Tabla de contenido
Prefacio
Este blog se basa en la conversión mutua del formato VOC y el formato YOLO en mi otro blog , puede consultarlo si es necesario.
El siguiente código se puede copiar y ejecutar directamente para pruebas personales (todas las rutas siguientes se modifican a sus rutas correspondientes) {\color{Red} \mathbf{El siguiente código se puede copiar y ejecutar directamente para pruebas personales (todas las rutas siguientes se modifican a sus propias rutas correspondientes)} }El siguiente código se puede copiar y ejecutar directamente para pruebas personales (cambie todas las rutas siguientes a sus propias rutas correspondientes)
Conjunto de entrenamiento, conjunto de validación (8:2)
split82.pyEl contenido es el siguiente:
import os
import shutil
import random
from tqdm import tqdm
"""
标注文件是yolo格式(txt文件)
训练集:验证集 (8:2)
"""
def split_img(img_path, label_path, split_list):
try: # 创建数据集文件夹
Data = './VOCdevkit/VOC2007/ImageSets'
# 这里我的文件夹./VOCdevkit/VOC2007/ImageSets提前创建好了,所以注释了下一行,否则会抛异常
# os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
# test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
# test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
# os.makedirs(test_img_dir)
# os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = all_img_path
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.txt'
return os.path.join(label_path, label)
if __name__ == '__main__':
img_path = './VOCdevkit/VOC2007/JPEGImages'
label_path = './YoloLabels'
split_list = [0.8, 0.2] # 数据集划分比例[train:val]
split_img(img_path, label_path, split_list)
Conjunto de entrenamiento, conjunto de validación, conjunto de prueba (7:2:1)
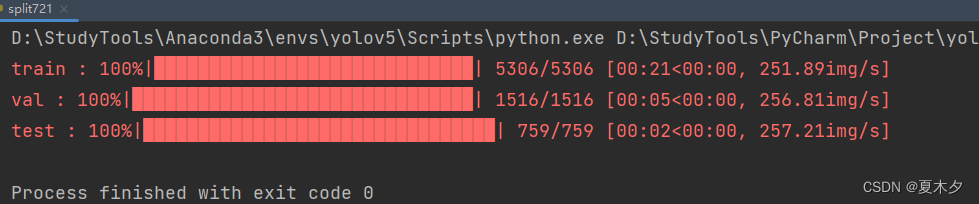
split721.pyEl contenido es el siguiente:
import os, shutil, random
from tqdm import tqdm
"""
标注文件是yolo格式(txt文件)
训练集:验证集:测试集 (7:2:1)
"""
def split_img(img_path, label_path, split_list):
try:
Data = './VOCdevkit/VOC2007/ImageSets'
# Data是你要将要创建的文件夹路径(路径一定是相对于你当前的这个脚本而言的)
# os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
os.makedirs(test_img_dir)
os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
all_img_path.remove(val_img[i])
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img]
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
_copy(test_img[i], test_img_dir)
_copy(test_label[i], test_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.txt'
return os.path.join(label_path, label)
if __name__ == '__main__':
img_path = './VOCdevkit/VOC2007/JPEGImages' # 你的图片存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
label_path = './YoloLabels' # 你的txt文件存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
split_list = [0.7, 0.2, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)
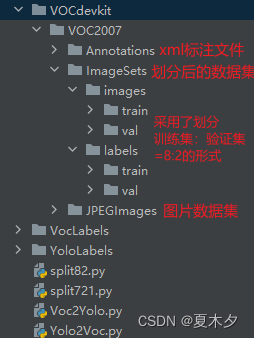
Después de completar la conversión mutua entre el formato VOC y el formato YOLO de mi otro blog y la partición YOLO del conjunto de datos (conjunto de entrenamiento, conjunto de verificación, conjunto de prueba) en este artículo , toda la estructura de mi proyecto se muestra a continuación: