Adresse de l'article : Réseaux prototypiques gaussiens pour un apprentissage en quelques étapes sur Omniglot
Annuaire d'articles
Résumé
Nous proposons une nouvelle architecture pour la classification K-shot de l'ensemble de données Omniglot. Sur la base du réseau prototype, nous étendons son architecture que nous appelons réseau prototype gaussien. Le réseau prototype apprend le mappage entre les images et les vecteurs d'intégration et utilise leur regroupement pour la classification. Dans notre modèle, une partie de la sortie du codeur est interprétée comme une estimation de la région de confiance par rapport au point d'intégration et est exprimée sous la forme d'une matrice de covariance gaussienne. Notre réseau construit ensuite une métrique de distance dépendante de l'orientation et de la catégorie sur l'espace d'intégration, en utilisant l'incertitude des points de données individuels comme poids. Nous montrons que le réseau prototype gaussien est une architecture supérieure au réseau prototype vanille avec le même nombre de paramètres. Nous rapportons des performances de pointe sur l'ensemble de données Omniglot pour la classification à 1 coup et à 5 coups dans des régimes à 5 et 20 voies (pour 5 coups à 5 voies, nous sommes à égalité avec l'état de l'art précédent). L'art). Nous explorons le sous-échantillonnage artificiel d'un sous-ensemble d'images dans l'ensemble de formation pour améliorer encore nos performances. Par conséquent, nous émettons l’hypothèse que les réseaux prototypes gaussiens pourraient mieux fonctionner dans des ensembles de données moins uniformes et plus bruyants, ce qui est courant dans les applications du monde réel.
1. Introduction
1.1 Apprentissage en quelques coups
Les humains peuvent apprendre à reconnaître de nouvelles catégories d’objets dans un seul ou un petit nombre d’exemples. Cela a été démontré dans un large éventail d'activités, de la reconnaissance de caractères manuscrits [1] au contrôle de mouvement [2], en passant par l'acquisition de concepts de haut niveau [3]. La reproduction de ce comportement dans les machines est la motivation pour étudier l’apprentissage en petits nombres.
L'apprentissage profond paramétrique fonctionne bien dans les environnements contenant de grandes quantités de données. En général, les modèles d’apprentissage profond ont une expressivité et des capacités fonctionnelles très élevées et reposent sur une formation lente et itérative sous un régime supervisé. Par conséquent, l’impact d’un exemple particulier dans l’ensemble de formation est minime car le but de la formation est de capturer la structure générale de l’ensemble de données. Cela empêche l'introduction rapide de nouvelles catégories après la formation. [4]
En revanche, l’apprentissage en quelques étapes nécessite une adaptation très rapide aux nouvelles données. En particulier, la classification k-shot fait référence à un régime selon lequel les cours non vus pendant la formation doivent être appris à l'aide de k exemples étiquetés. Les modèles non paramétriques tels que le k-plus proche voisin (kNN) ne sont pas surajustés, cependant, leurs performances dépendent fortement du choix de la métrique de distance. [5] combine l'architecture de modèles paramétriques et non paramétriques, ainsi que la correspondance des conditions d'entraînement et de test, et a récemment obtenu de bons résultats en matière de classification k-shot.
1.2 Réseau prototype gaussien
Dans cet article, nous développons une nouvelle architecture basée sur le réseau prototype utilisé dans [6] et la formons et la testons sur l'ensemble de données Omniglot [3]. Le réseau prototype Vanilla mappe les images en vecteurs d'intégration et utilise leur regroupement pour la classification. Ils ont divisé un lot d'images en images de support et de requête et ont utilisé les vecteurs d'intégration de l'ensemble de supports pour définir un prototype de classe – un vecteur d'intégration typique pour une classe donnée. La proximité de ceux-ci est ensuite utilisée pour classer.
Notre modèle, que nous appelons réseau prototype gaussien, mappe une image dans un vecteur d'intégration et une estimation de la qualité de l'image. Avec le vecteur d'intégration, une région de confiance autour de celui-ci est prédite, caractérisée par une matrice de covariance gaussienne. Le réseau prototype gaussien apprend à construire une métrique de distance dépendante de la direction et de la catégorie sur l'espace d'intégration. Nous montrons que notre modèle est le moyen privilégié pour utiliser des paramètres supplémentaires pouvant être entraînés par rapport aux réseaux prototypes vanille.
Notre objectif est de montrer qu'en permettant à notre modèle d'exprimer sa confiance sur un seul point de données, nous obtenons de meilleurs résultats. Nous avons également expérimenté la destruction délibérée de parties de l'ensemble de données pour explorer l'évolutivité de notre approche sur des ensembles de données du monde réel bruyants et non uniformes, où la pondération des points de données individuels peut être critique pour les performances.
Au meilleur de nos connaissances, sur l'ensemble de données Omniglot, nous rapportons des performances de pointe pour la classification à 1 coup et à 5 coups dans des régimes à 5 et 20 voies (pour 5 coups à 5 voies, nous comparer favorablement avec le précédent équivalent de performances avancées de pointe). [3] En étudiant la réponse de notre modèle aux données sous-échantillonnées, nous émettons l’hypothèse que son avantage pourrait être plus important dans des ensembles de données inégaux et de mauvaise qualité.
Cet article est structuré comme suit. Nous décrivons les travaux connexes dans la section 2. Ensuite, nous présentons notre méthode dans la section 3. Un programme d'entraînement épisodique est également présenté ici. Nous discutons de l'ensemble de données Omniglot dans la section 4 et de nos expériences dans la section 5. Enfin, nos conclusions sont présentées dans la section 6.
2 Travaux connexes
Les modèles non paramétriques, tels que les k-plus proches voisins (kNN), sont des candidats idéaux pour les classificateurs en petit nombre car ils permettent l'inclusion de classes inédites. Cependant, ils sont très sensibles au choix de la métrique de distance. [5] L'utilisation directe des distances dans l'espace d'entrée (telles que les valeurs brutes des pixels) ne donne pas une grande précision car la connexion entre une classe d'image et ses pixels est très non linéaire.
Comme démontré dans [7], [8], [9] et [10], une modification simple, c'est-à-dire l'apprentissage d'un plongement métrique qui est ensuite utilisé pour la classification kNN, donne de bons résultats. Dans [11] une méthode utilisant un réseau de correspondance est proposée, qui apprend essentiellement une métrique de distance entre des paires d'images. Une caractéristique remarquable de cette approche est son schéma de formation, dans lequel chaque mini-lot (appelé épisode) tente d'imiter des tests pauvres en données en sous-échantillonnant le nombre de classes et le nombre d'exemples dans chaque condition. Il a été démontré que de telles méthodes peuvent améliorer les performances de la classification des petits nombres. [11] Par conséquent, nous adoptons également cette approche.
