Bloggers meses antes de tocarlos, pitón tiene que decir como lengua de cola, tiene sus propias ventajas. Bloggers blancas como la programación, después de un día de trabajo duro, escribir improvisada utilizable pitón de araña después el código de error para mejorar la captura de requestException, reptiles medidos pueden funcionar para siempre, se subió a un montón de cosas sucias en la tierra. . .
Hermanos pegar el código que me des un comentario ah, un grupo de abandonado, gracias ah
arrastrándose resultados que se muestran a continuación:
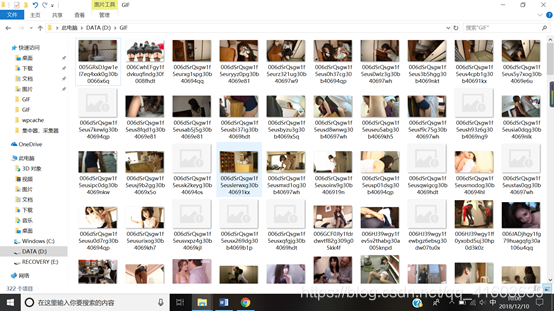
El código fuente es el siguiente:
import os
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
import time
from requests.exceptions import RequestException
def Download_gif(url,path):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
'Connection':'close'
}
html=requests.get(url,headers=headers)
soup=BeautifulSoup(html.text,'html.parser')
gif_url=soup.find_all('a',class_='focus') #找出单页上的所有链接,返回一个list,这个list由一系列字典组成
for gif_url in gif_url: #迭代出每个字典
gif_url=gif_url['href'] #每个字典的key为href时对应的value为链接
html=requests.get(gif_url,headers=headers) #对解析出的链接进行请求
soup=BeautifulSoup(html.text,'html.parser') #soup库进行解析
page=soup.find('div',class_='article-paging').find_all('span') #进入链接发现是分页形式,所有找出链接上的总页数
page=page[-1].text #发现div标签,class为article-paging的标签内的最后一个span标签为页数
each_url=gif_url #这里一定要将url区分开来,一个用each_url,一个用gif_url,否则会发生未知错误,调试过程会发现
for i in range(1,int(page)+1): #构造列表生成式,对应每一页链接进行图片或gif下载
pic=each_url+str(i) #每一页链接
html=requests.get(pic,headers=headers) #请求每一页链接
soup=BeautifulSoup(html.text,'html.parser') #解析每一页链接
pic_url=soup.find_all('img',class_='aligncenter') #发现每一页链接上的img标签,class_为aligncenter的为图片或gif_url
for a_url in pic_url: #迭代出每个图片或Gif链接(为字典形式)
os.chdir(path) #将目录切换至自己电脑上的path目录
a_url=a_url['src'] #gif链接中的src对应图片链接
if a_url==None: #加入判断,如果图片无链接,pass,让爬虫能够运行下去
pass
try:
html=requests.get(a_url,headers=headers) #请求图片链接,得到图片或Gif的文件流
requests.adapters.DEFAULT_RETRIES = 5 #加入重复请求次数
file_name=a_url.split('/')[-1] #给出文件名
f=open(file_name,'wb') #写入文件
f.write(html.content)
time.sleep(0.000001)
f.close()
time.sleep(0.2)
except RequestException:
return None
if __name__=='__main__':
path='C://Users/panenmin/Desktop/GIF/' #定义path,这里可以更改为自己电脑上的路径,一定用正斜线
start_url='https://www.gifjia5.com/category/neihan/page/' #定义start_url
pool=Pool(6) #构建进程池
for i in range(1,23): #构造列表生成式
url=start_url+str(i) #构造每一页链接
pool.apply_async(Download_gif,args=(url,path)) #传入函数和函数的参数
pool.close()
pool.join()
La lógica del código es un poco confuso, la idea principal es definir una función para rastrear una sola página. Esta función tiene tres iteración anidada. Después de la primera iteración de la capa de todos los enlaces de una sola página, para averiguar el número de páginas de cada enlace, estructura de tipo lista generación, cada página circular, filtrar el cuadro verdadero enlaces GIF, cada uno por un gif o jpg enlace, solicita la solicitud para obtener una corriente de imagen gIF o archivo y escritura en el archivo.
Para la función principal, que circulan ideas para la función Download_gif definidos para la implementación de la página principal que los enlaces en cada página del proceso de ejecución de la función. Mientras que la adición de múltiples proceso de piscina.
Dentro de la función, utilice el módulo de tiempo, time.sleep () es para hacer la solicitud al servidor de araña con menos frecuencia, para evitar el cierre ip etc operación de Sao.
