안녕하세요 여러분 Wei Xue AI입니다. 오늘은 여러 모델을 기반으로 한 기계 학습 실습 9-스크리닝 및 자폐증 예측 분석을 소개하겠습니다. 자폐증은 주로 대인 커뮤니케이션 및 사회적 상호 작용에서 나타나는 신경 발달 장애입니다. 상호 작용, 의사 소통의 어려움 장벽, 반복적인 고정관념. 조기 선별 및 분석은 자폐 아동의 진단 및 개입에 매우 중요합니다.
목차
1. 프로젝트 배경
2. 연구 의의
3. 코드 실습 및 데이터 분석
3.1 데이터 전처리
3.2 데이터 그래프 분석
4. 기계 학습 모델 분석
4.1 데이터 원-핫 인코딩
4.2 데이터 정렬
4.3 로지스틱 회귀 모델
4.4 랜덤 포레스트 모델
4.5K 최근접 이웃 모델
4.6 실행 결과
5. 요약
1. 프로젝트 배경
자폐증은 지난 수십 년 동안 광범위한 관심을 받아 왔으며 현재 환자와 그 가족에 대한 높은 유병률과 장기적인 영향이 인식되고 있습니다. 그러나 자폐증의 다양한 증상과 특정 바이오마커의 부족으로 인해 진단 및 치료가 큰 어려움에 직면해 있습니다. 따라서 자폐증에 대한 선별 및 분석 사업을 수행하는 것은 조기진단의 정확성과 개입의 효과를 높이는 데 도움이 될 수 있다.
2. 연구의 의의
조기 개입: 자폐증에 대한 조기 개입은 아동 발달에 매우 중요합니다. 스크리닝 및 분석 프로그램을 통해 아이들이 명백한 증상을 보이기 전에 환자를 조기에 발견하고 적시에 개입할 수 있습니다. 이는 환자의 사회적 상호 작용, 언어 기술 및 행동 발달을 개선하는 데 도움이 됩니다.
진단 정확도 향상: 자폐증 진단은 전문 의사의 임상 평가에 의존하지만 이 방법은 주관성과 오진의 위험이 있습니다. 선별 및 분석 프로젝트를 통해 첨단 과학 기술 및 데이터 분석 방법을 사용하여 자폐증의 진단 정확도를 높이고 누락 및 오진 사례를 줄일 수 있습니다.
자원 할당 최적화: 자폐증 진단 및 치료에는 상당한 시간, 재정 및 인적 자원이 필요합니다. 선별 및 분석 프로젝트를 통해 우리는 자폐증의 역학적 특성과 사회적 영향을 더 잘 이해할 수 있으므로 자원 할당을 최적화하고 보다 효과적인 지원과 서비스를 제공할 수 있습니다.
연구 및 지식 축적 촉진: 스크리닝 및 분석 프로젝트는 많은 양의 데이터를 수집하여 자폐증 연구를 위한 귀중한 자원과 정보를 제공할 수 있습니다. 이것은 병인, 유전적 요인 및 자폐증의 잠재적 치료법에 대한 통찰력을 얻고 자폐증 분야의 과학적 진보를 촉진하는 데 도움이 될 것입니다.
3. 코드 전투 및 데이터 분석
3.1 데이터 전처리
먼저 데이터 세트를 로드해야 합니다. 데이터 세트의 다운로드 주소:
링크: https://pan.baidu.com/s/1sfb3_w2o5X7ya7Z0R51Npw?pwd=94we
추출 코드: 94we
# 第三方库导入
import numpy as np # 导入numpy库用于进行线性代数计算
import pandas as pd # 导入pandas库用于数据处理
import matplotlib.pyplot as plt # 导入matplotlib库用于数据可视化
import seaborn as sns # 导入seaborn库用于数据可视化
# 读取数据集1和数据集2
df1 = pd.read_csv('Autism_Data.arff', na_values='?')
df2 = pd.read_csv('Toddler Autism dataset July 2018.csv', na_values='?')
sns.set_style('whitegrid') # 设置seaborn风格为白色网格
# 提取ASD类别为YES的数据(成年人)
data1 = df1[df1['Class/ASD'] == 'YES']
# 提取ASD Traits为Yes的数据(幼儿)
data2 = df2[df2['Class/ASD Traits '] == 'Yes']
# 计算ASD阳性成年人的比例
print("成年人: ", len(data1) / len(df1) * 100)
# 计算ASD阳性幼儿的比例
print("幼儿:", len(data2) / len(df2) * 100)
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
3.2 데이터 그래픽 분석
성인 데이터 세트에 대한 누락된 값의 히트맵
sns.heatmap(data1.isnull(), yticklabels=False, cbar=False, cmap='viridis', ax=ax[0])
ax[0].set_title('成年人数据集')
ax[0].set_ylabel('样本索引')
유아 데이터 세트에 대한 히트맵 결측값
sns.heatmap(data2.isnull(), yticklabels=False, cbar=False, cmap='viridis', ax=ax[1])
ax[1].set_title('幼儿数据集')
ax[1].set_ylabel('样本索引')
plt.show() # 显示图形
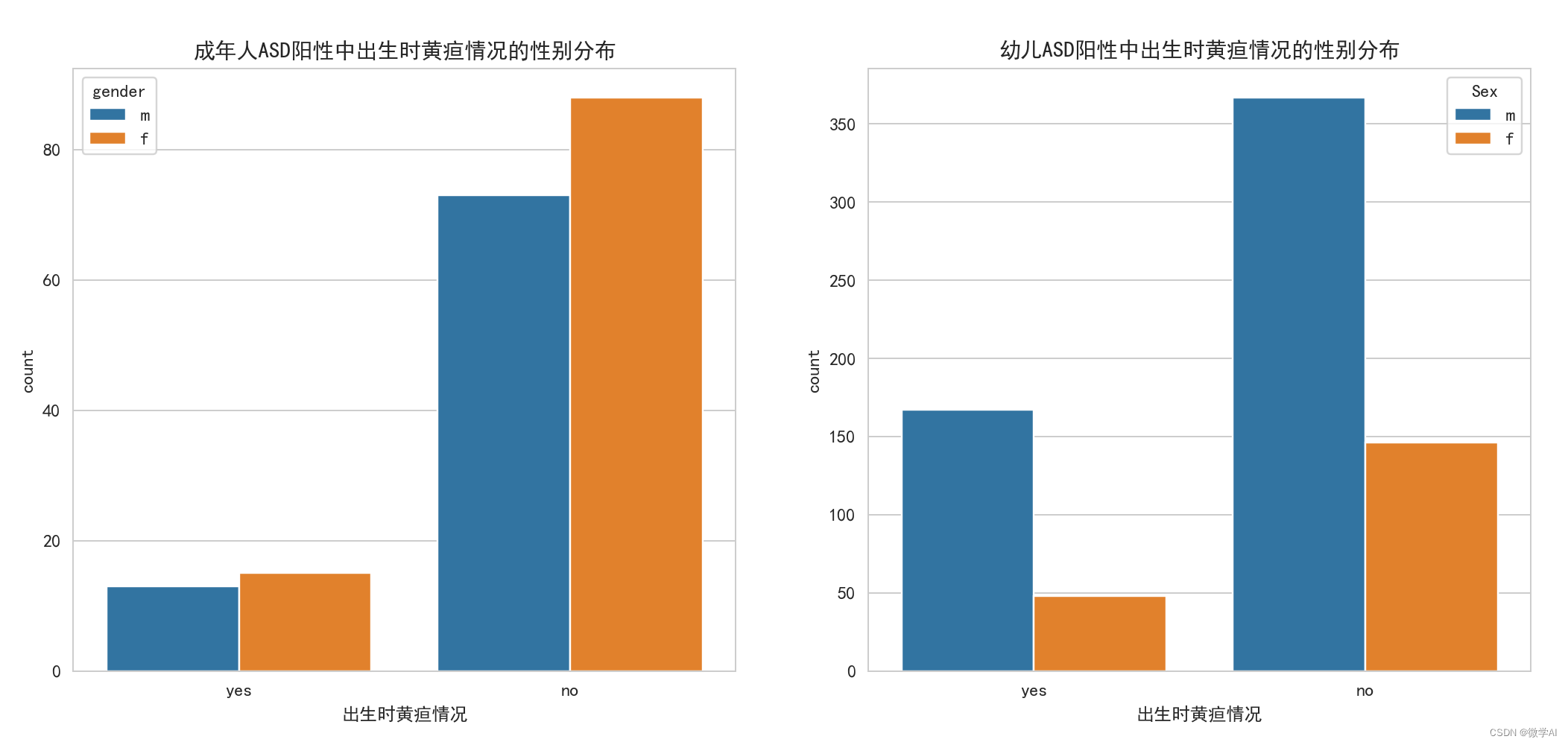
ASD 양성인 성인과 어린이의 출생 시 황달 카운트 히스토그램을 그립니다.
