Da ChatGPT in den letzten sechs Monaten weltweit populär geworden ist, sind große Sprachmodelle (LLM), die auf der Transformer-Architektur basieren, nach und nach in die Öffentlichkeit gelangt. Man kann sagen, dass der Einfluss von Transformer im Bereich der KI nicht geringer ist das von Transformers im Bereich der Science-Fiction.
Die Kernidee von Transformer besteht darin, den Self-Attention-Mechanismus zu nutzen, um Abhängigkeiten zwischen Sequenzen herzustellen. Noch vor zwei Jahren basierten viele Modelle hauptsächlich auf dem langen Kurzzeitgedächtnis (LSTM) und anderen Varianten rekurrenter neuronaler Netze (RNN), doch heute basieren große Sprachmodelle auf dem Aufmerksamkeitsmechanismus von Transformer. Der KI-Bereich entwickelt sich rasant vom traditionellen maschinellen Lernen über neuronale Netze bis hin zum heutigen Transformer.

Entwicklungsrichtung der künstlichen Intelligenz
Derzeit ist der Markt für große Sprachmodelle voller Blumen (xuè) (yǔ) (xīng) (fēng), daher haben wir in der Hoffnung, dass dies der Fall ist, eine Liste großer Sprachmodelle zusammengestellt, die möglicherweise die umfassendste im gesamten Netzwerk ist Jeder kann den Puls der AIGC-Ära erfassen.
Nachdem Sie diesen Artikel gelesen und gesammelt haben, erfahren Sie:
Globaler Sprachmodellentwicklungskontext und Genealogiematrix
Der Iterationsprozess großer Sprachmodelle in den beiden Lagern Google und Microsoft
Inventar der wichtigsten globalen und nationalen Sprachmodelle
Entwicklungsgeschichte globaler großer Sprachmodelle
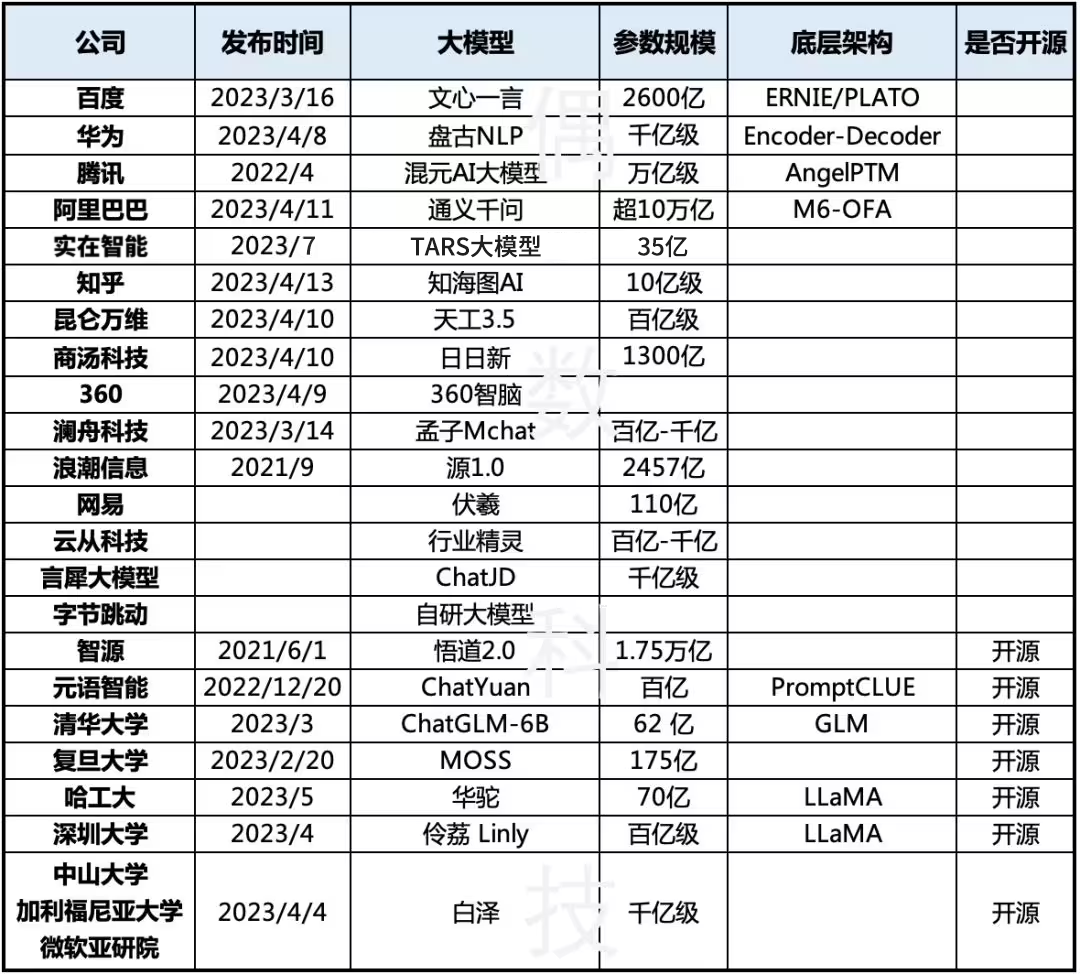
Die folgende Abbildung zeigt den Zeitplan für die Veröffentlichung großer Sprachmodelle mit einer Größenordnung von mehreren zehn Milliarden Parametern seit 2019. Die gelb markierten großen Modelle stammen aus offenen Quellen. Es ist zu erkennen, dass seit 2022 in einem endlosen Strom neue Modelle entstanden sind und die Iterationsgeschwindigkeit von OpenAI und den großen Modellen von Google deutlich höher ist als die anderer Hersteller.
Entwicklungstrends großer Sprachmodelle
Globale Stammbaummatrix für große Sprachmodelle
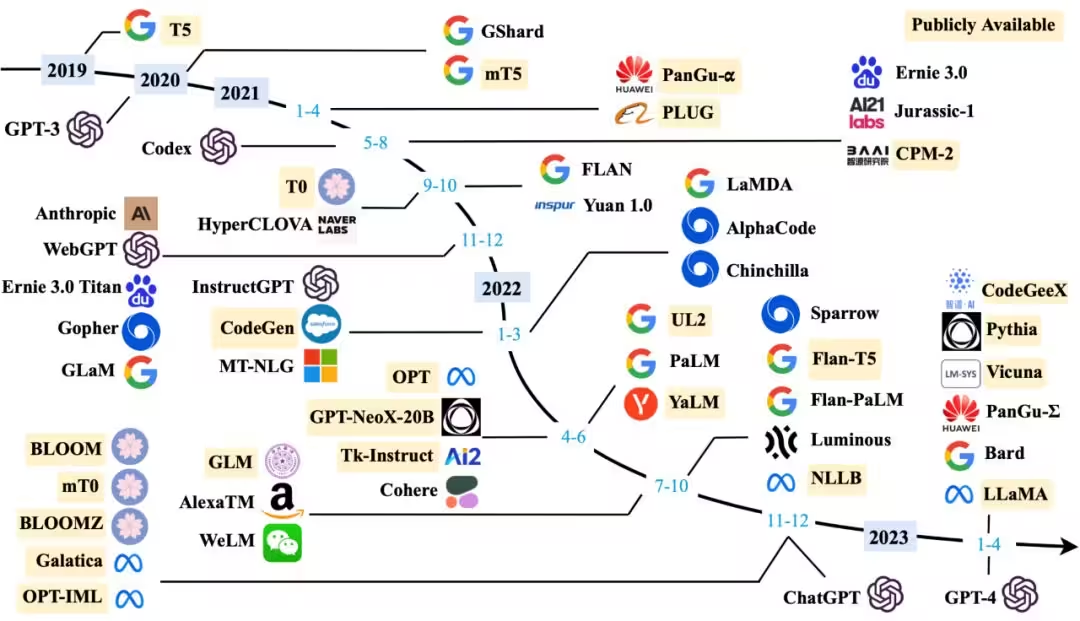
Die folgende Tabelle zeigt den Stammbaum der wichtigsten großen Sprachmodelle, wobei verschiedene Farben unterschiedliche technische Ursprünge darstellen. Die horizontale Achse ist die Zeitleiste und die vertikale Achse ist die Parameterskala des Modelltrainings. Seit 2018 hat sich der Umfang des Trainings großer Sprachmodelle weiter ausgeweitet, und 2022 wird auch in Bezug auf die Parameterskala ein explosives Jahr sein.

