

Desarrollar sus aplicaciones de IA en torno a modelos de código abierto puede hacerlas mejores, más baratas y más rápidas.
Traducido de Cómo vencer a los LLM propietarios con modelos de código abierto más pequeños , autor Aidan Cooper.
Introducción
Al diseñar sistemas que utilizan modelos de generación de texto, muchas personas recurren primero a servicios propietarios, como GPT-4 de OpenAI o Gemini de Google. Después de todo, estos son los mejores y más grandes modelos que existen, así que ¿por qué molestarse con algo más? Con el tiempo, las aplicaciones alcanzan una escala que estas API no admiten, o su costo resulta prohibitivo o los tiempos de respuesta son demasiado lentos. Los modelos de código abierto pueden resolver todos estos problemas, pero si intenta usarlos de la misma manera que usa los LLM propietarios, no obtendrá suficiente rendimiento.
En este artículo, exploraremos las ventajas únicas de los LLM de código abierto y cómo se pueden aprovechar para desarrollar aplicaciones de IA que no solo son más baratas y rápidas que los LLM propietarios, sino también mejores.
LLM propietario versus LLM de código abierto
La Tabla 1 compara las principales características de los LLM propietarios y los LLM de código abierto. Se cree que el LLM de código abierto se ejecuta en una infraestructura administrada por el usuario, ya sea local o en la nube. En resumen: el LLM propietario es el servicio administrado y ofrece el modelo de código cerrado más poderoso y la ventana de contexto más grande, pero el LLM de código abierto es superior en todos los demás aspectos importantes.
La siguiente es la versión china de la tabla (formato de rebajas):
| Modelo de lenguaje grande propietario | Modelo de lenguaje grande de código abierto | |
|---|---|---|
| Ejemplo | GPT-4 (OpenAI), Géminis (Google), Claude (Antrópico) | Gemma 2B (Google)、Mistral 7B (Mistral AI)、Llama 3 70B (Meta) |
| accesibilidad del software | fuente cerrada | Fuente abierta |
| Número de parámetros | nivel de billón | Escala típica: 2B, 7B, 70B |
| ventana contextual | Más largo, 100k-1M+tokens | Fichas más cortas y típicas de 8k-32k |
| capacidad | Mejor intérprete en todas las tablas de clasificación y puntos de referencia | Históricamente a la zaga de los modelos propietarios de lenguajes grandes |
| infraestructura | Plataforma como Servicio (PaaS), gestionada por el proveedor. No configurable. Límites de tasa API. | Normalmente autogestionado en infraestructura de nube (IaaS). Totalmente configurable. |
| Costo de razonamiento | más alto | más bajo |
| velocidad | Más lento al mismo precio. No se puede ajustar. | Depende de infraestructura, tecnología y optimización, pero más rápido. Altamente configurable. |
| Rendimiento | Generalmente sujeto al límite de tasa API. | Ilimitado: escala con su infraestructura. |
| Demora | más alto. Varias rondas de conversaciones pueden acumular una latencia de red significativa. | Si ejecuta el modelo localmente, no hay latencia de red. |
| Función | Normalmente expone un conjunto limitado de funcionalidades a través de su API. | El acceso directo al modelo desbloquea muchas técnicas poderosas. |
| cache | No se puede acceder al lado del servidor | Políticas configurables del lado del servidor para aumentar el rendimiento y reducir los costos. |
| sintonia FINA | Servicios de ajuste limitados (como OpenAI) | Control total sobre el ajuste fino. |
| Proyecto de aviso/flujo | A menudo no es posible debido al alto costo o debido a límites de tarifas o retrasos. | Los procesos de control sin restricciones y cuidadosamente diseñados tienen un impacto negativo mínimo. |
**Tabla 1.** Comparación de las características del LLM patentado y del LLM de código abierto
El objetivo de este artículo es que, al aprovechar las fortalezas de los modelos de código abierto, es posible crear aplicaciones de inteligencia artificial que realicen tareas mejor que los LLM propietarios y, al mismo tiempo, lograr mejores perfiles de rendimiento y costos.
Nos centraremos en estrategias para modelos de código abierto que no son posibles o menos efectivos con los LLM propietarios. Esto significa que no discutiremos técnicas que beneficien a ambos, como las sugerencias de pocos disparos o la generación de recuperación aumentada (RAG).
