Предисловие
Чиновник предоставляет нам пример классификации изображений одежды , чтобы облегчить нам быстрое обучение.
Рекомендуется смотреть по порядку, это небольшой сериал, подходящий для новичков вроде меня.
Среда конфигурации: установка тензорного потока в среде Windows
Пример классификации изображений: Пример использования TensorFlow: Классификация изображений одежды
Используйте официальную модель и настройте ее: Обучение TensorFlow: используйте официальную модель для классификации изображений и используйте свои собственные данные для точной настройки модели.
Преобразуйте модель и используйте ее во внешнем интерфейсе: обучение TensorFlow: как использовать модель Keras в веб-интерфейсе.
изучать
Предварительная обработка данных
В деле содержится следующий код
# 预处理数据,检查训练集中的第一个图像可以看到像素值处于0~255之间
plt.figure() # 创建图像窗口
plt.imshow(train_images[0]) # 显示图片
plt.colorbar() # 在图像旁边添加颜色条
plt.grid(False) # 取消网格线
plt.show() # 显示图形窗口
# 将值缩小至0~1之间,然后将其反馈到神经网络模型。训练集和测试集都需要处理
train_images = train_images / 255.0
test_images = test_images / 255.0
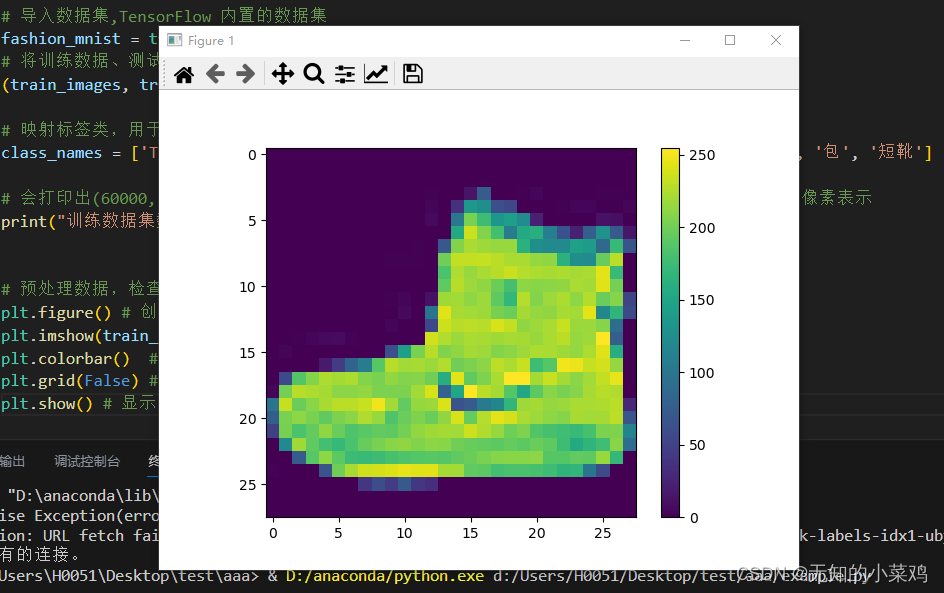
Baidu проверил это и сузил значение до значения от 0 до 1, чтобы
Сжатие значений данных обучающего набора и тестового набора до значений от 0 до 1 предназначено для нормализации данных (Нормализация). Это обычный этап предварительной обработки, который особенно важен для задач классификации изображений.
Масштабирование значений пикселей изображения между 0 и 1 имеет несколько преимуществ:
- Согласованность числового диапазона. Ограничение всех значений пикселей диапазоном от 0 до 1 может гарантировать, что функции разных образцов будут иметь согласованные числовые диапазоны. Это помогает избежать чрезмерного влияния определенных функций на обучение модели.
- Стабильность градиентного спуска. При глубоком обучении широко используемые алгоритмы оптимизации, такие как градиентный спуск, основаны на обновлении весов и вычислении градиента функции потерь. Масштабирование значений пикселей до меньшего диапазона может сделать эти вычисления более стабильными и помочь ускорить сходимость модели.
- Избегайте числового переполнения: в некоторых функциях активации и алгоритмах оптимизации, если входное значение слишком велико, может возникнуть числовое переполнение или нестабильность. Ограничение значений пикселей между 0 и 1 может уменьшить вероятность возникновения такой ситуации.
