[1] Conceptos y cálculos relacionados de pagaré en la detección de objetivos
IoU (Intersection over Union) es un módulo importante en la tarea de detección de objetivos, es el área de intersección de GT bbox y pred bbox / el área de unión de los dos .
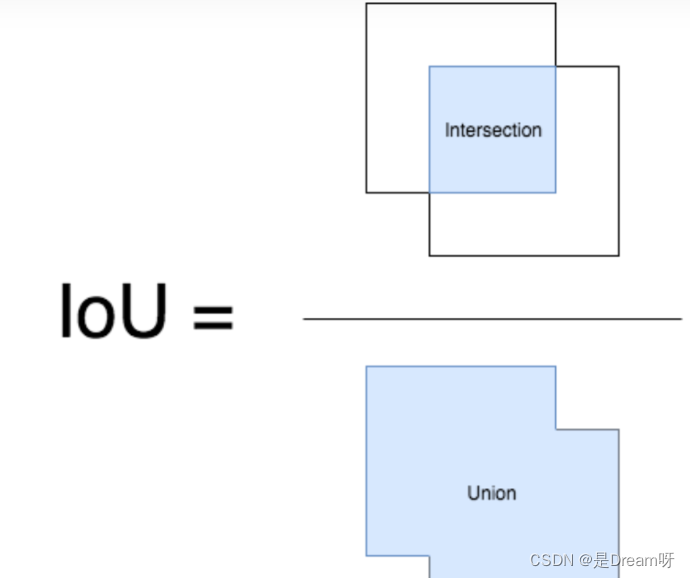
A continuación usamos coordenadas (arriba, izquierda, abajo, derecha), es decir, las coordenadas de la esquina superior izquierda y las coordenadas de la esquina inferior derecha. Por tanto, el valor del pagaré se puede calcular en los dos rectángulos dados.
def compute_iou(rect1,rect2):
# (y0,x0,y1,x1) = (top,left,bottom,right)
S_rect1 = (rect1[2] - rect1[0]) * (rect1[3] - rect1[1])
S_rect2 = (rect2[2] - rect2[0]) * (rect2[3] - rect1[1])
sum_all = S_rect1 + S_rect2
left_line = max(rect1[1],rect2[1])
right_line = min(rect1[3],rect2[3])
top_line = max(rect1[0],rect2[0])
bottom_line = min(rect1[2],rect2[2])
if left_line >= right_line or top_line >= bottom_line:
return 0
else:
intersect = (right_line - left_line) * (bottom_line - top_line)
return (intersect / (sum_area - intersect)) * 1.0
[2] Conceptos y cálculos relacionados de NMS en la detección de objetivos.
En la detección de objetivos, podemos utilizar la supresión no máxima (NMS) para posprocesar una gran cantidad de fotogramas candidatos generados, eliminar fotogramas candidatos redundantes y obtener los resultados más representativos para acelerar la eficiencia de la detección de objetivos.
Como se muestra en la siguiente figura, elimine los cuadros candidatos redundantes y encuentre el mejor bbox:

Proceso de supresión no máxima (NMS):
-
Primero necesitamos establecer dos valores: un umbral de puntuación y un umbral de pagaré.
-
Para cada tipo de objeto, recorra todos los cuadros candidatos de esa clase, filtre los cuadros candidatos cuyo valor de puntuación sea inferior al umbral de puntuación y ordene los cuadros candidatos según su probabilidad de clasificación de categoría: A < B < C < D < E < FA < B < C < D < E < FA<B<C<D<mi<F. _
-
Primero marque el cuadro rectangular de máxima probabilidad F como el cuadro candidato que queremos retener.
-
A partir del marco rectangular de máxima probabilidad F, se juzga si la relación de intersección y unión (IOU) de A a E y F es mayor que el umbral de IOU. Suponiendo que la superposición entre B, D y F excede el umbral de IOU, entonces Se eliminan B y D.
-
De los cuadros rectangulares restantes A, C y E, seleccione el E con mayor probabilidad y márquelo como cuadro candidato a retener, luego determine la superposición entre E, A y C, y elimine los cuadros rectangulares cuya superposición exceda el umbral establecido.
-
Repita esto hasta que no queden más cuadros rectangulares y marque todos los cuadros rectangulares que desee conservar.
-
Después de procesar cada categoría, regrese al paso 2 para procesar nuevamente la siguiente categoría de objetos.
import numpy as np
def py_cpu_nms(dets, thresh):
#x1、y1(左下角坐标)、x2、y2(右上角坐标)以及score的值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个候选框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照score降序排序(保存的是索引)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
#计算当前概率最大矩形框与其他矩形框的相交框的坐标,会用到numpy的broadcast机制,得到向量
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交框的面积,注意矩形框不相交时w或h算出来会是负数,用0代替
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算重叠度IOU:重叠面积 / (面积1 + 面积2 - 重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#找到重叠度不高于阈值的矩形框索引
inds = np.where(ovr < thresh)[0]
# 将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要加1操作
order = order[inds + 1]
return keep
[3] ¿Cuál es la diferencia entre la detección de objetivos en una etapa y la detección de objetivos en dos etapas?
Algoritmo de detección de objetivos de dos etapas : primero genera una propuesta de región (RP) (un cuadro preseleccionado que puede contener el objeto a detectar) y luego clasifica la muestra a través de una red neuronal convolucional. Su precisión es mayor y su velocidad es más lenta.
Lógica principal: Extracción de características -> Generar RP -> Regresión de clasificación/posicionamiento.
Los algoritmos comunes de detección de objetivos de dos etapas incluyen: series R-CNN y R-FCN más rápidas, etc.
Algoritmo de detección de objetivos de una etapa : sin RP, las características se extraen directamente de la red para predecir la clasificación y ubicación de los objetos. Es más rápido y tiene una precisión ligeramente menor que el algoritmo de dos etapas.
Lógica principal: extracción de características -> regresión de clasificación/posicionamiento.
Los algoritmos comunes de detección de objetivos de una etapa incluyen: serie YOLO, SSD y RetinaNet, etc.
【4】 ¿Qué métodos pueden mejorar el efecto de la detección de objetivos pequeños?
-
Mejorar la resolución de la imagen. Los objetos pequeños pueden contener solo unos pocos píxeles en el cuadro delimitador, por lo que la riqueza de funciones de los objetos pequeños se puede aumentar aumentando la resolución de la imagen.
-
Aumente la resolución de entrada del modelo. Este es un método general con mejor efecto, pero traerá el problema de una velocidad de inferencia del modelo más lenta.
-
Imágenes de mosaicos.

-
Aumento de datos. La mejora de la detección de objetivos pequeños incluye recorte aleatorio, rotación aleatoria y mejora del mosaico.
-
Aprenda automáticamente el ancla.
-
Optimización de categorías.
[5] ¿Cuáles son las características del modelo ResNet y los problemas que resuelve?
Cada vez que responda a esta pregunta incluiré mi egoísmo, me gusta explicarlo desde la perspectiva de la automatización eléctrica más que desde la perspectiva de las computadoras, porque me recuerda mis años verdes en la universidad.
ResNet es un amplificador diferencial . El diseño estructural y la lógica ideológica de ResNet es abstraer un amplificador diferencial en el aprendizaje automático, que puede mejorar la correlación de los gradientes de la red profunda y resaltar pequeños cambios durante la retropropagación del gradiente.
La característica del modelo es la estructura residual diseñada, que es muy sensible a pequeños cambios en la salida del modelo.
¿Por qué tiene efecto agregar el módulo residual?
Supuesto: Si no se utiliza el módulo residual, la salida es F 1 ( x ) = 5,1 F_{1} (x) = 5,1F1( X )=5.1 , el resultado esperado esH 1 ( x ) = 5 H_{1} (x) = 5h1( X )=5 , si quieres aprender la función H tal queF 1 ( x ) = H 1 ( x ) = 5 F_{1} (x) = H_{1} (x) = 5F1( X )=h1( X )=5. Esta tasa de cambio es relativamente baja y es difícil de aprender.
Pero si el diseño es H 1 ( x ) = F 1 ( x ) + 5 = 5.1 H_{1} (x) = F_{1} (x) + 5 = 5.1h1( X )=F1( X )+5=5.1 , realice una división tal queF 1 ( x ) = 0.1 F_ {1} (x) = 0.1F1( X )=0.1 , entonces el objetivo de aprendizaje es dejar queF 1 (x) = 0 F_ {1} (x) = 0F1( X )=0 , se aprende una función de mapeo para que su salida cambie de 0,1 a 0. Esto es relativamente simple. En otras palabras, el mapeo después de introducir el módulo residual es más sensible a los cambios de salida.
Comprensión adicional: si F 1 ( x ) = 5,1 F_ {1} (x) = 5,1F1( X )=5.1 , ahora continúe entrenando el modelo para que la función de mapeoF 1 ( x ) = 5 F_ {1} (x) = 5F1( X )=5 . Tasa de cambio:(5,1 − 5) / 5,1 = 0,02 (5,1 - 5) / 5,1 = 0,02( 5.1−5 ) /5.1=0,02 Si no se utiliza el módulo residual, la tasa de aprendizaje se puede establecer entre 0,01 y 0,0000001. Aún se puede solucionar si el número de capas es bajo, pero una vez que se profundiza el número de capas, puede que no sea fácil de usar.