Requisitos para un sistema LLM eficaz
Al considerar cómo diseñar sistemas eficaces en torno a LLM, hay algunos principios importantes a tener en cuenta.
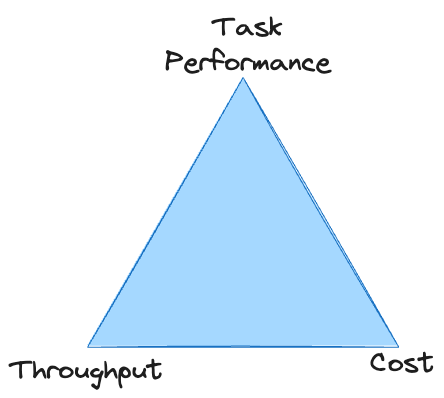
Existe una compensación directa entre el desempeño de la tarea, el rendimiento y el costo: es fácil mejorar cualquiera de ellos, pero generalmente a expensas de los otros dos. A menos que tenga un presupuesto ilimitado, el sistema debe cumplir con estándares mínimos en las tres áreas para sobrevivir. Con los LLM propietarios, a menudo uno se queda atrapado en el vértice del triángulo, incapaz de lograr un rendimiento suficiente a un costo aceptable.
Describiremos brevemente las características de cada uno de estos requisitos no funcionales antes de explorar estrategias que pueden ayudar a resolver cada problema.
Rendimiento
Muchos sistemas LLM luchan por lograr un rendimiento adecuado simplemente porque el LLM es lento.
Cuando se utiliza LLM, el rendimiento general del sistema está determinado casi en su totalidad por el tiempo necesario para generar resultados de texto.
A menos que su procesamiento de datos sea particularmente pesado, otros factores además de la generación de texto son relativamente poco importantes. LLM puede "leer" texto mucho más rápido de lo que puede generarlo; esto se debe a que los tokens de entrada se calculan en paralelo, mientras que los tokens de salida se generan secuencialmente.
Necesitamos maximizar la velocidad de generación de texto sin sacrificar la calidad ni incurrir en costos excesivos.
Esto nos da dos palancas para tirar cuando el objetivo es aumentar el rendimiento:
- Reducir la cantidad de tokens que deben generarse
- Aumentar la velocidad de generación de cada token individual.
Muchas de las estrategias siguientes están diseñadas para mejorar una o ambas áreas.
costo
Para LLM propietario, se le facturará por token de entrada y salida. El precio de cada token estará relacionado con la calidad (es decir, el tamaño) del modelo que utilice. Esto le brinda opciones limitadas para reducir costos: necesita reducir la cantidad de tokens de entrada/salida o usar un modelo más económico (no habrá demasiados para elegir).
Con un LLM autohospedado, sus costos están determinados por su infraestructura. Si utiliza un servicio en la nube para alojamiento, se le facturará por unidad de tiempo que "alquile" la máquina virtual.

Los modelos más grandes requieren máquinas virtuales más grandes y caras. Aumentar el rendimiento sin cambiar el hardware reduce los costos porque se requieren menos horas de computación para procesar una cantidad fija de datos. Del mismo modo, el rendimiento se puede aumentar escalando el hardware vertical u horizontalmente, pero esto aumentará los costos.
Las estrategias para minimizar costos se centran en habilitar modelos más pequeños para la tarea, ya que tienen el mayor rendimiento y son los más baratos de ejecutar.
desempeño de habilidades
El desempeño de la misión es el más vago de los tres requisitos, pero también el que tiene el mayor margen de optimización y mejora. Uno de los principales desafíos para lograr un desempeño adecuado de las tareas es medirlo: es difícil obtener una evaluación cuantitativa confiable del resultado del LLM.
Debido a que nos centramos en tecnologías que benefician exclusivamente a LLM de código abierto, nuestra estrategia enfatiza hacer más con menos recursos y aprovechar métodos que solo son posibles con acceso directo al modelo.
Estrategias de LLM de código abierto para derrotar al LLM propietario
Todas las estrategias siguientes son efectivas de forma aislada, pero también son complementarias. Se pueden aplicar en diversos grados para lograr el equilibrio adecuado entre los requisitos no funcionales del sistema y maximizar el rendimiento general.
Diálogo multiturno y flujo de control.
