
Autor: Dong Shandong (Fanden)
Este artículo es la versión de texto del discurso especial "Práctica de diagnóstico y monitoreo inteligente de AIOps observables en la nube de Alibaba" pronunciado por el autor en QCon Beijing 2023 (Conferencia Global de Desarrollo de Software) el 5 de septiembre.
Buenos días a todos, estoy muy feliz de compartir la práctica de monitoreo y diagnóstico inteligente de los AIOps observables de Alibaba Cloud en el lugar de estabilidad y observabilidad de QCon.
Soy Fanden del equipo de observabilidad nativa de la nube de Alibaba Cloud. Actualmente, es el principal responsable de la construcción comercial del producto observable AIOps Insights, la investigación y el desarrollo de soluciones AIOps y la exploración de grandes modelos en el campo observable en el equipo observable. Tengo mucha suerte de haber liderado los proyectos de evaluación de ARMS en "Gartner APM 2022" y "CAICT Root Cause Analysis Standard 2023" en los últimos años, por lo que hoy también compartiré algunas de mis experiencias durante el proceso de evaluación.
Hoy compartiré principalmente los siguientes cuatro aspectos.
Primero, presentaré brevemente cuáles son las capacidades principales de AIOps en el sistema observable.
La segunda parte es lo más destacado de hoy y se centra en los tres pilares de los escenarios AIOps que definimos en escenarios observables: detección, análisis y prácticas de convergencia. También compartiremos parte de nuestro resumen de arquitectura de ingeniería, arquitectura empresarial y modelos de algoritmos en esta sección.
La tercera parte consiste en analizar los puntos débiles y las necesidades de las empresas a través de casos de clientes específicos de AIOps observables.
Finalmente, también puede encontrar en los múltiples intercambios en esta conferencia que muchos de ellos tratan sobre modelos grandes y sus aplicaciones. Bajo tal tendencia, podemos observar los escenarios y direcciones en las que se pueden implementar AIOps.
Introducción a AlOps bajo sistema observable.
Bien, antes de comenzar la primera parte de compartir, echemos un vistazo también a las tres torturas del alma que las empresas desafían actualmente a AIOps:
-
¿Es AIOps una decoración?
-
¿Cómo medir el valor empresarial de AIOps?
-
¿Cómo implementar AIOps y cuánto cuesta?
Espero que durante mi intercambio de hoy, pueda hacer que todos piensen en la tortura del alma y encuentren algunas respuestas.
Se puede observar que con la popularización del concepto de nativo de la nube en los últimos años, cada vez más personas le prestan atención y lo mencionan. Pero no es un concepto nuevo en sí mismo. El primer concepto de observabilidad proviene de libros de cibernética, que enfatizan que el requisito previo para controlar un sistema es su observabilidad.
Creemos que la nueva generación de productos observables debe centrarse en las aplicaciones, vincularse hacia arriba con el éxito o el fracaso del negocio y la experiencia del usuario, y hacia abajo cubrir la infraestructura y el monitoreo de servicios en la nube. Entre ellos, se destaca la importancia de la experiencia del usuario, y es necesario centrar y desarrollar las capacidades de análisis empresarial, análisis del comportamiento del usuario y análisis de la causa raíz en caso de fallo. ¿Cómo implementar estas capacidades? Nuestra respuesta es AIOps.
El primer concepto de AIOps proviene del informe publicado por Gartner en 2016, que propuso por primera vez el concepto de operación y mantenimiento de TI basado en big data y algoritmos (Operaciones Algorítmicas de TI). Con el rápido aumento de la inteligencia artificial, Gartner amplió el concepto de AIOps de big data y algoritmos a inteligencia artificial (Inteligencia artificial para operaciones de TI, AIOps) en 2017. Cree que a través de big data, aprendizaje automático y tecnología de análisis avanzada, puede proporcionar Tiene la capacidad de ser proactivo, humano y visualizarse dinámicamente, mejorando directa o indirectamente las actuales capacidades tradicionales de operación y mantenimiento de TI (monitoreo, automatización, mesa de servicio). Por lo tanto, en la definición oficial, AIOps abarca los tres campos principales de monitoreo, ITSM y Ops.
Actualmente, AIOps ha aumentado desde 2016 hasta alcanzar el pico de expectativas en 2018/2019, y ahora AIOps se encuentra en la etapa del valle de la desesperación en la curva de conciencia del Efecto Dak.
Mi opinión personal es:
-
El concepto actual de AIOps es demasiado amplio , lo que da como resultado que no haya límites claros de productos ni elementos de competencia básicos para su implementación, lo que aumenta aún más la falta de claridad en la implementación.
-
Por otro lado, AIOps depende en gran medida de la recopilación, la calidad y la riqueza de los datos de los productos observables, lo que es muy coherente con las funciones de los productos observables. Sin embargo, la palabra clave "Ops" en AIOps a menudo se superpone demasiado con las funciones de DevOps. Esta dependencia excesiva de otros campos dificulta que AIOps se implemente verdaderamente como un producto independiente.
Creo que la mejor opción es profundizar en un campo específico en la etapa actual, como la observabilidad, y construir capacidades AIOps en varios escenarios observables, y luego formar gradualmente un producto de marca AIOps unificado. Foreign Datadog construye Watchdog y Dynatrace construye los productos de la marca AIOps de Davis, los cuales han verificado la viabilidad de este camino.
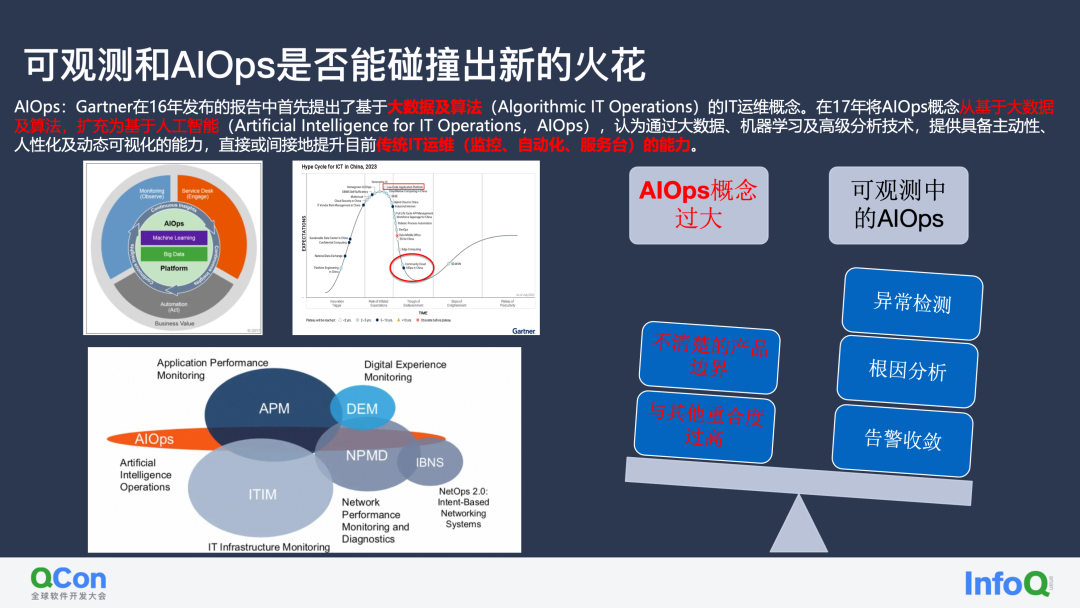
Por supuesto, en los últimos años, AIOps ha pasado de ser un concepto vago a uno que cada vez puede implementarse en un campo mediante métodos estandarizados. Los expertos de la Academia de Tecnología de la Información y las Comunicaciones y de varias empresas todavía desempeñan un papel importante. Podemos ver que AIOps El lanzamiento de los estándares del modelo de madurez de capacidad también puede ver el lanzamiento de elementos de evaluación para construir requisitos técnicos de análisis de causa raíz en el campo observable. Estos pueden guiarnos mejor para implementar AIOps observables.

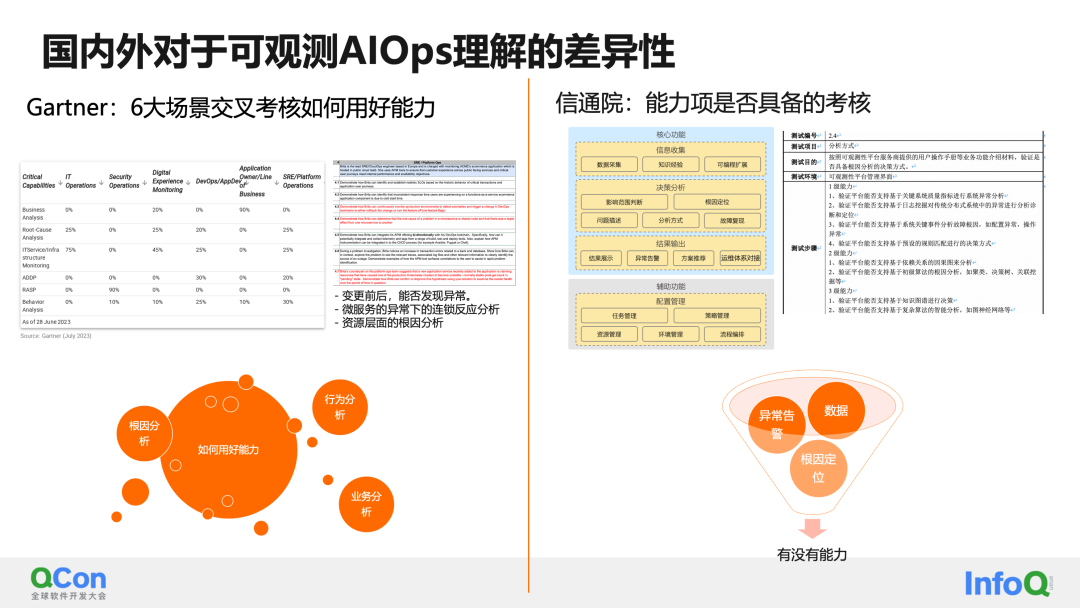
Por supuesto, actualmente existen ciertas diferencias en la capacidad de producción de AIOps en cada producto observable, o en la comprensión de AIOps observables en la evaluación de expertos nacionales y extranjeros.
Los representantes extranjeros típicos, como Gartner, elaboran cada año informes de análisis en el campo APM. En su evaluación de Capacidades Críticas (CC), se centran en seis categorías principales de escenarios: operaciones de TI, operaciones de seguridad, monitoreo de experiencia digital, DevOps, líneas de negocios y aplicaciones. y SRE se utilizan para diseñar preguntas de prueba, cada escenario tiene un rol simulado y una serie de problemas que deben resolverse. Por ejemplo, en el escenario SRE, es posible que deba ocuparse de:
- ¿Se pueden encontrar anomalías antes y después del cambio?
- Análisis de reacción en cadena bajo excepciones de microservicios
- Análisis de causa raíz a nivel de recursos
Desde la perspectiva de las capacidades básicas requeridas para la evaluación, AIOps debe desempeñar un papel muy importante en ellas, incluido: análisis del comportamiento del usuario, análisis comercial y análisis de la causa raíz en todo el enlace. El foco de la evaluación de Gartner también gira en torno a cómo hacer un buen uso de estas capacidades.
Los representantes nacionales pueden consultar el estándar "Requisitos técnicos del análisis de causa raíz" publicado por la Academia de Tecnología de la Información y las Comunicaciones este año. Los elementos básicos de capacidad de evaluación incluyen: recopilación de información, análisis de toma de decisiones y producción de resultados. La evaluación consiste en calificar los elementos de capacidad para ver en qué nivel se encuentran los elementos de capacidad de su producto actual. El objetivo de la evaluación aquí es ver si tiene capacidades AIOps.
Al comparar los requisitos de evaluación nacionales y extranjeros, los países extranjeros prestan más atención a la capacidad de hacer un buen uso de AIOps, mientras que las evaluaciones nacionales todavía se centran en si existen elementos de capacidad. De esto, podemos ver que debemos desarrollar aún más las capacidades de AIOps en Durante el proceso de implementación de AIOps y en la iteración continua, la clave para la implementación es continuar haciendo un buen uso de las capacidades de AIOps.
Bien, aquí tenemos una breve introducción a la observabilidad y los AIOps observables, y también hemos comprendido brevemente las diferencias en la comprensión de los AIOps observables en el país y en el extranjero. A continuación, el capítulo 2 es el foco de lo que compartimos hoy: echemos un vistazo a la práctica del equipo de observabilidad de Alibaba Cloud en monitoreo y diagnóstico inteligentes.
Práctica de diagnóstico y monitoreo inteligente de AlOps observable en la nube de Alibaba
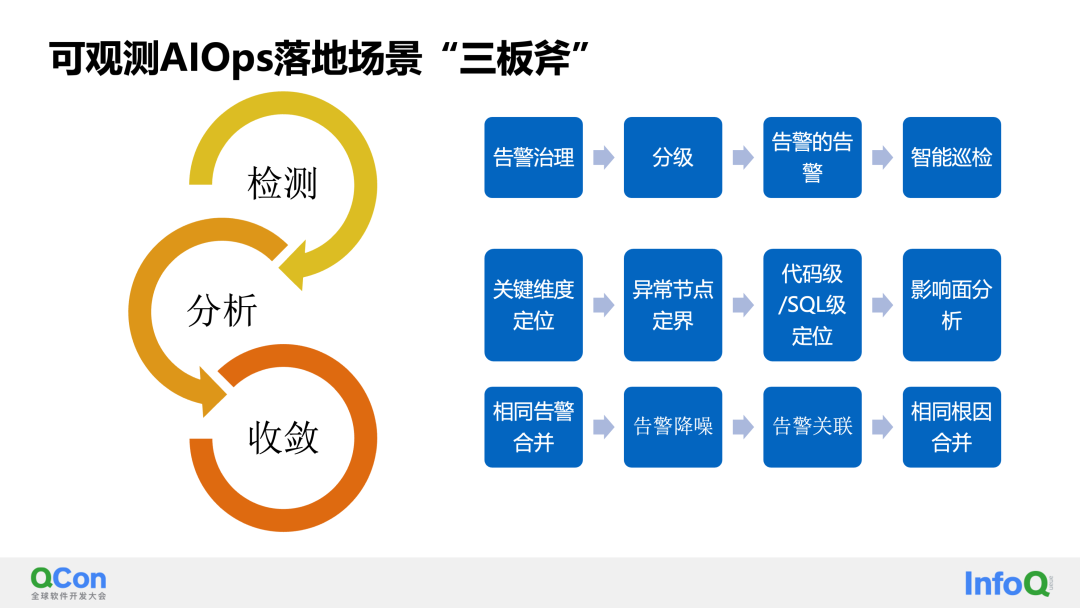
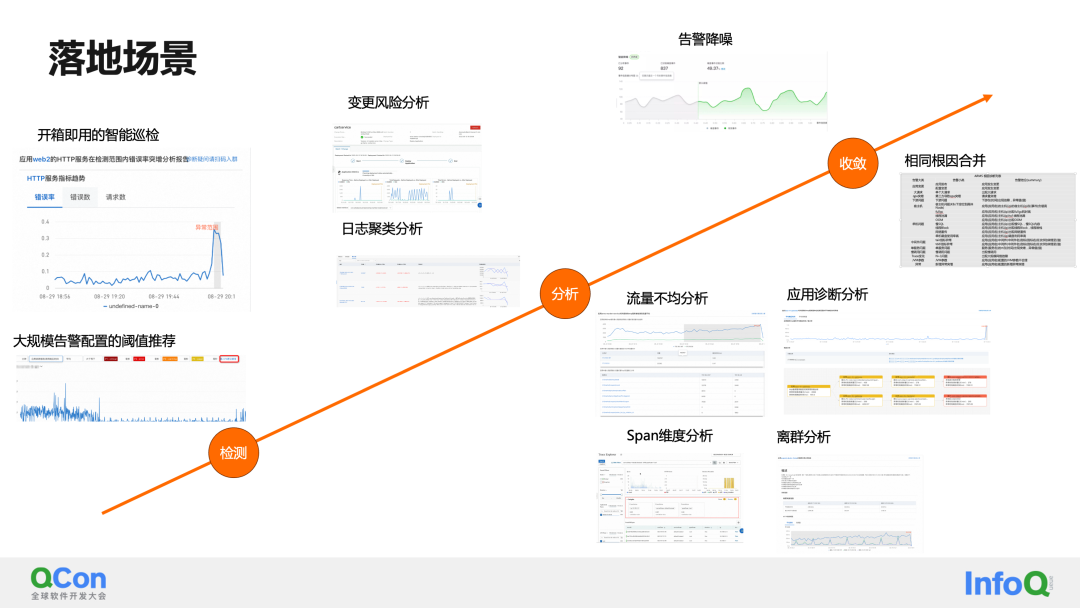
Primero, para la definición de escenarios AIOps observables, resumimos los tres puntos clave de implementación: detección, análisis y convergencia.
Creemos que en productos en el campo observable, debemos llevar a cabo prácticas de implementación e iteraciones continuas en torno a estos tres pilares: planificación de capacidad, autorreparación de fallas, seguridad, etc., mencionados en AIOps tradicionales, no están dentro del alcance de nuestras consideraciones de implementación.
Entre ellas, durante el proceso de implementación, resumimos las capacidades específicas que se pueden optimizar para cada placa:
El primero es detectar la escena:
-
Primero debemos realizar la gestión de alarmas sobre las reglas de alarma existentes en el sistema de alarma y las reglas de alarma que se configurarán. Clasifique qué objetos de detección deben configurarse para detectar problemas. Aquí hay un ejemplo: en el monitoreo empresarial, los indicadores centrales del negocio, como la cantidad de personas en línea y la tasa de éxito, son los objetos de alarma de detección que deben configurarse; en el monitoreo de aplicaciones, los tres indicadores dorados de la aplicación son RT (retraso promedio), Tasa de error (tasa de error) y QPS (volumen de solicitud) son los indicadores para los cuales se deben configurar las alarmas. Algunos indicadores deben usarse en el análisis de causa raíz, como indicadores de JVM, indicadores de recursos de infraestructura como el uso de CPU, etc.
-
En segundo lugar, debemos realizar un diseño jerárquico de reglas de alarma. Por un lado, podemos construir un mecanismo jerárquico para los indicadores centrales y los indicadores de alerta temprana: indicadores centrales como RT e indicadores de alerta temprana como el uso de CPU. Por otro lado, las reglas para los indicadores centrales también se pueden clasificar: por ejemplo, si el RT es de 50 ms a 200 ms, puede ser una alarma P3, y si el RT es de 50 ms a 1 s, debería ser una alarma P1. Además de definir manualmente el mecanismo de calificación, también podemos usar algoritmos para crear capacidades de mecanismo de calificación adaptativo.
-
El tercero es monitorear tormentas de alarmas o alarmas a gran escala, nuestra solución es detectar indicadores de alarma de alarma.
-
La cuarta es que, además de las alarmas de umbral manuales, necesitamos una inspección inteligente para proporcionar capacidades de inspección adaptativas para indicadores comerciales e indicadores altamente volátiles.
El siguiente es el escenario de análisis:
-
El primer elemento de capacidad que se puede construir en el escenario de análisis es posicionar las dimensiones clave de los indicadores multidimensionales. Por ejemplo: cuando se encuentra una anomalía en el número total de personas en línea, podemos conocer rápidamente los indicadores del número de personas en línea en todas las regiones realizando un análisis de posicionamiento dimensional en una determinada dimensión bajo el indicador, como la región (Beijing , Shenzhen, Shanghai) ¿Hay problemas en todas las áreas o es sólo un problema localizado en Shanghai? Esto puede reducir rápidamente el alcance de la falla. Se pueden utilizar capacidades similares en registros detallados multidimensionales y tramos de enlaces de llamadas.
