¿Por qué no hash (también conocido como hash ) ?
- La tabla hash es la tabla hash. El principio es utilizar la función hash para convertir los datos que almacenamos en un valor hash en forma de palabras clave y luego almacenar los datos en la memoria de acuerdo con el valor hash.
- Ya sea leyendo o escribiendo, el hash es más rápido que el árbol, entonces, ¿por qué elegir la estructura de árbol como estructura de índice? Porque para agrupar, ordenar y comparar, la complejidad temporal del índice hash degenerará a O (n) y, en aplicaciones prácticas, el tiempo es relativamente largo después de que la cantidad de datos sea de millones de niveles.
- Habrá conflictos de hash en el algoritmo hash. Aunque se utiliza la función de perturbación, después de que la cantidad de datos sea grande, todavía habrá una distribución desigual ( función de perturbación 1 , función de perturbación 2 )
¿Por qué no utilizar un árbol binario?
- Cada nodo del árbol binario solo se divide en dos bifurcaciones y cada nodo solo puede almacenar un registro. A medida que aumenta la cantidad de datos, la altura del árbol aumentará significativamente y cuanto mayor sea la altura, más lenta será la velocidad de consulta.
- Después de aumentar la altura, el número se convierte en una lista y la complejidad del tiempo se acerca a O (n)
¿Por qué no utilizar árboles B?
- El número de nodos en cada capa del árbol B es muy grande y el número de capas es muy pequeño. En comparación con el árbol binario, el número de E/S de disco se reduce, pero cada nodo almacena datos y la consulta requiere información. recorrido de orden, que no es la mejor manera de localizar datos rápidamente.
árbol AVL
-
Con condición de equilibrio: el valor absoluto (factor de equilibrio) de la diferencia de altura entre los subárboles izquierdo y derecho de cada nodo es como máximo 1. En otras palabras, el árbol AVL es esencialmente un árbol de búsqueda binario con una función de equilibrio. Aunque el número está equilibrado y la consulta es más rápida, al insertar datos, para lograr el equilibrio se requieren múltiples rotaciones. Cuando la cantidad de datos es grande, la rotación requiere mucho tiempo
árbol negro rojo
- Árbol binario desequilibrado, pero los datos son grandes y la consulta llevará mucho tiempo
árbol B
- Durante la IO de datos de la computadora, los datos de consulta no utilizan lectura ni escritura continua. Utilice 4k o N*4k para leer y escribir. La ventaja de esto es que la consulta es más rápida.
- En esta unidad de datos 4k. Los nodos de hoja del árbol B almacenan claves y datos. De esta forma, cuanto mayor sea la cantidad de datos, más datos habrá en esta unidad de datos. Si la clave de datos + llega a 2k. Entonces cada nodo solo puede colocar 2 datos.
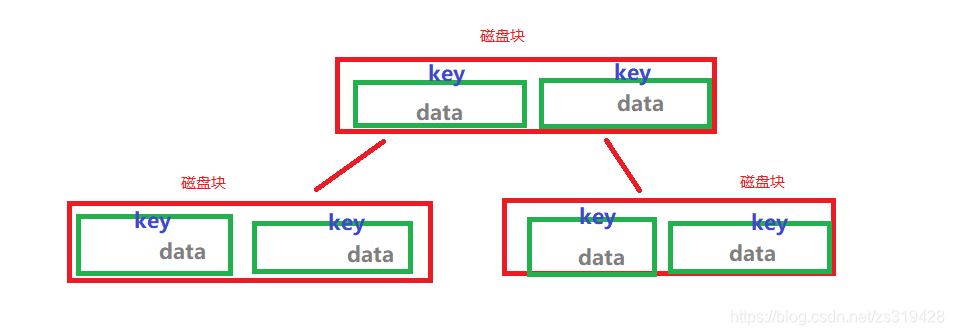
¿Por qué utilizar el árbol B+ en lugar del árbol B?
- El árbol B + se mejora sobre la base del árbol B. Los datos solo se almacenan en los nodos hoja y se agrega una lista vinculada entre los nodos hoja. De esta manera, al obtener nodos, no es necesario recorrerlos en orden. lo cual es conveniente para localizar datos rápidamente y es la mejor manera de reducir la E/S del disco.