Вы поймете цель этого, когда в будущем столкнетесь с обработкой 255.
Построить модель
Построение нейронной сети требует настройки слоев модели, а затем ее компиляции.
Настройка слоев
Основными строительными блоками нейронных сетей являются слои. Слои извлекают представления из подаваемых на них данных. Надеемся, что эти представления помогут решить возникшую проблему.
Большая часть глубокого обучения состоит из объединения простых слоев. Большинство слоев (например tf.keras.layers.Dense, ) имеют параметры, которые изучаются только во время обучения.
# 1、设置层
# tf.keras是TensorFlow中的高级API,用于构建和训练神经网络模型。它是一个基于Keras库的接口,提供了更简单、更高级的方式来定义、配置和训练神经网络模型。
# tf.keras.Sequential 用于按顺序堆叠各个神经网络层来构建模型,是一种简单的模型类型
model = tf.keras.Sequential([
# 将图像格式从二维数组(28*28像素),转化为一维数组(28*28 = 784像素)。将该层视为图像中未堆叠的像素行并将其排列起来。该层没有要学习的参数,它只会重新格式化数据。
tf.keras.layers.Flatten(input_shape=(28,28)),
# 第二层,是一个具有128个神经元的全连接神经层
tf.keras.layers.Dense(128,activation='relu'),
# 第三层会返回一个长度为10的数组,每个都包含一个得分来表示当前图像属于10个类中的哪一个
tf.keras.layers.Dense(10)
])
Я считаю, что у многих людей, как и у меня, есть вопросы по этому коду.К счастью, сейчас есть gpt, иначе они бы не знали, где найти ответ. Вот некоторые из моих вопросов и ответов gpt:
- Почему здесь всего три этажа? Ответ: В нейронных сетях выбор количества слоев — это гибкий выбор конструкции, который зависит от сложности конкретной задачи и характеристик набора данных. Выбор трех слоев может быть направлен на упрощение модели или сама задача не требует большего количества слоев.
- Почему второй слой
tf.keras.layers.Dense(128). Ответ: Выбор 128 нейронов был основан на оценке сложности проблемы и опыте. Если проблема более сложная или набор данных больше, увеличение количества нейронов может увеличить емкость модели и улучшить ее представление. - Почему третий слой
tf.keras.layers.Dense(10). Ответ: Поскольку это проблема классификации, в данном случае существует 10 классификаций. Каждый нейрон соответствует категории и выдает прогнозируемую вероятность соответствующей категории. tf.keras.layers.Dense(128)Это рассчитано? О: Обычно его необходимо скорректировать в зависимости от реальной проблемы и набора данных. Увеличение количества нейронов может увеличить емкость и способность к обучению модели, но также может привести к переобучению. Переоснащение — это когда модель хорошо работает на обучающих данных, но плохо работает на новых данных. Рекомендуется начать с меньшего числа и постепенно увеличивать его до тех пор, пока производительность модели не перестанет улучшаться или она не начнет переопределяться.- Является ли последний слой модели выходным слоем? Ответ: Последний слой модели обычно является выходным слоем. Количество нейронов в выходном слое обычно связано с проблемой, которую вы пытаетесь решить. Для задач классификации количество нейронов в выходном слое должно быть равно количеству категорий. В задачах двоичной классификации один нейрон можно использовать для представления вероятностей двух категорий. Для задач мультиклассификации можно использовать несколько нейронов, каждый из которых представляет вероятность класса. Используйте
tf.keras``构建模型时,你可以使用tf.keras.layers.Dense`, чтобы определить выходной слой, и используйте соответствующую функцию активации для создания выходных данных.
Скомпилировать модель
Прежде чем вы будете готовы обучать модель, вам нужно ее еще немного настроить. На этапе компиляции модели было добавлено следующее:
- Функция потерь — измеряет, насколько точной была модель во время обучения. Вы хотите минимизировать эту функцию, чтобы «направить» модель в правильном направлении.
- Оптимизатор — определяет, как обновляется модель на основе видимых данных и собственной функции потерь.
- Метрики — используются для мониторинга этапов обучения и тестирования. В следующих примерах используется точность, то есть доля правильно классифицированных изображений.
# 2、编译模型
model.compile(
optimizer='adam', # 指定优化器,adam是常用的优化器,可以自适应的调整学习率
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 指定损失函数,这里使用了稀疏分类交叉熵损失函数
metrics=['accuracy'] # 指定评估模型性能的指标,这里使用准确率
)
Модель обучения
Обучение модели нейронной сети требует следующих шагов:
- Подайте данные обучения в модель. В этом примере данные обучения находятся в массивах train_images и train_labels.
- Модель учится ассоциировать изображения с метками.
- Попросите модель сделать прогнозы на тестовом наборе (в данном случае массиве test_images).
- Убедитесь, что прогнозы соответствуют меткам в массиве test_labels.
# 1、将训练数据反馈给模型
# model.fit用于将模型与训练数据进行拟合,这里是将所有样本迭代10次
model.fit(train_images,train_labels,epochs=10)
Как показано ниже:

# 2、在测试数据集上评估准确率,verbose=2参数表示以详细模式输出评估过程
test_loss,test_acc = model.evaluate(test_images,test_labels,verbose=2)
print("损失率:",test_loss,"准确率:",test_acc)
Как показано ниже:

делать предсказания
# 进行预测
# 模型经过训练后,您可以使用它对一些图像进行预测。附加一个 Softmax 层,将模型的线性输出 logits 转换成更容易理解的概率
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()])
# 预测图片
predictions = probability_model.predict(test_images)
print("第一个预测结果:",predictions[0])
Результатом предсказания является массив, содержащий 10 чисел. Они олицетворяют «уверенность» модели в каждом из 10 различных предметов одежды. Вы можете увидеть, какая метка имеет наибольшее значение достоверности:
np.argmax(predictions[0])
Используйте обученную модель
Теперь, когда модель обучена, мы можем делать прогнозы для отдельных изображений на основе модели.
# 使用训练好的模型
# 加载图片
img = Image.open('pics/shirt.png')
# 调整大小
img = img.resize((28,28))
# 将彩色图片转为灰度图片
img_gray = img.convert('L')
# 将图像转换为 NumPy 数组,并反转颜色
img_arr = np.array(img_gray)
img_arr = 255 - img_arr
# 将图像像素值归一化到0~1
img_arr = img_arr / 255.0
# 将图像形状调整为(1,28,288)
img_arr = img_arr.reshape(1,28,28)
# 可以保存处理后的文件,也可以进行预测
# np.save('abc.npy',img_arr)
# tf.keras 模型经过了优化,可同时对一个批或一组样本进行预测。因此,即便您只使用一个图像,您也需要将其添加到列表中
#img_arr = tf.keras.preprocessing.image.img_to_array(img)
res = probability_model.predict(img_arr)
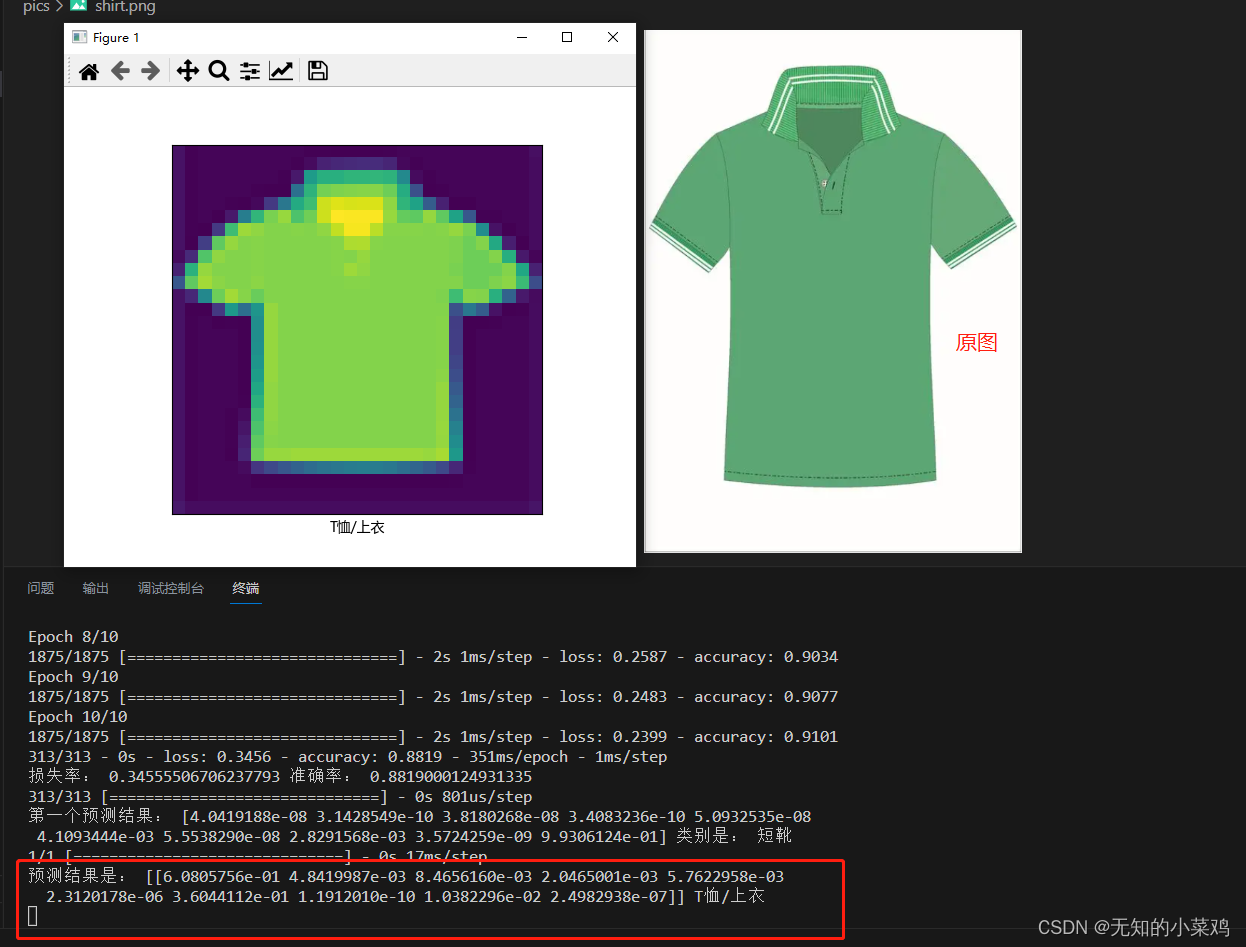
print("预测结果是:",res,class_names[np.argmax(res[0])])
# 可视化显示
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure() # 创建图像窗口
plt.xticks([])
plt.yticks([])
plt.grid(False) # 取消网格线
plt.imshow(img_arr[0]) # 显示图片
plt.xlabel(class_names[np.argmax(res[0])],fontproperties=font)
plt.show() # 显示图形窗口
Это была самая сложная часть, и чтобы добиться успеха, потребовалось много времени. Изображение, которое вы загружаете, является цветным. Вы должны преобразовать изображение в оттенки серого и пиксельное 28*28изображение. То есть ваше изображение должно быть обработано в изображение, соответствующее этой модели.
Но конечный результат на самом деле не очень точен. Основная причина заключается в том, что после обработки изображения можно получить очень мало функций, что приведет к ошибкам в суждениях.
результат
Возникшие проблемы
Вопрос 1 подсказывает
при выполнении(train_images, train_labels), (test_images,test_labels) = fashion_mnist.load_data()
Исключение: ошибка получения URL-адреса на https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz: Нет – [WinError 10054] Удаленный хост принудительно закрыл существующее соединение.
Это сбой при загрузке набора данных. Эта проблема всегда возникает при доступе и загрузке данных из Google в Китае.
Решение:
1. Откройте официальный сайт набора данных https://github.com/zalandoresearch/fashion-mnist , загрузите следующие 4 данных локально и поместите их в проект.