Il a été récemment proposé [12] qu'au lieu d'apprendre directement sur l'ensemble de données, on entraîne un LSTM [13] pour prédire les mises à jour d'un classificateur probabiliste étant donné un épisode en entrée. Cette approche est appelée méta-apprentissage. Comme le montrent [14] et [15], le méta-apprentissage a atteint une grande précision sur Omniglot [3]. Un méta-apprenant de diagnostic de tâches basé sur la convolution temporelle est proposé dans [16]. La combinaison de méthodes paramétriques et non paramétriques a récemment été la plus réussie dans l'apprentissage de petits nombres. [6][17][18]
Notre méthode est spécifiquement ciblée sur la classification d'images et ne tente pas de résoudre ce problème par le méta-apprentissage. Nous nous appuyons sur le modèle proposé dans [6], qui mappe les images en vecteurs d'intégration et utilise leur regroupement pour la classification. Une nouvelle caractéristique de notre modèle est qu'il prédit sa confiance pour des points de données individuels via une matrice de covariance apprise et dépendante de l'image. Cela lui permet de créer un espace d'intégration plus riche dans lequel les images peuvent être projetées. Ensuite, leur regroupement sous une métrique de distance liée à la direction et à la classe est utilisé pour la classification.
3 méthodes
Dans cet article, nous explorons d'abord le réseau prototype décrit dans [6]. Nous étendons cette architecture à ce que nous appelons les réseaux prototypes gaussiens, permettant aux modèles de refléter la qualité des points de données individuels (images) en prédisant leurs vecteurs d'incorporation ainsi que les régions de confiance qui les entourent, caractérisées par une matrice de covariance gaussienne.
Un prototype de réseau fictif consiste en un encodeur qui mappe une image dans un vecteur d'intégration. Un lot contient un sous-ensemble des cours de formation disponibles. A chaque itération, les images de chaque catégorie sont divisées aléatoirement en images supports et images requêtes. Les intégrations basées sur des images sont utilisées pour définir des prototypes de classe – des vecteurs d'intégration typiques pour cette classe. La proximité de l'intégration de l'image de requête au prototype de classe est utilisée pour la classification.
Il n'y a aucune différence dans l'architecture d'encodeur du réseau prototype vanille et du réseau prototype gaussien. Les principales différences résident dans la manière dont la sortie de l'encodeur est interprétée et utilisée, et dans la façon dont la métrique de l'espace d'intégration est construite. Dans les réseaux gaussiens, une partie de la sortie du codeur est utilisée pour construire une matrice de covariance par rapport aux vecteurs d'intégration, ce qui permet à notre modèle de refléter le pouvoir prédictif ainsi que la qualité des points de données individuels.
3.1 Encodeur
Nous codons les images dans des vecteurs euclidiens de grande dimension en utilisant un réseau neuronal convolutif multicouche sans couche finale explicite entièrement connectée. Pour le prototype de réseau du Néant décrit dans [6], l'encodeur est une fonction qui prend une image I et la convertit en un vecteur ~x, c'est-à-dire où H et W sont la hauteur et la largeur de
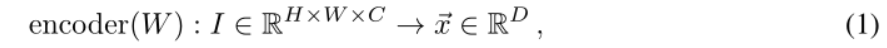
l'image d'entrée et C est son canal. quantité. D est la dimension d'intégration de notre espace vectoriel et est un hyperparamètre du modèle. W sont les poids entraînables de l'encodeur.
Pour un réseau prototype gaussien, la sortie du codeur est la concaténation du vecteur d'incorporation ~ x∈R D et des composantes pertinentes de la matrice de covariance Σ∈R D×D .
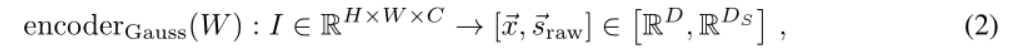
Où D S est donc la dimension de la composante de prédiction de la matrice de covariance.
Nous explorons trois variantes de réseaux prototypes gaussiens.
- Estimations de la covariance du rayon . D S =1, chaque image génère un seul nombre réel s brut ∈ R 1 pour décrire la taille de l'intervalle de confiance autour de son vecteur de plongement. Par conséquent, la matrice de covariance est de la forme Σ=diag(σ,σ,…,σ), où σ est calculé à partir de la sortie s brute du codeur d'origine . Par conséquent, les estimations de confiance ne sont pas directionnelles. Sur l'ensemble de données Omniglot, cette approche s'est avérée être l'utilisation la plus efficace de paramètres supplémentaires [3]. Nous pensons que cette préférence peut être spécifique à un ensemble de données, les ensembles de données moins homogènes préférant probablement des estimations de covariance plus complexes.
- Estimations de covariance diagonale . D S = D, les dimensions de l'estimation de covariance sont les mêmes que les dimensions de l'espace d'intégration. → sraw∈R D est généré sur chaque image pour décrire la taille de l'intervalle de confiance autour du vecteur d'intégration. Par conséquent, la matrice de covariance est de la forme Σ = diag ( → σ), où → σ est calculé à partir de la sortie originale du codeur → sraw. Cela permet au réseau d'exprimer la confiance directionnelle dans les points de données, bien que l'ellipsoïde de confiance reste toujours aligné sur les axes de l'espace d'intégration.
- Estimation complète de la covariance . Une matrice de covariance complète est générée pour chaque point de données. Cette approche s’est avérée inutilement complexe pour la tâche donnée et n’a pas été explorée davantage.
Nous utilisons des images Omniglot en niveaux de gris sous-échantillonnées de dimension 28 × 28 × 1 en entrée. Une architecture CNN à 4 couches avec un ensemble maximal 2 × 2 donne un volume de forme 1 × 1 × (D + D S ), où la dimension d'intégration D plus la partie pertinente de la matrice de covariance D est égale à la quantité de filtre finale. Nous utilisons le rembourrage SAME et la foulée 1 de TensorFlow. Notre filtre a une étendue spatiale de 3 × 3. La dernière couche équivaut à une couche entièrement connectée.
Nous utilisons une architecture à 2 encodeurs. 1) une petite architecture, et 2) une grande architecture. La petite architecture correspond à celle utilisée dans [6], que nous utilisons pour valider nos propres expériences par rapport aux résultats de l'état de l'art antérieurs. De grandes architectures ont été utilisées pour observer l'impact de l'augmentation de la capacité du modèle sur la précision. Comme élément de base, nous utilisons la séquence de couches dans l’équation 3.
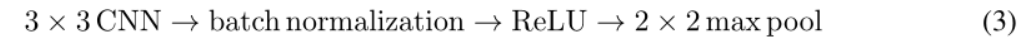
Les deux architectures sont composées de 4 blocs de ce type empilés ensemble. Les détails de l'architecture sont les suivants.
