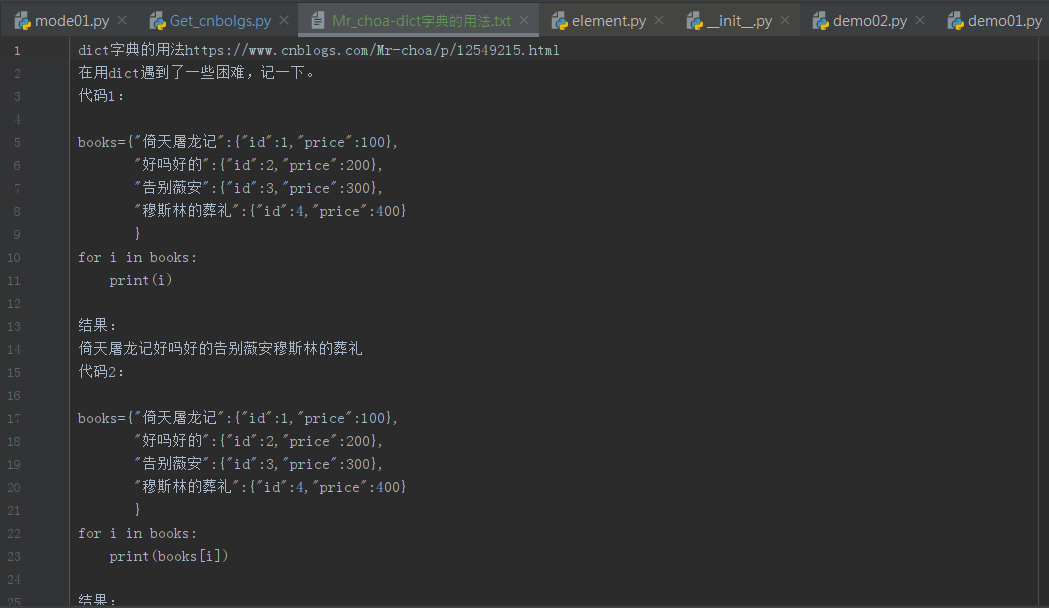
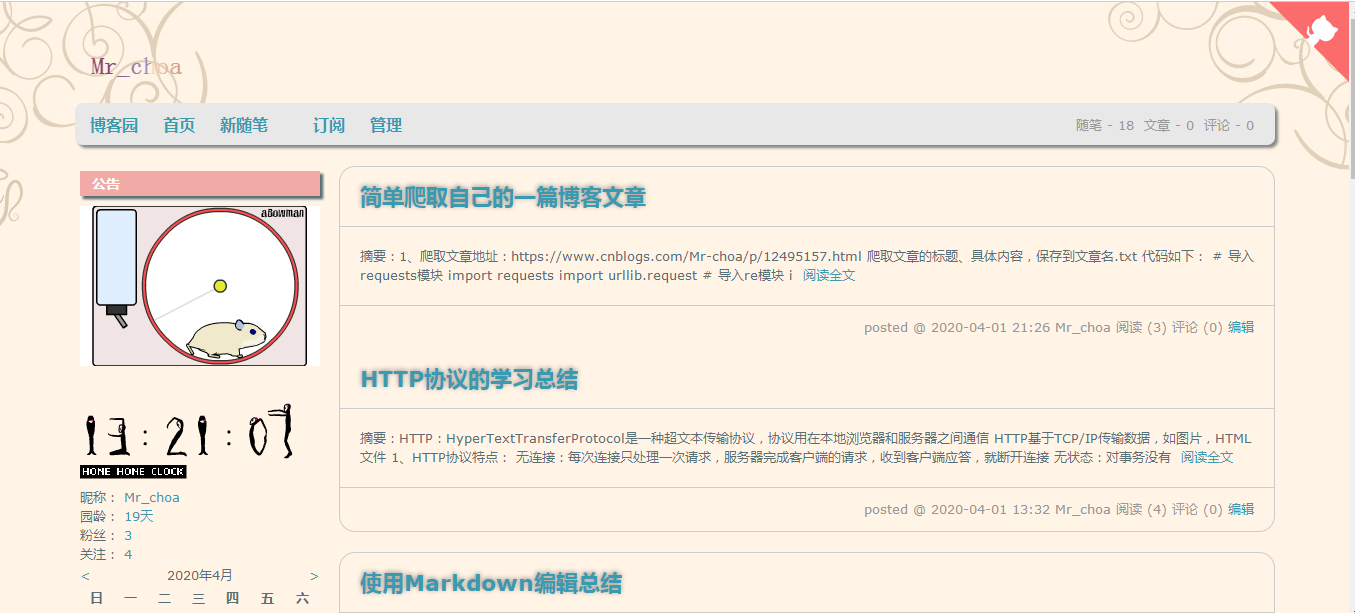
Para rastrear en mi propio blog, por ejemplo: https://www.cnblogs.com/Mr-choa/
1 para los enlaces a todos los artículos:

artículos de blogs representaron un total de dos, como la apertura de la primera página: https://www.cnblogs.com/Mr-choa/default.html?page=1 HTML archivo de origen

Los enlaces son cada blog bajo una etiqueta, y tiene un atributo de clase "postTitle2", cuyo atributo href puntos a esta dirección de blog
<a href=" class=" postTitle2" https://www.cnblogs.com/Mr-choa/p/12615986.html ">
Simple rastreo de su entrada en el blog
</a>
Por lo que podemos obtener expresiones positivas dirección de Bowen para los enlaces a todas las páginas de los artículos del blog va a hacer una travesía:
Módulo de la implementación del código:
# Obtener todos los enlaces DEF get_Urls (url, pageno): "" " De acuerdo url, pageno, puede volver a la lista blogger url de todos los artículos : url param: : param pageno: : retorno: " "" # crear una lista, las entradas del blog se utiliza para mantener la dirección de total_urls = [] # de páginas para ser atravesados por i en el rango (1, pageno + 1 ): # de páginas dirección de URL_1 = url + str (i) # get toda la fuente de esta página código HTML = get_html (URL_1) # Crear una propiedad title_pattern R ^ = ' <a. * class = "postTitle2." * el href = "(. *)"> ' #Expresiones encontrar todos los datos relevantes a través de los atributos positivos, se vincule a todos los mensajes de blog direcciones URL = re.findall (title_pattern, HTML) # enviar un enlace dentro de la lista en el recipiente para URL_ en las direcciones URL: total_urls.append (URL_) # impresión ( .__ __ len total_urls ()) # devuelve todos los enlaces a artículos de blogs vuelven total_urls
2, obtener todo el código fuente
la implementación del código:
DEF get_html (url): "" " devuelve la página correspondiente a la URL de la fuente, después de que el contenido decodificado : param url: : retorno: " "" REQ = urllib.request.Request (url) RESP = la urllib.request.urlopen (REQ) html_page = resp.read (). decodificación ( ' UTF. 8 ' ) de retorno html_page
3, obtener un blog título de la entrada
la implementación del código:
# Obtener título del blog del artículo DEF get_title (url): '' ' adquiere correspondientes inferior artículo url Título : url param: : retorno: ' '' html_page = get_html (url) title_pattern = R ^ ' (<A * ID = ". cb_post_title_url. "*>) (. *) (</a>) ' title_match = la re.search (title_pattern, html_page) título = (2 title_match.group ) de retorno del título
4, blogs get todo el texto
la implementación del código:
# Obtener texto artículo de blog DEF get_Body (url): "" " obtener la URL del contenido del texto del artículo correspondiente : param url: : retorno: " "" html_page = get_html (url) Sopa = BeautifulSoup (html_page, ' html.parser ' ) div = soup.find (el anteriormente mencionado de id = " cnblogs_post_body " ) de retorno div.text
5, para ahorrar papel
la implementación del código:
# Guarda artículos DEF save_file (url): "" " De acuerdo url, excepto los artículos a un local de : url param: : retorno: " "" título = get_title (URL) del cuerpo = get_Body (url) de nombre de archivo = " Mr_choa " + " - ' + + título ' .txt ' con Open (nombre de archivo, ' W 'que codifica = ' UTF-8. ' AS F): f.write (título) f.write (URL) F.Write (cuerpo) # a través de todos los enlaces de blog para los artículos, los artículos del blog guarda DEF save_files (url, pageno): '' ' según la URL y pageno, guarde todos los bloggers artículos : param url: : param pageno: : retorno: ' '' totol_urls = get_Urls (url, pageno) para URL_ en totol_urls: save_file (url_)
Mostrar todo el código:


Importación urllib.request importación Re desde BS4 importación BeautifulSoup # cuántas páginas del blog del autor, un total de pageno = 2 # detrás de la necesidad de añadir números de página url = ' https://www.cnblogs.com/Mr-choa/default.html?page= ' # adquiere la fuente de la página web DEF get_html (url): "" " devuelve la página correspondiente a la URL de la fuente, después de que el contenido decodificado : param url: : retorno: " "" REQ = urllib.request.Request (url) RESP = la urllib.request .urlopen (REQ) html_page = resp.read (). decodificación ( ' UTF. 8 ' ) Volver html_page # adquirido título del blog del artículo DEF get_title (url): '' ' título adquirido corresponde url artículo : url param: : retorno: ' '' html_page = get_html (url) title_pattern = R ^ ' (<A *. = por encima de la Identificación del mencionado "cb_post_title_url." *>) (. *) (</a>) ' title_match = re.search (title_pattern, html_page) título = title_match.group (2 ) de retorno título # get artículo en el blog de texto DEF get_Body (url ): "" " obtener la URL del contenido del texto del artículo correspondiente : url param: : Vuelta: html_page = get_html (url) Sopa = BeautifulSoup (html_page, ' html.parser ' ) div = soup.find (por encima de la Identificación del mencionado = " cnblogs_post_body " ) de retorno div.text # Guarda artículos DEF save_file (url): "" " según url, guardado localmente artículo : URL param: : retorno: "" " título = get_title (URL) del cuerpo = get_Body (URL) de nombre de archivo = " Mr_choa " + '-""" '+ + título ' .Txt ' con Open (nombre de archivo, ' w 'que codifica = ' UTF-8 ' ) AS f: f.write (título) f.write (url) f.write (cuerpo) # a través de todo enlace artículo de blog Guardar Blog artículos Def save_files (url, pageno): '' ' según la URL y pageno, guarde todos los bloggers artículos : param url: : param pageno: : retorno: ' '' totol_urls = get_Urls (url, pageno) para URL_ en totol_urls: save_file (URL_) # obtener todos los enlaces defget_Urls (url, pageno): "" " De acuerdo url, pageno, puede volver a la lista blogger url de todos los artículos : url param: : param pageno: : retorno: " "" # crear una lista, que se utiliza para los artículos del blog de retención dirección total_urls = [] # de páginas para ser atravesados por que en el rango (1 ,. 1 + pageno que no es. ): # de páginas dirección de URL_1 URL = + STR (I) # Get todo el código fuente de la página HTML = get_html (URL_1 ) # Crear una propiedad title_pattern R ^ = ' <a. * class = "postTitle2." * el href = "(. *)"> ' # Expresión de encontrar todos los datos relevantes a través de los atributos positivos, es el enlace de todas las entradas del blog = URLs re.findall (title_pattern, HTML) # enviar un enlace dentro de la lista en el recipiente para URL_ en las direcciones URL: total_urls.append (URL_) # impresión (total_urls .__ __ len ()) # devuelve todos los enlaces a artículos de blogs vuelven total_urls save_files (url , pageno)
efecto:

.txt abierta: