Als neue neuronale Netzwerkarchitektur erzielt RetNet gleichzeitig gute Skalierungsergebnisse, paralleles Training, kostengünstige Bereitstellung und effiziente Inferenz. Diese Eigenschaften machen RetNet zu einem leistungsstarken Nachfolger der grundlegenden Netzwerkarchitektur großer Sprachmodelle nach Transformer.
——Wei Furu, Global Research Partner, Microsoft Research Asia
Der folgende Inhalt wird mit Genehmigung des öffentlichen Kontos „Qubit“ reproduziert, der Originaltitel „Transformer-Nachfolger hat ein Modell!“ MSRA schlägt eine neue groß angelegte Modellinfrastruktur vor: 8-mal schnelleres Denken und 70 % weniger Speicherverbrauch.“
Kürzlich veröffentlichte das Microsoft Asia Research Institute das Papier „Remanente Netzwerke: Ein Nachfolger von Transformer für große Sprachmodelle“ zur neuen Architektur großer Modelle. Diese Infrastruktur verwendet einen neuen Aufbewahrungsmechanismus anstelle von Achtung, was Transformer herausfordert!

Experimentelle Daten zeigen auch, dass es bei Sprachmodellierungsaufgaben Folgendes gibt:
- RetNet kann eine mit Transformer vergleichbare Verwirrung erzielen
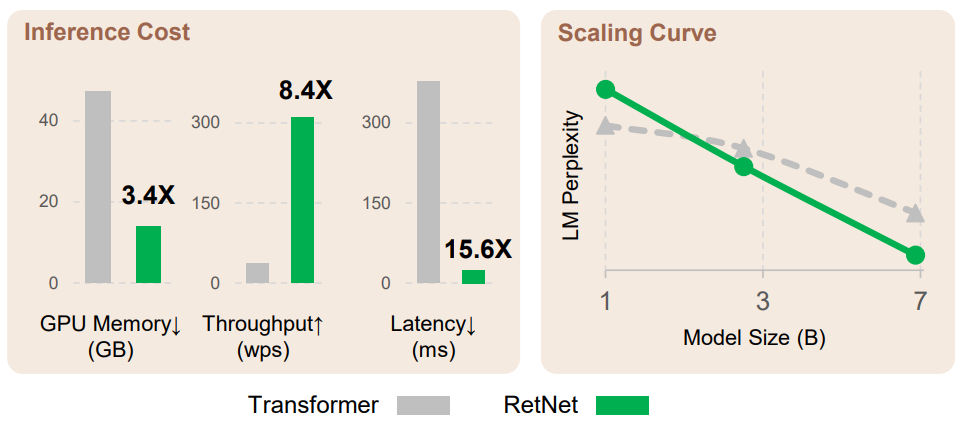
- 8,4-mal schnellere Inferenz
- 70 % Reduzierung der Speichernutzung
- Hat eine gute Skalierbarkeit
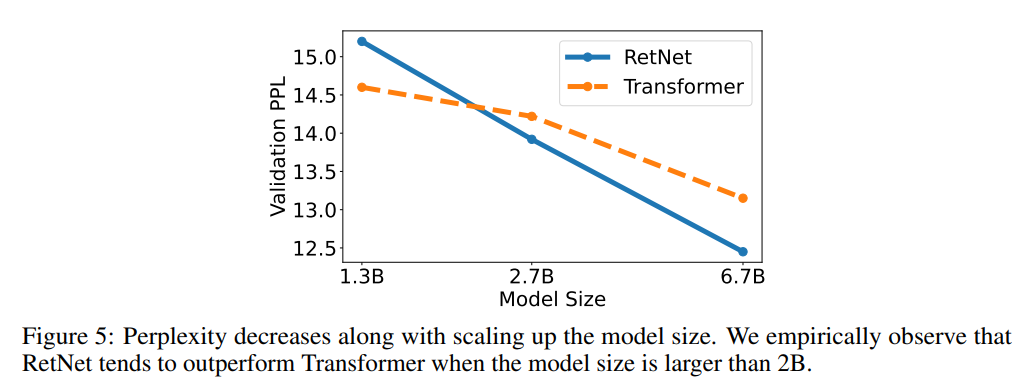
Und wenn die Modellgröße einen bestimmten Maßstab überschreitet, ist RetNet leistungsfähiger als Transformer.
Die Einzelheiten erfahren Sie gemeinsam.