- Mejorar el rendimiento de la tarea
- Reducir el rendimiento
- Agregar costo por insumo
Si bien se puede utilizar una amplia gama de estrategias de diálogo de múltiples turnos con los LLM propietarios, estas estrategias a menudo no son factibles porque:
- Puede resultar costoso cuando se factura mediante token
- Puede agotar los límites de tasa de API porque requieren múltiples llamadas de API por entrada
- Podría ser demasiado lento si el intercambio de ida y vuelta implica generar muchos tokens o acumular mucha latencia en la red.
Es probable que esta situación mejore con el tiempo a medida que los LLM propietarios se vuelvan más rápidos, escalables y asequibles. Pero por ahora, los LLM propietarios a menudo se limitan a una única estrategia que se puede aplicar a escala a casos de uso del mundo real. Esto es consistente con la ventana de contexto más amplia proporcionada por los LLM propietarios: la estrategia preferida a menudo es simplemente agrupar una gran cantidad de información e instrucciones en un solo mensaje (lo que, por cierto, tiene impactos negativos en el costo y la velocidad).
Con un modelo autohospedado, estas desventajas de las conversaciones de múltiples rondas son menos preocupantes: el costo por token es menos relevante; no hay límites de velocidad de API y la latencia de la red se puede minimizar; La ventana de contexto más pequeña y las capacidades de inferencia más débiles de los modelos de código abierto también deberían impedirle utilizar una sola pista. Esto nos lleva a la estrategia central para derrotar a los LLM propietarios:
La clave para superar el LLM propietario es utilizar modelos de código abierto más pequeños para realizar más trabajo en una serie de subtareas más detalladas.
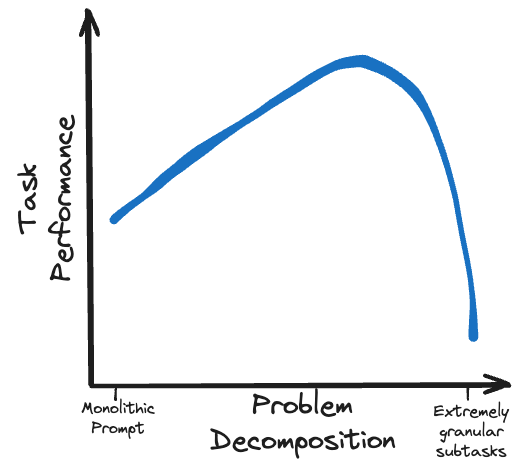
Las estrategias de estímulo de múltiples rondas cuidadosamente formuladas son factibles para los modelos locales. Técnicas como Chain of Thoughts (CoT), Trees of Thought (ToT) y ReAct permiten que los modelos menos capaces funcionen a la par de los modelos más grandes.
Otro nivel de complejidad es el uso de flujo de control y ramificación para guiar dinámicamente el modelo a lo largo de la ruta de inferencia correcta y descargar algunas tareas de procesamiento a funciones externas. Estos también se pueden usar como un mecanismo para preservar el presupuesto de tokens de la ventana de contexto bifurcando subtareas en ramas fuera del flujo de aviso principal y luego volviendo a unir los resultados agregados de esas bifurcaciones.
En lugar de sobrecargar un pequeño modelo de código abierto con una tarea demasiado compleja, divida el problema en un flujo lógico de subtareas viables.
decodificación restringida
- Mejorar el rendimiento
- reducir costos
- Mejorar el rendimiento de la tarea
Para aplicaciones que implican generar resultados estructurados (como objetos JSON), la decodificación restringida es una técnica poderosa que puede:
- Producción garantizada que se ajusta a la estructura requerida
- Mejore drásticamente el rendimiento acelerando la generación de tokens y reduciendo la cantidad de tokens que deben generarse.
- Mejore el desempeño de las tareas guiando modelos
Escribí un artículo separado que explica este tema en detalle: Una guía para la generación estructurada con decodificación restringida Los cómo, los porqués, las capacidades y los inconvenientes de generar resultados de modelos de lenguaje
Fundamentalmente, la decodificación de restricciones solo funciona con modelos de generación de texto que brindan acceso directo a la distribución completa de probabilidad del siguiente token, que no está disponible en ningún proveedor importante de LLM propietario en el momento de escribir este artículo.
OpenAI proporciona un esquema JSON , pero esta decodificación estrictamente restringida no garantiza ventajas estructurales o de rendimiento de la salida JSON.
La decodificación de restricciones va de la mano con las estrategias de flujo de control, ya que le permite dirigir de manera confiable un modelo de lenguaje grande a una ruta preespecificada al restringir su respuesta a diferentes opciones de bifurcación. Pedirle a un modelo que produzca respuestas breves y limitadas a una serie de largas preguntas de diálogo de varios turnos es muy rápido y económico (recuerde: la velocidad de rendimiento está determinada por la cantidad de tokens generados).
La decodificación de restricciones no tiene desventajas notables, por lo que si su tarea requiere una salida estructurada, debe usarla.
Almacenamiento en caché, cuantificación de modelos y otras optimizaciones de backend
- Mejorar el rendimiento
- reducir costos
- No afecta el desempeño de la tarea.
El almacenamiento en caché es una técnica que acelera las operaciones de recuperación de datos almacenando pares de entrada:salida de un cálculo y reutilizando los resultados si se vuelve a encontrar la misma entrada.
En sistemas que no son LLM, el almacenamiento en caché generalmente se aplica a solicitudes que coinciden exactamente con solicitudes vistas anteriormente. Algunos sistemas LLM también pueden beneficiarse de esta forma estricta de almacenamiento en caché, pero generalmente cuando se construye con LLM no queremos encontrar exactamente la misma entrada con demasiada frecuencia.
Afortunadamente, existen técnicas sofisticadas de almacenamiento en caché de valores clave específicas para LLM que son mucho más flexibles. Estas técnicas pueden acelerar enormemente la generación de texto para solicitudes que coinciden parcialmente, pero no exactamente, con la entrada vista anteriormente. Esto mejora el rendimiento del sistema al reducir la cantidad de tokens que deben generarse (o al menos acelerarlos, según la tecnología y el escenario de almacenamiento en caché específicos).
Con un LLM propietario, usted no tiene control sobre cómo se realiza o no el almacenamiento en caché de sus solicitudes. Pero para LLM de código abierto, existen varios marcos de backend para servicios LLM que pueden mejorar significativamente el rendimiento de inferencia y se pueden configurar de acuerdo con los requisitos personalizados de su sistema.
Además del almacenamiento en caché, existen otras optimizaciones LLM que se pueden utilizar para mejorar el rendimiento de la inferencia, como la cuantificación del modelo . Al reducir la precisión utilizada para los pesos de los modelos, el tamaño del modelo (y por lo tanto sus requisitos de memoria) se puede reducir sin comprometer significativamente la calidad de su salida. Los modelos populares suelen tener una gran cantidad de variantes cuantificadas disponibles en Hugging Face, aportadas por la comunidad de código abierto, lo que le evita tener que realizar el proceso de cuantificación usted mismo.
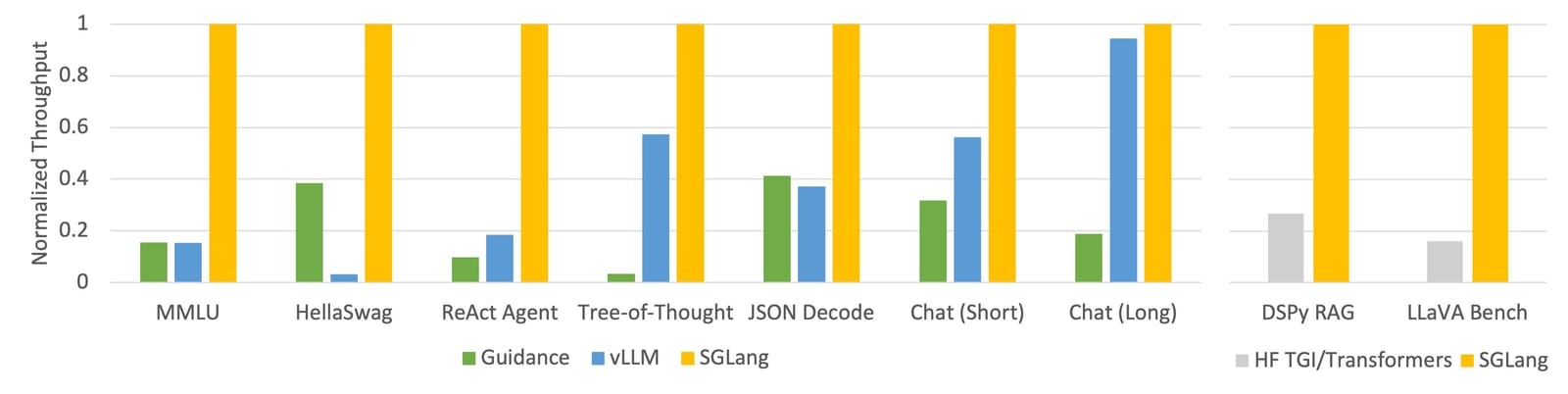
Anuncio de rendimiento sorprendente de SGLang (consulte la publicación del blog de lanzamiento de SGLang)
vLLM es probablemente el marco de servicio más maduro, con varios mecanismos de almacenamiento en caché, paralelización, optimización del kernel y métodos de cuantificación de modelos. SGLang es un reproductor más nuevo con una funcionalidad similar a vLLM, así como un innovador método de almacenamiento en caché RadixAttention que presume de un rendimiento particularmente impresionante.