- Petite structure . Filtre 3×3, le nombre de filtres est [64, 64, 64, D] ([64, 64, 64, D+1] est le modèle gaussien du rayon, [64, 64, 64, 2D] est le modèle gaussien diagonal modèle ). Les dimensions de l'espace d'intégration exploré sont D=32, 64 et 128.
- Grande structure . Filtre 3 × 3, le nombre de filtres est [128, 256, 512, D] (le modèle gaussien du rayon est [128, 256, 512, D+1], le modèle gaussien diagonal est [128, 256, 512, 2D]) . Les dimensions de l'espace d'encastrement exploré sont D=128, 256, 512.
Nous avons exploré 4 méthodes différentes pour convertir la sortie brute de la matrice de covariance de l'encodeur en une matrice de covariance réelle. Puisque nous avons principalement affaire à la valeur inverse de la matrice de covariance S=Σ-1, nous la prédisons directement. Soit S raw la partie pertinente de la sortie brute du codeur . Méthodes comme ci-dessous.
- S = 1 + softplus(S raw ), où softplus(x) = log (1 + e x ), qui est appliqué par composant. Puisque softplus(x)>0, cela garantit S>1, l'encodeur ne peut que rendre les points de données moins importants. La valeur de S n’est pas non plus soumise aux restrictions ci-dessus. Les deux méthodes se sont révélées bénéfiques pour la formation. Nos meilleurs modèles utilisent ce régime pour la formation initiale.
- S = 1 + sigmoïde (S raw ), où sigmoïde(x) = 1/ (1 + e -x ), qui est appliqué par composant. Puisque sigmoid(x)>0, qui garantit S>1, l'encodeur ne peut que rendre les points de données moins importants. La valeur de S est délimitée par le haut car S <2, donc l'encodeur est plus contraint.
- S = 1 + 4 sigmoïde (S brut ), donc 1 < S < 5. Nous utilisons cela pour explorer l'impact de la taille du domaine d'estimation de covariance sur les performances.
- S = offset + scale × softplus (S raw /div), où offset, scale et div sont initialisés à 1,0 et peuvent être entraînés. Nos meilleurs modèles utilisent ce régime en post-formation car il est plus flexible et basé sur les données que la première approche.
3.2 Formation occasionnelle
Un élément clé du modèle prototype est le régime d'entraînement épisodique décrit dans [6]. Au cours du processus de formation, un sous-ensemble de Nc classes est sélectionné parmi le nombre total de classes dans l'ensemble de formation (sans remplacement). Pour chacune de ces classes, Ns instances de support et Nq instances de requête sont sélectionnées aléatoirement. Les exemples d'incorporation de codage pris en charge sont utilisés pour définir la position d'un prototype de classe spécifique dans l'espace d'incorporation. La distance entre l'instance de requête et la position du prototype de classe est utilisée pour classer l'instance de requête et calculer la perte. Pour les réseaux prototypes gaussiens, la covariance de chaque point d'intégration est également estimée. Un diagramme schématique de ce processus est présenté à la figure 1.
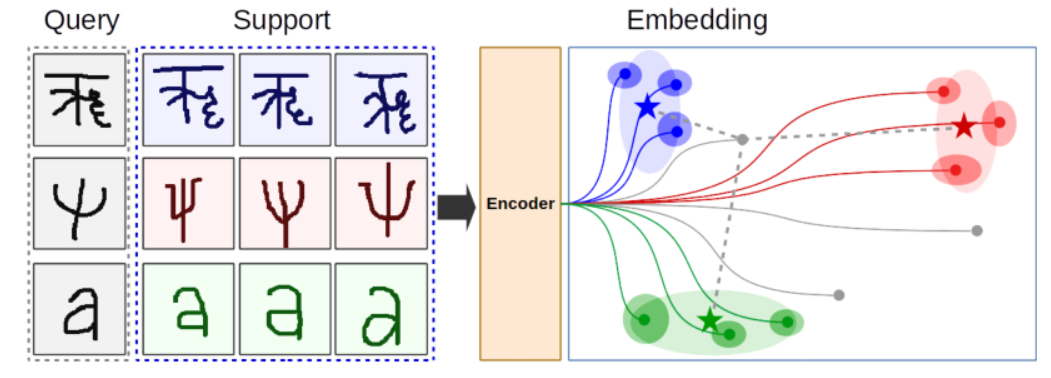
Figure 1 : Schéma fonctionnel du réseau prototype gaussien. L'encodeur mappe l'image sur un vecteur dans l'espace d'intégration (cercles sombres). Chaque image génère également une matrice de covariance (ellipse sombre). Les images de support sont utilisées pour définir des prototypes spécifiques à une classe (étoiles) et des matrices de covariance (ovales de couleur claire). La distance entre le point central et l'image de requête codée, corrigée par la covariance totale d'une classe, est utilisée pour classer l'image de requête. Les distances sont affichées sous forme de lignes pointillées grises jusqu'à des points de requête spécifiques.
Pour les réseaux prototypes gaussiens, le rayon ou la diagonale de la matrice de covariance est généré avec le vecteur d'intégration (plus précisément, dans sa forme originale, voir la section 3.1 pour plus de détails). Ceux-ci sont ensuite utilisés pour pondérer les vecteurs d'intégration correspondant aux points de support d'une classe particulière et pour calculer la matrice de covariance globale pour cette classe. Ensuite, la distance d c (i) d'un prototype c d'une classe à un point de requête i est calculée comme suit :
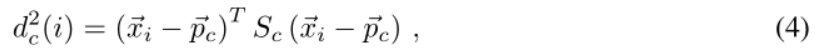
où → p c est le point central, ou prototype, de la classe c, et S c = Σ -1 c est son matrice de covariance inverse. Par conséquent, le réseau prototype gaussien est capable d’apprendre des mesures de distance dépendantes de la classe et de l’orientation dans l’espace d’intégration. Nous avons constaté que la vitesse de l’entraînement et sa précision dépendent fortement de la manière dont la distance est utilisée pour construire la perte. Nous concluons que la meilleure option est d’utiliser la distance euclidienne linéaire, c’est-à-dire d c (i). La forme spécifique de la fonction de perte utilisée est présentée dans l'algorithme 1. La figure 2 montre le diagramme d'espace d'intégration du réseau prototype gaussien. Les figures 10 et 11 en annexe montrent un échantillon de l'espace d'intégration pendant la formation. Il illustre le regroupement de caractères similaires pour la classification.
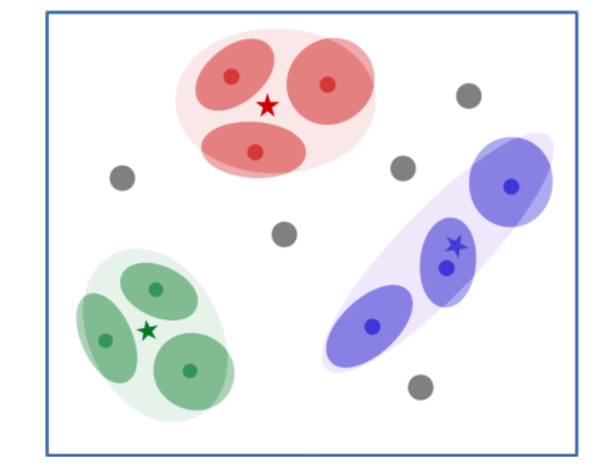
Figure 2 : Schéma montrant l'espace d'intégration d'un réseau prototype gaussien. Une image est mappée par l'encodeur sur ses vecteurs d'intégration (points sombres). Sa matrice de covariance (ellipse sombre) est également sortie par l'encodeur. Ensuite, la matrice de covariance globale de chaque classe est calculée (la grande ellipse de couleur claire), ainsi que le prototype de la classe (les étoiles). Une matrice de covariance de classe est utilisée pour modifier localement la métrique de distance du point de requête (affichée en gris).
Nous étudions le cadre où la matrice de covariance est diagonale, comme résumé dans la section 3.1. Pour le cas du rayon, S = sI, où I est la matrice d'identité et s∈R1 est calculé à partir de la sortie brute du codeur pour chaque image. Pour le cas diagonal, S = diag ( → s), où → s est également calculé à partir de la sortie brute de l'encodeur pour chaque image.
3.3 Définir une classe
Un élément clé d'un réseau de prototypes est la création d'un prototype de catégorie à partir des points de support disponibles pour une catégorie spécifique. Nous proposons comme solution une combinaison linéaire pondérée par la variance des vecteurs d'intégration des instances de support individuelles. Soit la classe c avoir des images de support I i , qui sont codées sous forme de vecteurs d'intégration → x c i , et l'inverse de la matrice de covariance S c i , dont la diagonale est → s c i . Le prototype, c'est-à-dire le point central de la classe, est défini comme

où ◦ représente la multiplication par composants et la division est également par composant. Ensuite, la diagonale de la matrice de quasi-covariance est calculée comme suit.

Cela équivaut à optimiser les gaussiennes centrées en chaque point en une quasi-gaussienne globale, d'où le nom du réseau : Gaussien. Les éléments de s sont en réalité 1/σ 2 . Par conséquent, les équations 5 et 6 correspondent à une pondération des exemples par 1/ σ2 . Cela permet au réseau de réduire la pondération des exemples qui sont moins importants pour définir une classe, rendant ainsi notre architecture plus adaptée aux ensembles de données bruyants, inégaux ou imparfaits.
Pour un régime ponctuel, c'est-à-dire la manière dont notre réseau est formé, il existe un seul vecteur d'étiquette → x c définissant chaque catégorie. Cela signifie que le vecteur lui-même devient le prototype de la classe et que sa matrice de covariance est héritée par la classe. La covariance joue alors un rôle dans la modification de la distance au point de requête. L'algorithme complet est décrit dans l'algorithme 1.

3.4 Modèle d'évaluation
Pour estimer la précision du modèle sur l'ensemble de test, nous classons l'ensemble de test avec le numéro Ns = k de chaque point d'appui dans la plage k∈[1,…19]. Par conséquent, le nombre de points de requête pour un k spécifique est Nq = 20 - Ns, puisqu'Omniglot fournit 20 exemples pour chaque catégorie. La précision a ensuite été regroupée et la précision de la classification k-shot en fonction de k a été déterminée pour une étape spécifique de la formation du modèle. Comme nous n'avons pas utilisé d'ensemble de validation spécifié, nous avons garanti notre impartialité en considérant les 5 résultats de tests avec la plus grande précision d'entraînement et en calculant leur moyenne et leur écart type. En faisant cela, nous empêchons les résultats d'optimisation sur l'ensemble de test et obtenons en outre une erreur liée à la précision résultante. Nous évaluons notre modèle selon des classifications de tests à 5 et 20 voies pour le comparer directement avec la littérature existante.
4 ensembles de données
Nous avons utilisé le jeu de données Omniglot. [3] Omniglot contient 1623 classes de caractères provenant de 50 alphabets (réels et fictifs) et 20 exemples manuscrits en niveaux de gris de 105 × 105 pixels de chaque classe de caractères. Nous les sous-échantillonnons à 28 × 28 × 1, soustrayons leur moyenne et les inversons. Nous avons utilisé la méthode de segmentation recommandée de 30 lettres de formation et 20 lettres de test, suggérée par [3] et utilisée par [6]. L’ensemble de formation comprend 964 classes de personnages uniques, tandis que l’ensemble de test en comprend 659. Il n'y a pas de chevauchement de catégories entre les ensembles de données de formation et de test. Nous n'avons pas utilisé d'ensemble de validation distinct car nous n'avons pas affiné les hyperparamètres et avons uniquement sélectionné le modèle le plus performant en fonction de la précision de l'entraînement (voir section 3.4).
Pour augmenter le nombre de classes, nous augmentons l'ensemble de données en faisant pivoter chaque caractère de 90 ◦ , 180 ◦ et 270 ◦ et définissons chaque rotation comme une nouvelle classe de caractères elle-même. La même approche est également utilisée dans [11] et [6]. Un exemple de caractères améliorés est présenté à la figure 3. Cela augmente le nombre de classes de 4 fois. Par conséquent, l’ensemble de formation comprend un total de 77 120 images et l’ensemble de test comprend 52 720 images. En raison de l'amélioration de la rotation, les caractères présentant une symétrie de rotation sont toujours définis en plusieurs catégories. Étant donné que même un classificateur parfait hypothétique ne peut pas faire la distinction entre des caractères tels que « O » et un « O » pivoté, une précision de 100 % ne peut pas être atteinte.

Figure 3 : Un exemple d'augmentation du nombre de classes par rotation. Un caractère original (à gauche) subit une rotation de 90◦, 180◦ et 270◦. Chaque rotation est définie comme une nouvelle classe. Cela augmente le nombre de classes mais introduit également une dégénérescence pour les caractères symétriques.
Afin d'améliorer la formation et de tirer parti de la capacité des réseaux gaussiens à prédire les covariances des caractères, nous avons délibérément sous-échantillonné certaines parties de l'ensemble de formation dans certaines expériences. Voir la section 5 pour plus de détails. Nos résultats montrent que l'ensemble de données Omniglot est trop simple pour exploiter pleinement la capacité des réseaux gaussiens à estimer des matrices de covariance. Nous émettons l’hypothèse que notre méthode présentera de plus grands avantages sur des ensembles de données hétérogènes où la qualité des points de données individuels varie, ce qui est une situation courante dans les applications du monde réel.