Quadrant mit großer Parameterskala für Sprachmodelle
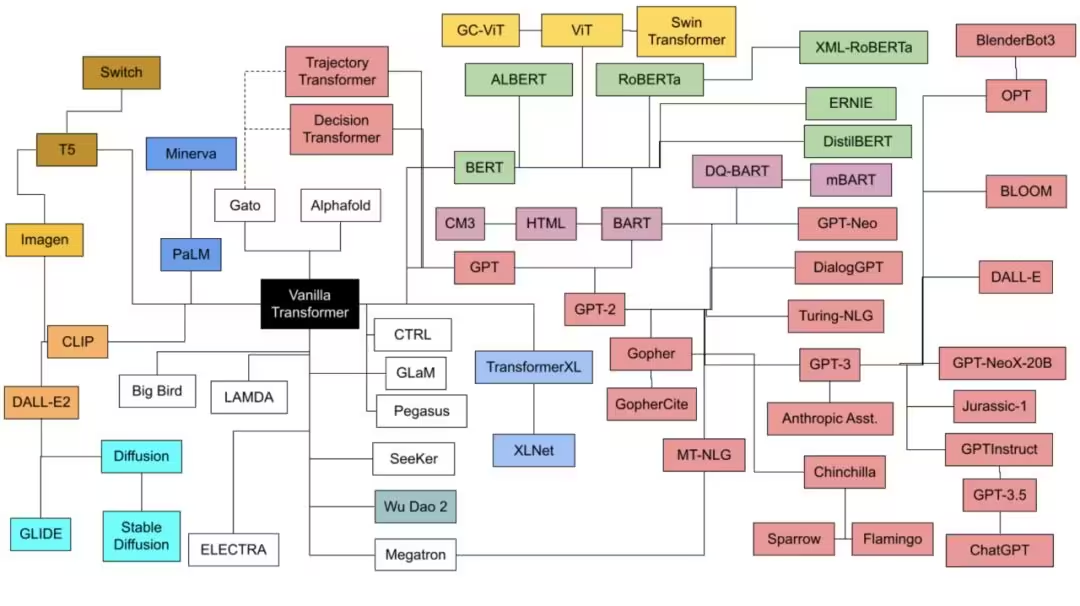
Große Sprachmodell-Technologie-Roadmap-Genealogie-Beziehung
Giganten-Konfrontation: Der Wettlauf zwischen Google und Microsoft eskaliert weiter
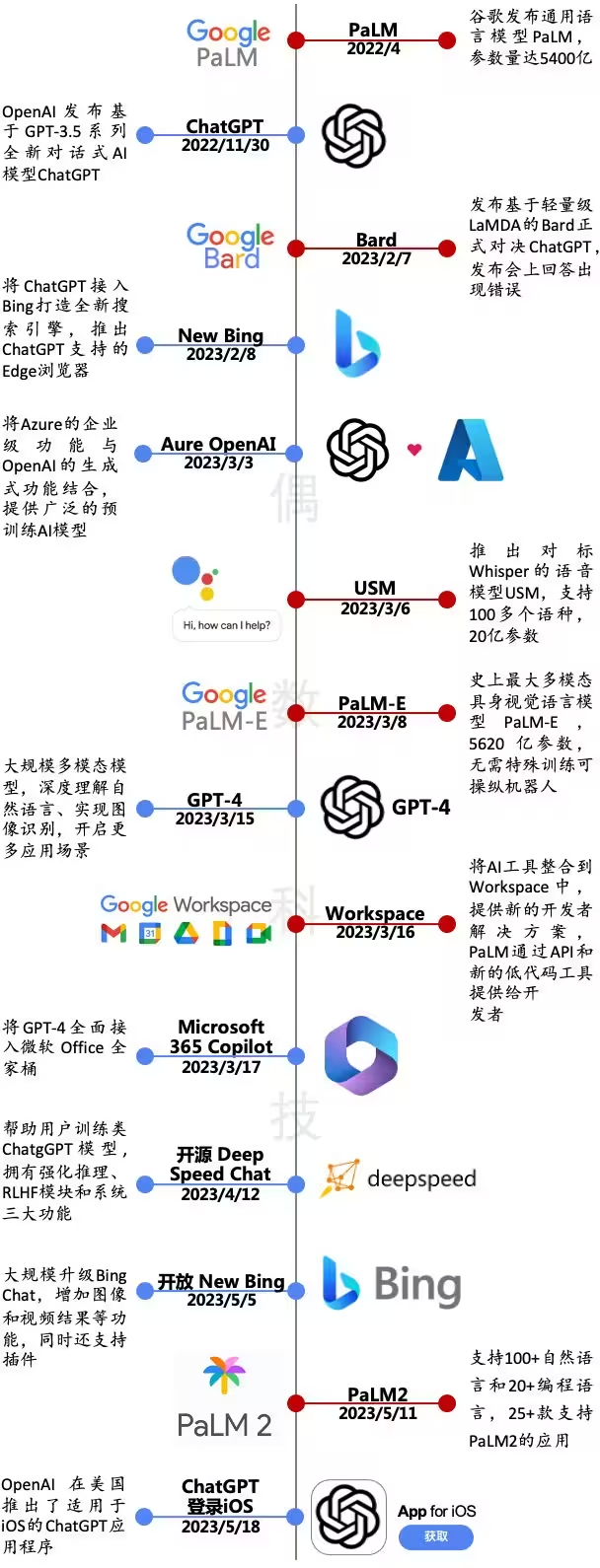
Am 22. November veröffentlichte OpenAI ChatGPT, ein neues Konversations-KI-Modell, das auf der GPT-3.5-Serie basiert. Dieses iterative Upgrade ist von epochenübergreifender Bedeutung: Im Februar dieses Jahres integrierte Microsoft ChatGPT in Bing, um die Suchmaschine neu zu definieren, und im März dieses Jahres Es wurde ein multimodales, groß angelegtes Sprachmodell GPT-4 veröffentlicht, das stärkere Fähigkeiten im Bereich „Verstehen + Erstellen“ zeigt.
Angesichts der von OpenAI gestarteten GPT-Reihe folgt Google aufmerksam. Im Februar und März dieses Jahres brachte das Unternehmen Bard auf den Markt, das ChatGPT als Benchmarking setzt, und PaLM-E, das größte multimodale verkörperte visuelle Sprachmodell in der Geschichte; Google startete offiziell am 11. Mai „Counterattack“ veröffentlichte das große Sprachmodell PaLM2, um die Schwachstellen von GPT-4 direkt anzugehen, und integrierte gleichzeitig KI in mehr als 25 Anwendungen.
Microsoft vs. Google veröffentlicht Upgrades
Große Datenquelle für das Sprachmodelltraining