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
# 绘制成年人ASD阳性中出生时黄疸情况的计数柱状图
sns.countplot(x='jundice', data=data1, hue='gender', ax=ax[0])
ax[0].set_title('成年人ASD阳性中出生时黄疸情况的性别分布')
ax[0].set_xlabel('出生时黄疸情况')
# 绘制幼儿ASD阳性中出生时黄疸情况的计数柱状图
sns.countplot(x='Jaundice', data=data2, hue='Sex', ax=ax[1])
ax[1].set_title('幼儿ASD阳性中出生时黄疸情况的性别分布')
ax[1].set_xlabel('出生时黄疸情况')
plt.show() # 显示图形
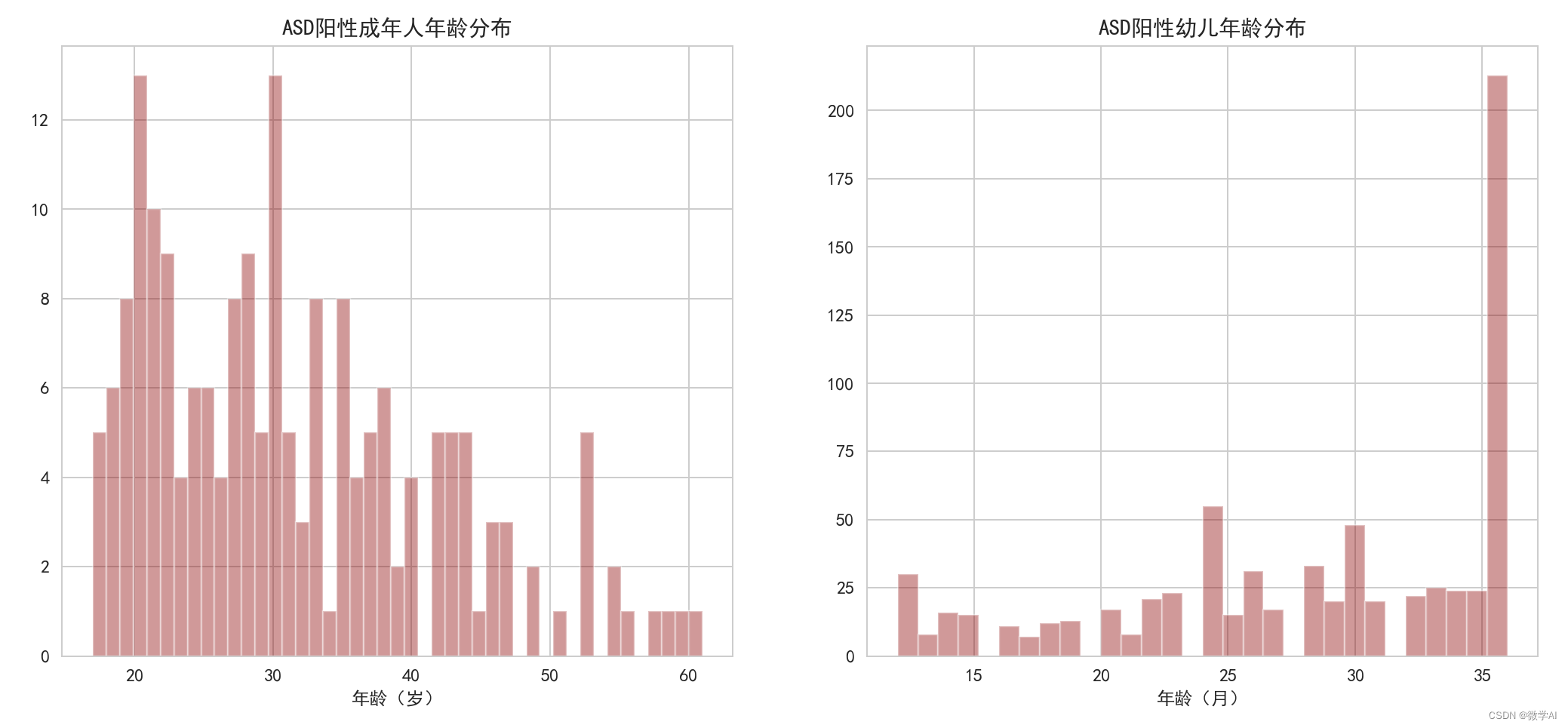
성인, 어린이의 ASD 양성 연령 분포 히스토그램을 그립니다.