5 expériences
Nous menons plusieurs expériences d'apprentissage approfondies sur l'ensemble de données Omniglot. Pour le réseau prototype gaussien, nous avons exploré différentes dimensions spatiales d'intégration, façons de générer des matrices de covariance et capacités d'encodeur (voir la section 3.1 pour plus de détails). Nous les avons également comparés aux réseaux prototypes vanille et les résultats montrent que notre variante gaussienne est avantageuse, d'autant plus que le moyen le plus efficace d'utiliser des paramètres supplémentaires est de prédire un nombre unique pour chaque point d'intégration (méthode du rayon dans la section 3.1). En général, nous explorons les tailles d'encodeurs (petits et grands, comme décrit dans la section 3), les comparaisons avec les réseaux prototypes gaussiens/vanille, les métriques de distance (cosinus, √L 2 , L 2 et L 2 2 ) , le nombre de degrés . de liberté de la matrice de covariance dans le réseau gaussien (rayons et estimations diagonales, voir section 3.1) et les dimensions de l'espace d'intégration. Nous avons également envisagé d'encourager le réseau à utiliser l'estimation de covariance en sous-échantillonnant un sous-ensemble de l'ensemble de données d'entrée et avons constaté que cela améliorait les performances de (k > 1) fois.
Nous utilisons l'optimiseur Adam avec un taux d'apprentissage initial de 2×10 -3 . Nous réduisons de moitié le taux d'apprentissage tous les 2000 événements ≈ 30 époques. Tous nos modèles sont implémentés dans TensorFlow et fonctionnent sur un seul GPU NVidia K80 dans Google Cloud. Chaque modèle prend moins d’une journée à s’entraîner.
Nous avons entraîné notre modèle avec Nc=60 catégories (classification à 60 voies) pendant la formation et testé la classification Nct=20 catégories (20 voies). Pour notre modèle le plus performant, nous avons également effectué un test final de classification Nct=5 (5 voies) pour comparer nos résultats avec la littérature. Lors de l'entraînement, chaque classe présente dans le mini-lot est constituée de Ns = 1 points d'appui, car nous avons constaté que limiter le nombre de points d'appui conduit à une meilleure précision de classification. Cela peut être intuitivement compris comme la mise en adéquation du régime de formation et du régime de tests. Les Nq = 20 - Ns = 19 images restantes par catégorie sont utilisées comme points de requête.
Les résultats détaillés de nos expériences sont résumés dans le tableau 1. Nous explorons 4 méthodes pour estimer la matrice de covariance à partir de la sortie de covariance brute de l'encodeur, voir la section 3.1 pour plus de détails.
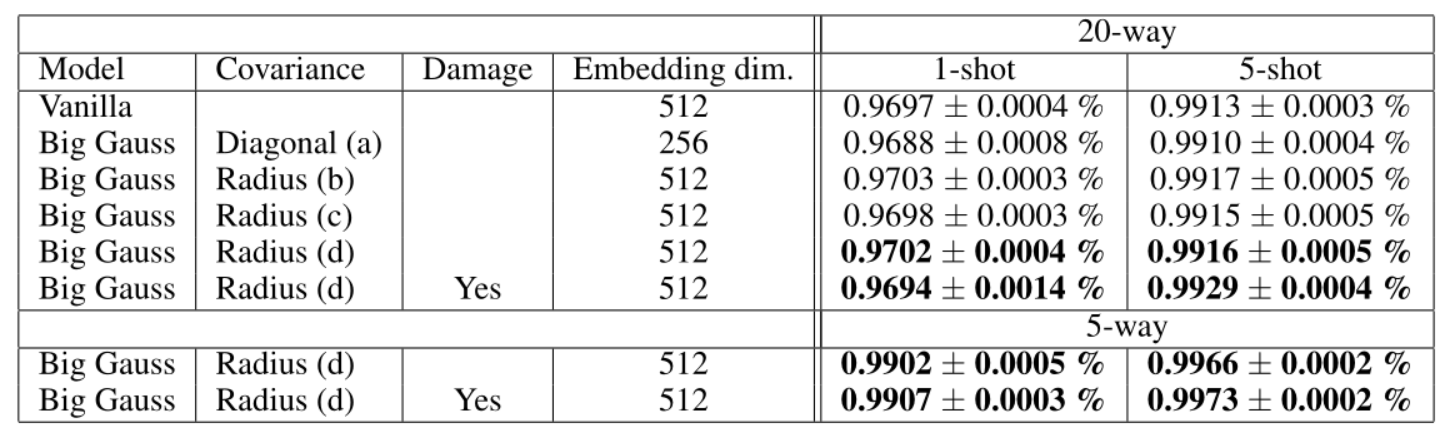
Tableau 1 : Résultats de tests d'une grande structure d'encodeur (filtres 3 × 3, 4 couches, nombre de filtres = 128 256 512,-), comparant l'impact des dimensions de la matrice de covariance et de l'espace d'intégration sur la précision finale. (a, b, c, d) impliquent différentes méthodes de conversion de la sortie brute du codeur en une matrice de covariance. L'estimation du rayon de la covariance ajoute une dimension à la sortie du codeur. L'estimation diagonale double le nombre de sorties du codeur. Par conséquent, un grand réseau gaussien avec 256 dimensions d’intégration et une covariance diagonale a le même nombre de paramètres qu’un réseau imaginaire avec 512. L'estimation du rayon a 1 dimension supplémentaire et est donc comparable au modèle fictif de la même dimension d'intégration. La colonne endommagée indique que l'ensemble de formation a été intentionnellement partiellement sous-échantillonné pendant la formation.
Nous avons également vérifié que, tant que les estimations de covariance ne sont pas inutilement complexes, il est plus avantageux d’utiliser la sortie du codeur comme estimation de covariance que d’utiliser le même nombre de paramètres comme dimensions d’intégration supplémentaires. Cela est vrai pour l'estimation du rayon (c'est-à-dire un nombre réel par vecteur d'intégration), cependant, l'estimation diagonale ne semble pas améliorer les performances (en gardant le nombre de paramètres égal). Cet effet est illustré à la figure 4 et au tableau 1. Le modèle le plus performant a été initialement formé sur l'ensemble de données non corrompu pendant 220 époques. Continuez ensuite la formation en sous-échantillonnant 1,5 % des images à 24 × 24, 1,0 % en sous-échantillonnant 20 × 20 et 0,5 % en sous-échantillonnant 16 × 16 pendant 100 époques. Utilisez ensuite un sous-échantillonnage de 1,5 % à 23 × 23, un sous-échantillonnage de 1,0 % à 17 × 17 pour 20 époques et un sous-échantillonnage de 1,0 % à 23 × 23 pour 10 époques. Ces choix sont arbitraires et non optimisés. La destruction délibérée de l'ensemble de données a encouragé l'utilisation d'estimations de covariance et a augmenté les résultats (k > 1), comme le montrent le tableau 1 et la figure 5. Cette section montre que l'ensemble de données Omniglot est de trop haute qualité et un banc d'essai trop simple pour notre approche. La courbe de perte d’entraînement est présentée à la figure 6. La précision de la formation et des tests en fonction de l’itération est également illustrée à la figure 7.