Anhand der Trainingsdatenquellen großer Sprachmodelle können wir feststellen, dass diese Modelle hauptsächlich durch Crawlen von Webseitendaten trainiert werden. GPT-3 fügt auch einige Buchinformationen auf der Grundlage von Webseiten hinzu. Interessant ist, dass es sich bei den von DeepMind entwickelten AlphaCode-Trainingsdatenquellen ausschließlich um Codes handelt, von denen man ableiten kann, dass sie über starke Programmierfähigkeiten verfügen. Es wird davon ausgegangen, dass AlphaCode an 10 Programmierwettbewerben von Codeforces im Jahr 2022 teilgenommen hat, unter den besten 54,3 % lag, 46 % der Teilnehmer besiegte und einen Elo-Wert von 1238 erreichte.

Verschiedene große Datenquellen für das Sprachmodelltraining
Umfangreiche Hardwareressourcen für das Sprachmodelltraining
Umfangreiches Sprachtraining verbraucht enorme Mengen an Hardwareressourcen. Neben der ersten Verwendung von GPUs als Trainingschips haben viele große Sprachmodelle inzwischen damit begonnen, TPUs als Haupttrainingschips zu verwenden. Einerseits hat die rasante Entwicklung der Hardware zweifellos die Iterationseffizienz großer Sprachmodelle verbessert, andererseits hat der harte Wettbewerb bei großen Sprachmodellen auch zu einem starken Preisanstieg für Hardware, hauptsächlich Chips und Server, geführt . Laut Jiemian News wurde über mehrere Kanäle über den Preis von NVIDIAs KI-Flaggschiff-Chip H100 auf 40.000 US-Dollar spekuliert, was eine deutliche Steigerung im Vergleich zum vorherigen von Einzelhändlern angegebenen Preis von 36.000 US-Dollar darstellt. 10.000 NVIDIA A100-Chips sind die Rechenleistungsschwelle für Entwicklung großer Sprachmodelle. .