Lösen Sie das „unmögliche Dreieck“
Die Bedeutung von Transformer in großen Sprachmodellen steht außer Zweifel. Ob es sich um die GPT-Serie von OpenAI, Googles PaLM oder Metas LLaMA handelt, sie alle basieren auf Transformer.
Aber Transformer ist nicht perfekt: Sein paralleler Verarbeitungsmechanismus geht zu Lasten ineffizienter Argumentation, und die Komplexität jedes Schritts beträgt O(N); Transformer ist ein speicherintensives Modell, und je länger die Sequenz, desto mehr Speicher beansprucht es .
Vorher dachten nicht alle darüber nach, Transformer weiter zu verbessern. Allerdings werden die Hauptforschungsrichtungen etwas vernachlässigt:
Lineare Aufmerksamkeit kann die Argumentationskosten reduzieren, aber die Leistung ist schlecht.
Rekurrente neuronale Netze können nicht parallel trainiert werden.
Mit anderen Worten: Vor diesen neuronalen Netzwerkarchitekturen befindet sich ein „unmögliches Dreieck“. Die drei Ecken stehen für: paralleles Training, kostengünstige Argumentation und gute Skalierbarkeit.
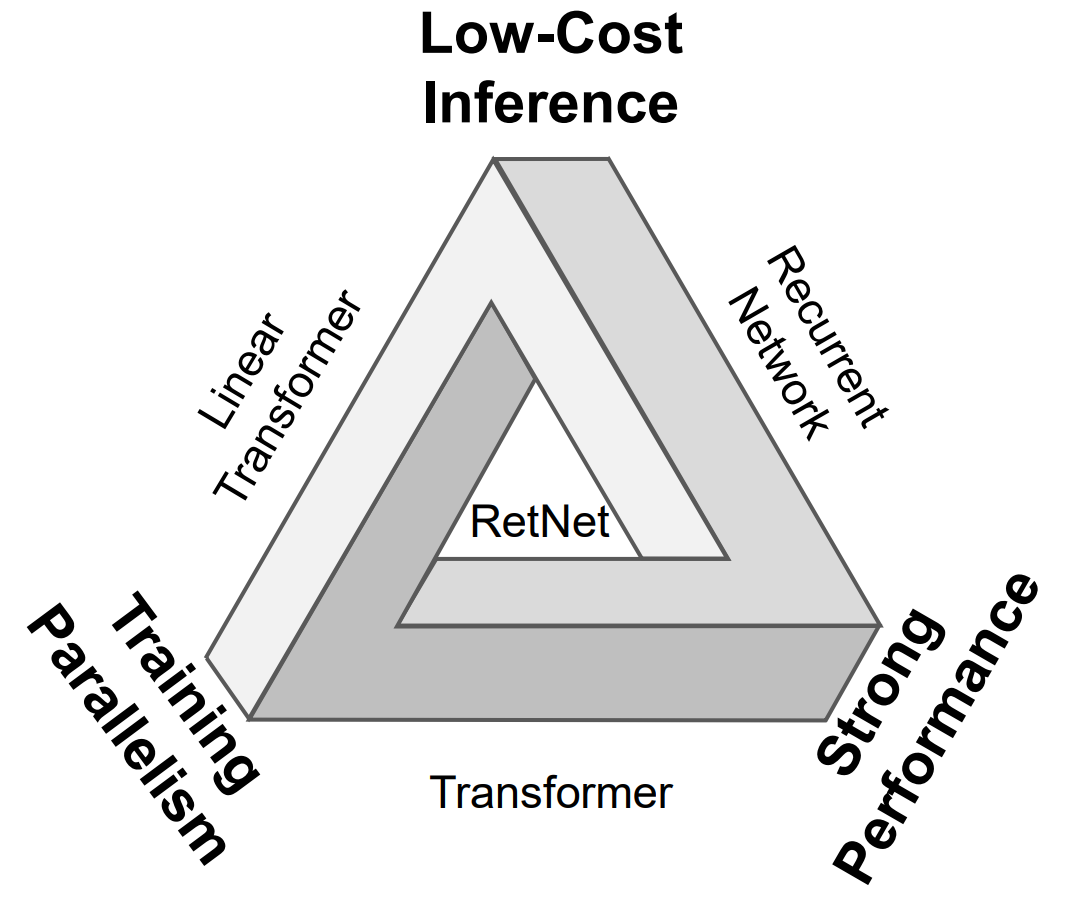
Was die Forscher von RetNet tun wollen, ist, das Unmögliche möglich zu machen.
Insbesondere verwendet RetNet auf der Basis von Transformer einen mehrskaligen Aufbewahrungsmechanismus (Retention), um den Standard-Selbstaufmerksamkeitsmechanismus zu ersetzen.