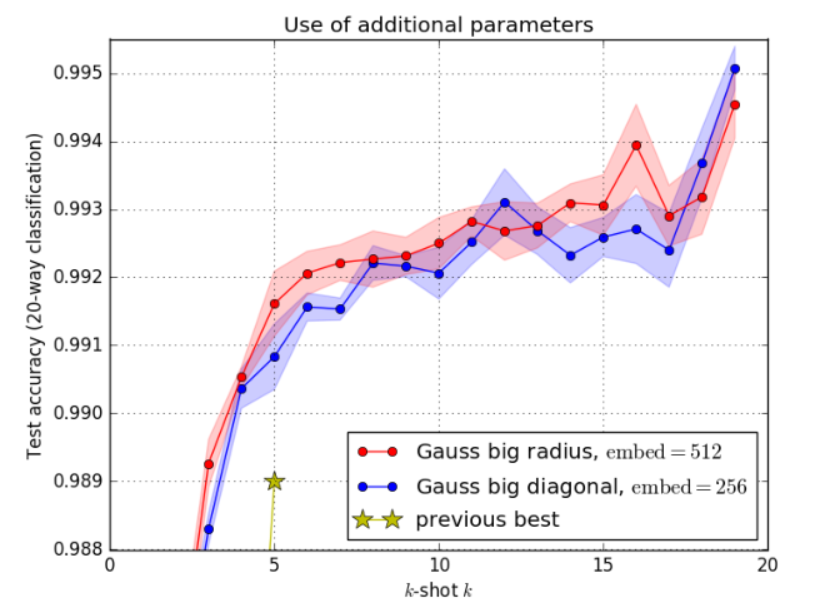
Figure 4 : Comparaison de deux méthodes d'attribution de paramètres supplémentaires. Attribuez des paramètres supplémentaires pour augmenter la dimension de l'espace d'intégration (rayon) ou pour effectuer une estimation de covariance plus précise (diagonale). L'estimation du rayon (avec 1 nombre réel supplémentaire par vecteur d'intégration) surpasse l'estimation diagonale, ainsi que le réseau prototype fictif avec le même nombre de paramètres.
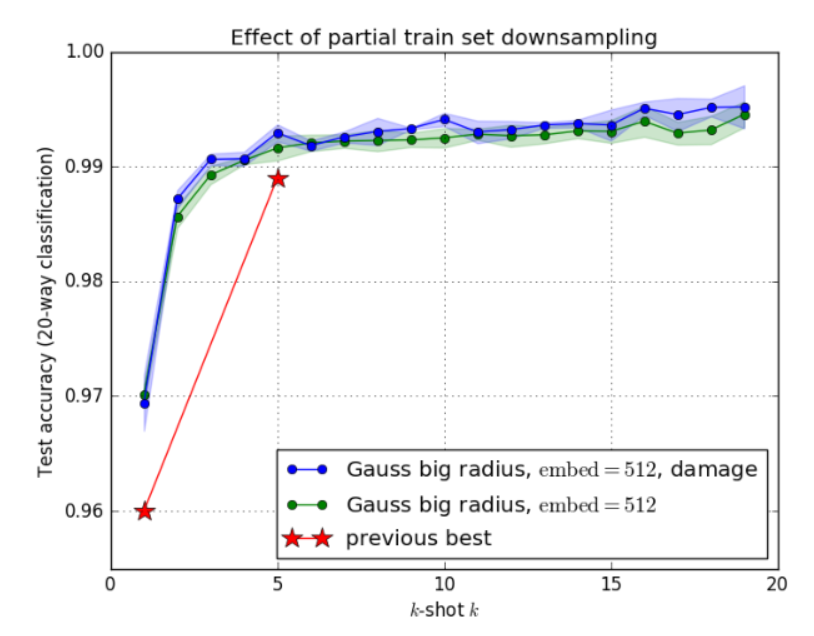
Figure 5 : Effet du sous-échantillonnage d’une partie de l’ensemble d’entraînement sur la précision du test k-shot. La version formée sur des données intentionnellement corrompues surpasse la version formée sur des données non modifiées car elle apprend à mieux exploiter les estimations de covariance.
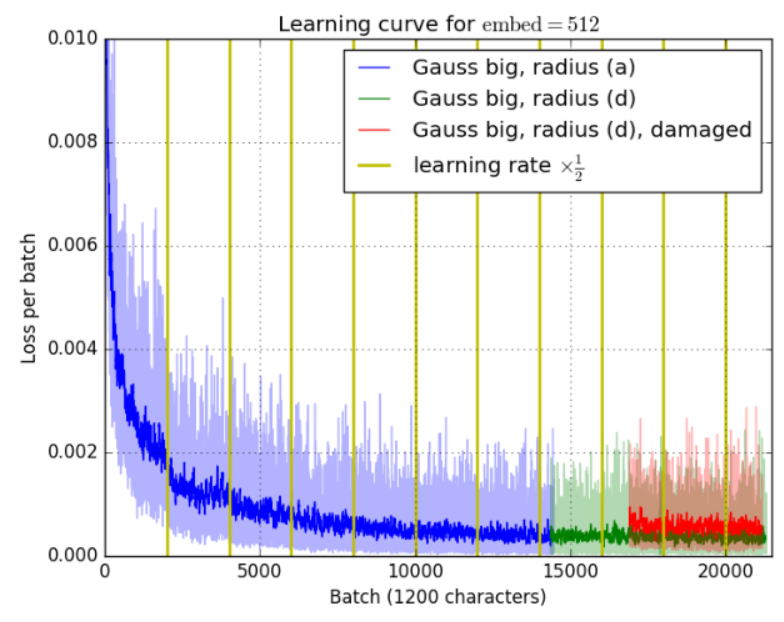
Figure 6 : Perte en fonction de l'itération. La ligne verticale jaune indique où le taux d'apprentissage est divisé par deux. Les effets bénéfiques d’une réduction de moitié du taux d’apprentissage sont visibles dès le début. La partie rouge correspond à un entraînement sur un ensemble d'entraînement partiellement sous-échantillonné et présente donc une perte plus élevée.