A pesar de esta araña comparar basura, pero también escribir código durante mucho tiempo, pero también la esperanza acaba de empezar amigos reptiles eran capaces de aprender un poco de algo desde el interior, pero mañana voy a estar etiquetados proceso de desarrollo específico. (Difícil obligar al propietario a los trabajadores de oficina, pero más ocupado.)
Adjunto mi palabra favorita, hablar es barato, muéstrame el código de
proceso de desarrollo:
1: gif lugar de nacimiento de los primeros en entrar en la página principal, consulte Diseño de página
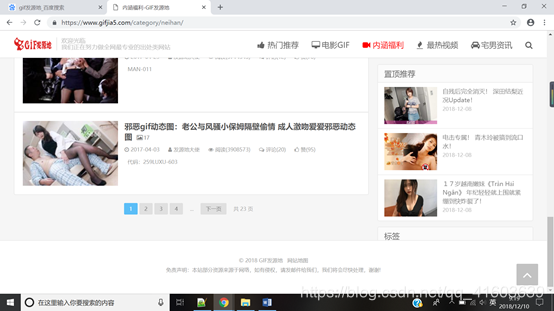
Con opciones de cromo desarrolladores de navegadores, se encontró lo siguiente:
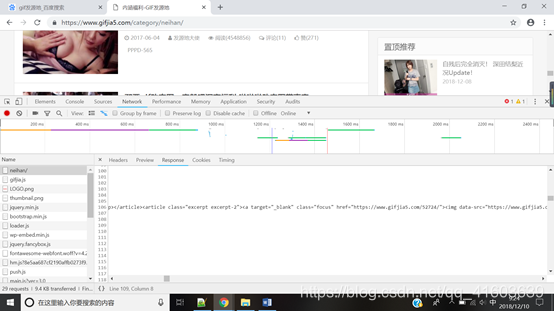
se puede encontrar una etiqueta, atributos de clase para centrarse nodo que contiene enlaces a toda la casa de
todos los enlaces de la página principal es la correspondiente href
primer eslabón de nuestra casa, como se muestra a continuación:
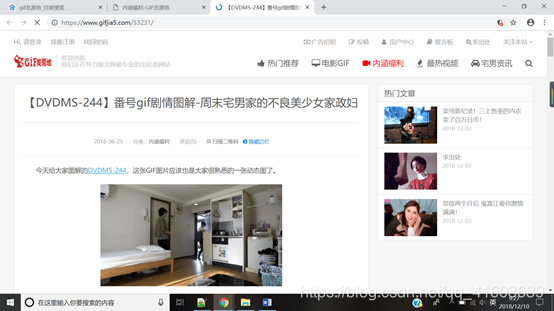
Rechazado, todavía encontramos la pestaña de interfaz
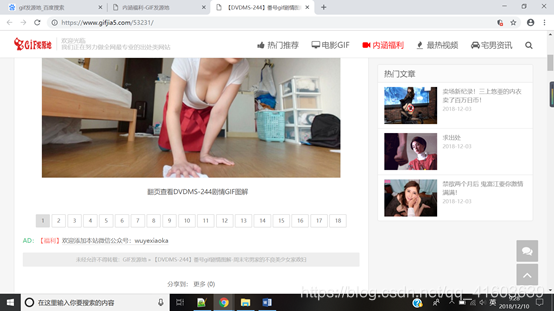
Opciones de desarrollador abiertos, encontrar el número máximo de páginas jpg o gif vínculo
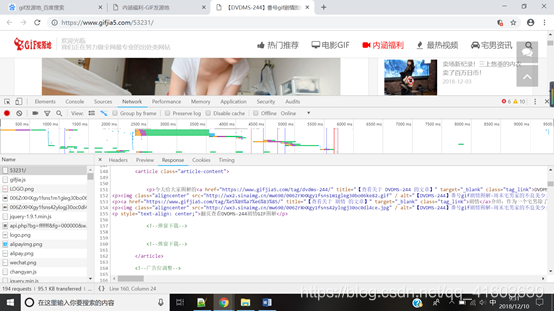
Encuentra el número máximo de páginas:
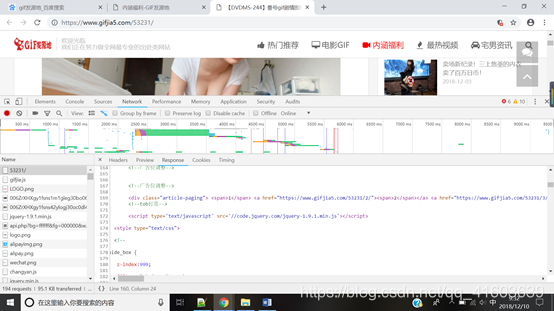
Después enlaces FIND para cada solicitud de página a las imágenes Circulate o gif vínculo para obtener una secuencia de archivo, escribir en el fichero.