2. Загрузите локальные данные
import gzip
import numpy as np
def load_data():
# 加载训练集图像数据
with gzip.open('train-images-idx3-ubyte.gz', 'rb') as f:
train_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载训练集标签数据
with gzip.open('train-labels-idx1-ubyte.gz', 'rb') as f:
train_labels = np.frombuffer(f.read(), np.uint8, offset=8)
# 加载测试集图像数据
with gzip.open('t10k-images-idx3-ubyte.gz', 'rb') as f:
test_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载测试集标签数据
with gzip.open('t10k-labels-idx1-ubyte.gz', 'rb') as f:
test_labels = np.frombuffer(f.read(), np.uint8, offset=8)
return (train_images, train_labels), (test_images, test_labels)
# 调用加载数据函数
(train_images, train_labels), (test_images, test_labels) = load_data()
Вопрос 2
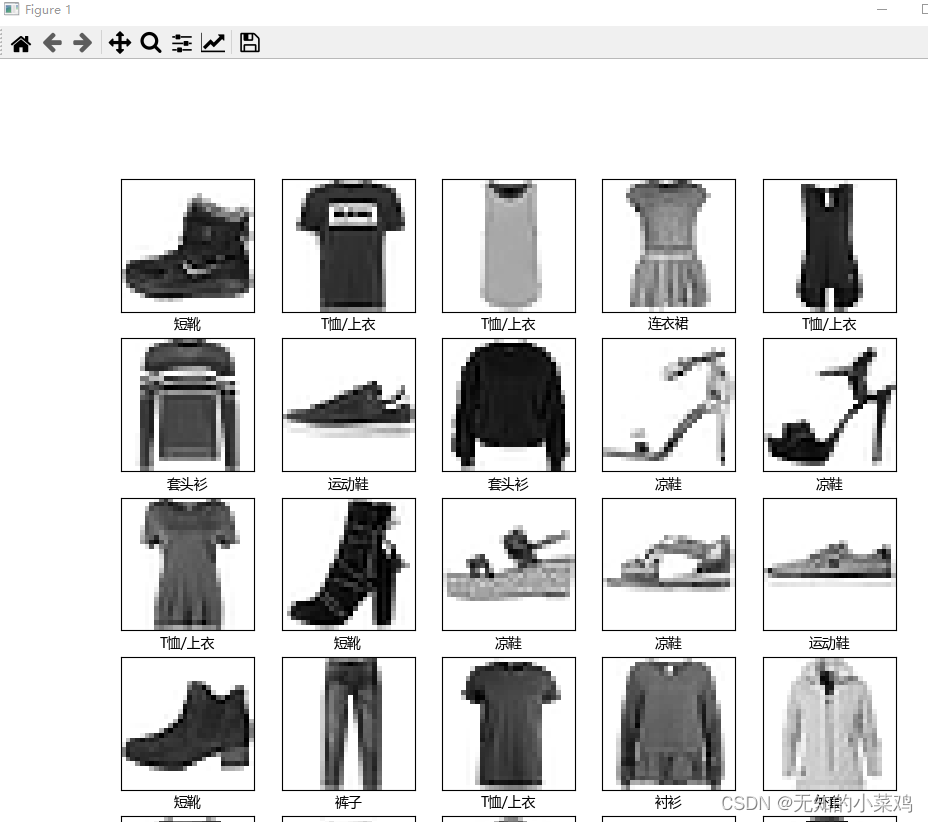
проверяет первые 25 изображений и устанавливает искаженные китайские символы. В руководстве используется английский язык. Я попробовал китайский язык, но китайские иероглифы были искажены.
Решение: установите китайский шрифт.
# 字体属性
from matplotlib.font_manager import FontProperties
# 验证训练集中的前25个图像,并显示其名称
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1) # 按照 5*5进行显示
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]],fontproperties=font)
plt.show()
Полный код
# 导入 TensorFlow 重命名
import tensorflow as tf
# numpy是科学计算库,matplotlib是用于绘制图表和可视化数据的库
import numpy as np
import matplotlib.pylab as plt
# 字体属性
from matplotlib.font_manager import FontProperties
# 用于加载文件
import gzip
# 用于处理图片
from PIL import Image
# 用于加载数据集的函数
def load_data():
# 加载训练集图像数据
with gzip.open('train-images-idx3-ubyte.gz', 'rb') as f:
train_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载训练集标签数据
with gzip.open('train-labels-idx1-ubyte.gz', 'rb') as f:
train_labels = np.frombuffer(f.read(), np.uint8, offset=8)
# 加载测试集图像数据
with gzip.open('t10k-images-idx3-ubyte.gz', 'rb') as f:
test_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载测试集标签数据
with gzip.open('t10k-labels-idx1-ubyte.gz', 'rb') as f:
test_labels = np.frombuffer(f.read(), np.uint8, offset=8)
return (train_images, train_labels), (test_images, test_labels)
print("tf版本:",tf.__version__)
# 导入数据集,TensorFlow 内置的数据集
fashion_mnist = tf.keras.datasets.fashion_mnist
# 将训练数据、测试数据取出,保存的元组里
(train_images, train_labels), (test_images,test_labels) = load_data()
# 映射标签类,用于后面绘制图像使用
class_names = ['T恤/上衣', '裤子', '套头衫', '连衣裙', '外套', '凉鞋', '衬衫', '运动鞋', '包', '短靴']
# 会打印出(60000, 28, 28),官方文档解释为训练集中有 60,000 个图像,每个图像由 28 x 28 的像素表示
print("训练数据集数据:",train_images.shape)
