Descargar el conjunto de datos:
Link: https: //pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
código de extracción: 2xq4
Crear un conjunto de datos: https://www.cnblogs.com/xiximayou/p/12398285.html
La lectura de los conjuntos de datos: https://www.cnblogs.com/xiximayou/p/12422827.html
Formación: https://www.cnblogs.com/xiximayou/p/12448300.html
Guardar el modelo y la formación continua: https://www.cnblogs.com/xiximayou/p/12452624.html
Cargar un modelo guardado y la prueba: https://www.cnblogs.com/xiximayou/p/12459499.html
Formación y validación del conjunto de la división de verificación borde lateral: https://www.cnblogs.com/xiximayou/p/12464738.html
Uso de estrategias y la tasa de atenuación de la prueba de entrenamiento borde lateral de aprendizaje: https://www.cnblogs.com/xiximayou/p/12468010.html
uso Tensorboard entrenamiento visual y el proceso de pruebas: https://www.cnblogs.com/xiximayou/p/12482573.html
Recibir los parámetros de línea de comandos: https://www.cnblogs.com/xiximayou/p/12488662.html
uso top5 TOP1 y precisión para medir el modelo: https://www.cnblogs.com/xiximayou/p/12489069.html
El uso de pre-formados modelo resnet18: https://www.cnblogs.com/xiximayou/p/12504579.html
El cálculo de la varianza media y la del conjunto de datos: https://www.cnblogs.com/xiximayou/p/12507149.html
La relación entre la Época, el BatchSize, el PASO: https://www.cnblogs.com/xiximayou/p/12405485.html
pytorch leer los conjuntos de datos de dos maneras. En esta sección se describe una segunda forma de realización.
La estructura de directorio se almacena en el conjunto de datos:

En primer lugar, necesitamos una imagen de la trayectoria y la etiqueta almacenada para el archivo txt, crear un nuevo archivo en las utilidades Img_to_txt.py
importación OS de pegote importación pegote raíz = " / content / unidad / Mi unidad / cuadernos Colab / datos / dogcat / " train_path = raíz + " tren " val_path = raíz + " val " test_path = raíz + " prueba " def img_to_txt (ruta): tmp = path.strip split () (. " / " ) [- 1 ] nombre de archivo = tmp + " .txt " con abierto (nombre de archivo, ' un ' ,encoding =" UTF-8 " ) como fp: i = 0 para f en ordenados (os.listdir (ruta de acceso)): para la imagen en glob (ruta + " / " + str (f) + " /*.jpg " ): fp. escritura (imagen + " " + str (i) + " \ n " ) i + = 1 img_to_txt (train_path) #img_to_txt (val_path) #img_to_txt (test_path)
En el que el os.listdir () para obtener una lista de archivos en la ruta de la carpeta, [ 'gato', 'perro']. glob () para obtener todos los archivos correspondientes en el directorio. Para poder categoría digitalmente marca el fin, necesitamos ordenar la lista de directorios. Vamos a continuación, gato marcado como 0, 1 perro etiquetado. Y el camino de las etiquetas y que corresponde a añadir a la txt.
Después de ejecutar Se obtuvieron resultados similares:
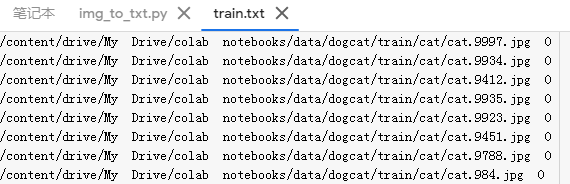
Entonces queremos lograr su clase de conjunto de datos definido, necesidad de heredar la clase de conjunto de datos, y anular __getitem __ () y __len __ () método: Crear un nuevo archivo en las utilidades read_from_txt.py
de torch.utils.data importación de conjunto de datos de PIL importación Imagen clase Dogcat (conjunto de datos): def __init__ (auto, txt_path, transformar = Ninguno, target_transform = None): super (Dogcat, sí). __init__ () self.txt_path = txt_path self.transform = transformar self.target_transform = target_transform fp = abierto (txt_path, ' r ' ) imgs = [] para línea en fp: línea= Line.strip (). Split () # de impresión (línea) img = línea [0] + " " + línea [1] + " " + línea [2 ] # [ '/ content / unidad / Mi', 'Drive / colab', 'cuadernos / data / dogcat / tren / cat / cat.9997.jpg', '0'] # imgs.append ((línea [0], int (línea [-1]))) imgs.append ((img, int (línea [-1 ]))) self.imgs = imgs def __getitem__ (self, índice): imagen, etiqueta = self.imgs [índice] imagen = Image.open (imagen) .convert ( ' RGB ' ) si uno mismo.transformar es no Ninguno: imagen = self.transform (imagen) de retorno de imagen, etiqueta def __len__ (self): retorno len (self.imgs)
Puesto que tenemos una imagen de la etiqueta del espacio en el camino, el camino tomado nota y cuándo.
Después de la rdata.py
de torch.utils.data importación DataLoader importación torchvision importación torchvision.transforms como transformadas de importación antorcha de utils importar read_from_txt def load_dataset_from_dataset (batch_size): # 预处理 de impresión (batch_size) train_transform = transforms.Compose ([transforms.RandomResizedCrop (224 ), las transformadas .ToTensor ()]) val_transform = transforms.Compose ([transforms.Resize ((224224 )), transforms.ToTensor ()]) test_transform = transforms.Compose ([transforms.Resize ((224224)), transforms.ToTensor ()]) de la raíz = " / content / unidad / Mi unidad / colab cuadernos / utils / " train_loader = DataLoader (read_from_txt.Dogcat (raíz + " train.txt " , train_transform), batch_size = batch_size, reproducción aleatoria = True, num_workers = 6 ) val_loader = DataLoader (read_from_txt.Dogcat (raíz + " val.txt " , val_transform), batch_size = batch_size, barajar = True, num_workers = 6 ) test_loader = DataLoader read_from_txt.Dogcat (raíz + ( " test.txt " , test_transform), batch_size = batch_size, barajar = True, num_workers = 6 ) de retorno train_loader, val_loader, test_loader
Entonces main.py están listos para usar.
train_loader, val_loader, test_loader = rdata.load_dataset_from_dataset (batch_size)
Compruebe el error bajo train.txt encuentran los nombres de archivos duplicados, estos archivos duplicados que desea eliminar.

Última ejecución:

Este último ser dada a:

La dirección de la imagen no se han leído a DataLoader se unió en el? Hilo de seguridad? Sin embargo, para encontrar una solución. Sin embargo, el proceso de creación de un conjunto de datos en su conjunto es uno de esos.