1. 변환기
1. 변환기란 무엇입니까
기능 엔지니어링의 이전 단계:
(1) 첫 번째 단계는 변환기 클래스(Transformer)를 인스턴스화하는 것입니다.
(2) 두 번째 단계는 fit_transform을 호출하여 데이터를 변환하는 것입니다.
2. 기능 엔지니어링 인터페이스를 변환기라고 부르며 변환기 호출에는 여러 가지 형태가 있습니다:
fit_transform()
fit()
변환()
3. 예
표준화를 예로 들어보겠습니다: (x - 평균) / std
변환할 특성 x를 이 열의 평균 평균에서 빼고 표준편차로 나눕니다.
첫 번째 단계에서는 fit()을 실행하여 각 열의 평균, 표준편차
두 번째 단계에서는 변환()을 실행하고 첫 번째 단계에서 계산된 결과를 최종 변환 공식에 적용합니다.
2. 추정기
1. 에스티메이터(estimator)란 무엇인가?
sklearn에서 에스티메이터(estimator)는 중요한 역할을 하며, 알고리즘을 구현하는 API의 일종으로
모든 머신러닝 알고리즘이 에스티메이터에 캡슐화되어 있습니다.
2. 분류를 위한 추정기
(1) sklearn.neighbors: k-neighbor 알고리즘
(2) sklearn.naive_bayes: Naive Bayes
(3) sklearn.linear_model.LogisticRegression: 로지스틱 회귀
(4) sklearn.tree: 랜덤 포레스트를 사용한 의사결정 트리
3. 회귀에 사용되는 추정기
(1) sklearn.linear_model.LinearRegression: 선형 회귀
(2) sklearn.linear_model.Ridge: 능형 회귀
4. 비지도 학습을 위한 추정기
(1) sklearn.cluster.KMeans: 클러스터링
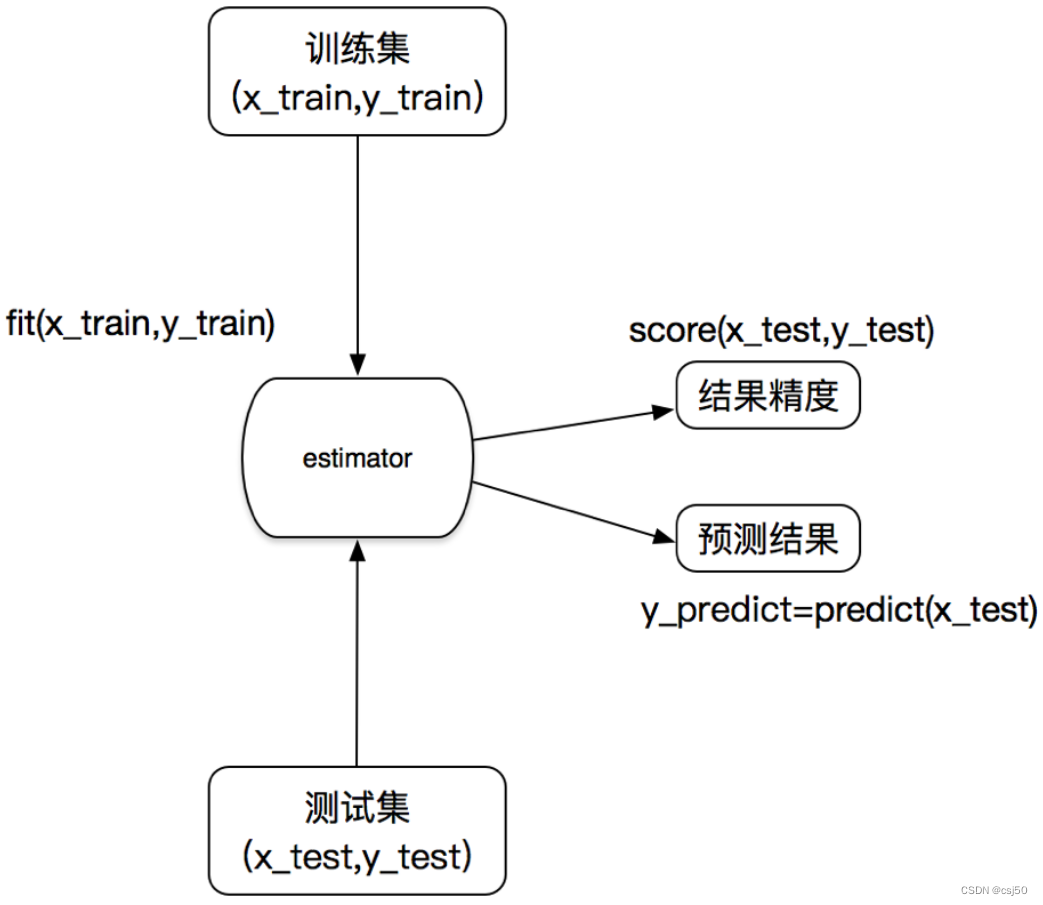
3. 추정기 작업 흐름
1. 추정기 인스턴스화
2. estimator.fit(x_train, y_train)을 호출하여 계산합니다
.fit 메소드에 훈련 세트의 특성 값과 목표 값을 전달합니다.
호출이 완료되면 모델이 생성된다는 의미입니다.
3. 모델 평가
(1) 참값과 예측값을 직접 비교
참고: x_test 테스트 세트, y_predict 예측 결과, y_test 테스트 세트 목표값
y_predict = estimator.predict(x_test)
비교 y_test == y_predict
(2) 정확도 계산
설명: 정확도 정확도
= estimator.score(x_test, y_test)