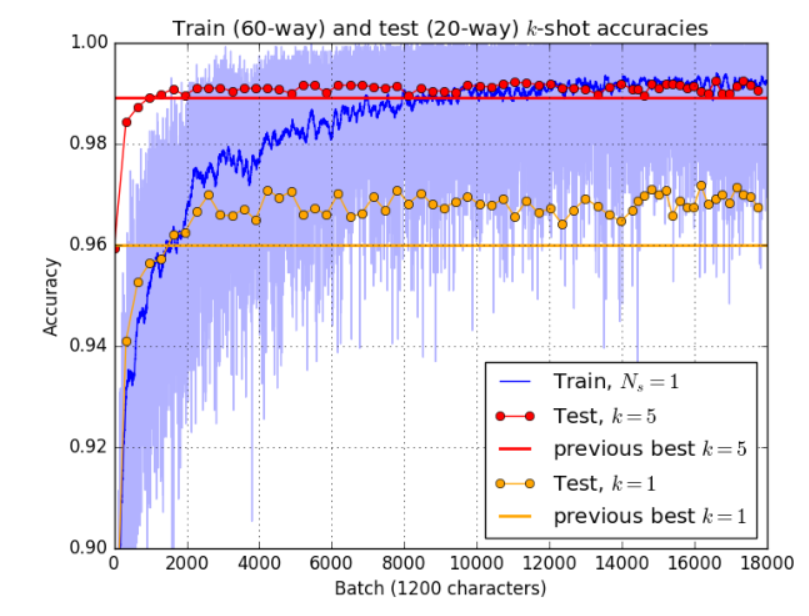
Figure 7 : Comparaison de la précision de la formation et de la précision des tests. La figure montre la précision de l'entraînement (classification à 60 voies) d'un grand réseau prototype gaussien (estimation de la covariance du rayon) et la compare aux performances de tests à 1 et 5 coups (classification à 20 voies). Il compare également les résultats avec la technologie de pointe actuelle. [6]
Nous avons mené des expériences de validation avec une petite architecture et obtenu des résultats comparables à ceux de [6], résumés dans le tableau 2. Le tableau montre également que l'entraînement sous un régime Ns > 1, c'est-à-dire utiliser plus de points de données pour définir une classe, conduit à de moins bonnes performances. La figure 8 montre l'effet d'une capacité plus élevée pour les modèles plus grands. Une comparaison de notre modèle avec les résultats de la littérature est présentée dans le tableau 3. Au meilleur de nos connaissances, notre modèle surpasse les résultats de pointe en 1 et 5 coups dans la classification du temps de test à 5 et 20 voies sur Omniglot. En particulier dans la classification à 5 coups, nous avons atteint des performances très proches de la perfection (99,73 ± 0,02 %), concluant ainsi qu'un ensemble de données plus complexe est nécessaire pour poursuivre le développement de l'algorithme d'apprentissage des petits nombres.
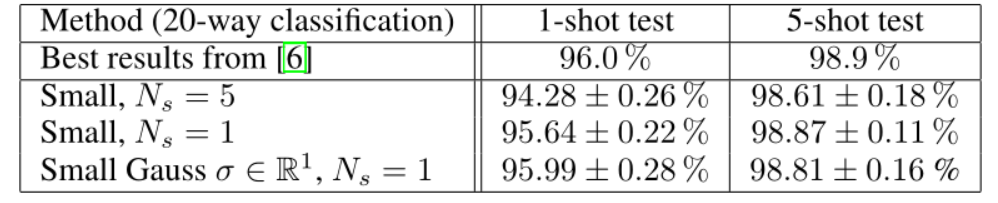
Tableau 2 : Résultats de nos expériences de validation utilisant une petite architecture. Le niveau technique du classement à 20 est de 96,0% pour 1 coup et de 98,9% pour 5 coups. Ns est le nombre de points d'appui de chaque catégorie lors de l'entraînement. Toute la formation est effectuée sous le régime Nc = 60 (classification à 60 voies). Pour le modèle prototype gaussien, σ∈S représente la dimension de la matrice de covariance estimée.
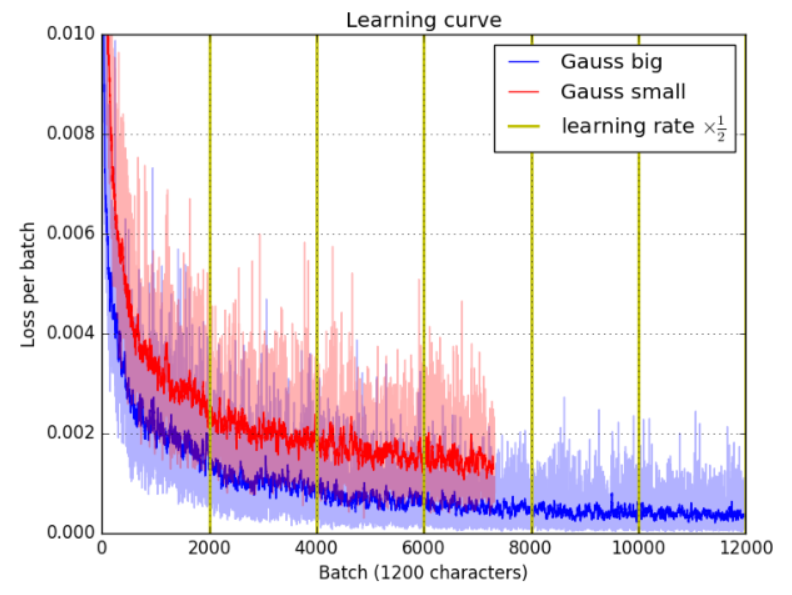
Figure 8 : Effet de la capacité du modèle sur la perte. Les modèles plus grands s’entraînent plus rapidement et génèrent globalement des pertes moindres. La ligne verticale jaune indique où le taux d'apprentissage est divisé par deux.