Si aloja su modelo usted mismo, vale la pena utilizar estos marcos y técnicas de optimización, ya que puede esperar razonablemente mejorar el rendimiento en al menos un orden de magnitud.
Ajuste de modelos y destilación de conocimientos.
- Mejorar la eficiencia de ejecución de tareas
- No afecta los costos de razonamiento.
- No afecta el rendimiento
El ajuste fino abarca una variedad de técnicas para ajustar un modelo existente para que funcione mejor en una tarea específica. Recomiendo consultar la publicación del blog de Sebastian Raschka sobre métodos de ajuste como introducción al tema. La destilación de conocimientos es un concepto relacionado en el que se entrena un modelo de "estudiante" más pequeño para simular el resultado de un modelo de "maestro" más grande en la tarea de interés.
Algunos proveedores propietarios de LLM, incluido OpenAI , ofrecen capacidades mínimas de ajuste. Pero sólo los modelos de código abierto brindan control total sobre el proceso de ajuste y acceso a tecnologías integrales de ajuste.
El ajuste de los modelos puede mejorar significativamente el rendimiento de las tareas sin afectar el costo o el rendimiento de la inferencia. Pero implementar el ajuste requiere tiempo, habilidad y buenos datos, y el proceso de capacitación implica un costo. Las técnicas de ajuste eficiente de parámetros (PEFT), como LoRA, son particularmente atractivas porque ofrecen los mayores rendimientos de rendimiento en relación con la cantidad de recursos necesarios.
El ajuste fino y la destilación de conocimientos se encuentran entre las técnicas más poderosas para maximizar el rendimiento del modelo. Siempre que se implementen correctamente, no tienen inconvenientes, salvo la inversión inicial necesaria para ejecutarlos. Sin embargo, debe tener cuidado y asegurarse de que el ajuste fino se realice de manera coherente con otros aspectos del sistema, como el flujo de señales y las estructuras de salida de decodificación restringidas. Si existen diferencias entre estas tecnologías, puede producirse un comportamiento inesperado.
Optimizar el tamaño del modelo
Modelo pequeño:
- Mejorar el rendimiento
- reducir costos
- Reducir el rendimiento de ejecución de tareas
Esto también se puede definir como un "modelo más grande", con ventajas y desventajas opuestas. Los puntos clave son:
Haga que su modelo sea lo más pequeño posible pero mantenga la capacidad suficiente para comprender y completar la tarea de manera confiable.
La mayoría de los proveedores de LLM propietarios ofrecen algún tamaño de modelo/nivel de capacidad. Y cuando se trata de código abierto, hay opciones de modelos vertiginosas en todos los tamaños que desee, hasta más de 100 mil millones de parámetros.
Como se mencionó en la sección de conversación de varios turnos, podemos simplificar tareas complejas dividiéndolas en una serie de subtareas más manejables. Pero siempre habrá un problema que no se puede desglosar más, o que hacerlo comprometería aspectos de la misión que deben abordarse más plenamente. Esto depende en gran medida del caso de uso, pero la granularidad y complejidad de la tarea tendrán un punto óptimo que dicta el tamaño correcto del modelo, como lo demuestra lograr un rendimiento adecuado de la tarea en el tamaño de modelo más pequeño.