Vergleich der Hardwareressourcen für das Training großer Sprachmodelle
Inventar der wichtigsten globalen Sprachmodelle
Aus globaler Sicht gehören zu den Hauptherausgebern großer Sprachmodelle Google, OpenAI, Facebook, Microsoft, Deepmind und EleutherAI. Die Modellparameterskala beträgt hauptsächlich mehrere zehn Milliarden und Hunderte von Milliarden, und die technische Architektur besteht hauptsächlich aus Encoder-Decoder. Die Anzahl der in der folgenden Tabelle aufgeführten Modelle liegt bei knapp 100, es dürfte aber noch viel mehr sein.
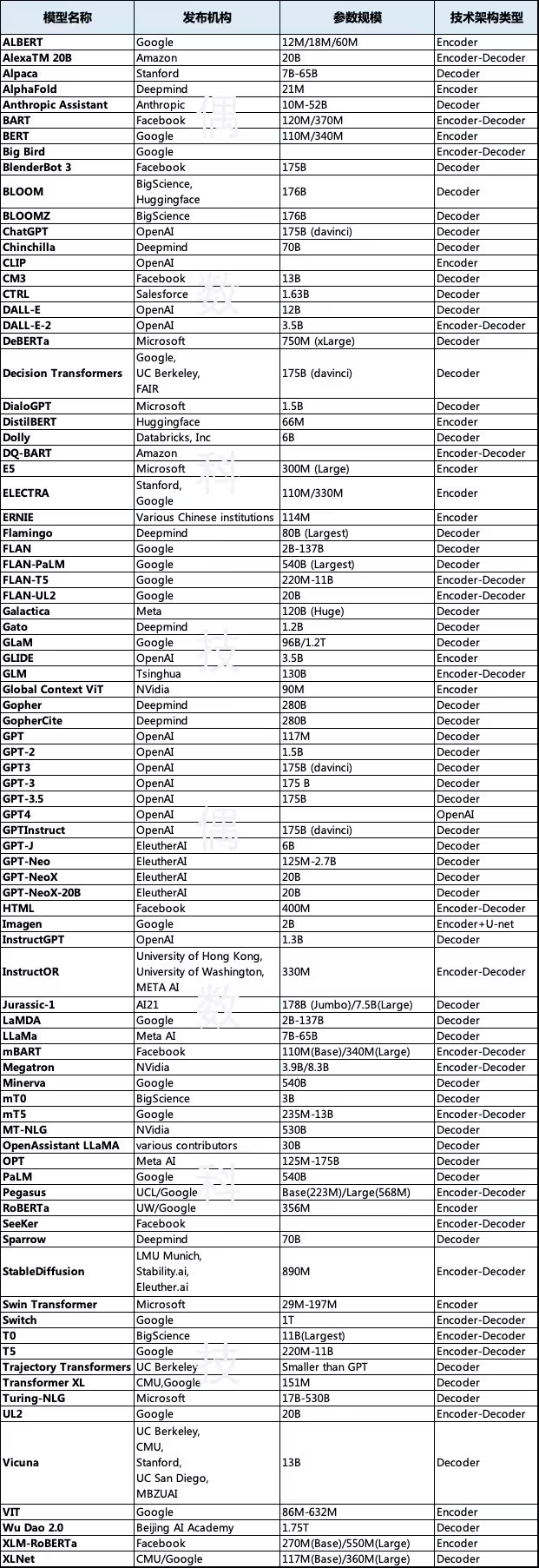
Vergleich der wichtigsten globalen Sprachmodelle
Inventar der wichtigsten globalen Sprachmodelle
Inventar der inländischen großen Sprachmodelle
Natürlich hat das Feuer großer Sprachmodelle auch die Begeisterung inländischer Technologieunternehmen für große Sprachmodelle entfacht. Basierend auf der frühen Selbstforschung oder Open-Source-Modellen haben viele inländische Institutionen große Sprachmodelle auf den Markt gebracht. Unvollständigen Statistiken zufolge gibt es dort sind mehr als 20 Unternehmen.