Level 1:
-
1. Was veranschaulichen die folgenden beiden Bilder?
A,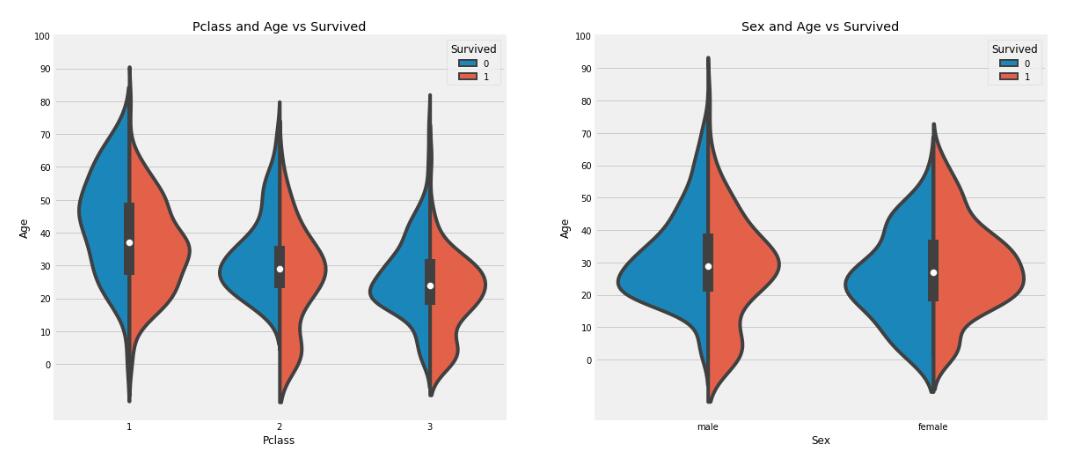
Die Überlebensrate von Kindern unter 10 Jahren ist relativ hoch und hat nichts mit dem Kabinenniveau zu tun.
B,Passagiere der ersten Klasse im Alter von 20 bis 50 Jahren haben eine höhere Überlebensrate
C,Bei Männern gilt: Je älter sie werden, desto geringer sind ihre Überlebenschancen
D,Frauen haben höhere Überlebensraten
Antwort: BCD
-
2、
Was veranschaulicht dieses Bild?
A,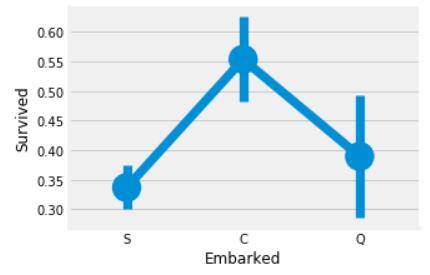
Die Überlebensrate der Passagiere, die am Hafen C aussteigen, liegt über 55 %
B,Passagiere, die in Port S einsteigen, haben die niedrigste Überlebensrate
C,In Hafen C gehen die meisten Menschen an Bord des Schiffes.
D,Port S ist der Hafen mit der geringsten Anzahl an Passagieren.
Antwort: AB
-
3,
Was veranschaulichen die folgenden vier Bilder?
A,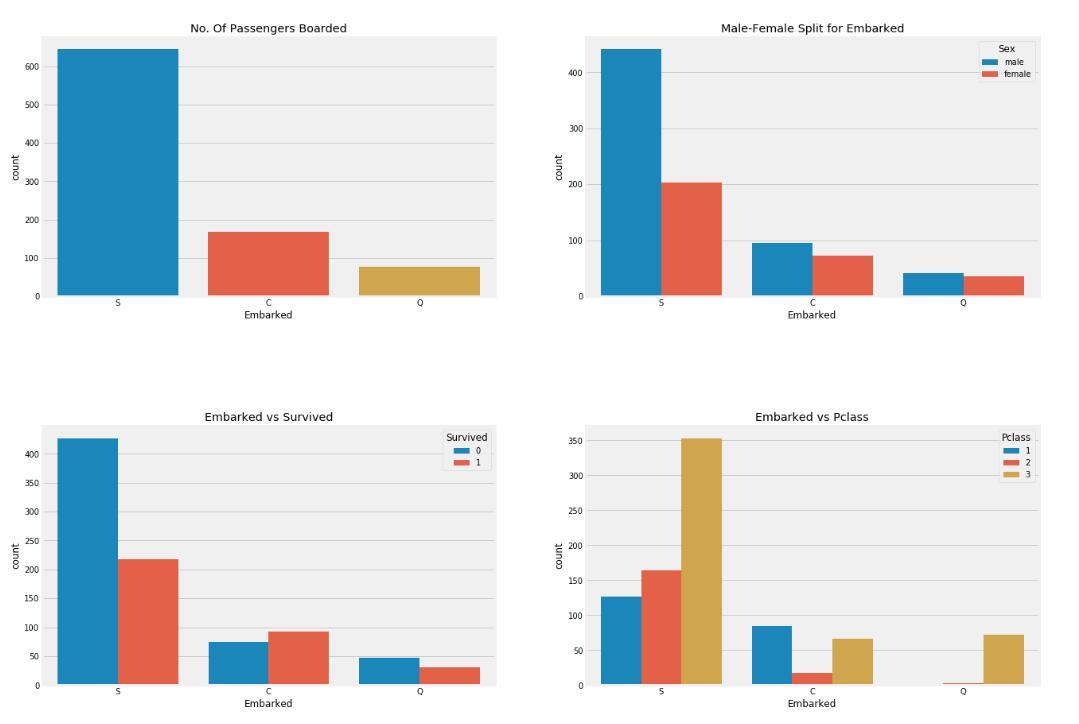
Obwohl im Grunde genommen viele erstklassige Reiche das Schiff in Port S bestiegen, hatte Port S die niedrigste Überlebensrate. Dies kann daran liegen, dass viele der Leute, die in Port S das Schiff bestiegen, Passagiere der dritten Klasse waren.
B,Die meisten Menschen, die im Hafen S an Bord des Schiffes gehen, sind Passagiere zweiter Klasse.
C,Mehr als 90 % der Passagiere, die in Port Q an Bord des Schiffes gehen, sind Passagiere der dritten Klasse
D,Die Überlebensrate ist am höchsten, wenn man das Schiff in Port C betritt
Antwort: ACD
-
4、
Was veranschaulichen die folgenden beiden Bilder?
A,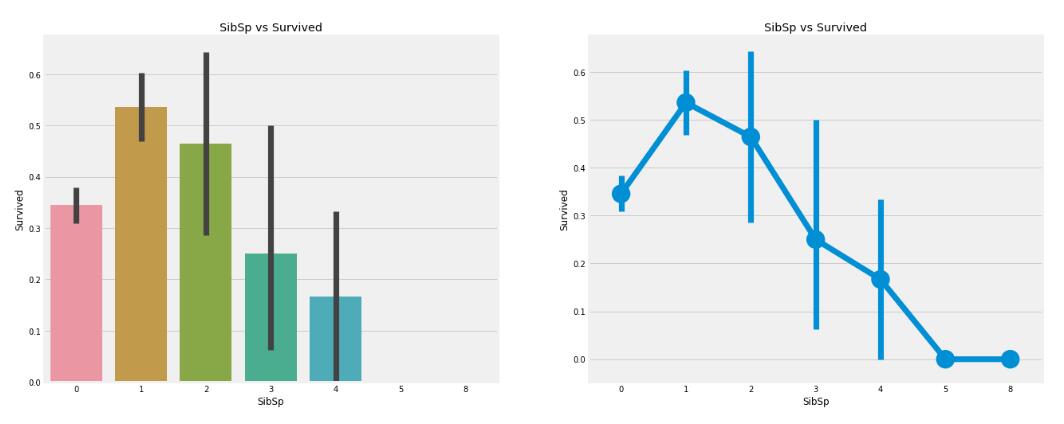
Die Überlebensrate für Alleinreisende auf einem Boot liegt bei etwa 34 %
B,Wenn auch ein Geschwisterkind oder ein geliebter Mensch an Bord ist, ist die Überlebensrate am höchsten.
C,Wenn die Zahl der Geschwister oder Liebhaber relativ groß ist, nimmt die Überlebensrate tendenziell ab.
Antwort: ABC
Ebene 2: Fehlende Werte ergänzen
import pandas as pd
import numpy as np
def process_nan_value(data):
'''
处理data中缺失值,有缺失值的特征为`Age`,`Cabin`,`Embarked`。
:param data: 训练集的特征,类型为DataFrame
:return:处理好缺失值后的训练集特征,类型为DataFrame
'''
#********* Begin *********#
data['Age'].replace(np.nan,np.nanmedian(data['Age']),
inplace=True)
#data['Age'].replace(np.nan,np.nanmedian(data['Age']),inplace=True)
data.drop(labels='Cabin',axis=1,inplace=True)
data['Embarked'].replace(np.nan,'S',inplace=True)
return data
#********* End *********#
Ebene 3: Feature Engineering und Überlebensvorhersage
import pandas as pd
import numpy as np
import sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
#********* Begin *********#
titanic = pd.read_csv('./train.csv')
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df
titanic = set_missing_ages(titanic)
dummies_Embarked = pd.get_dummies(titanic['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(titanic['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(titanic['Pclass'], prefix= 'Pclass')
df = pd.concat([titanic, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
# print(df)
train_label = df['Survived']
train_titanic = df.drop('Survived', 1)
titanic_test = pd.read_csv('./test.csv')
titanic_test = set_missing_ages(titanic_test)
dummies_Embarked = pd.get_dummies(titanic_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(titanic_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(titanic_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([titanic_test,dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
#model = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
model = RandomForestClassifier(n_estimators=10)
model.fit(train_titanic, train_label)
predictions = model.predict(df_test)
result = pd.DataFrame({'Survived':predictions.astype(np.int32)})
result.to_csv("./predict.csv", index=False)
#********* End *********#