Para algunas tareas, esto significa utilizar el modelo más grande y capaz que pueda encontrar; para otras tareas, es posible que pueda utilizar un modelo muy pequeño (incluso uno que no sea LLM).
En cualquier caso, elija utilizar el mejor modelo de su clase para cualquier tamaño de parámetro determinado. Esto se puede identificar mediante referencia a puntos de referencia y clasificaciones públicas , que cambian periódicamente en función del rápido ritmo de desarrollo en el campo. Algunos puntos de referencia son más adecuados para su caso de uso que otros, por lo que vale la pena descubrir cuáles funcionan mejor.
Pero no crea que puede simplemente reemplazar el nuevo mejor modelo y lograr una mejora inmediata en el rendimiento. Los diferentes modelos tienen diferentes modos de falla y características, por lo que un sistema optimizado para un modelo no necesariamente funcionará para otro, incluso si debería ser mejor.
hoja de ruta tecnológica
Como se mencionó anteriormente, todas estas estrategias son complementarias y, cuando se combinan, se combinan para producir un sistema sólido e integral. Pero existen dependencias entre estas tecnologías y es importante garantizar que sean consistentes para evitar disfunciones.
La siguiente figura es un diagrama de dependencia que muestra la secuencia lógica para implementar estas tecnologías. Esto supone que el caso de uso requiere generar una salida estructurada.
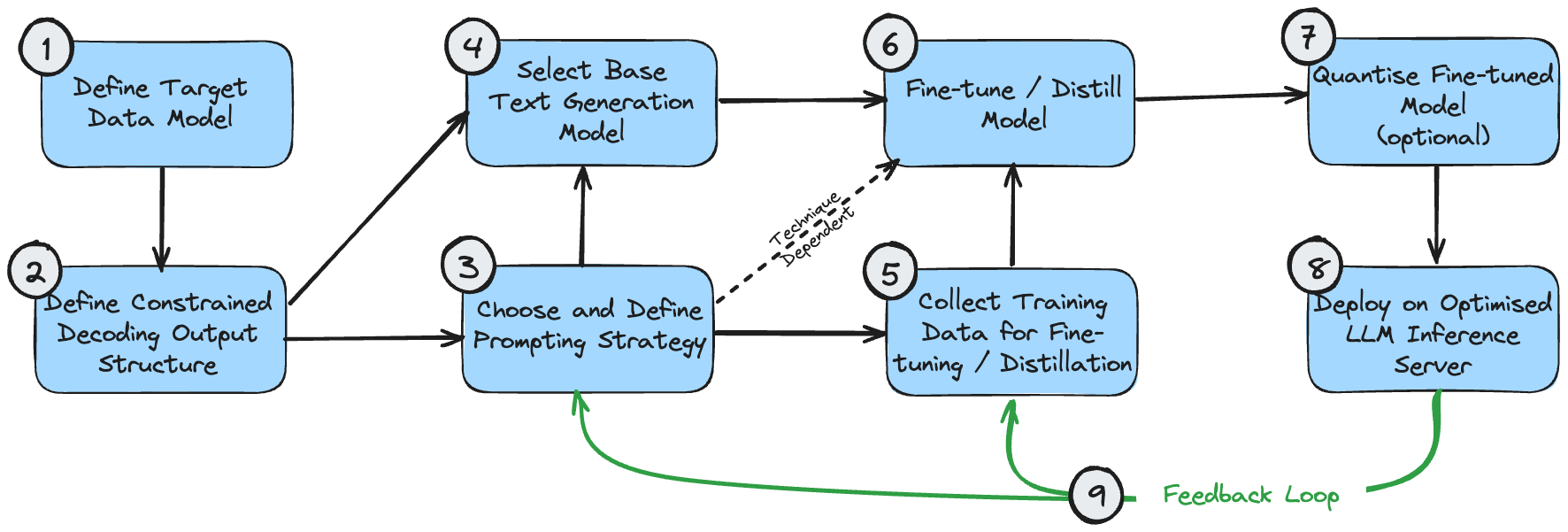
Estas etapas se pueden entender de la siguiente manera:
- El modelo de datos de destino es el resultado final que desea crear. Esto está determinado por su caso de uso y los requisitos más amplios del sistema general más allá de generar procesamiento de texto.