Im Vergleich zum Standard-Selbstaufmerksamkeitsmechanismus weist der Retentionsmechanismus mehrere Merkmale auf:
Als Ersatz für Softmax wird ein positionsabhängiger exponentieller Zerfallsterm eingeführt, der die Berechnung vereinfacht und die Informationen des vorherigen Schritts in Form eines Zerfalls beibehält.
Führen Sie einen komplexen Zahlenraum ein, um Positionsinformationen auszudrücken, ersetzen Sie die absolute oder relative Positionscodierung und konvertieren Sie ihn einfach in eine rekursive Form.
Darüber hinaus verwendet der Retentionsmechanismus Multiskalen-Abfallraten, um die Ausdruckskraft des Modells zu erhöhen, und nutzt die Skalierungsinvarianz von GroupNorm, um die numerische Genauigkeit der Retentionsschicht zu verbessern.
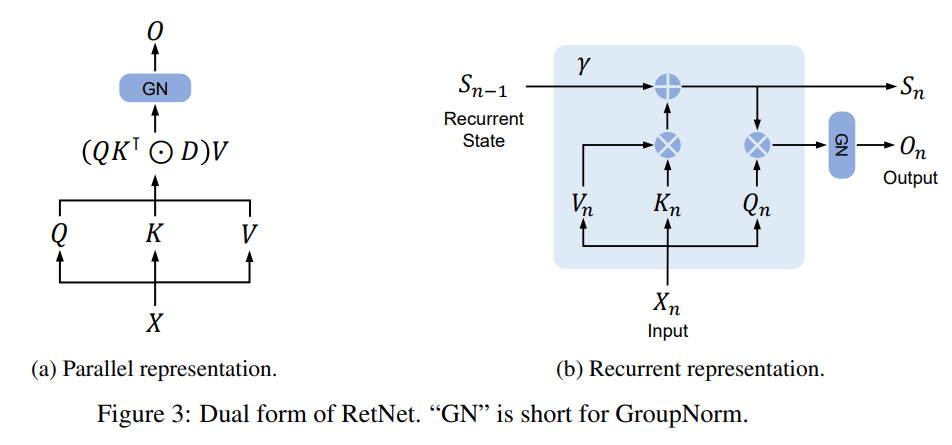
Doppelte Darstellung von RetNet
Jeder RetNet-Block enthält zwei Module: ein Multi-Scale-Preserving-Modul (MSR) und ein Feed-Forward-Network-Modul (FFN).
Der Haltemechanismus unterstützt die Darstellung von Sequenzen in drei Formen:
- parallel
- Rekursion
- Blockrekursion, also eine Hybridform aus paralleler Darstellung und rekursiver Darstellung, unterteilt die Eingabesequenz in Blöcke, führt Berechnungen entsprechend der parallelen Darstellung innerhalb von Blöcken durch und folgt der rekursiven Darstellung zwischen Blöcken.
Unter anderem ermöglicht die parallele Darstellung RetNet, die GPU effizient für paralleles Training wie Transformer zu nutzen.
Die rekursive Darstellung erreicht eine O(1)-Inferenzkomplexität und reduziert so den Speicherverbrauch und die Latenz.
Mit der Chunked-Rekursion können lange Sequenzen effizienter verarbeitet werden.
Auf diese Weise ermöglicht RetNet das „unmögliche Dreieck“. Im Folgenden sind die Vergleichsergebnisse von RetNet und anderen Infrastrukturen aufgeführt:
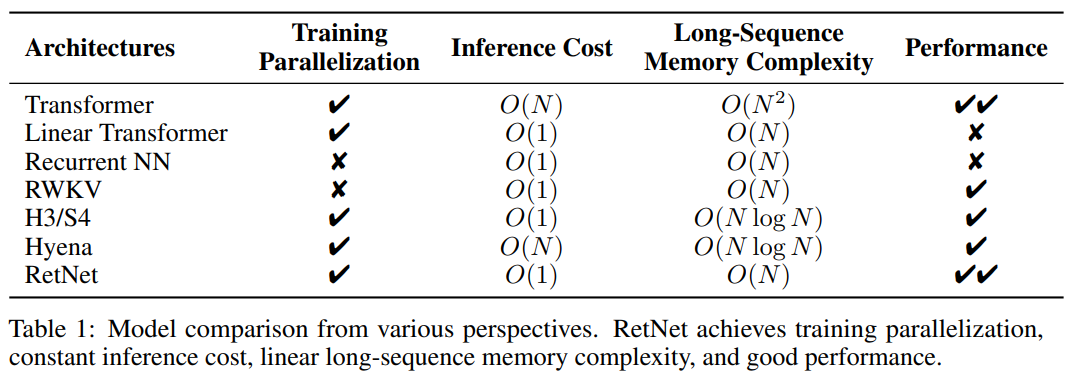
Experimentelle Ergebnisse zu Sprachmodellierungsaufgaben beweisen die Wirksamkeit von RetNet weiter.