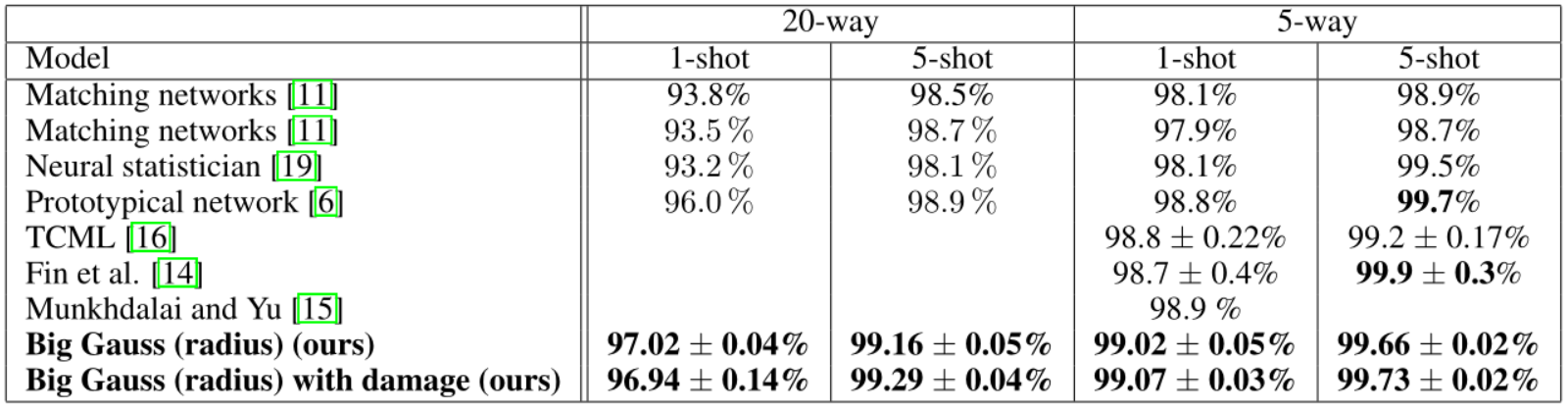
Tableau 3 : Meilleurs résultats de nos expériences par rapport à d’autres articles. Toute la formation est effectuée sous le régime Nc = 60 (classification à 60 voies). Au meilleur de nos connaissances, notre modèle atteint des performances statistiquement avancées dans la classification à 20 voies en 1 coup et en 5 coups, ainsi qu'en classification à 5 voies en 1 coup. Dans 5 cas de 5 voies, nos performances sont comparables à l'état de l'art actuel.
5.1 Utilisation de l'estimation de covariance
Pour tester notre hypothèse selon laquelle le réseau prototype gaussien surpasse la version vanille en raison de sa capacité à prédire la covariance des images individuelles intégrées et donc la possibilité de les sous-pondérer, nous avons étudié les performances du réseau le plus performant formé sur un échantillon partiellement sous-échantillonné. ensemble de formation.La distribution des valeurs prédites s. Nous avons intentionnellement sous-échantillonné une partie des données et étudié la distribution de covariance qui en résulte.
Une image sous-échantillonnée change sa moyenne et sa variance. Étant donné que notre encodeur dispose d'une couche de normalisation par lots dans chaque bloc (voir l'équation 3 pour plus de détails), la signification d'une valeur spécifique de la sortie d'origine change en fonction du lot actuel. Étant donné que notre modèle est entraîné avec la normalisation par lots, le désactiver pour étudier la covariance conduit à des résultats non pertinents.
Pour l’ensemble de données non compromis, la grande majorité des estimations de covariance sont les mêmes. Cela reste vrai même lorsque des dégradations sont artificiellement introduites par le biais d’un sous-échantillonnage. Cependant, la distribution est décalée en raison de l'effet de normalisation des lots dans la dernière couche. Pour mieux représenter la signification des covariances inverses individuelles, nous alignons les histogrammes de manière à ce que les valeurs les plus fréquentes correspondent. Cette approche est utile car la valeur la plus dominante correspond à la sortie originale de 0, et seules les valeurs qui en diffèrent affectent la classification. Les résultats sont présentés dans la figure 9.
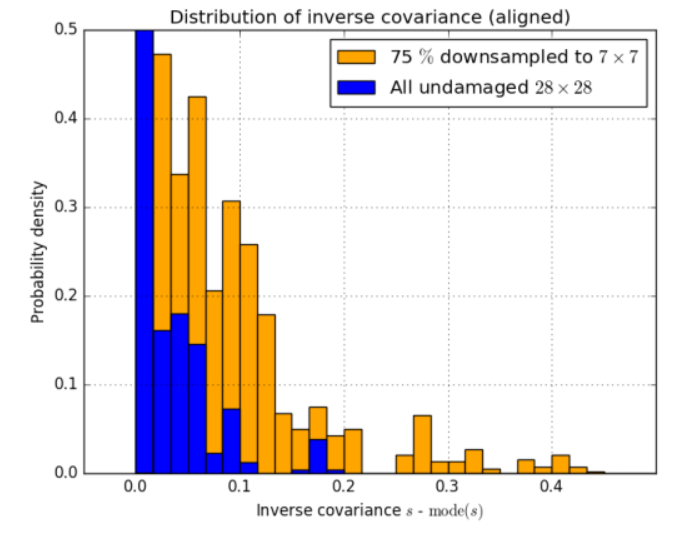
Figure 9 : Covariances prévues de l'ensemble de données d'origine et de la version partiellement sous-échantillonnée. Le réseau gaussien apprend à réduire la pondération des exemples compromis en prédisant un S plus élevé, comme le montre la queue plus lourde de la distribution jaune. Les distributions sont regroupées car seule la différence entre le front d'attaque et une valeur affecte la classification.
6. Conclusion
Dans cet article, nous proposons un réseau prototype gaussien pour la classification des photos minoritaires – une architecture améliorée basée sur des réseaux prototypes [6]. Nous avons testé notre modèle sur l'ensemble de données Omniglot et exploré différentes méthodes de génération d'estimations de matrice de covariance et d'intégration de vecteurs. Nous montrons que pour un nombre comparable de paramètres, les réseaux prototypes gaussiens surpassent les réseaux prototypes vanille et, par conséquent, notre choix architectural est bénéfique. Nous constatons que l’estimation d’un seul nombre réel sur le vecteur d’intégration fonctionne mieux que l’estimation d’une matrice de covariance diagonale ou complète. Nous émettons l’hypothèse que des ensembles de données de moindre qualité et moins homogènes pourraient préférer des estimations de matrice de covariance plus complexes. Contrairement à [6], nous avons constaté que les meilleurs résultats sont obtenus si le réseau est formé dans un régime 1-shot. Nous avons ensuite étendu le modèle et réussi à atteindre des performances de pointe en matière de classification à 1 et 5 coups dans les régimes de test à 5 et 20 voies (pour 5 coups à 5 voies, nous avons comparé des tests équivalents à 5 et à 20 voies). à l'état de l'art). Nous parvenons à obtenir une meilleure précision (en particulier pour la classification (k>1)-shot) en abaissant artificiellement le taux d'échantillonnage de l'ensemble de données d'entraînement pour encourager le réseau à tirer pleinement parti des estimations de covariance. Nos résultats sont très proches de la performance parfaite, en particulier pour la classification à 5 voies. Nous concluons donc que les développements ultérieurs dans la classification des photos minoritaires devraient se concentrer sur des ensembles de données plus complexes qu'Omniglot. Nous émettons l’hypothèse que la capacité d’apprendre les plongements et leurs incertitudes sera plus bénéfique sur des ensembles de données de moindre qualité, ce qui est courant dans les applications du monde réel. Dans ce cas, la sous-pondération de certains points de données peut être la clé d’une classification fidèle. Nos expériences de sous-échantillonnage sur Omniglot le démontrent.