- La estructura de salida de decodificación restringida puede ser la misma que su modelo de datos de destino o puede modificarse ligeramente para lograr un rendimiento óptimo durante la decodificación restringida. Consulte mi artículo sobre decodificación restringida para comprender por qué sucede esto. Si es diferente, se requiere una etapa de posprocesamiento para transformarlo en el modelo de datos objetivo final.
- Debe hacer una mejor estimación inicial de la estrategia de indicación correcta para su caso de uso. Si el problema es simple o no se puede desglosar intuitivamente, elija una única estrategia rápida. Si el problema es muy complejo, con muchos subcomponentes detallados, elija una estrategia de múltiples indicaciones.
- La selección inicial del modelo es principalmente una cuestión de optimizar el tamaño y garantizar que las propiedades del modelo cumplan con los requisitos funcionales del problema. Los tamaños óptimos de los modelos se analizan anteriormente. Las propiedades del modelo, como la longitud requerida de la ventana de contexto, se pueden calcular en función de la estructura de salida esperada ((1) y (2)) y la estrategia de solicitud (3).
- Los datos de entrenamiento utilizados para el ajuste del modelo deben ser coherentes con la estructura de salida (2). Si se utiliza una estrategia de múltiples señales que genera el resultado paso a paso, los datos de entrenamiento también deben reflejar cada etapa de este proceso.
- El ajuste fino/destilación del modelo depende naturalmente de la selección del modelo, la curación de los datos de entrenamiento y el flujo rápido.
- La cuantificación de modelos ajustados es opcional. Sus opciones de cuantificación dependerán del modelo base que elija.
- El servidor de inferencia LLM solo admite arquitecturas de modelos y métodos de cuantificación específicos, así que asegúrese de que su selección anterior sea compatible con la configuración de backend deseada.
- Una vez que tenga implementado un sistema de extremo a extremo, puede crear un circuito de retroalimentación para la mejora continua. Debe ajustar periódicamente las indicaciones y los ejemplos de algunas tomas (si los está utilizando) para tener en cuenta los ejemplos en los que el sistema no produce resultados aceptables. Una vez que haya acumulado una muestra razonable de casos de falla, también debería considerar usar estas muestras para realizar más ajustes del modelo.
En realidad, el proceso de desarrollo nunca es completamente lineal y, según el caso de uso, es posible que deba priorizar la optimización de algunos de estos componentes sobre otros. Pero es una base razonable a partir de la cual diseñar una hoja de ruta basada en sus requisitos específicos.
en conclusión
Los modelos de código abierto pueden ser más rápidos, más baratos y mejores que los LLM propietarios. Esto se puede lograr diseñando sistemas más complejos que aprovechen las fortalezas únicas de los modelos de código abierto y hagan concesiones apropiadas entre rendimiento, costo y desempeño de la misión.
Esta elección de diseño cambia la complejidad del sistema por el rendimiento general. Una alternativa válida es tener un sistema más simple e igualmente potente impulsado por un LLM patentado, pero a un costo mayor y un rendimiento menor. La decisión correcta depende de su aplicación, su presupuesto y la disponibilidad de sus recursos de ingeniería.
Pero no abandone los modelos de código abierto demasiado rápido sin adaptar su estrategia tecnológica para adaptarse a ellos; es posible que se sorprenda de lo que pueden hacer.
Decidí renunciar al software industrial de código abierto. Eventos importantes: se lanzó OGG 1.0, Huawei contribuyó con todo el código fuente y se lanzó oficialmente Ubuntu 24.04. El equipo de la Fundación Google Python fue despedido por la "montaña de código de mierda" . ". Se lanzó oficialmente Fedora Linux 40. Una conocida compañía de juegos lanzó Nuevas regulaciones: los obsequios de boda de los empleados no deben exceder los 100.000 yuanes. China Unicom lanza la primera versión china Llama3 8B del mundo del modelo de código abierto. Pinduoduo es sentenciado a compensar 5 millones de yuanes por competencia desleal. Método de entrada en la nube nacional: solo Huawei no tiene problemas de seguridad para cargar datos en la nube.Este artículo se publicó por primera vez en Yunyunzhongsheng ( https://yylives.cc/ ), todos son bienvenidos a visitarlo.