Die Ergebnisse zeigen, dass RetNet eine ähnliche Verwirrung wie Transformer erzielen kann (PPL, ein Indikator zur Bewertung der Qualität eines Sprachmodells, je kleiner, desto besser).
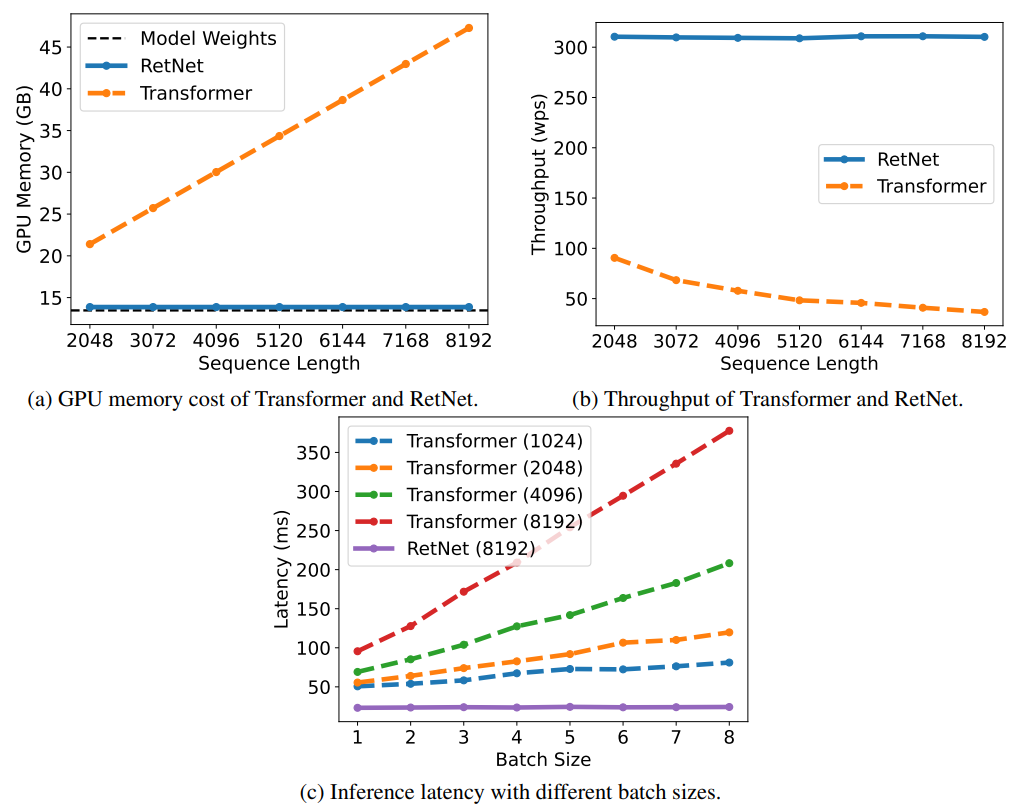
Wenn die Modellparameter 7 Milliarden betragen und die Eingabesequenzlänge 8 KB beträgt, kann die Inferenzgeschwindigkeit von RetNet gleichzeitig das 8,4-fache der von Transformer erreichen und die Speichernutzung wird um 70 % reduziert.
Während des Trainingsprozesses schneidet RetNet auch in Bezug auf Speichereinsparung und Beschleunigungseffekte besser ab als der Standard-Transformer+FlashAttention und erreicht 25-50 % bzw. das Siebenfache.
Es ist erwähnenswert, dass die Inferenzkosten von RetNet unabhängig von der Sequenzlänge sind und die Inferenzlatenz unabhängig von der Stapelgröße ist, was einen hohen Durchsatz ermöglicht.
Wenn die Modellparametergröße mehr als 2 Milliarden beträgt, ist RetNet außerdem leistungsfähiger als Transformer.
Remanentes Netzwerk: Ein Nachfolger des Transformers für große Sprachmodelle
Papieradresse: https://arxiv.org/abs/2307.08621