in range(len(L)):
for frequent_set in L[i]: # 每一个频繁k项集
for sub_set in sub_set_list: # 每一个频繁k项的子集
if sub_set.issubset(frequent_set): #必须是频繁项集的子集
conf = support_data[frequent_set] / support_data[sub_set] #可信度
# 强关联规则格式为 子集 频繁项集 可信度
rule = (sub_set, frequent_set - sub_set, conf)
if conf >= min_confidence and rule not in rule_list: # 去重 并添加规则
rule_list.append(rule)
sub_set_list.append(frequent_set)
return rule_list
if __name__ == "__main__":
data_set = load_data_set()
'''
print("Test")
# 数据库事务打印
for t in data_set:
print(t)
'''
'''
print("Test")
# 候选频繁1项集打印
C1 = Create_C1(data_set)
for item in C1:
print(item)
'''
'''
# 频繁1项集打印
print("Test")
L = Generate_L(data_set, 1, 0.2)
for item in L:
print(item)
'''
'''
# 频繁k项集打印
print("Test")
L, support_data = Generate_L(data_set, 2, 0.2)
for item in L:
print(item)
'''
'''
# 关联规则测试
print("Test")
L, support_data = Generate_L(data_set, 3, 0.2)
rule_list = Generate_Rule(L, support_data, 0.7)
for item in support_data:
print(item, ": ", support_data[item])
print("-----------------------")
for item in rule_list:
print(item[0], "=>", item[1], "'s conf:", item[2])
'''
# 最大频繁项集的项数 k 最小支持度 最小可信度
maxK=3
minsupport=0.5
minconfidence=0.8
L, support_data = Generate_L(data_set, maxK, minsupport)
rule_list = Generate_Rule(L, support_data, minconfidence)
print()
print()
print("最小支持度:"+str(minsupport)+"\t最小置信度:"+str(minsupport)+"\t最大频繁项的项数:"+str(maxK))
for Lk in L:
print("=" * 40)
print("frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport")
#print("=" * 40)
for frequent_set in Lk:
s="{}\t\t\t{}"
a=list(frequent_set)
a.sort() # 排序字典序
print(s.format(a, support_data[frequent_set]))
print()
print("Rules\t\t\t\t最小置信度"+str(minsupport))
for item in rule_list:
a=list(item[0])
a.sort()
print(a, "=>", list(item[1]), "'s conf: ", item[2])
図のように実行中の図

