Die yolo-Serie ist derzeit eines der am weitesten verbreiteten Detektionsmodelle in der Technik. yolov5 hat eine hervorragende Erkennungsleistung und eine bequeme Bereitstellung und wird von Entwicklern gut angenommen. Wenn das Modell jedoch auf dem Frontend läuft, sind die Modellgröße und die Inferenzzeit anspruchsvoll, und das leichte Modell yolov5s ist auch schwer zu parieren. Um die Effizienz des Modells zu verbessern, teile ich hier den Github- Sharing-Link der auf yolov5 basierenden Modellbereinigungsmethode mit Ihnen .
Pruning-Prinzip und Pipeline
Dieses Mal wird spärliches Training verwendet, um die Kanaldimension aus dem Artikel Learning Efficient Convolutional Networks Through Network Slimming zu beschneiden . Tatsächlich ist das Prinzip leicht zu verstehen: Wir wissen, dass es in der bn-Schicht zwei trainierbare Parameter γ , β \gamma,\beta gibtc ,β , die normalisierte Verteilung, die durch Eingabe von bn erhalten wird. Wennγ , β \gamma, βWenn γ und β gegen 0 tendieren, entspricht die Eingabe einer Multiplikation mit 0, dann gibt die Faltung auf dem Kanal nur 0 aus, was bedeutungslos ist. Daher können wir davon ausgehen, dass das Entfernen solcher redundanter Kanäle nur geringe Auswirkungen auf die Modellleistung hat. Während des normalen Netzwerktrainings wird aufgrund der Initialisierungγ \gammaγ ist im Allgemeinen um 1 verteilt. Umγ \gammaγ tendiert zu 0 und kann durch Hinzufügen einer L1-Regularisierung eingeschränkt werden, um den Koeffizienten spärlich zu machen, undγ \gammaDas Training mit γ L1-Regularisierung wird als spärliches Training bezeichnet.
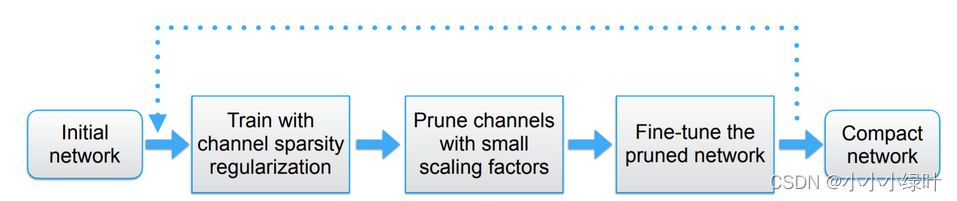
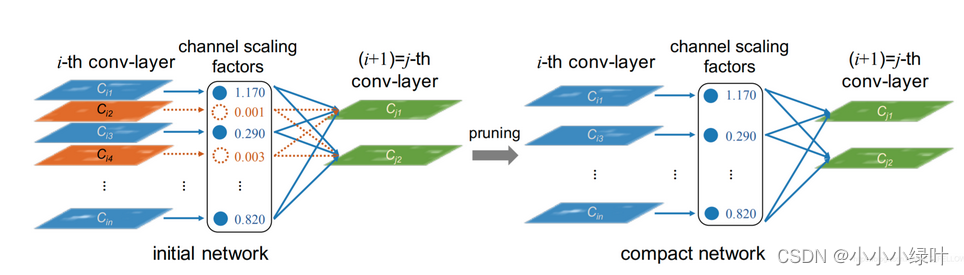 Der gesamte Pruning-Prozess ist in der folgenden Abbildung dargestellt: Initialisieren Sie zunächst das Netzwerk, fügen Sie den Parametern der bn-Schicht eine L1-Regularisierung hinzu und trainieren Sie das Netzwerk. γ \gammain statistischen Netzenγ , stellen Sie die Beschneidungsrate ein, um das Netzwerk zu schneiden. Passen Sie schließlich das beschnittene Netzwerk an, um die Beschneidungsarbeit abzuschließen.
Der gesamte Pruning-Prozess ist in der folgenden Abbildung dargestellt: Initialisieren Sie zunächst das Netzwerk, fügen Sie den Parametern der bn-Schicht eine L1-Regularisierung hinzu und trainieren Sie das Netzwerk. γ \gammain statistischen Netzenγ , stellen Sie die Beschneidungsrate ein, um das Netzwerk zu schneiden. Passen Sie schließlich das beschnittene Netzwerk an, um die Beschneidungsarbeit abzuschließen.
Details zum Beschneiden
1. Sparse-Training
Im vorigen Kapitel wurde das Prinzip des Sparse-Trainings vorgestellt.Sehen wir uns an, wie der Code implementiert wird. Der Code lautet wie folgt: Zunächst müssen wir den Sparse-Koeffizienten festlegen. Der Sparse-Koeffizient ist sehr wichtig für die Pruning-Leistung des gesamten Netzwerks, wenn der Koeffizient zu klein eingestellt ist, γ \ gammaDer Grad, in dem γ gegen 0 tendiert, ist nicht hoch, und ein hochintensives Pruning kann im Netzwerk nicht durchgeführt werden, aber wenn es zu groß eingestellt ist, wird es die Netzwerkleistung beeinträchtigen und die Karte stark reduzieren. Daher müssen wir den geeigneten dünnbesetzten Koeffizienten durch Experimente finden.
Die Trainingsparameter der bn-Schicht umfassenγ , β \gamma, \betac ,β , d. h. nach m.weight, m.bias und loss.backward im Code, fügen Sie den Gradienten der L1-Regularisierung zum Gradienten dieser beiden Parameter hinzu.
srtmp = opt.sr * (1 - 0.9 * epoch/epochs)
for k, m in model.named_modules():
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
2. Beschneidung des Netzwerks
Im vorherigen Schritt haben wir das spärlich trainierte Netzwerk erhalten.Als nächstes müssen wir γ \gamma verwendenKanäle, bei denen γ gegen 0 geht, werden abgeschnitten. Zählen Sie zuerstdie γ \gammaγ und ordnen und sortieren, um den Schwellenwert thre zu finden, der der Beschneidungsrate entspricht.
for i, layer in model.named_modules():
if isinstance(layer, nn.BatchNorm2d):
if i not in ignore_bn_list:
model_list[i] = layer
# bnw = layer.state_dict()['weight']
model_list = {
k:v for k,v in model_list.items() if k not in ignore_bn_list}
prune_conv_list = [layer.replace("bn", "conv") for layer in model_list.keys()]
bn_weights = gather_bn_weights(model_list)
sorted_bn = torch.sort(bn_weights)[0]
thre_index = int(len(sorted_bn) * opt.percent)
thre = sorted_bn[thre_index]
Dann wird die Maske jeder bn-Schicht gemäß dem Schwellenwert erhalten.Hier wird eine gewisse Logik hinzugefügt, um sicherzustellen, dass der beschnitteneKanal ein Vielfaches von 4 ist, was die zusammengesetzte Front-End-Beschleunigungsanforderungist.
def obtain_bn_mask(bn_module, thre):
thre = thre.cuda()
bn_layer = bn_module.weight.data.abs()
temp = abs(torch.sort(bn_layer)[0][3::4] - thre)
thre_temp = torch.sort(bn_layer)[0][3::4][temp.argmin()]
if int(temp.argmin()) == 0 and thre_temp > thre:
thre = -1
else:
thre = thre_temp
thre_index = int(bn_layer.shape[0] * 0.9)
if thre_index % 4 != 0:
thre_index -= thre_index % 4
thre_perbn = torch.sort(bn_layer)[0][thre_index - 1]
if thre_perbn < thre:
thre = min(thre, thre_perbn)
mask = bn_module.weight.data.abs().gt(thre).float()
return mask
Da das beschnittene Netzwerk nicht mit dem ursprünglichen Netzwerkkanal ausgerichtet werden kann, müssen wir das Netzwerk neu definieren und das Netzwerk analysieren. Die rekonstruierte Netzwerkstruktur muss neu definiert werden, da weitere Parameter importiert werden müssen.
pruned_yaml["backbone"] =[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3Pruned, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3Pruned, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3Pruned, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3Pruned, [1024]],
[-1, 1, SPPFPruned, [1024, 5]], # 9
]
pruned_yaml["head"] = [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3Pruned, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3Pruned, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3Pruned, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3Pruned, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Das Rückgrat und der Hals von yolov5 haben eine C3-Struktur, und es gibt eine Abkürzung in C3, das heißt, es gibt zwei Formen der Faltung und Addition. Damit das Netzwerk normal addiert, müssen wir die beiden Faltungsmasken von add zusammenführen. Gleichzeitig gibt es Concate im Netzwerk, daher muss auch festgehalten werden, aus welchen Layern das Concate kommt und aus welchem Layer der Concate-Ausgang kommt.
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
named_m_base = "model.{}".format(i)
if m in [Conv]:
named_m_bn = named_m_base + ".bn"
bnc = int(maskbndict[named_m_bn].sum())
c1, c2 = ch[f], bnc
args = [c1, c2, *args[1:]]
layertmp = named_m_bn
if i>0:
from_to_map[layertmp] = fromlayer[f]
fromlayer.append(named_m_bn)
elif m in [C3Pruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
named_m_cv3_bn = named_m_base + ".cv3.bn"
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = fromlayer[f]
fromlayer.append(named_m_cv3_bn)
if len(args) == 1:
temp_mask = maskbndict[named_m_cv1_bn].bool() | maskbndict[named_m_base + '.m.0.cv2.bn'].bool()
maskbndict[named_m_cv1_bn], maskbndict[named_m_base + '.m.0.cv2.bn'] = temp_mask.float(), temp_mask.float()
if n > 1:
for repeat_ind in range(1, n):
temp_mask |= maskbndict[named_m_base + ".m.{}.cv2.bn".format(repeat_ind)].bool()
for re_ind in range(n):
maskbndict[named_m_base + ".m.{}.cv2.bn".format(re_ind)] = temp_mask
maskbndict[named_m_cv1_bn], maskbndict[named_m_base + '.m.0.cv2.bn'] = temp_mask.float(), temp_mask.float()
cv1in = ch[f]
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
cv3out = int(maskbndict[named_m_cv3_bn].sum())
args = [cv1in, cv1out, cv2out, cv3out, n, args[-1]]
bottle_args = []
chin = [cv1out]
c3fromlayer = [named_m_cv1_bn]
for p in range(n):
named_m_bottle_cv1_bn = named_m_base + ".m.{}.cv1.bn".format(p)
named_m_bottle_cv2_bn = named_m_base + ".m.{}.cv2.bn".format(p)
bottle_cv1in = chin[-1]
bottle_cv1out = int(maskbndict[named_m_bottle_cv1_bn].sum())
bottle_cv2out = int(maskbndict[named_m_bottle_cv2_bn].sum())
chin.append(bottle_cv2out)
bottle_args.append([bottle_cv1in, bottle_cv1out, bottle_cv2out])
from_to_map[named_m_bottle_cv1_bn] = c3fromlayer[p]
from_to_map[named_m_bottle_cv2_bn] = named_m_bottle_cv1_bn
c3fromlayer.append(named_m_bottle_cv2_bn)
args.insert(4, bottle_args)
c2 = cv3out
n = 1
from_to_map[named_m_cv3_bn] = [c3fromlayer[-1], named_m_cv2_bn]
elif m in [SPPFPruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
cv1in = ch[f]
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = [named_m_cv1_bn]*4
fromlayer.append(named_m_cv2_bn)
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
args = [cv1in, cv1out, cv2out, *args[1:]]
c2 = cv2out
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
inputtmp = [fromlayer[x] for x in f]
fromlayer.append(inputtmp)
elif m is Detect:
from_to_map[named_m_base + ".m.0"] = fromlayer[f[0]]
from_to_map[named_m_base + ".m.1"] = fromlayer[f[1]]
from_to_map[named_m_base + ".m.2"] = fromlayer[f[2]]
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
fromtmp = fromlayer[-1]
fromlayer.append(fromtmp)
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save), from_to_map
Nach der Rekonstruktion und Analyse des Netzwerks müssen wir die Parameter des analysierten Netzwerks eingeben, d. h. die Parameter jeder Schicht des analysierten Netzwerks finden, die dem ursprünglichen Netzwerk entsprechen, und dem rekonstruierten Netzwerk per Klon Werte zuweisen. Der Code lautet wie folgt:
for ((layername, layer),(pruned_layername, pruned_layer)) in zip(model.named_modules(), pruned_model.named_modules()):
assert layername == pruned_layername
if isinstance(layer, nn.Conv2d) and not layername.startswith("model.24"):
convname = layername[:-4]+"bn"
if convname in from_to_map.keys():
former = from_to_map[convname]
if isinstance(former, str):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
w = layer.weight.data[:, in_idx, :, :].clone()
if len(w.shape) ==3: # remain only 1 channel.
w = w.unsqueeze(1)
w = w[out_idx, :, :, :].clone()
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(former, list):
orignin = [modelstate[i+".weight"].shape[0] for i in former]
formerin = []
for it in range(len(former)):
name = former[it]
tmp = [i for i in range(maskbndict[name].shape[0]) if maskbndict[name][i] == 1]
if it > 0:
tmp = [k + sum(orignin[:it]) for k in tmp]
formerin.extend(tmp)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
pruned_layer.weight.data = w[:,formerin, :, :].clone()
changed_state.append(layername + ".weight")
else:
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
assert len(w.shape) == 4
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(layer,nn.BatchNorm2d):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[out_idx].clone()
pruned_layer.bias.data = layer.bias.data[out_idx].clone()
pruned_layer.running_mean = layer.running_mean[out_idx].clone()
pruned_layer.running_var = layer.running_var[out_idx].clone()
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
changed_state.append(layername + ".running_mean")
changed_state.append(layername + ".running_var")
changed_state.append(layername + ".num_batches_tracked")
if isinstance(layer, nn.Conv2d) and layername.startswith("model.24"):
former = from_to_map[layername]
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[:, in_idx, :, :]
pruned_layer.bias.data = layer.bias.data
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
Bisher haben wir alle Schritte des Beschneidens abgeschlossen.