# 预处理数据,检查训练集中的第一个图像可以看到像素值处于0~255之间
# plt.figure() # 创建图像窗口
# plt.imshow(train_images[0]) # 显示图片
# plt.colorbar() # 在图像旁边添加颜色条
# plt.grid(False) # 取消网格线
# plt.show() # 显示图形窗口
# 将值缩小至0~1之间,然后将其反馈到神经网络模型。训练集和测试集都需要处理
train_images = train_images / 255.0
test_images = test_images / 255.0
# 验证训练集中的前25个图像,并显示其名称
# font = FontProperties()
# font.set_family('Microsoft YaHei')
# plt.figure(figsize=(10,10))
# for i in range(25):
# plt.subplot(5,5,i+1) # 按照 5*5进行显示
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# plt.imshow(train_images[i], cmap=plt.cm.binary)
# plt.xlabel(class_names[train_labels[i]],fontproperties=font)
# plt.show()
# 构建模型
# 1、设置层
# tf.keras是TensorFlow中的高级API,用于构建和训练神经网络模型。它是一个基于Keras库的接口,提供了更简单、更高级的方式来定义、配置和训练神经网络模型。
# tf.keras.Sequential 用于按顺序堆叠各个神经网络层来构建模型,是一种简单的模型类型
model = tf.keras.Sequential([
# 将图像格式从二维数组(28*28像素),转化为一维数组(28*28 = 784像素)。将该层视为图像中未堆叠的像素行并将其排列起来。该层没有要学习的参数,它只会重新格式化数据。
tf.keras.layers.Flatten(input_shape=(28,28)),
# 第二层,是一个具有128个神经元的全连接神经层
tf.keras.layers.Dense(128,activation='relu'),
# 第三层会返回一个长度为10的数组,每个都包含一个得分来表示当前图像属于10个类中的哪一个
tf.keras.layers.Dense(10)
])
# 2、编译模型
model.compile(
optimizer='adam', # 指定优化器,adam是常用的优化器,可以自适应的调整学习率
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 指定损失函数,这里使用了稀疏分类交叉熵损失函数
metrics=['accuracy'] # 指定评估模型性能的指标,这里使用准确率
)
# 训练模型
# 1、将训练数据反馈给模型
# model.fit用于将模型与训练数据进行拟合,这里是将所有样本迭代10次
model.fit(train_images,train_labels,epochs=10)
# 2、在测试数据集上评估准确率,verbose=2参数表示以详细模式输出评估过程
test_loss,test_acc = model.evaluate(test_images,test_labels,verbose=2)
print("损失率:",test_loss,"准确率:",test_acc)
# 进行预测
# 模型经过训练后,您可以使用它对一些图像进行预测。附加一个 Softmax 层,将模型的线性输出 logits 转换成更容易理解的概率
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()])
# 预测图片
predictions = probability_model.predict(test_images)
print("第一个预测结果:",predictions[0],'类别是:',class_names[np.argmax(predictions[0])])
# 使用训练好的模型
# 加载图片
img = Image.open('pics/shirt.png')
# 调整大小
img = img.resize((28,28))
# 将彩色图片转为灰度图片
img_gray = img.convert('L')
# 将图像转换为 NumPy 数组,并反转颜色
img_arr = np.array(img_gray)
img_arr = 255 - img_arr
# 将图像像素值归一化到0~1
img_arr = img_arr / 255.0
# 将图像形状调整为(1,28,288)
img_arr = img_arr.reshape(1,28,28)
# 可以保存处理后的文件,也可以进行预测
# np.save('abc.npy',img_arr)
res = probability_model.predict(img_arr)
print("预测结果是:",res,class_names[np.argmax(res[0])])
# 可视化显示
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure() # 创建图像窗口
plt.xticks([])
plt.yticks([])
plt.grid(False) # 取消网格线
plt.imshow(img_arr[0]) # 显示图片
plt.xlabel(class_names[np.argmax(res[0])],fontproperties=font)
plt.show() # 显示图形窗口