Si se utiliza el módulo residual en este momento, es decir, F 1 ( x ) = 0,1 F_ {1} (x) = 0,1F1( X )=0.1 cambia aF 1 ( x ) = 0 F_{1} (x) = 0F1( X )=0 . Esta tasa de cambio aumentó en un 100%. Obviamente, esto tendrá un mayor efecto en el ajuste de las ponderaciones de los parámetros.
[6] ¿Cuáles son la estructura y características del modelo ResNeXt?
El modelo ResNeXt está optimizado en función del modelo ResNet. Su objetivo principal es introducir la idea de Inception en ResNeXt. Como se muestra en la figura siguiente, el lado izquierdo es la estructura clásica de ResNet y el lado derecho es la estructura ResNeXt, que convierte la convolución de un solo canal en convolución multicanal multicanal para convolución agrupada .
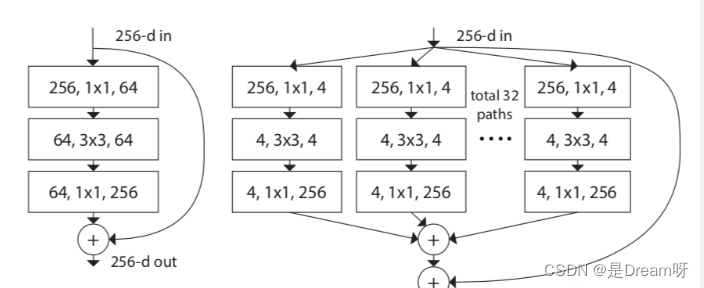
El autor propuso además tres estructuras equivalentes de ResNeXt, entre las cuales me vino a la mente la idea de convolución agrupada en la estructura c.
Finalmente, echemos un vistazo al cuadro comparativo de las diferencias estructurales entre ResNeXt50 y ResNet50:
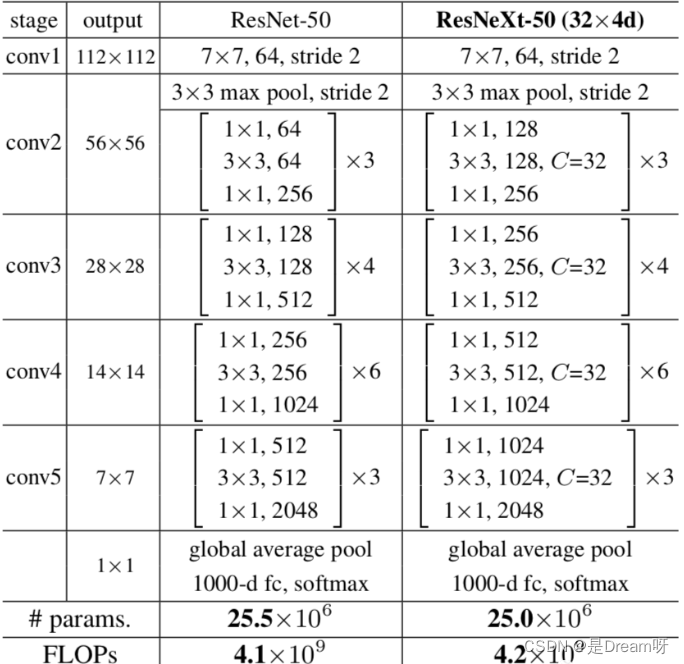
ResNeXt论文:《Transformaciones residuales agregadas para redes neuronales profundas》
[7] ¿Cuáles son las estructuras y características de los modelos de la serie MobileNet?
MobileNet es una estructura de red liviana diseñada principalmente para dispositivos integrados como teléfonos móviles. La estructura de red MobileNetv1 utiliza convolución separable en profundidad sobre la base de VGG, lo que reduce en gran medida la cantidad de parámetros del modelo y al mismo tiempo garantiza no perder demasiada precisión.
La convolución separable en profundidad se compone de convolución en profundidad y convolución puntual.
La convolución en profundidad (DW) puede reducir eficazmente la cantidad de parámetros y mejorar la velocidad de operación. Sin embargo, dado que cada mapa de características está convolucionado por solo un núcleo de convolución, el mapa de características generado por DW solo contiene toda la información del mapa de características de entrada y la información entre características no se puede comunicar, lo que resulta en un "flujo de información deficiente". La convolución puntual (PW) realiza el intercambio de información de características del canal y resuelve el problema del "flujo de información deficiente" causado por la convolución DW.
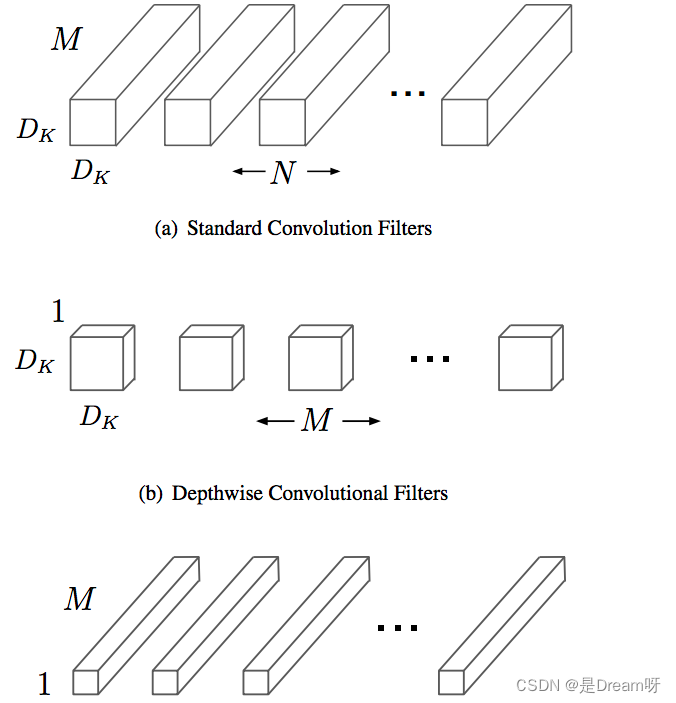
Comparación de la cantidad de cálculo de la convolución separable en profundidad y la convolución estándar:
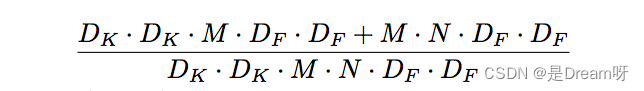
En comparación con la convolución estándar, la convolución separable en profundidad puede reducir en gran medida la cantidad de cálculo. Y a medida que aumenta el número de canales convolucionales, el efecto se vuelve más obvio.
Además, Mobilenetv1 usa la convolución stride=2 para reemplazar la operación de agrupación , y usa directamente stride=2 para completar la reducción de resolución durante la convolución, ahorrando así el tiempo de usar la operación de agrupación para realizar la reducción de resolución después de la convolución, lo que puede mejorar la velocidad de cálculo.
MobileNetv1论文:《MobileNets: redes neuronales convolucionales eficientes para aplicaciones de visión móvil》
[8] ¿Cuáles son las estructuras y características de los modelos de la serie MobileNet? (dos)
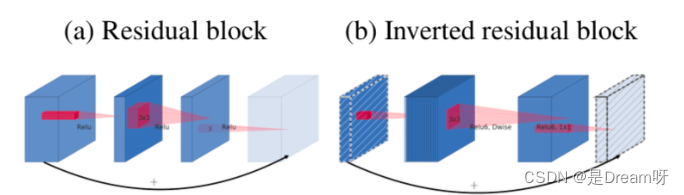
MobileNetV2 presenta cuellos de botella lineales y residuos invertidos basados en MobileNetV1 .
MobileNetV2 utiliza Linear Bottleneck (transformación lineal) en lugar de la función de activación no lineal original para capturar la variedad de interés. Los experimentos han demostrado que el uso de Linear Bottleneck puede retener mejor información útil sobre funciones en redes pequeñas.
Los residuales invertidos son exactamente lo opuesto a la operación entre canales del módulo residual ResNet clásico. Dado que MobileNetV2 utiliza una estructura de cuello de botella lineal, las dimensiones de las características extraídas son generalmente bajas. Si solo usa un mapa de características de baja dimensión, el efecto no será bueno. Si todas las capas convolucionales utilizan mapas de características de baja dimensión para extraer características, entonces no habrá forma de extraer suficiente información general. Si queremos extraer información completa sobre las características, debemos complementarla con un mapa de características de alta dimensión para lograr el equilibrio.
MobileNetV2的论文:《MobileNetV2: residuos invertidos y cuellos de botella lineales》
MobileNetV3 presenta dos grandes innovaciones en su conjunto :
1. Combinación de tecnología de búsqueda complementaria: el NAS de recursos limitados realiza una búsqueda a nivel de módulo, NetAdapt realiza una búsqueda local y afina la capa de red después de determinar cada módulo.
2. Mejora de la estructura de la red: reduzca aún más la cantidad de capas de red e introduzca la función de activación h-swish.
El autor descubrió que la función de activación rápida puede mejorar efectivamente la precisión de la red. Sin embargo, el swish requiere demasiado cálculo. El autor propuso h-swish (versión dura de swish) de la siguiente manera:
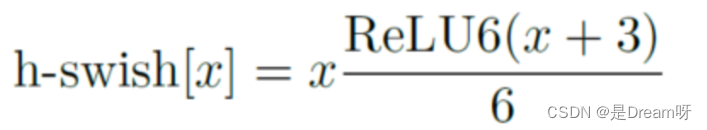
Esta no linealidad aporta muchas ventajas al tiempo que mantiene la precisión. En primer lugar, ReLU6 se puede implementar en muchos marcos de software y hardware. En segundo lugar, evita la pérdida de precisión numérica durante la cuantificación y se ejecuta rápidamente.
Optimización de la estructura del modelo MobileNetV3:
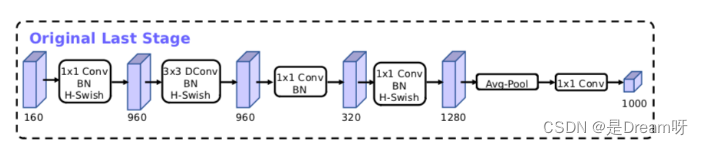
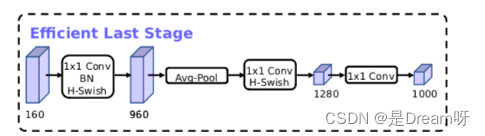
Documento de MobileNetV3: "Buscando MobileNetV3"
[9] ¿Cuáles son las estructuras y características del modelo ViT (Vision Transformer)?
Características del modelo ViT :
1. ViT utiliza directamente la estructura Transformer estándar para la clasificación de imágenes y su estructura de modelo no contiene CNN.
2. Para cumplir con los requisitos de la estructura de entrada del Transformador, el extremo de entrada divide la imagen completa en pequeños bloques de imágenes y luego ingresa la secuencia de incrustación lineal de estos pequeños bloques de imágenes en la red. En la salida final, el formulario Class Token se utiliza para la predicción de clasificación.
3. El transformador tiene menos invariancia de traducción y perceptibilidad local que la estructura CNN. Cuando la cantidad de datos es pequeña, el efecto puede no ser tan bueno como el modelo CNN. Sin embargo, después de un entrenamiento previo en un conjunto de datos a gran escala y luego realizar la transferencia Al aprender, puede lograr el rendimiento SOTA en tareas específicas.
La estructura general del modelo de ViT :
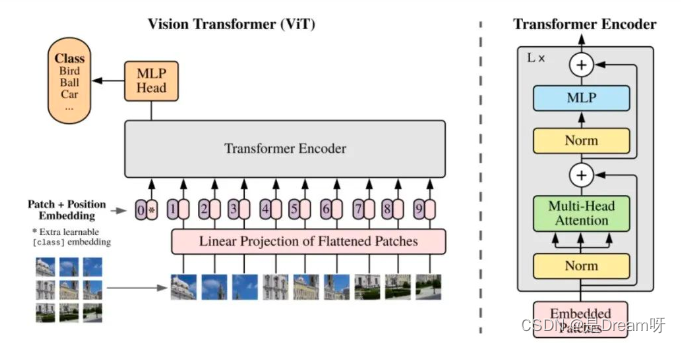
Se puede dividir específicamente en las siguientes partes:
-
Incrustación de bloques de imágenes
-
estructura de atención multidireccional
-
Estructura de perceptrón multicapa (MLP)
-
Utilice operaciones como DropPath, Class Token, codificación posicional, etc.
[10] ¿Cuáles son las estructuras y características de los modelos de la serie EfficientNet?
El modelo de la serie Efficientnet es un modelo que se obtiene ajustando la búsqueda desde tres perspectivas: profundidad, ancho y resolución de la imagen de entrada mediante búsqueda en cuadrícula. Desde la versión EfficientNet-B0 hasta la versión EfficientNet-L2, la precisión del modelo es cada vez mayor y, de manera similar, también aumentará la cantidad de parámetros y requisitos de memoria.
La escala del modelo de profundidad está determinada principalmente por los parámetros de escala de las tres dimensiones de ancho, profundidad y resolución. Estas tres dimensiones no son independientes entre sí. Para el caso en que la resolución de la imagen de entrada es mayor, se necesita una red más profunda para obtener un campo de visión más grande. De manera similar, para imágenes de mayor resolución, se necesitan más canales para obtener características más precisas .
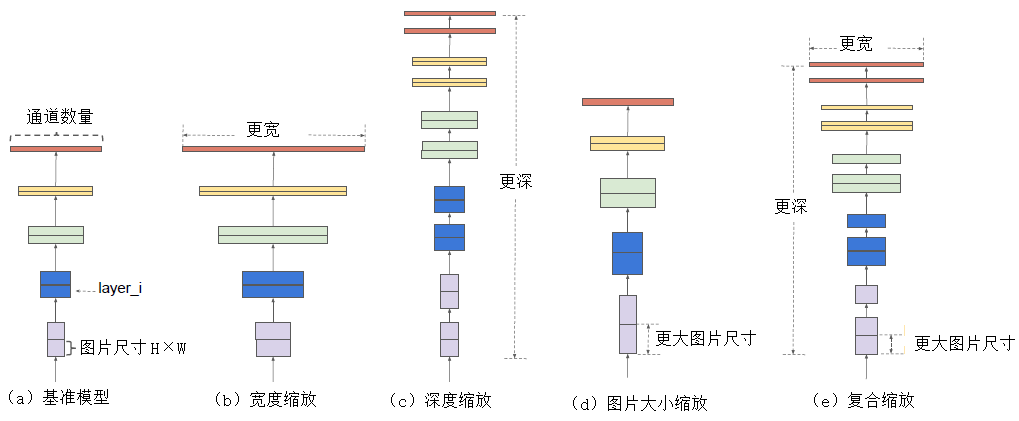
El interior del modelo EfficientNet se implementa a través de múltiples módulos de convolución MBConv. La estructura específica de cada módulo de convolución MBConv se muestra en la siguiente figura. Se ha demostrado experimentalmente que la convolución separable en profundidad sigue siendo muy efectiva en modelos grandes; la convolución separable en profundidad tiene mejores capacidades de extracción y expresión de características que la convolución estándar .
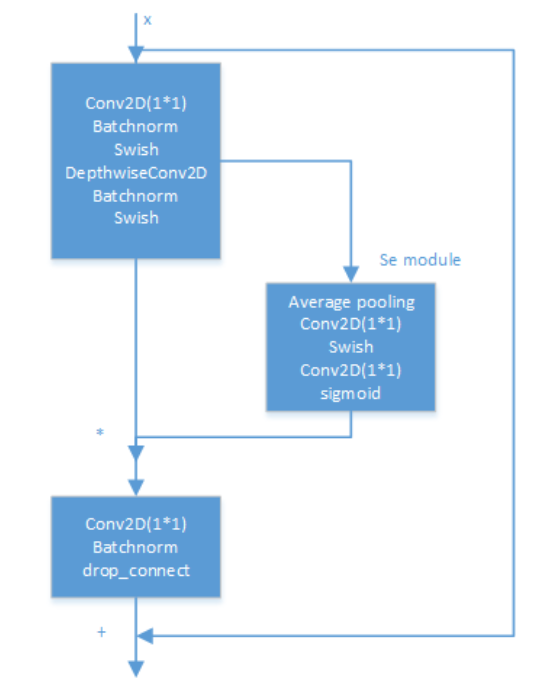
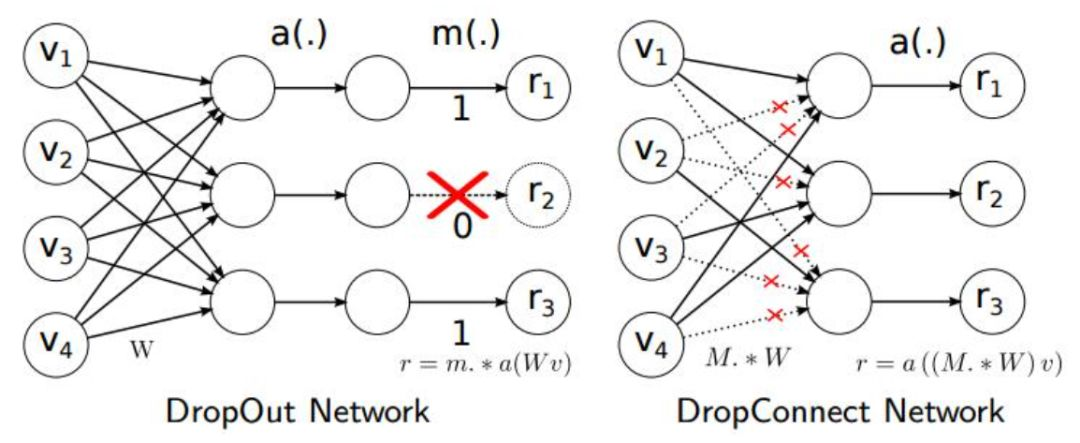
Además, el método Drop_Connect se utiliza en el artículo para reemplazar el método Dropout tradicional para evitar el sobreajuste del modelo. La diferencia entre DropConnect y Dropout es que en el proceso de entrenamiento del modelo de red neuronal, no descarta aleatoriamente la salida de los nodos de la capa oculta, sino que descarta aleatoriamente la entrada de los nodos de la capa oculta.
EfficientNet论文:《EfficientNet: Repensar el escalado de modelos para redes neuronales convolucionales》
Para hacer una digresión, puede ver el asfixiante proceso de ajuste de parámetros del autor a través del artículo. . .
[11] ¿Modelo clásico de preguntas frecuentes en las entrevistas?
A menudo se hacen preguntas sobre modelos durante las entrevistas. Esta también es una pregunta que no es fácil de cuantificar porque los modelos son complejos y diversos. Es posible que el entrevistador haga cualquier pregunta. En el diagrama lógico a continuación, he enumerado algunas preguntas. que son útiles en campos académicos, tanto el mundo como la industria son modelos de alto valor para referencia de todos.
Es mejor pulir su currículum con más proyectos, concursos, investigaciones científicas, etc., y dirigir las preguntas relacionadas con los modelos durante el proceso de entrevista a modelos familiares utilizados en estos trabajos.
【12】¿Cuál es el papel de la pérdida focal?
Focal Loss es una función de pérdida que resuelve el desequilibrio de categorías y las diferencias en la dificultad de clasificación en problemas de clasificación, permitiendo que el modelo se centre más en muestras difíciles durante el proceso de entrenamiento.
Focal Loss comienza con problemas de dos clasificaciones y la misma idea se puede transferir a problemas de clasificaciones múltiples.
Sabemos que la pérdida estándar para los problemas de clasificación binaria es la entropía cruzada :
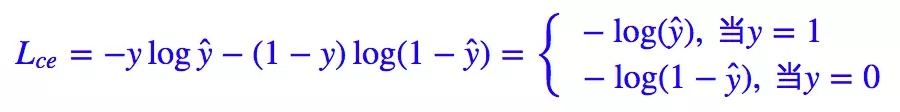
Para problemas de clasificación binaria, casi aplicamos la función de activación sigmoidea y ^ = σ ( x ) \hat{y} = \sigma(x)y^=σ ( x ) , por lo que la fórmula anterior se puede transformar en:
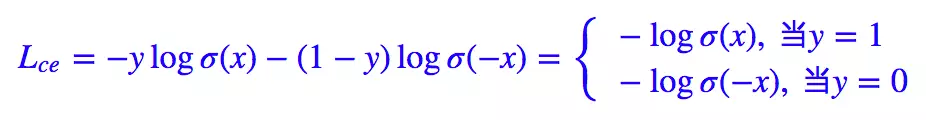
Aquí tenemos 1 − σ ( x ) = σ ( − x ) 1 - \sigma(x) = \sigma(-x)1−σ ( x )=σ ( - x ) .
La fórmula dada en el artículo sobre pérdida focal es la siguiente:

donde y ∈ { 1 , − 1 } y\in \{ 1,-1\}y∈{ 1 ,− 1 } es la etiqueta real,p ∈ [ 0 , 1 ] p\in[0,1]pag∈[ 0 ,1 ] es la probabilidad prevista.
Luego definimos pt: p_{t}:pagt:

Luego, la fórmula de entropía cruzada anterior se puede convertir en:

Con la base anterior, el artículo inicial sobre pérdida focal introdujo la función de entropía cruzada equilibrada :

Para abordar el problema del desequilibrio de categorías, se agrega un peso de control a la pérdida. Para muestras que pertenecen a la categoría minoritaria, se aumenta α t \alpha_{t} .atEso es todo. Pero esto tiene un problema: solo resuelve el problema del equilibrio entre muestras positivas y negativas, y no distingue entre muestras fáciles y difíciles .
¿Por qué la fórmula anterior solo resuelve el problema del desequilibrio entre muestras positivas y negativas?
Porque se suma un coeficiente α t \alpha_{t}at, seguido de pt p_{t}pagtLa definición es similar, cuando etiqueta = 1 etiqueta = 1etiqueta _ _ _=Cuando 1 , α t = α \alpha_{t}=\alphaat=α ;当etiqueta = − 1 etiqueta=-1etiqueta _ _ _=Cuando − 1 , α t = 1 − α \alpha_{t}= 1 - \alphaat=1−α ,α \alfaEl rango de α también es [0, 1] [0,1][ 0 ,1 ] . Por lo tanto, podemos establecerα \alphavalor de α (si1 11El número de muestras en esta categoría se compara con− 1 -1− 1El número de muestras en esta categoría es mucho menor, entoncesα \alphaα se puede tomar como0,5 0,50,5 a1 11 para aumentar1 11El peso de las muestras de esta clase) para controlar la contribución de las muestras positivas y negativas a la pérdida general.
Pérdida focal
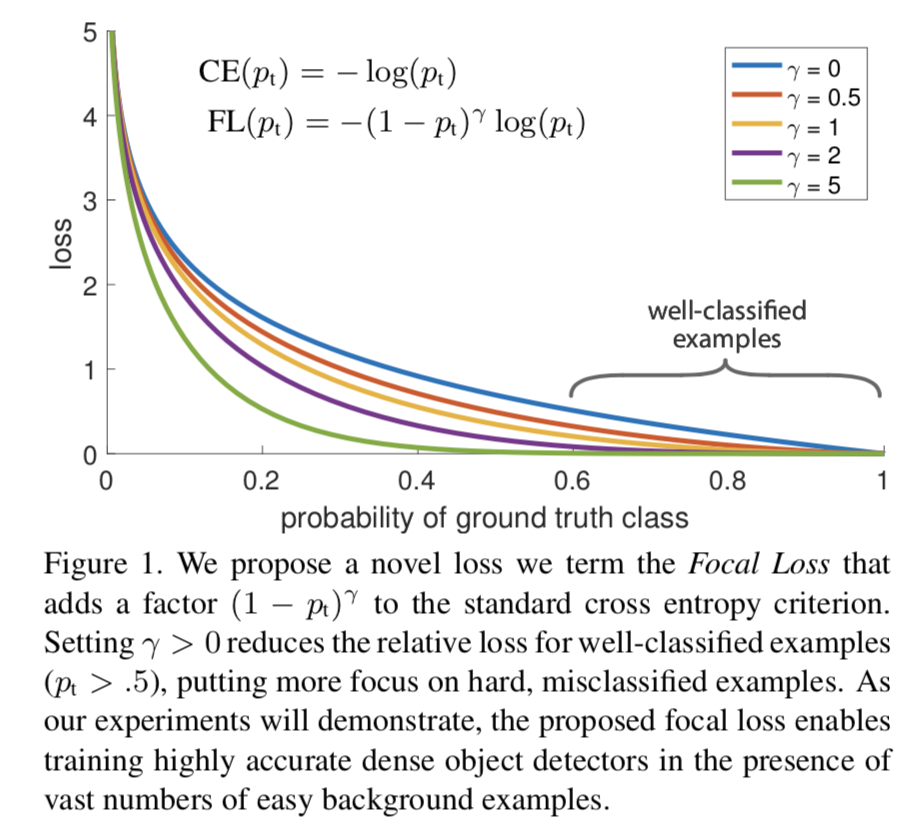
Para distinguir muestras difíciles/fáciles, apareció el prototipo de Focal Loss:

( 1 − pt ) γ (1 - p_{t})^{\gamma}( 1−pagt)γ se utiliza para equilibrar la proporción desigual de muestras difíciles y fáciles,γ > 0 \gamma >0C>0 desempeña el papel de(1 − pt) (1 - p_{t})( 1−pagt) efecto de amplificación. γ > 0 \gamma >0C>0 reduce la pérdida de muestras fácilmente clasificadas, lo que permite que el modelo se centre más en muestras que son difíciles de clasificar y que fácilmente se clasifican erróneamente. Por ejemplo, cuandoγ = 2 \gamma =2C=2 , el modelo predice la confianzapt p_{t}pagtes 0,9 0,90,9 , entonces( 1 − 0,9 ) γ = 0,01 (1 - 0,9)^{\gamma} = 0,01( 1−0,9 )C=0.01 , es decir, el valor de FL se vuelve muy pequeño; y cuando el modelo predice el nivel de confianzapt p_{t}pagtCuando 0,3, ( 1 − 0,3 ) γ = 0,49 (1 - 0,3)^{\gamma} = 0,49( 1−0.3 )C=0,49 , en este momento su contribución a la pérdida aumenta. Cuandoγ = 0 \gamma = 0C=Cuando es 0 , se convierte en pérdida de entropía cruzada.
Para abordar el problema del desequilibrio entre muestras positivas y negativas, se agrega α t \alpha_{t} de entropía cruzada equilibrada a la fórmula anterior.atFactor, utilizado para equilibrar la proporción desigual de muestras positivas y negativas, y finalmente obtener la pérdida focal:
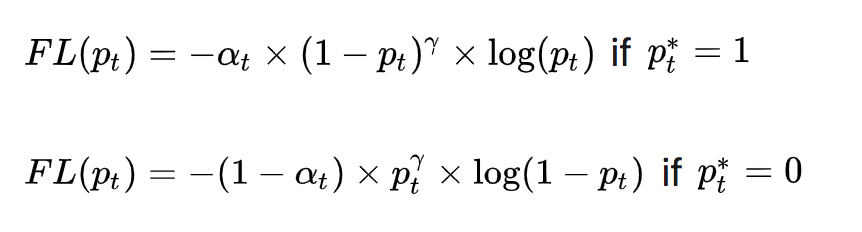
El valor experimental óptimo dado en el artículo sobre pérdida focal es = 0,25 a_ {t} = 0,25at=0,25,γ = 2 \gamma = 2C=2 .
[14] ¿Cuáles son los modelos clásicos de detección de rostros livianos?
La detección de rostros es una subtarea en comparación con la detección general de objetivos. En comparación con la tarea de detección de objetivos general que detecta 1000 categorías en cada turno, la tarea de detección de rostros se centra principalmente en la detección de rostros de un solo tipo. Usar un modelo de detección de objetivos general es demasiado extravagante y se siente un poco como "matar un pollo con un "mazo" y tiene una gran cantidad de parámetros. La redundancia afectará la practicidad del lado de implementación . Por lo tanto, para las tareas de detección de rostros, la comunidad académica ha propuesto muchos modelos livianos de detección de rostros. Rocky presentará algunos representativos aquí:
- detección de caralibros
- Detector-de-caras-genérico-ultraligero-rápido-1MB
- Un-detector-de-rostros-ligero-y-rápido-para-dispositivos-de-borde-
- Cara central
- DBCara
- RetinaCara
- MTCNN
[15] ¿Cuáles son las estructuras y características del modelo de detección de rostros LFFD?
A Rocky se le preguntó muchas veces sobre el modelo LFFD durante las entrevistas de reclutamiento de pasantías/campus y la situación en la que el entrevistador quería extraer soluciones algorítmicas relacionadas con LFFD, lo que demuestra que el modelo LFFD sigue siendo bastante valioso en la industria . Ahora Rocky llevará a todos a aprenda sobre el modelo LFFD.conocimiento:
LFFD (un detector de rostros ligero y rápido para dispositivos de borde) es adecuado para tareas de detección de objetivos únicos, como rostros, peatones y vehículos. Tiene las características de velocidad rápida, modelo pequeño y buen efecto. . LFFD es un método sin anclajes. Utiliza campos receptivos en lugar de anclajes y extrae mapas de características de 8 vías en la estructura principal para detectar rostros de pequeños a grandes. El módulo de detección se divide en dos categorías y regresión del cuadro delimitador .
Estructura del modelo LFFD
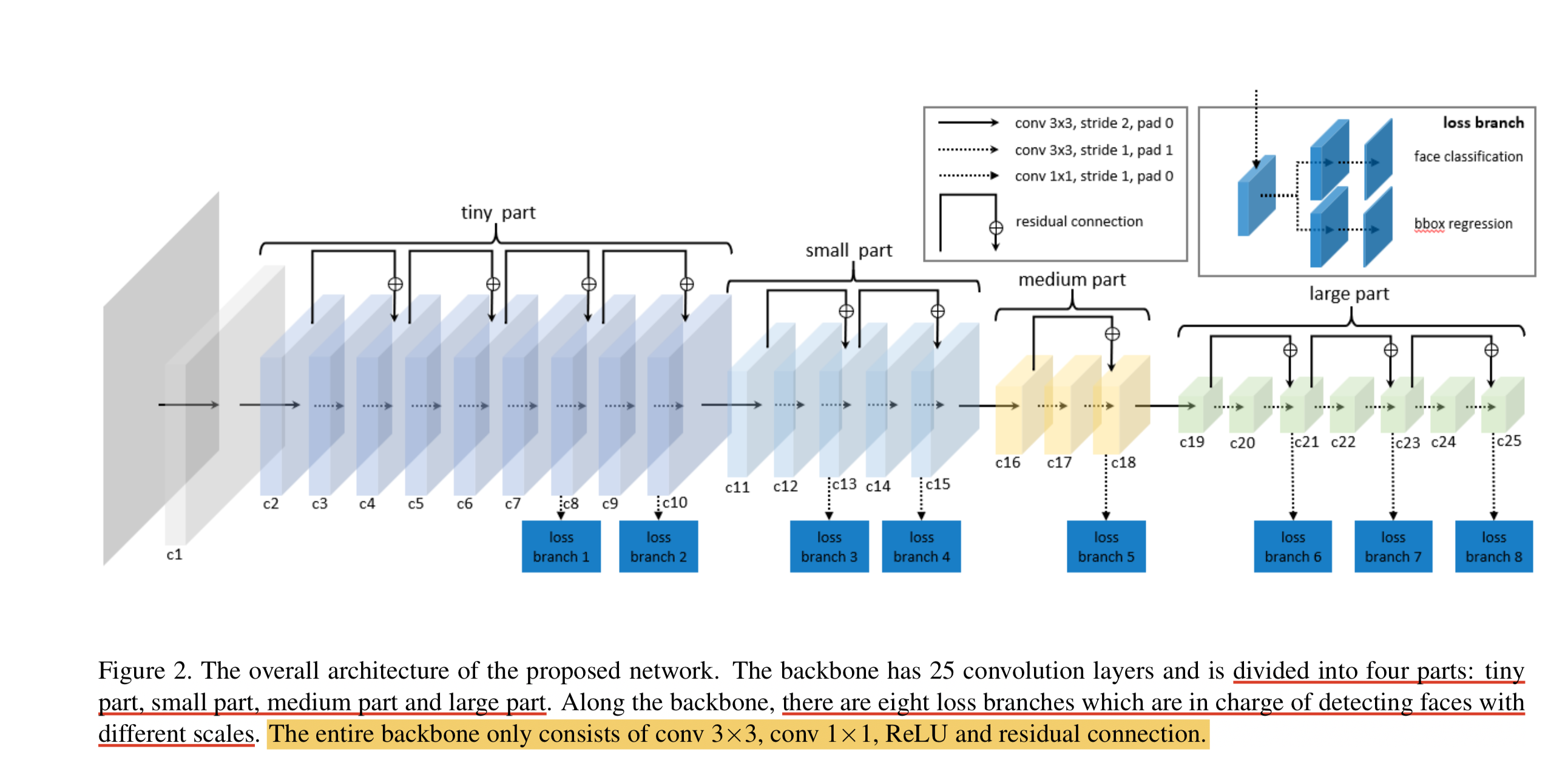
Podemos ver que el modelo LFFD consta principalmente de cuatro partes: parte pequeña, parte pequeña, parte mediana y parte grande.
La capa BN no se utiliza en el modelo porque reducirá la velocidad de inferencia en un 17%. Utiliza principalmente una reducción de resolución lo más rápido posible para mantener una cobertura facial del 100%.
Características principales de LFFD:
-
La estructura es simple y directa, y es fácil de implementar en dispositivos finales de IA convencionales.
-
La capacidad de detectar objetivos pequeños es excepcional: en imágenes de resolución extremadamente alta (como 8K o más), puede detectar objetivos de hasta 10 píxeles entre ellos;
Función de pérdida LFFD
La función de pérdida LFFD es la suma ponderada de la pérdida de regresión y la pérdida de clasificación.
La pérdida de clasificación utiliza pérdida de entropía cruzada.
La pérdida de regresión utiliza la función de pérdida L2.
Dirección en papel de LFFD: LFFD: un detector de rostros ligero y rápido para dispositivos de borde Dirección en papel
【16】 ¿La estructura y características del modelo U-Net?
La estructura de la red U-Net es la siguiente:
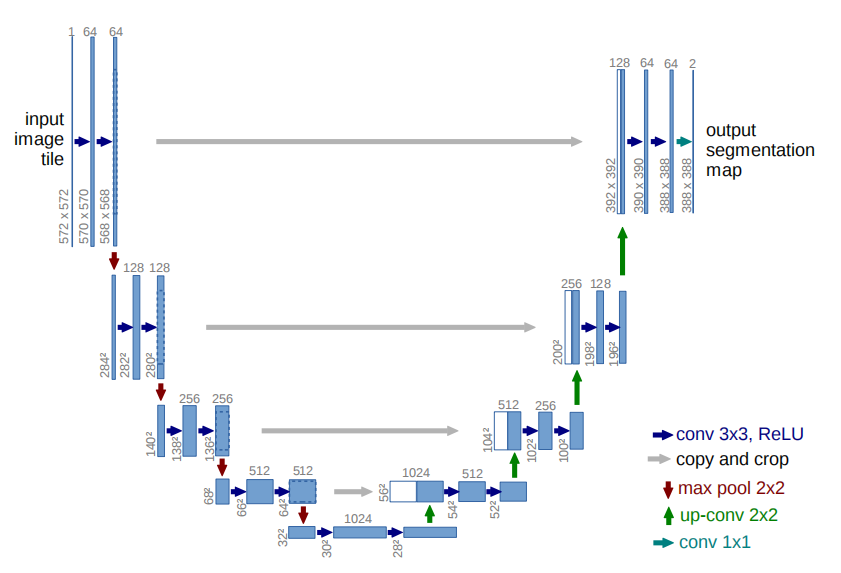
Características de la red U-Net:
- Red neuronal totalmente convolucional: utilice 1 × 1 1\times11×1 convolución reemplaza completamente la capa completamente conectada, lo que hace que el tamaño de entrada del modelo no esté restringido.
- La mitad izquierda de la red es la ruta de contracción: se utilizan capas de convolución y de agrupación máxima para reducir la muestra del mapa de características.
- La mitad derecha de la red es la ruta de expansión: use convolución transpuesta para aumentar la muestra del mapa de características y concatenarlo con el mapa de características generado por la capa correspondiente de la ruta de contracción. El muestreo ascendente puede complementar la información de características, además de concat con el mapa de características de la ruta de contracción de la mitad izquierda de la red (haciendo que los dos mapas de características tengan el mismo tamaño a través de la operación de recorte), lo que equivale a una fusión entre alta resolución y alta -características dimensionales.compromiso .
- U-Net propone una estructura general refrescante de codificador-decodificador, lo que hace que U-Net esté lleno de vitalidad y gran adaptabilidad.
U-Net tiene aplicaciones muy ricas en imágenes médicas, detección de defectos y escenas de tráfico. Se puede decir que en escenarios reales de segmentación de imágenes, U-Net es una línea de base universal.
Dirección impresa de U-Net: U-Net
[17] ¿Cuál es la estructura y características del modelo RepVGG?
La arquitectura básica del modelo RepVGG consta de 20 multicapa 3 × 3 3\times33×Consta de 3 convoluciones y se divide en 5 etapas. La primera capa de cada etapa se reduce con zancada = 2 y cada capa de convolución usa ReLU como función de activación.
Características clave de RepVGG:
- 3 × 3 3\veces33×La densidad computacional de 3 convoluciones en la GPU (operaciones teóricas divididas por el tiempo utilizado) puede ser hasta cuatro veces mayor que la de convoluciones 1x1 y 5x5.
- La eficiencia de cálculo de la estructura monocanal recta es mayor que la de la estructura multicanal.
- La estructura simple de un solo canal ocupa menos memoria que la estructura multicanal.
- La arquitectura de un solo canal tiene mayor flexibilidad y es más fácil de realizar operaciones adicionales como la compresión del modelo.
- RepVGG contiene solo un operador, lo que facilita a los fabricantes de chips diseñar chips especiales para mejorar la eficiencia de la IA final.
Entonces, ¿qué permite a RepVGG lograr el efecto SOTA en la situación anterior?
La respuesta es la reparametrización estructural .
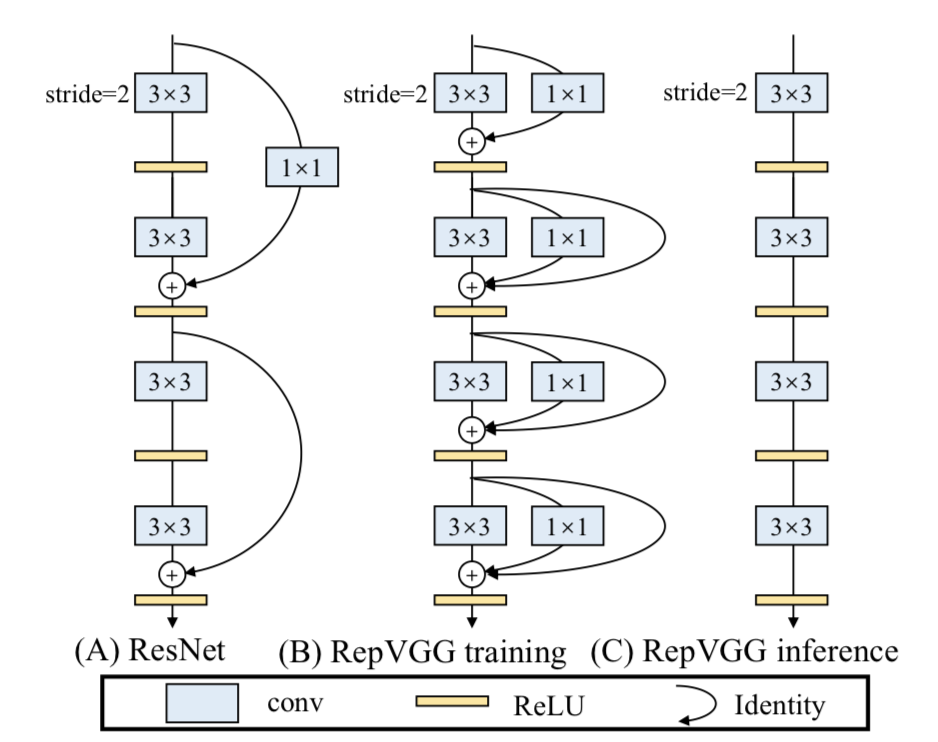
En la fase de entrenamiento, se entrena un modelo de múltiples ramas y se convierte de manera equivalente en un modelo de una sola rama. En la fase de implementación, implemente un modelo de canal único. De esta manera, puede aprovechar las ventajas del entrenamiento de modelos de múltiples ramas (alto rendimiento) y las ventajas de la inferencia de modelos de un solo canal (velocidad rápida, ahorro de memoria).
En capítulos posteriores se presentará un conocimiento más detallado de la reparametrización estructural, ¡así que todos lo esperan con ansias!
【18】 ¿La idea central de GAN?
En 2014, Ian Goodfellow propuso por primera vez el concepto de GAN. Yann LeCun dijo una vez: "Las redes generativas de confrontación y sus variantes se han convertido en una de las ideas más importantes en el campo del aprendizaje automático en los últimos 10 años " . La propuesta de GAN permitió que el modelo generativo volviera a estar en el escenario brillante de la ola de aprendizaje profundo y comenzó a charlar y reír con el modelo discriminativo.
GAN consta del generador GGG y discriminadorDDcomposición D. Entre ellos, el generador es el principal responsable de generar los datos de muestra correspondientes, y la entrada generalmente es ruido ZZmuestreado aleatoriamente a partir de una distribución gaussiana.Z. _ La principal responsabilidad del discriminador es distinguir las muestras generadas por el generador degt (GroundTruth) gt (GroundTruth)Muestra g t ( G ro u n d T r u t h ) , la entrada generalmente esgt gtmuestras g t y las muestras generadas correspondientes, lo que queremos es emparejargt gtCuanto más cerca esté el nivel de confianza de la salida muestral de g t a 1 11 es mejor y la confianza en el resultado de la muestra generada está más cerca de0 00 es mejor. A diferencia de las redes neuronales generales, GAN necesita entrenar el generador y el discriminador al mismo tiempo durante el entrenamiento, por lo que su entrenamiento es relativamente difícil.
En el primer artículo que propuso GAN, se comparó al generador con un delincuente que imprime dinero falso y al discriminador se le trató como a un policía. Los delincuentes trabajan duro para que el dinero falso que imprimen parezca realista, y la policía mejora constantemente su capacidad para detectar dinero falso. Los dos compiten entre sí y, a medida que pase el tiempo, se volverán cada vez más fuertes. Lo mismo ocurre en las tareas de generación de imágenes, donde el generador genera continuamente imágenes falsas que son lo más realistas posible. El discriminador determina que la imagen es gt gt.g t imagen, o imagen generada. Los dos continúan optimizando el juego y, finalmente, la imagen generada por el generador hace que sea completamente imposible para el discriminador distinguir entre verdadero y falso.
La idea contradictoria de GAN se realiza principalmente a través de su función objetivo . La fórmula específica es la siguiente:
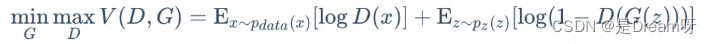
La fórmula anterior parece complicada, pero no lo es. Más allá de los detalles, la lógica central de toda la fórmula es en realidad un problema mínimo-máximo. Cuando los límites de las aplicaciones matemáticas de aprendizaje profundo se expanden aquí, GAN comienza a brillar .
Luego entramos en los detalles. Podemos ver esta fórmula en dos partes, a saber, el ángulo de minimización del discriminador y el ángulo de maximización del generador. Desde la perspectiva del discriminador, queremos maximizar esta función objetivo, porque en la primera parte de la publicidad significa gt gt.g t muestra(x ~ P datos) (x ~ Pdatos)( x ~ P d a t a ) La confianza de la salida después de ingresar el discriminador, por supuesto, está más cerca de1 11 es mejor. La segunda parte de la fórmula representa la muestra generada (G (z))generada por el generador( G ( z ) ) luego se ingresa en el discriminador para la clasificación binaria. Por supuesto, el nivel de confianza de su salida está más cerca de0 00 es mejor, entonces1 − D ( G ( z ) ) 1 - D(G(z))1−Cuanto más cerca esté D ( G ( z ) ) de 1 11 es mejor.
Desde la perspectiva del generador, queremos minimizar el valor máximo de la función objetivo discriminadora . El valor máximo de la función objetivo discriminadora representa la divergencia JS entre la distribución de datos real y la distribución de datos generada. La divergencia JS puede medir la similitud de la distribución. Cuanto más cercanas estén las dos distribuciones, menor será la divergencia JS (la divergencia JS es el valor inicial). Se propuso en el artículo de GAN, pero se encontrarán deficiencias en las aplicaciones prácticas. Los artículos posteriores han propuesto sucesivamente muchas funciones de pérdida nuevas para la optimización)
[19] ¿Modelo GAN clásico que a menudo se pregunta en las entrevistas?
- GAN original y su lógica de entrenamiento
- DCGAN
- CGAN
- EQUIVOCADO
- LSGAN
- Serie PixPix
- CysleGAN
- Serie SRGAN
【20】 Conocimientos relacionados con FPN (Feature Pyramid Network)
Puntos de innovación de FPN
- Característica de diseño estructura piramidal.
- Extraiga funciones multicapa (de abajo hacia arriba, de arriba hacia abajo)
- Fusión de características multicapa (conexión lateral)
La estructura de la pirámide de características está diseñada para resolver el problema de múltiples escalas en la detección de objetivos y mejorar en gran medida el rendimiento de detección de objetos pequeños sin aumentar básicamente la cantidad de cálculo del modelo original.
Resulta que muchos algoritmos de detección de objetivos solo utilizan características de alto nivel para la predicción, que tienen información semántica rica, pero tienen baja resolución y ubicaciones de objetivos aproximadas. Supongamos que en una red profunda, un píxel en el mapa de características final de alto nivel puede corresponder a la imagen de salida 20 × 20 20 \times 2020×Área de 20 píxeles, luego menos de20 × 20 20 \times 2020×Lo más probable es que se hayan perdido las características de un objeto pequeño de 20 píxeles . Al mismo tiempo, la información semántica de características de bajo nivel es relativamente pequeña, pero la posición del objetivo es precisa, lo que resulta útil para la detección de objetivos pequeños. FPN fusiona características de alto nivel con características de bajo nivel, utilizando así simultáneamente la alta resolución de las características de bajo nivel y la rica información semántica de las características de alto nivel, y realiza predicciones independientes de características de múltiples escalas, mejorando significativamente el efecto de detección de objetos pequeños.
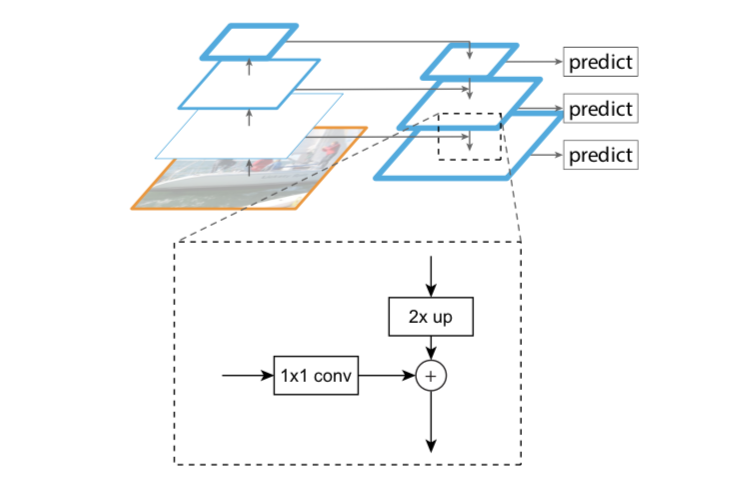
Las ideas tradicionales para resolver este problema incluyen:
- Pirámide de imágenes, es decir, entrenamiento y pruebas a múltiples escalas. Sin embargo, este método es computacionalmente intensivo y requiere mucho tiempo.
- Capas de características, es decir, cada capa genera los resultados de detección de la resolución de escala correspondiente, como el algoritmo SSD. Pero, de hecho, diferentes profundidades corresponden a diferentes niveles de características semánticas. La red superficial tiene una alta resolución y aprende características más detalladas. La red profunda tiene una resolución baja y aprende más características semánticas. Las diferentes características por sí solas no son suficientes.
Módulos principales de FPN
- Camino de abajo hacia arriba
- Camino de arriba hacia abajo
- Conexiones laterales
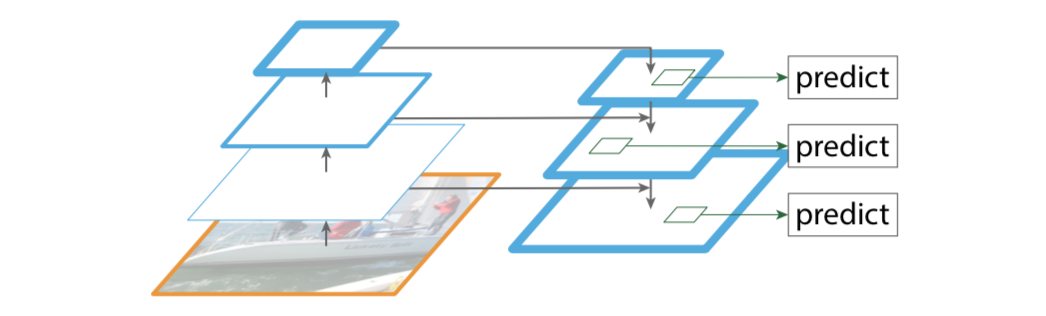
Camino de abajo hacia arriba
La línea ascendente es el proceso de propagación directa de la red convolucional. Durante la propagación hacia adelante, el tamaño del mapa de características puede cambiar en algunas capas.
Ruta de arriba hacia abajo (línea de arriba hacia abajo) y conexiones laterales (enlaces horizontales)
La línea de arriba hacia abajo es un proceso de muestreo ascendente, mientras que el enlace horizontal fusiona los resultados de la línea de arriba hacia abajo con la estructura de la línea de abajo hacia arriba.
El mapa de características muestreado ascendente y el mapa de características muestreado reducidamente del mismo tamaño se agregan y fusionan píxel por píxel (adición de elementos), donde la característica ascendente pasa primero por 1 × 1 1\times 11×1 capa convolucional, el propósito es reducir la dimensión del canal.
aplicación fpn
En el documento, FPN se mejora directamente en Faster R-CNN, y su columna vertebral es ResNet101. FPN se utiliza principalmente en los dos módulos de RPN y Fast R-CNN en Faster R-CNN.
FPN+RPN:
Al combinar FPN y RPN, la entrada de RPN se convertirá en un mapa de características de múltiples escalas y se conectarán múltiples capas principales de RPN a la salida de RPN para satisfacer la clasificación y regresión de anclajes.
FPN+R-CNN rápido:
La lógica estructural general de Fast R-CNN permanece sin cambios y la idea de FPN se introduce en la parte principal para la transformación.
【21】 Conocimientos relacionados con SPP (Spatial Pyramid Pooling)
En el campo de la detección de objetivos, muchos algoritmos de detección finalmente utilizan capas completamente conectadas, lo que da como resultado un tamaño de entrada fijo. Cuando encuentre entradas de imágenes con tamaños que no coinciden, debe utilizar operaciones como recortar o deformar para hacer coincidir el tamaño de la imagen y la entrada del algoritmo. Estos dos métodos pueden causar diferentes problemas: el área recortada puede no contener el objeto completo; la operación de deformación causa una distorsión geométrica inútil del objetivo, etc.
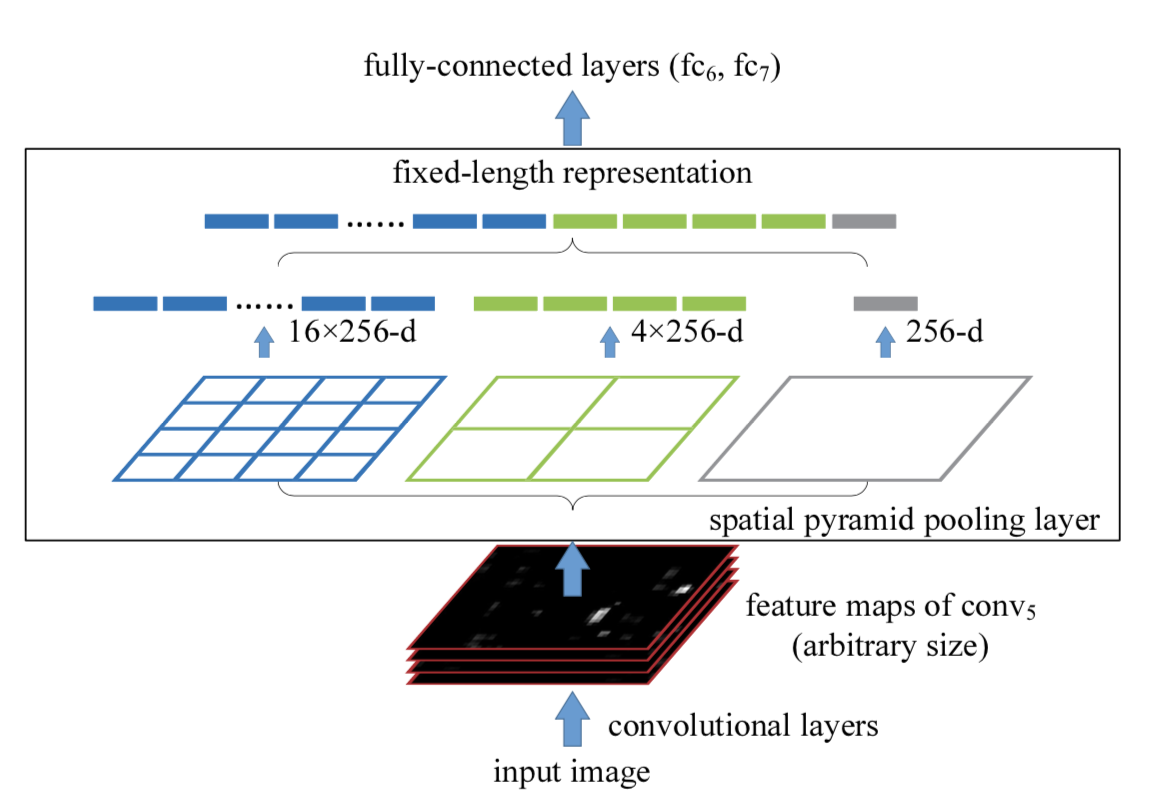
Lo que hace SPP es agregar una capa SPP después de la capa convolucional para convertir el mapa de características en un vector de características de longitud fija. Luego, el vector de características se ingresa en la capa completamente conectada . Esto resolverá el vergonzoso problema anterior.
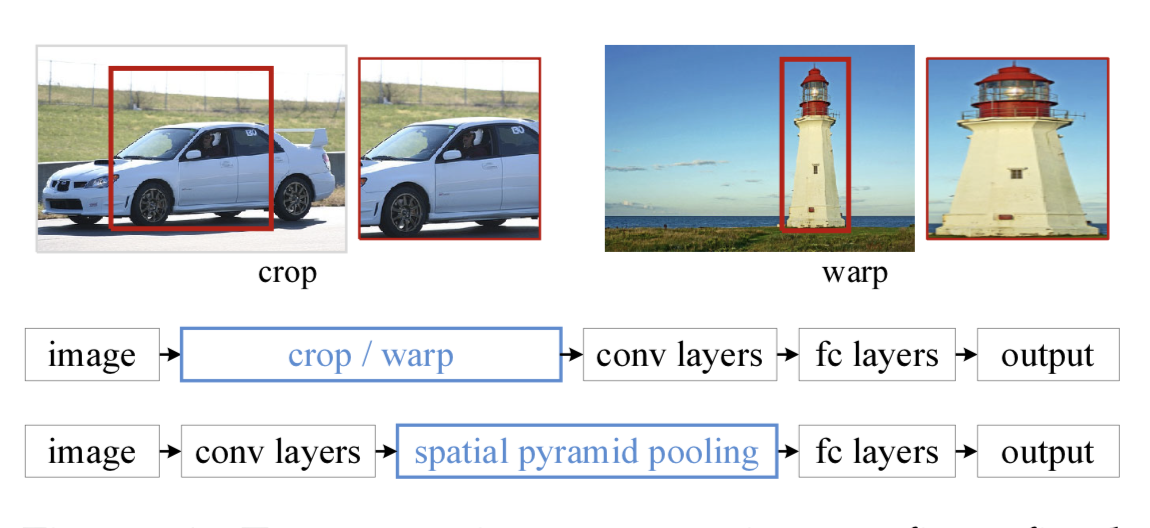
Ventajas del SPP:
- SPP puede ignorar las dimensiones de entrada y producir resultados de longitud fija.
- SPP utiliza núcleos deslizantes de múltiples escalas en lugar de una ventana deslizante de un solo tamaño para la agrupación.
- SPP extrae características en mapas de características de diferentes tamaños, aumentando la riqueza de las características extraídas.
[22] El significado de AP, AP50, AP75, mAP y otros indicadores en la detección de objetivos
AP: Área bajo la curva PR.
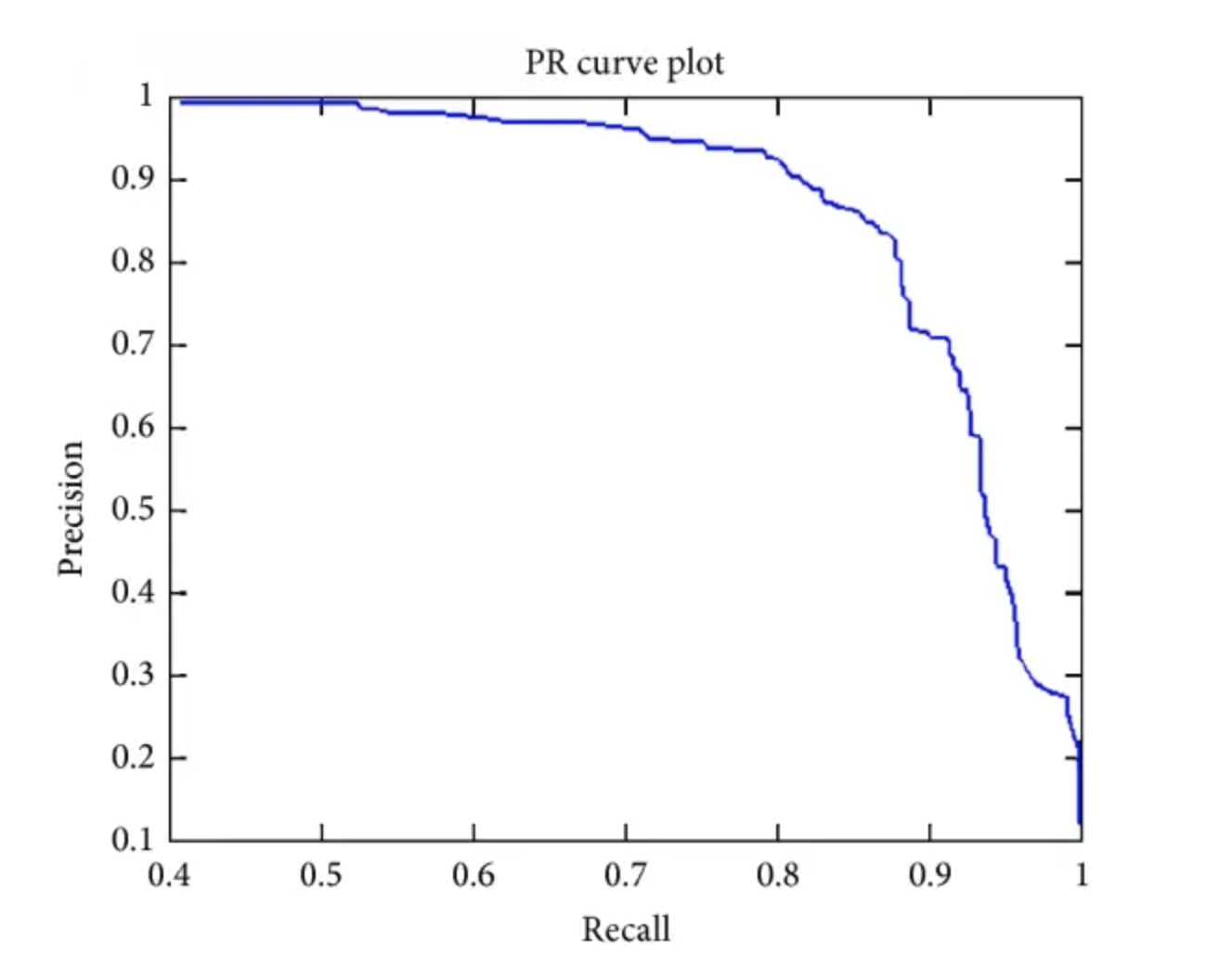
AP50: el valor de AP cuando el IoU fijo es del 50%.
AP75: el valor de AP cuando el IoU fijo es del 75 %.
AP@[0.5:0.95]: divida el valor de IoU cada 5% del 50% al 95% y promedie estos 10 conjuntos de valores AP.
mapa: calcula el AP para todas las categorías y luego toma el promedio.
mAP@[.5:.95] (es decir, mAP@[.5,.95]): indica que en diferentes umbrales de IoU (de 0,5 a 0,95, tamaño de paso 0,05) (0,5, 0,55, 0,6, 0,65, 0,7, 0,75 , 0,8, 0,85, 0,9, 0,95).
【23】¿Cómo generar ancla en YOLOv2?
El algoritmo K-means se introduce en YOLOv2 para generar anclajes , que pueden encontrar automáticamente mejores valores de ancho y alto de anclaje para la inicialización del entrenamiento del modelo.
Sin embargo, si la distancia euclidiana en K-means clásica se utiliza como métrica, significa que un Anchor más grande producirá un error mayor que un Anchor más pequeño, y los resultados de agrupación pueden desviarse.
Dado que la detección de objetivos se preocupa principalmente por el pagaré del ancla y la caja verdadera de tierra (caja gt), no le importa el tamaño de las dos. Por lo tanto, es más apropiado utilizar IOU como métrica, es decir, aumentar el valor del IOU. Por lo tanto, YOLOv2 utiliza el valor del pagaré como criterio:
d (gtbox, ancla) = 1 − pagaré (gtbox, ancla) d(gtbox,ancla) = 1 - pagaré(gtbox,ancla)d ( g t caja x , _ancla ) _ _ _=1−I O U ( g t caja , _ _ancla ) _ _ _
Los pasos específicos de generación de anclajes son aproximadamente los mismos que los de las K-medias clásicas, que se presentarán en detalle en el próximo capítulo. La principal diferencia es que la métrica utilizada es d (gtbox, ancla) d(gt caja, ancla)d ( g t caja x , _an c h o ) y utilice el ancla como centro del grupo.