Las ideas que se arrastran sobre una parte de la función, es decir, para subir un solo ideas de página para las páginas que se arrastran, la idea es muy simple, un total de 23, ciclo de rastreo
SI Nombre == ' principal ':
path = 'C: // el usuario / panenmin / Escritorio / GIF /' # define el camino, donde se puede cambiar la ruta a su propio ordenador, asegúrese de utilizar una barra inclinada
START_URL =' https: // www.gifjia5.com/category/neihan/page/ '# definen START_URL
la piscina = piscina (6). Construcción proceso de piscina #
para i en el rango de (1,23): # configurado fórmula lista
url = START_URL + str (i) # construcción de cada página enlaza
pool.apply_async (Download_gif, args = (URL , ruta)) # paso de parámetros y funciones de función
pool.close ()
pool.join ()
Y el parámetro de la función de rastreo pase en una sola página, se hace. Pero los bloggers descubrieron que los reptiles son todavía muchas áreas de mejora, tales como gatear por algún tiempo, se encuentra el host remoto a fuerza de reptil se redujo (cierre transitorio Ip), considere unirse a la piscina agente. Muchos de los problemas encontrados en el proceso de desarrollo, se puede considerar mientras que el aprendizaje, el conocimiento y la acción. Espero que acaba de empezar amigos reptiles luchar por su escritura algo, por lo que a entender más profundamente.
Modificar el código, el blogger apareció en error del sistema operativo nombre_archivo en el momento de rastreo, por lo que el código fuente actualizado. `Juicio de nombre_archivo
import os
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
import time
from requests.exceptions import RequestException
def Download_gif(url,path):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
'Connection':'close'
}
html=requests.get(url,headers=headers)
soup=BeautifulSoup(html.text,'html.parser')
gif_url=soup.find_all('a',class_='focus') #找出单页上的所有链接,返回一个list,这个list由一系列字典组成
for gif_url in gif_url: #迭代出每个字典
gif_url=gif_url['href'] #每个字典的key为href时对应的value为链接
html=requests.get(gif_url,headers=headers) #对解析出的链接进行请求
soup=BeautifulSoup(html.text,'html.parser') #soup库进行解析
page=soup.find('div',class_='article-paging').find_all('span') #进入链接发现是分页形式,所有找出链接上的总页数
page=page[-1].text #发现div标签,class为article-paging的标签内的最后一个span标签为页数
each_url=gif_url #这里一定要将url区分开来,一个用each_url,一个用gif_url,否则会发生未知错误,调试过程会发现
for i in range(1,int(page)+1): #构造列表生成式,对应每一页链接进行图片或gif下载
pic=each_url+str(i) #每一页链接
html=requests.get(pic,headers=headers) #请求每一页链接
soup=BeautifulSoup(html.text,'html.parser') #解析每一页链接
pic_url=soup.find_all('img',class_='aligncenter') #发现每一页链接上的img标签,class_为aligncenter的为图片或gif_url
for a_url in pic_url: #迭代出每个图片或Gif链接(为字典形式)
os.chdir(path) #将目录切换至自己电脑上的path目录
a_url=a_url['src'] #gif链接中的src对应图片链接
file_name=a_url.split(r'/')[-1]
if file_name[-4:]!='.gif' and file_name[-4:]!='.jpg' and file_name[-4:]!='jpeg':
return None
if a_url==None: #加入判断,如果图片无链接,pass,让爬虫能够运行下去
pass
try:
html=requests.get(a_url,headers=headers) #请求图片链接,得到图片或Gif的文件流
requests.adapters.DEFAULT_RETRIES = 5 #加入重复请求次数
f=open(file_name,'wb')
f.write(html.content)
time.sleep(0.000001)
f.close()
time.sleep(0.2)
except RequestException:
return None
if __name__=='__main__':
path='D://GIF/' #定义path,这里可以更改为自己电脑上的路径,一定用正斜线
start_url='https://www.gifjia5.com/category/neihan/page/' #定义start_url
pool=Pool(6) #构建进程池
for i in range(1,23): #构造列表生成式
url=start_url+str(i) #构造每一页链接
pool.apply(Download_gif,args=(url,path)) #传入函数和函数的参数
print('第i页已爬完')
pool.close()
pool.join()
Explicar aquí, asegúrese de añadir un código escribir comentario para que las personas no sólo es fácil de leer, en el futuro, cuando el insecto apareció el código, pueden tener una idea clara del código puede ser fácil de mantener. Por supuesto, a excepción de dios. . .