-
Después de ubicar el rango de dimensiones del negocio, necesitamos tener un mecanismo que pueda ubicar rápidamente nodos anormales alrededor de la invocación de servicios en microservicios y las dependencias de recursos de los servicios. Nos referimos colectivamente a este elemento de capacidad como delimitación anormal de nodos. A través de la construcción de este elemento de capacidad, podemos saber rápidamente qué POD tiene un problema y realizar un análisis específico de la causa raíz anormal.
-
En el proceso real de solución de problemas, ¿es suficiente que proporcionemos nodos anormales? ¿Podemos analizar y solucionar problemas más a fondo y dar directamente la causa raíz real del error: al código, al nivel de pila de métodos o al nivel de comando SQL llamado? Esto requiere el soporte de capacidades de posicionamiento de causa raíz a nivel de código.
-
Finalmente, está el elemento de capacidad de análisis de la superficie de impacto, que a menudo es un punto que muchas personas tienden a pasar por alto en los escenarios de análisis de implementación. Sin embargo, el análisis de la superficie de impacto suele ser muy crítico: a través de él, podemos saber rápidamente a cuántas aplicaciones afecta actualmente una determinada falla, a cuántas solicitudes de transacciones afecta y a cuántos usuarios afecta. Esto es muy útil para el análisis de seguimiento de la experiencia del usuario. Por supuesto, desde el negocio hasta los servicios back-end y el análisis de usuarios, esto también requiere correlación a nivel de datos, lo que se puede lograr, por ejemplo, transmitiendo de forma transparente los ID de usuario en el negocio front-end-back-end.
Finalmente, los escenarios de convergencia se suelen utilizar para solucionar el problema de divergencia y alarmas excesivas en los sistemas de alarma:
-
En primer lugar, la capacidad que se puede crear es fusionar las mismas alarmas. Cuando la alarma no se recupera, las notificaciones se pueden enviar con la frecuencia de 1-5-10-30 y las notificaciones pueden incluir los atributos de los elementos del historial de envío.
-
También podemos realizar análisis de ruido en eventos de alarma para identificar cuánta información puede transmitir la alarma actual. Para aquellos eventos de alarma sin valor o de valor bajo, se pueden considerar como ruido y el ruido se puede filtrar. Por supuesto, hay varias formas de determinar específicamente si una alarma es ruido y compartiremos cómo lo implementamos más adelante.
-
El tercero es la correlación de alarmas. La correlación de alarmas no necesariamente reduce el número de alarmas, pero puede aumentar la densidad de información de las alarmas. Al adjuntar toda la información de alarma relevante al evento de alarma, el SRE puede recopilar más información al procesar una sola alarma, ayudando así en la resolución de problemas.
-
Finalmente, si el sistema construye un análisis de causa raíz, puede fusionar las mismas causas raíz durante la convergencia, logrando así verdaderamente una convergencia de alarmas.
A continuación, echemos un vistazo a algunos de los desafíos y soluciones específicos en la implementación de estos escenarios de tres ejes.
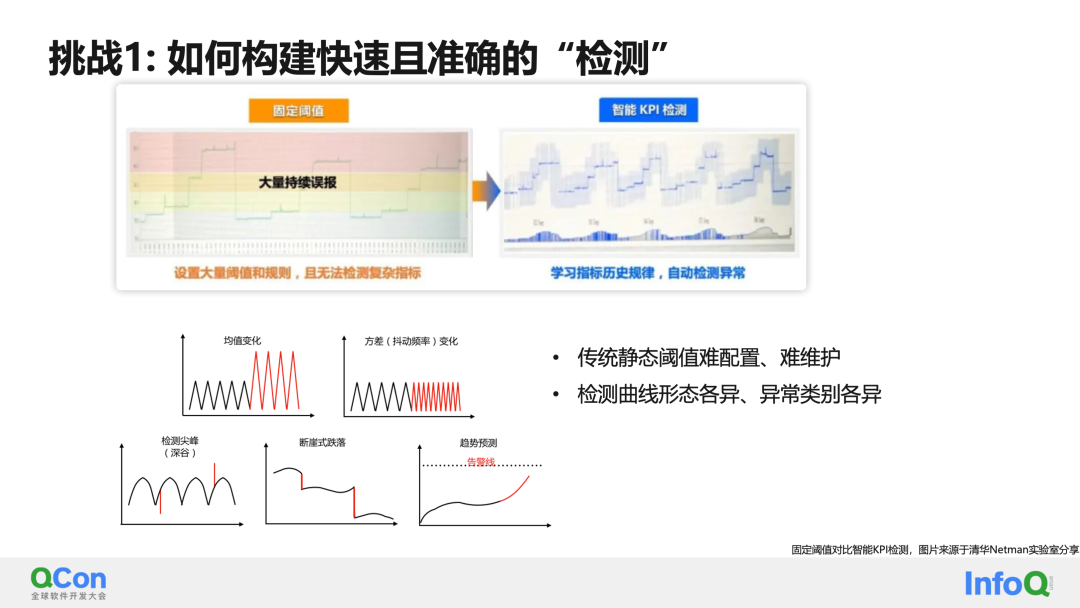
El primer desafío es: cómo crear una prueba rápida y precisa.
Creo que en los últimos años cada vez más personas conocen las ventajas de la detección inteligente en comparación con la detección de umbrales tradicional. Por un lado, los indicadores comerciales no son umbrales fáciles de configurar, por otro lado, los umbrales deben ser ajustar periódicamente mantenimiento. Por el contrario, la detección inteligente puede capturar y aprender de forma adaptativa sus patrones históricos para obtener buenas capacidades de detección continuas. Sin embargo, construir una solución de detección inteligente no es tan fácil. Los dos mayores desafíos aquí son:
- Los indicadores vienen en diferentes formas.
- La definición de anormalidad no está clara, incluidos cambios anormales en los valores medios, tendencias anormales e incluso derivas periódicas. Algunas personas también pueden considerarlos anormales.
Echemos un vistazo a la clasificación de las soluciones de prueba que actualmente se entienden generalmente en la industria:
Los más utilizados son los algoritmos estadísticos, incluida la comparación del mismo ciclo, k-sigma, diagramas de caja, etc.
Para el algoritmo de comparación del mismo ciclo, la comparación ciclo por ciclo es si la tasa de cambio del valor de comparación excede un umbral establecido, y la comparación año tras año es si el valor del mismo período excede el umbral establecido. Estos algoritmos funcionan bien en escenas fijas y muy periódicas.
El segundo algoritmo estadístico es k-sigma. Cuando la distribución de datos se ajusta a la distribución normal, la mayoría de los puntos fluctúan alrededor de la media. La probabilidad de exceder la desviación estándar más o menos tres veces la media es del 0,3%, lo cual es un evento de probabilidad pequeño. Este tipo de algoritmo identifica pequeños valores de probabilidad como anomalías, evolucionando así el algoritmo de detección k-sigma.
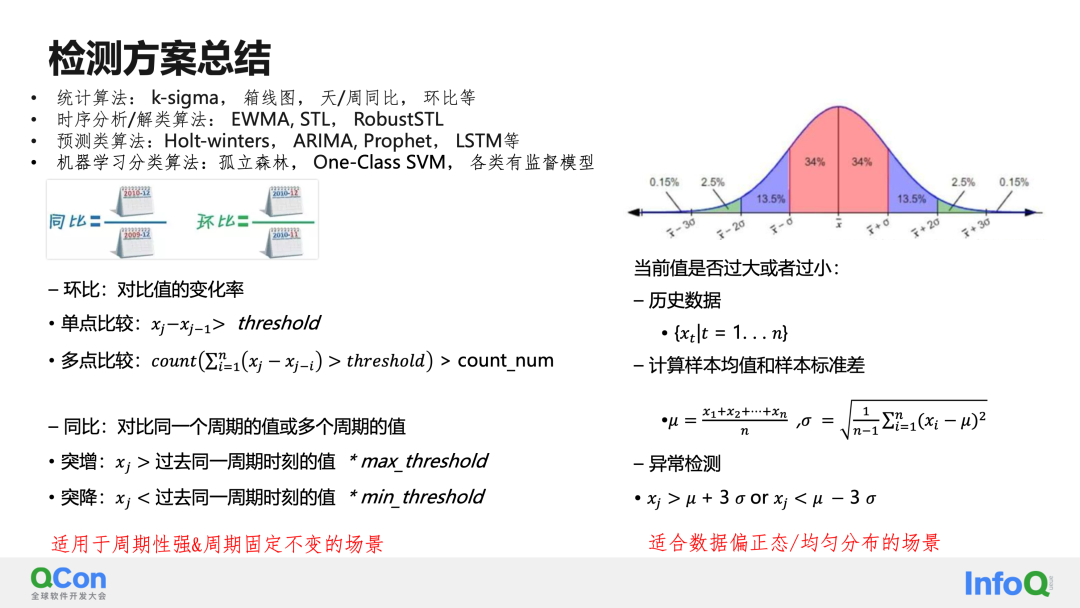
La segunda categoría más grande de algoritmos de detección son los algoritmos de análisis de tiempos y descomposición de tiempos, como EWMA, STL, etc. Tomando STL como ejemplo, se cree que cualquier serie de tiempo se puede descomponer en términos periódicos, términos de tendencia y términos residuales. Al descomponer la serie temporal, los elementos de tendencia y los residuales se detectan por separado, para lograr mejores resultados de detección.
La tercera categoría principal de algoritmos de detección son los algoritmos de predicción, normalmente como Prophet y LSTM. Estos algoritmos predicen tendencias y límites razonables en el futuro ajustando las tendencias de los indicadores históricos. Cuando los valores reales exceden los límites superior e inferior del ajuste, se consideran valores atípicos. Tomando a Prophet como ejemplo, este algoritmo se puede dividir en 4 pasos principales. El primer paso es seleccionar puntos de cambio en los datos de la curva y detectar automáticamente cambios en las tendencias. El segundo paso es descomponer la construcción de tiempo. En comparación con el STL tradicional, Prophet admite agregar fechas de vacaciones a través de la configuración, resolviendo así el problema de la detección inexacta causada por los efectos de las vacaciones. El tercer paso es ajustar las tendencias y períodos obtenidos por separado, y luego sumarlos/multiplicarlos para obtener la curva ajustada. Finalmente, el límite superior se calcula a través de la diferencia de distribución entre el valor predicho y la curva real. En realidad, este paso es similar a la construcción tradicional de límites de detección de EWMA, pero Prophet es muy amigable para comenzar con la práctica. Puede obtener rápidamente un detector con una puntuación de 60 a 80 mediante un simple ajuste de parámetros. Si está interesado, puede probar él.
La última categoría son los modelos de aprendizaje automático/aprendizaje profundo, que consideran el problema de detección como un problema de 2 clasificaciones y obtienen un detector utilizable mediante entrenamiento supervisado. Este tipo de modelo de algoritmo es más adecuado para su implementación en escenarios que ya tienen un determinado conjunto de datos etiquetados. Otra idea es utilizar una combinación de aprendizaje activo para realizar aprendizaje no supervisado en series de tiempo normales para hacer frente a condiciones normales y anormales típicas, y luego combinar algunos métodos de etiquetado de casos límite para realizar capacitación supervisada para mejorar las capacidades de clasificación. Modelos de aprendizaje automático/aprendizaje profundo en el caso de muestras pequeñas.
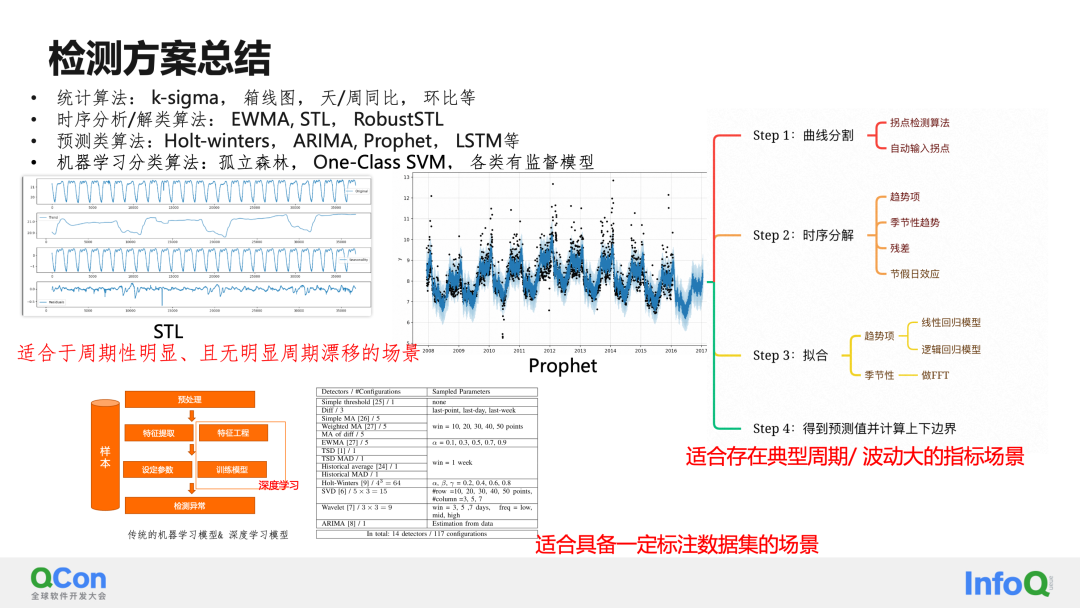
Teniendo en cuenta las definiciones de varios tipos de anomalías y las ventajas y desventajas de varios modelos de algoritmos, adoptamos una solución de detección de fusión multimodelo. Combinando varios modelos no supervisados y el modelo xgboost que entrenamos en algunos escenarios y a través del mecanismo de votación. , integramos múltiples modelos.Una solución de integración de detección. El plan general se divide en 3 pasos principales:
1. Capa de datos: esta capa realiza principalmente la verificación de datos (verificación de validez, verificación de valores faltantes) y el preprocesamiento de datos (procesamiento de valores faltantes, procesamiento de normalización), etc.
2. Capa de algoritmo: la capa de algoritmo adopta la solución de votación multimodelo STL + en su conjunto. A través de STL se realiza la periodicidad y la identificación de tendencias. Aquí implementamos la determinación de ciclos múltiples a través de tres esquemas: FFT, ACF y similitud de fragmentos.
3. Capa empresarial: la capa empresarial completa principalmente la configuración personalizada del negocio, el procesamiento de indicadores especiales y la construcción de estrategias algorítmicas centradas en el negocio. Tales como: nivel de confianza de valores atípicos, intervalos anormales e intervalos normales.
El algoritmo general se puede observar en detalle a partir de tres características:
- La idea de "combinación de largo y corto plazo presentada por LSTM", combinación de características a corto plazo y características a largo plazo.
La detección de características a largo plazo no solo mejora el efecto de detección, sino que también puede implementar soluciones de detección dinámica de bajo costo a través de características de secuencia a largo plazo y cálculos de límites para algunos escenarios de detección que esperan un bajo costo.
- “Divide y vencerás”, diferentes detectores con diferentes tiempos
- Para indicadores con fuerte estacionariedad, partimos de la eficiencia de detección y generalmente utilizamos un detector fuerte que es una combinación de múltiples detectores débiles, que incluyen: K-sigma KDE, EWMA y diagramas de caja.
- Para los indicadores no estacionarios, Insights primero diferencia los indicadores y luego los convierte en un modelo de detección general para la detección después de pasar la verificación de estacionariedad.
- Para indicadores con una fuerte periodicidad, combinados con Fourier y similitud, se lleva a cabo una identificación precisa de uno o varios ciclos y la detección de anomalías generales se realiza después de eliminar los ciclos.
- Para escenarios con conjuntos de datos de detección, la inspección de Insights puede admitir xgboost, bosque aislado y otros algoritmos de detección e identificación.
- "Mecanismo de votación", que utiliza múltiples detectores débiles para formar un detector fuerte
Los algoritmos débiles comunes en la industria, como K-sigma, algoritmo de diagrama de caja, KDE y EWMA, son detectores básicos en la solución de fusión. Utilizando una variedad de detectores débiles, se construyó y optimizó un algoritmo de detector fuerte en función de la estrategia de votación.
En resumen, bajo la guía de dicho "mecanismo de votación", "divide y vencerás" y "combinación de características largas y cortas", en general hemos logrado buenos resultados en la detección de los tres indicadores dorados manteniendo la mayoría de los modelos sin supervisión. La tasa de precisión de las muestras anormales es del 95%, la tasa de recuperación es del 90% y la tasa de precisión general es superior a la puntuación de evaluación del 95%

En un entorno nativo de la nube, la topología entre servicios es compleja y una aplicación puede llamar directa o indirectamente a cientos de microservicios, por lo que es necesario localizar la causa raíz de forma rápida, precisa y a bajo costo . El segundo mayor desafío en el escenario de implementación "Three Banaxe" es cómo implementar de manera rápida y rentable el análisis de causa raíz en un escenario de microservicios.
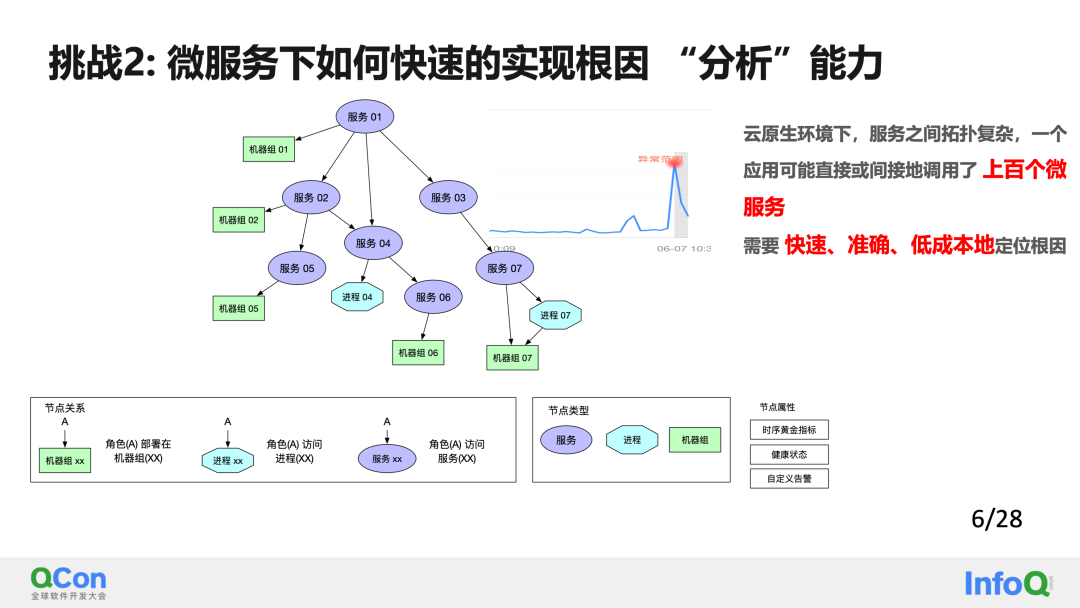
Actualmente, la ubicación típica de la causa raíz se puede dividir en tres categorías:
El primero es el posicionamiento multidimensional : cuando ocurre una anomalía en un KPI multidimensional, la forma de ubicar la dimensión de la causa raíz también se denomina análisis detallado del indicador.
El segundo tipo es el posicionamiento asistido por correlación : este tipo de posicionamiento encuentra la correlación entre diferentes indicadores cuando ocurre una falla utilizando la relación entre indicadores (correlación CMDB, los algoritmos incluyen: similitud, extracción frecuente de elementos, etc.).
La última solución es el posicionamiento de topología/enlace de llamada : este tipo de análisis de causa raíz generalmente tiene un diagrama de topología de llamada de servicio claro y enlaces de llamada en tiempo real. Esquemas como paseo aleatorio/modelado general basado en gráficos topológicos.

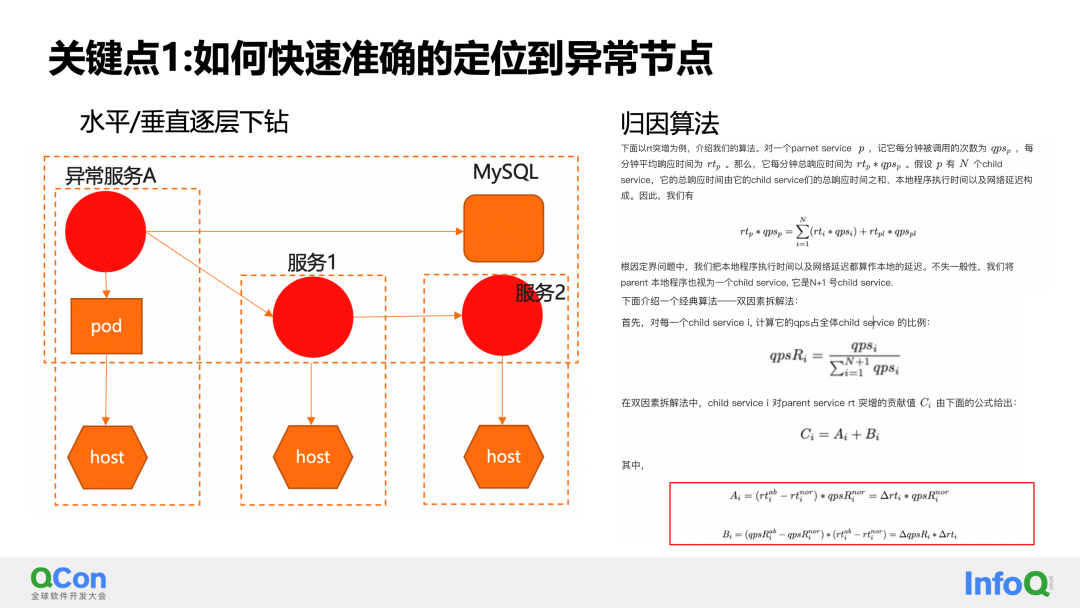
Aquí desglosamos el análisis de la causa raíz a nivel de microservicio en 2 puntos clave. El primer punto clave es: cómo localizar nodos anormales a bajo costo.
La solución que damos aquí es ordenar la topología de los microservicios horizontal y verticalmente. El nivel se divide en llamadas entre servicios. Dividido verticalmente en implementación dependiente de servicio a recurso. Cada uno puede ser una relación de 1 a muchos. Después de dicha clasificación, podemos construir un análisis detallado capa por capa sin obtener el mapa topológico completo. Es decir, sólo se necesitan la información del nodo de la capa actual y la información del nodo de la siguiente capa. La ventaja de esto es que el costo de extracción de datos es mucho menor que el del modelado general: es esencialmente una capa de poda en el mapa topológico.
En cuanto al análisis detallado específico de cada capa, diseñamos un modelo de algoritmo de atribución basado en el escenario de microservicio. Tomando como ejemplo el algoritmo de atribución de dos factores, para el indicador de llamada de clase RT, cuando ocurre una excepción en RT, se deben considerar dos factores: el volumen de solicitud de servicio y el tiempo de solicitud. Al desmantelar los dos factores, podemos conocer con precisión el impacto de los cambios en cada factor sobre los cambios en el resultado general final. De esta manera, a través de modelos de algoritmos de atribución y perforación capa por capa, podemos lograr una delimitación de nodos anormales precisa y de bajo costo.
El segundo punto clave es que en el proceso de creación de un análisis de causa raíz, pensamos constantemente en qué tipo de sistema de análisis deberíamos proporcionar. ¿Es suficiente proporcionar nodos de excepción e información relacionada con las excepciones? Muchas soluciones en la industria actual se implementan en la primera capa y al final y, después de proporcionar nodos e información anormales, dependen más del juicio de los expertos en operación y mantenimiento.
Hemos ido un paso más allá y modelado muchos de los pasos y procesos de análisis de los expertos en operación y mantenimiento a través de árboles de decisión. De esta manera, después de localizar el nodo anormal, podemos analizar más a fondo el código, las llamadas a la pila de métodos, los indicadores, los registros de excepciones y otra información en el nodo anormal para lograr un análisis de la causa raíz a nivel de código.
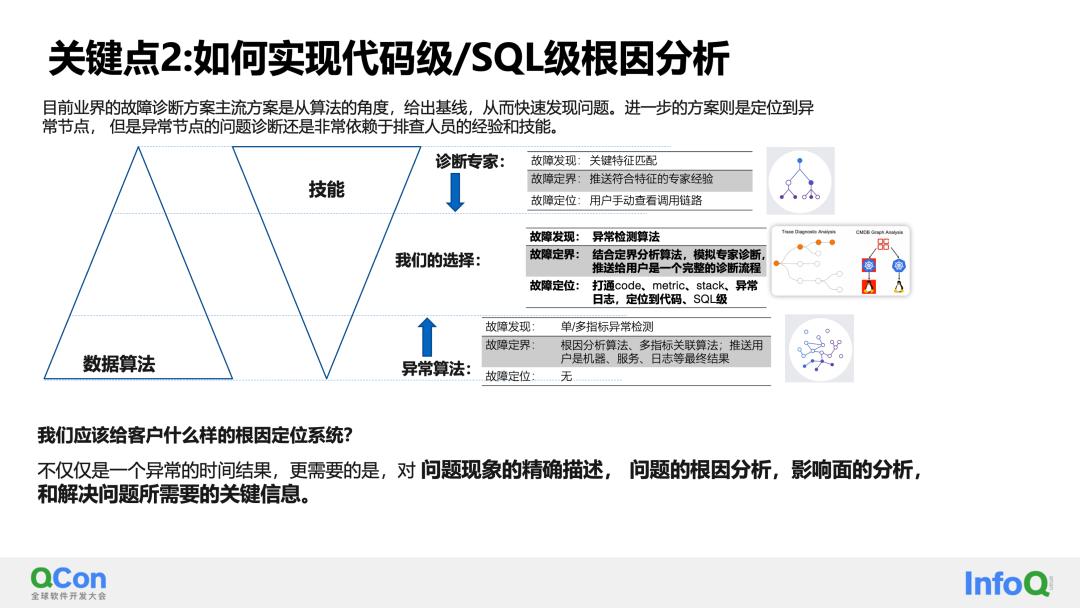
La solución general se basa en el modelado de árbol de decisión de algoritmo + sistema experto. Primero analiza las contribuciones de dependencia del servicio horizontalmente y analiza verticalmente las anomalías de la infraestructura para delinear fallas y lograr nodos anormales específicos. A través del análisis de complementos expertos, se puede implementar un análisis en profundidad de fallas típicas basado en complementos en nodos anormales específicos, logrando así en general una capacidad de análisis de causa raíz desde la delimitación de nodos hasta el nivel de código.
Actualmente, hemos implementado complementos expertos para el modelado de árboles de decisión para una variedad de escenarios, como problemas de dependencia descendente, problemas de SQL lento, problemas de tráfico desigual, etc. Hemos implementado la ubicación de la causa raíz a nivel de código para estos escenarios.
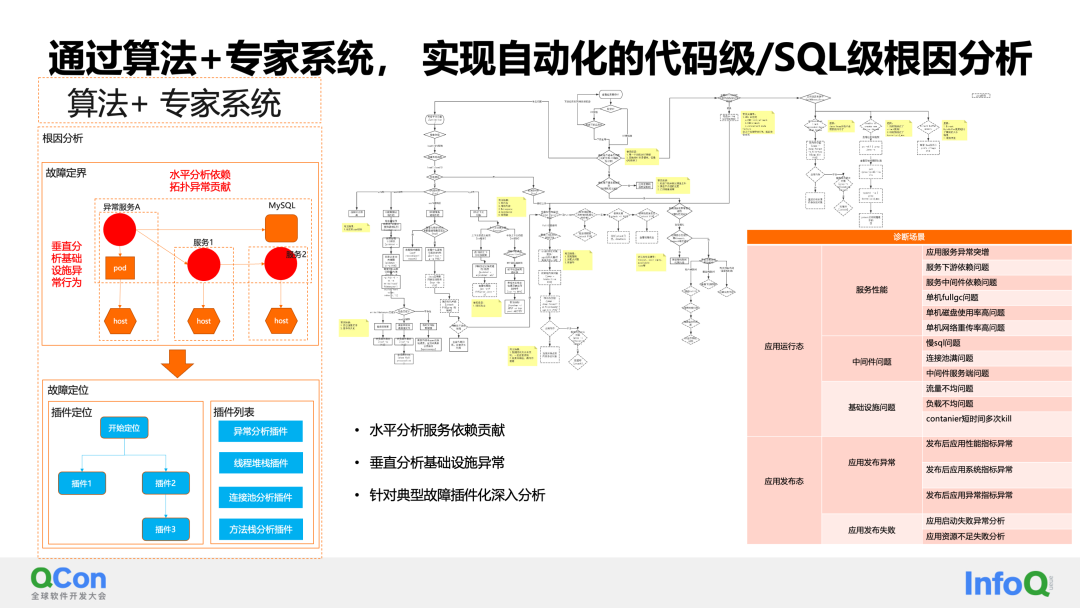
Finalmente, en el escenario de análisis, veamos casos de uso específicos.
La primera es que el indicador RT de una determinada aplicación de usuario aumenta repentinamente de manera anormal. Con la detección y resolución de problemas manuales tradicionales, primero debe configurar las alarmas relevantes para esta aplicación. Después de recibir la alarma, debe recopilar manualmente información anormal: verifique el registro , comprobar alarmas, leer el mercado y ejecutar comandos temporales. Luego, se puede lograr el análisis y la determinación de la causa raíz mediante la comprensión de la situación de implementación del sistema, el conocimiento de diversos dominios, etc.
En cuanto al monitoreo y diagnóstico inteligentes, el evento anormal se identifica de manera inteligente y se determina el nivel de gravedad sin necesidad de configuración. Mientras se enviaban notificaciones a los usuarios, se realizó un análisis de la causa raíz. En el informe de diagnóstico de causa raíz, enumeramos las razones de este aumento repentino en el consumo de tiempo: algunas interfaces de la aplicación B tuvieron un aumento repentino en el consumo de tiempo al ejecutar solicitudes SQL, lo que provocó que el RT de la aplicación ascendente se volviera alto.
Con base en esta información, el usuario confirmó rápidamente y finalmente descubrió que el problema se debía a una falla del índice SQL.

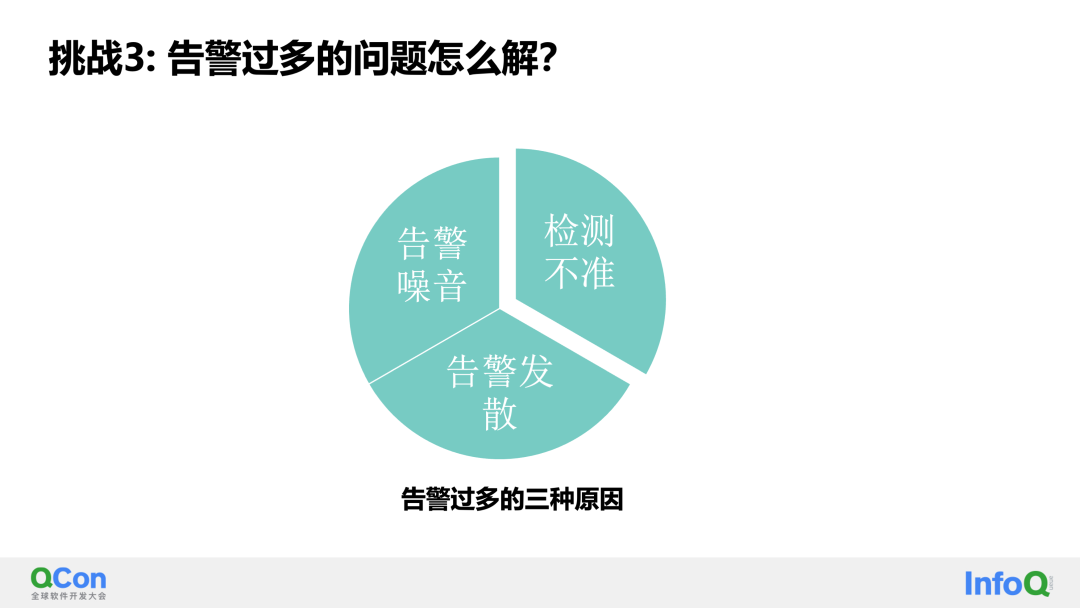
El tercer desafío resuelto por Banaxe es ¿cómo solucionar el problema del exceso de alarmas? Primero, analicemos por qué hay demasiadas alarmas. Generalmente hay tres razones:
-
Una detección inexacta da como resultado configuraciones de alarma conservadoras.
-
Naturalmente, en el sistema existe una cierta cantidad de ruido de alarma.
-
Las alarmas relevantes se configuran en varios lugares. Por ejemplo, si las alarmas se configuran en una máquina y las alarmas se configuran en los servicios de la máquina, las alarmas aparecerán en varios lugares de la máquina y los servicios. De hecho, la causa subyacente es la misma raíz. causa de la falla.
A través de métodos de convergencia, podemos identificar algo de ruido en las alarmas y las alarmas divergentes se pueden resolver mediante métodos de correlación y fusión de causas raíz.
Veamos primero varias soluciones de convergencia en los escenarios actuales de la industria:
La primera es realizar una agrupación similar en el contenido de los eventos de alarma, como títulos de alarma comunes y contenidos de alarma. La relevancia del contenido de las alarmas a menudo depende de los campos seleccionados, y muchos contenidos de las alarmas se generan mediante plantillas, lo que interfiere mucho con la similitud del texto y reduce la precisión.
El segundo método consiste en realizar una correlación similar en la serie temporal generada por la alarma. Estos dos esquemas son relativamente simples y directos, pero la desventaja es que a menudo son correlaciones construidas y no son muy deterministas. Se puede mostrar como información relacionada.
El tercer método consiste en extraer elementos frecuentes en elementos de alarma históricos para determinar si existe una cierta correlación entre diferentes objetos de alarma. Esta solución todavía tiene sentido a primera vista, pero en el proceso de implementación real, encontrará que, de hecho, las que aparecen juntas con frecuencia pueden contener múltiples correlaciones. La simple construcción de correlaciones a través de este método conducirá a una precisión deficiente.

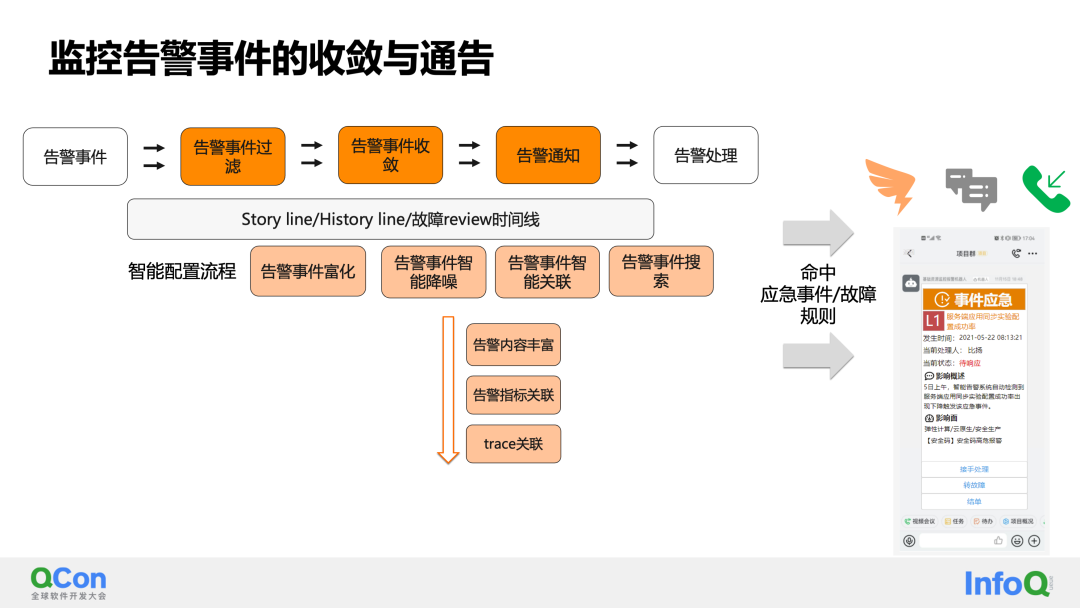
Nuestra solución de convergencia combina las ventajas de múltiples opciones tecnológicas para crear un flujo de análisis y procesamiento de eventos. La parte más central es:
-
El filtrado general de los eventos de alarma se basa en el reconocimiento inteligente del ruido de alarma. Los identificados como ruido se pueden degradar o incluso filtrar.
-
La convergencia de eventos de alarma contiene dos dimensiones de información relacionada:
La primera es correlacionar los eventos de alarma históricos del objeto de alarma: esto puede proporcionar a los expertos en operación y mantenimiento información histórica de alarmas, sugerencias de manejo, etc.
El segundo es asociar la información relevante actual del objeto de alarma (como mapas de topología ascendentes y descendentes, indicadores de alarma relacionados, etc.).
Un caso bajo convergencia es: identificación de ruido de eventos de alarma.
Para cualquier alarma, se puede dividir en uno de los siguientes cuatro tipos:
- Ruido: La alarma actual sirve de poco y es prescindible.
- Novedad: eventos de alarma inesperados o alarmas que nunca se han visto o que rara vez se ven.
- Importante: alarmas para indicadores clave
- Anormalidad: La frecuencia de aparición de la alarma ha cambiado. Por ejemplo: aunque un determinado evento de alarma es ruido, antes ocurría 5 veces al día y ahora ocurre 50 veces al día. Entonces esto puede representar un cambio importante en el sistema.
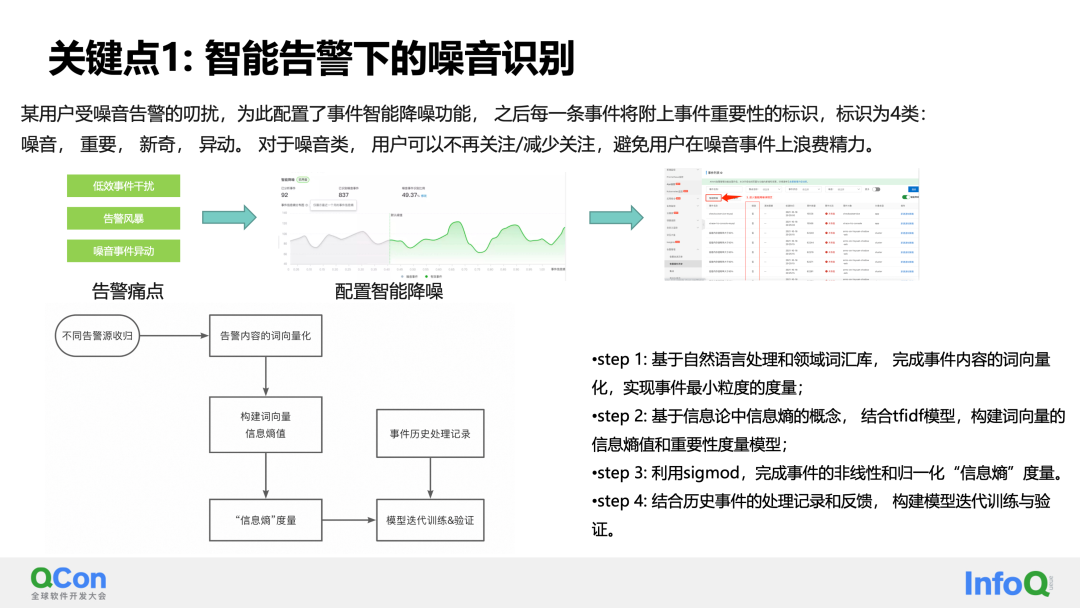
Al clasificar los eventos de ruido, podemos utilizar el algoritmo PNL y el modelo de entropía de la información para calcular la cantidad de información contenida en una alarma.
El conjunto se divide en cuatro pasos:
- Paso 1: basándose en el procesamiento del lenguaje natural y la base de datos de vocabulario de dominio, complete la vectorización de palabras del contenido del evento y logre la medición de granularidad mínima de los eventos;
- Paso 2: Basado en el concepto de entropía de la información en la teoría de la información, combinado con el modelo tfidf, construya el valor de entropía de la información y el modelo de medición de importancia de los vectores de palabras;
- Paso 3: utilice sigmod para completar la medición de "entropía de información" no lineal y normalizada del evento;
- Paso 4: combine los registros de procesamiento y la retroalimentación de eventos históricos para crear un modelo para capacitación y verificación iterativas.
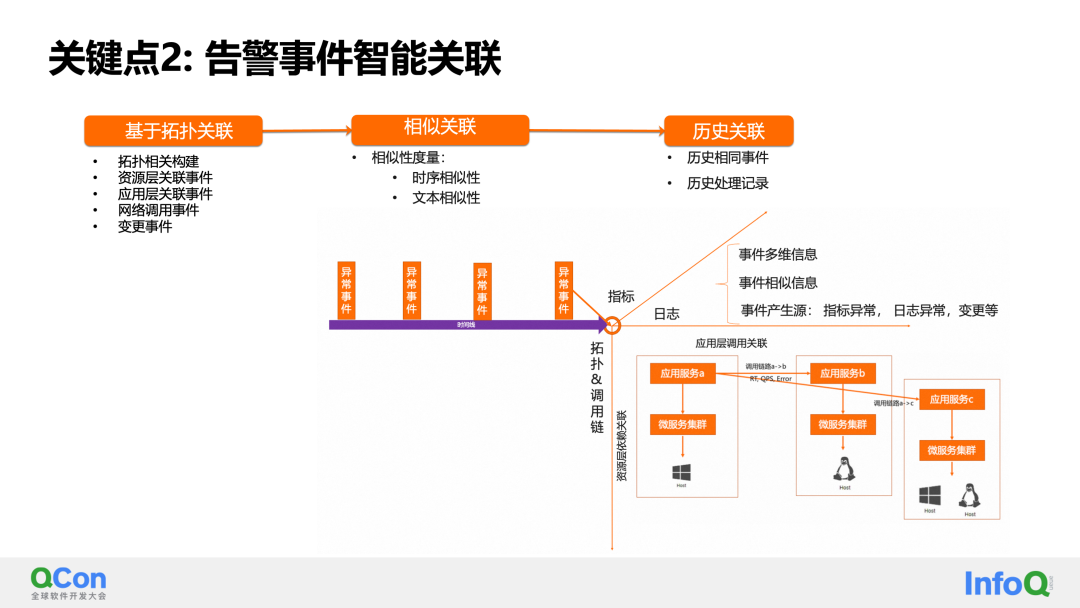
El segundo punto clave es que se pueden asociar eventos de alarma. Aquí intentamos correlacionar información desde múltiples ángulos. Esto incluye asociaciones deterministas basadas en la topología, como prácticas relacionadas con la capa de recursos, prácticas relacionadas con la capa de aplicación, eventos relacionados con llamadas de red y eventos de cambio dentro de la ventana de tiempo. En segundo lugar, se pueden construir asociaciones basadas en similitudes, como la similitud de series temporales y la similitud de textos de alarma. Finalmente, también existe una correlación histórica, como la ocurrencia de los mismos eventos en la historia, los manejadores y los registros de manejo en ese momento.
Bien, aquí hemos compartido la práctica del escenario de tres pasos de detección-análisis-convergencia. Introduzcamos algunas cosas más generales a continuación. Si desea crear AIOps observables de 0 a 1 hoy, creo que puede tomar el siguiente contenido y usarlo directamente.
El primero es el modelo de algoritmo AIOps generalizado. Aquí resumimos y comparamos los algoritmos de la escena Sanbanax, y los comparamos desde múltiples perspectivas, como la complejidad común del espacio-tiempo, la complejidad de la muestra y la interpretabilidad. Debido a razones de tiempo, no ampliaremos la comparación de algoritmos aquí. El contenido no es Los estudiantes interesados pueden realizar un análisis comparativo detallado del PPT después de la reunión.




El segundo es la arquitectura de ingeniería que pueden utilizar los AIOps.
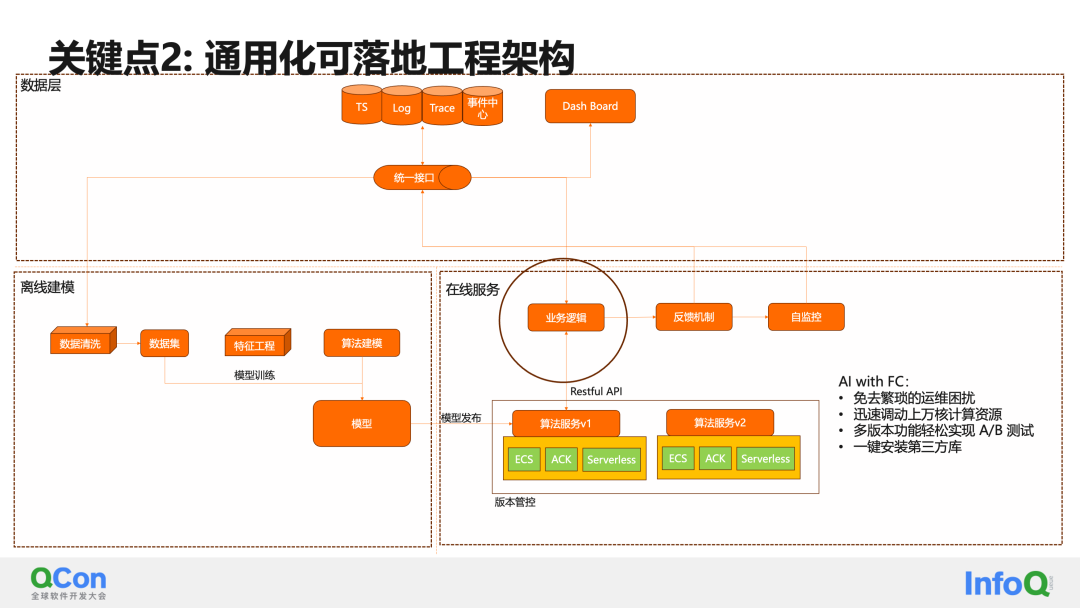
En un proyecto de IA, las partes clave suelen ser tres partes principales: capa de datos, modelado fuera de línea y servicios en línea.
En la capa de datos, interactuamos con la base de datos de series temporales, la biblioteca de seguimiento de registros y el centro de eventos mediante la creación de una interfaz unificada.
Una vez que los requisitos específicos del escenario AIOP son claros, a menudo realizamos primero el modelado fuera de línea, obtenemos los datos correspondientes a través de una interfaz de datos unificada y los limpiamos en un conjunto de datos fuera de línea. Luego realice modelado y entrenamiento iterativo de acuerdo con el modelo específico.
Después de entrenar un modelo utilizable, se puede publicar a través de la plataforma de algoritmos. Aquí está la versión del servicio de algoritmo. Recomiendo la solución FC. Principalmente no requiere operación ni mantenimiento y puede implementar fácilmente pruebas A/B para funciones de múltiples versiones.
En la capa de servicios en línea, se construyen una lógica empresarial específica, un mecanismo de retroalimentación y capacidades de autocontrol. Los servicios de algoritmos y lógica empresarial pueden interactuar a través de API.
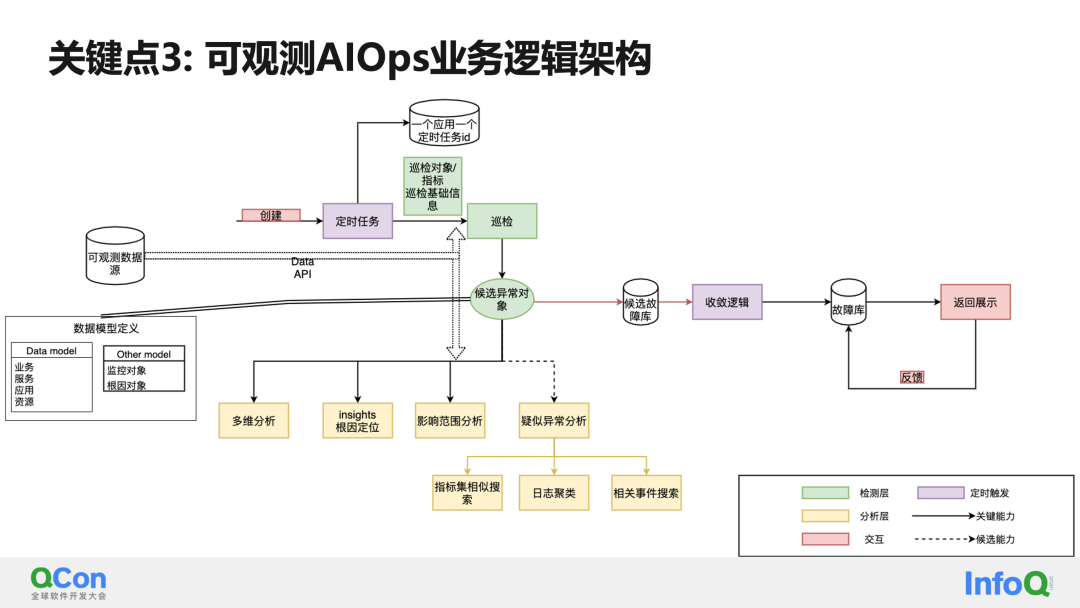
En cuanto a la arquitectura de lógica empresarial de AIOps observables, puede consultar esto:
La primera es la necesidad de interactuar con fuentes de datos observables a través de una API unificada. Otra cosa que debe enfatizarse es el modelo de datos, incluido el modelo de objetos de datos para su detección, el modelo de objetos para el análisis de causa raíz, etc., que deben tener una definición unificada.
Después de conectarse a la detección inteligente, el sistema puede crear una tarea programada para realizar inspecciones programadas. Cuando se detecta una excepción durante la inspección, la excepción se coloca en la biblioteca de objetos de excepción candidatos. En este momento, el módulo de análisis se puede activar de forma sincrónica/asincrónica.
El módulo de análisis incluye lo antes mencionado: análisis multidimensional, análisis de ubicación de causa raíz de microservicios, análisis de alcance de influencia, análisis de correlación, etc.
Al mismo tiempo, para la biblioteca de anomalías candidatas, el sistema tiene una lógica de convergencia de temporización, que realiza cálculos de convergencia sobre las fallas en la biblioteca de fallas candidatas de manera programada y actualiza los datos convergentes en la biblioteca de fallas de manera sincrónica.
Finalmente, las alarmas en tiempo real y las listas de problemas de convergencia de la pantalla del tablero interactúan con la biblioteca de fallas.
Bien, después de analizar detalladamente la práctica de diagnóstico y monitoreo inteligente de AIOps observables e introducir la comparación de arquitectura de ingeniería generalizada, arquitectura empresarial y modelos de algoritmos, veamos un caso específico en la nube pública.
Casos específicos observables de AlOps
Transsion Holdings utiliza Spring Cloud para implementar microservicios de aplicaciones integrales. La aplicación se ejecuta en Alibaba Cloud Container Service ACK y se distribuye en Europa, Asia y otras regiones, logrando verdaderamente un sistema de servicios multirregional. Para este sistema, es un gran desafío construir un sistema observable completo. Incluye principalmente 4 puntos débiles importantes:
El primer punto débil es que los objetos de observación son complejos y numerosos: los objetos de observación están distribuidos en diferentes pilas de tecnología y arquitecturas, y es un gran desafío lograr una cobertura y un enfoque integrales.
El segundo punto débil es la lentitud en la resolución de problemas en línea: la estructura empresarial después de los microservicios se ha vuelto compleja y la resolución de problemas en línea requiere analizar enlaces de llamadas complejos, lo que lleva mucho tiempo.
El tercero es la dificultad de la promoción interna: con frecuencia se lanzan nuevos servicios y algunas empresas no están dispuestas a conectarse a la plataforma observable para reducir la carga de trabajo del lanzamiento y requerir promoción adicional.
El cuarto punto débil es la dificultad para agregar fuentes de datos de monitoreo: después del despliegue multirregional, cada región tiene una plataforma observable independiente y los datos observables dispersos en múltiples regiones no se pueden agregar.
Entre ellos, el más relevante para las AIOps observables es la lentitud en la resolución de problemas en línea. Esperamos ayudar a mejorar la eficiencia del diagnóstico mediante la integración del diagnóstico de enlaces de seguimiento y capacidades AIOps observables.
Para abordar estos cuatro puntos débiles, las soluciones proporcionadas por ARMS son:
1. Solución de acceso no intrusivo: solo necesita agregar 2 líneas de anotaciones al implementar la aplicación e inyectar automáticamente el Agente para realizar un monitoreo de enlace completo, no hay intrusión en el código y el equipo de operación y mantenimiento no Necesitamos gastar energía en promover la plataforma observable.
2. Proporcionar un sistema de indicadores unificado: a través de ARMS y la versión de monitoreo observable de Prometheus, se establece un sistema de indicadores unificado que cubre la capa de recursos, la capa de contenedor, la capa de servicio, la capa de aplicación y la capa de experiencia del usuario para lograr una cobertura completa desde puntos únicos dispersos hasta Gran escala.
3. Seguimiento y diagnóstico de enlace completo: después de acceder al monitoreo de aplicaciones ARMS, puede verificar fácilmente el estado y las dependencias del servicio. Cuando ocurre un problema en línea, toda la cadena de llamadas se puede rastrear y ubicar rápidamente a nivel de código, lo que mejora en gran medida la eficiencia de la resolución de problemas.
4. Agregación de datos globales: a través de la instancia de agregación global de la versión de monitoreo observable de Prometheus y el centro de alarma inteligente, los sistemas comerciales implementados en todo el mundo se pueden presentar y alarmar de manera unificada.
Finalmente, después de establecer nuevas capacidades técnicas observables, Transsion Holdings no solo mejoró la eficiencia del diagnóstico de problemas, sino que también mejoró enormemente la experiencia del usuario. Los clientes también han reconocido las capacidades de detección de anomalías y diagnóstico inteligente proporcionadas por Observable AIOps.

En la era de los grandes modelos, ¿adónde irán los AlOps observables?
Finalmente, en la era de los grandes modelos, ¿adónde irán los AIOps observables? Como se puede ver en los temas compartidos de QCon esta vez, los modelos grandes y sus aplicaciones son muy populares, y todos están pensando en cómo reconstruir los escenarios de aplicaciones originales a través de modelos grandes.
En el campo de la observabilidad, los modelos grandes han traído algunos cambios nuevos. En la actualidad, los fabricantes extranjeros de observables han utilizado la ayuda de chatgpt para mostrar demostraciones de sus propios modelos observables grandes. Incluye principalmente grok como: nueva reliquia. Cuando chatgpt apenas comenzaba a ganar popularidad en abril-mayo, fue el primero en lanzar Grok, conocido como el primer asistente de IA generativa en el campo observable.
Datadog ha sido líder en el campo de la observabilidad durante muchos años y muchos competidores han imitado las sólidas capacidades de su producto. En la Conferencia Dash de este año, lanzó una solución observable de extremo a extremo para IA, que incluye infraestructura, bases de datos vectoriales e implementación de modelos para operación y mantenimiento, desarrollo de modelos y orquestación de tareas. Además, se lanzó un robot de IA generativa, BITS.AI, para ayudar a Datadog a lograr consultas, conocimientos, retroalimentación de comportamiento y colaboración organizacional en el monitoreo de datos. También es digno de atención el reciente lanzamiento de Duet AI por parte de Google, que ha rehecho productos en la nube a través de grandes modelos, entre ellos cosas estrechamente relacionadas con la observabilidad, como la generación de Promql, que coinciden con algunas de nuestras prácticas.
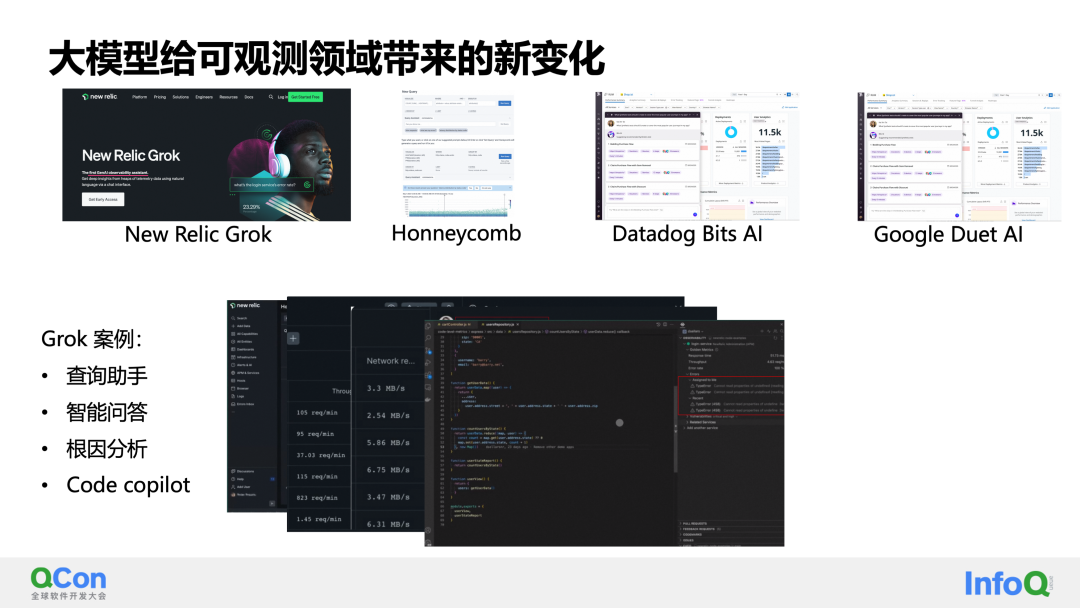
En el futuro, por un lado, esperamos construir un copiloto en el campo observable a través de la arquitectura de modelos grandes y langchain, para lograr la respuesta diaria a preguntas, consultas de datos y llamar a la caja de herramientas de práctica observable para completar. una serie de escenarios de aplicación. Por otro lado, esperamos que la capacidad de comprensión general de los modelos grandes, combinada con el Agente, desarrolle la capacidad del controlador principal y nos ayude a mejorar aún más las capacidades del modelo en escenarios de detección, análisis y convergencia.

Gracias a todos, este es el final de mi intercambio de hoy. Repaso las tres preguntas del alma al principio. ¡Espero todas sus respuestas y pensamientos después de escuchar esta conferencia!
Se lanza oficialmente Qt 6.6. La ventana emergente en la página de lotería de la aplicación Gome insulta a su fundador . Se lanza oficialmente Ubuntu 23.10. ¡También puedes aprovechar el viernes para actualizar! RISC-V: no controlado por ninguna empresa o país. Episodio de lanzamiento de Ubuntu 23.10: la imagen ISO fue "retirada" urgentemente debido a que contenía discurso de odio. Las empresas rusas producen computadoras y servidores basados en procesadores Loongson. ChromeOS es una distribución de Linux que utiliza Google Desktop Medio ambiente: estudiante de doctorado de 23 años corrige un "error fantasma" de 22 años en Firefox Lanzamiento de TiDB 7.4: oficialmente compatible con MySQL 8.0 Microsoft lanza la versión Windows Terminal Canary