# 创建一个包含2个子图的画布,设置大小为20x6
fig, ax = plt.subplots(1, 2, figsize=(20, 6))
# 绘制成年人ASD阳性年龄分布的直方图
sns.distplot(data1['age'], kde=False, bins=45, color='darkred', ax=ax[0])
ax[0].set_xlabel('年龄(岁)')
ax[0].set_title('ASD阳性成年人年龄分布')
# 绘制幼儿ASD阳性年龄分布的直方图
sns.distplot(data2['Age_Mons'], kde=False, bins=30, color='darkred', ax=ax[1])
ax[1].set_xlabel('年龄(月)')
ax[1].set_title('ASD阳性幼儿年龄分布')
plt.show() # 显示图形
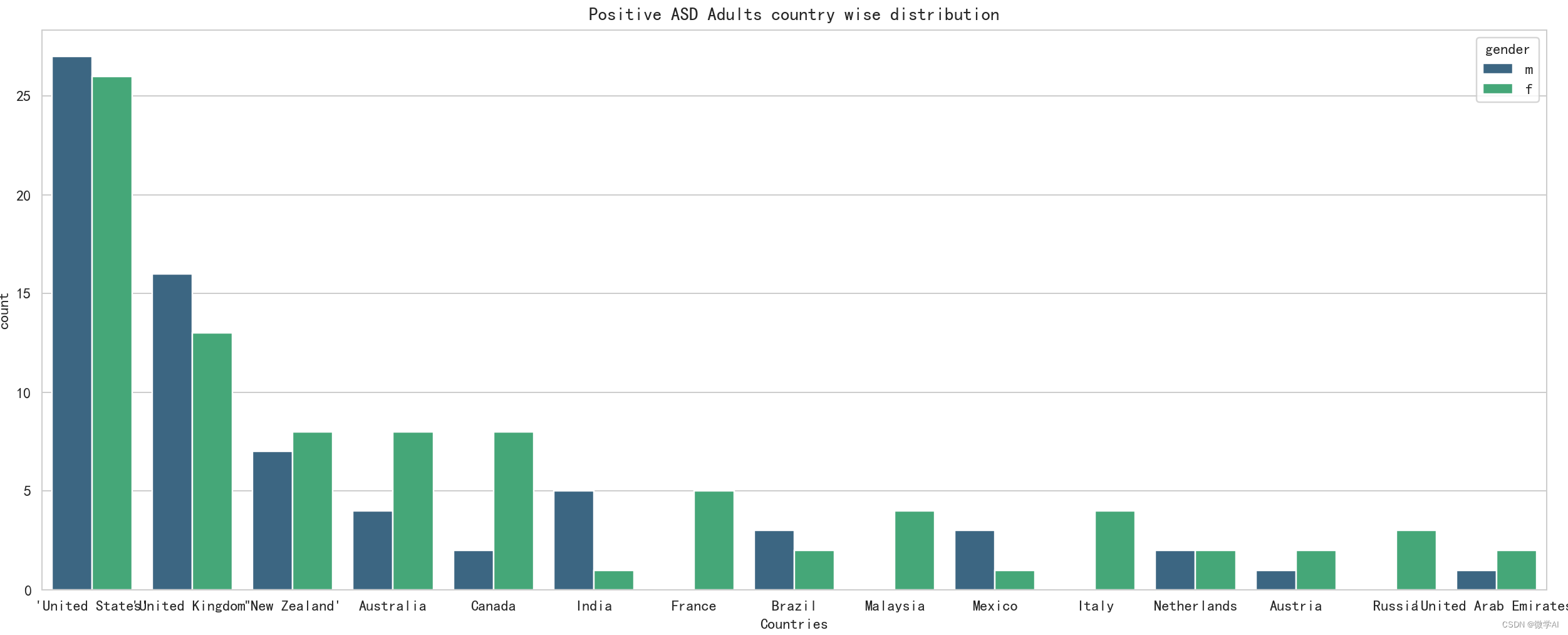
긍정적인 ASD를 가진 성인의 국가 분포 매핑 분석
plt.figure(figsize=(20,6))
sns.countplot(x='contry_of_res',data=data1,order= data1['contry_of_res'].value_counts().index[:15],hue='gender',palette='viridis')
plt.title('Positive ASD Adults country wise distribution')
plt.xlabel('Countries')
plt.tight_layout()
plt.show() # 显示图形
# 输出种族的计数值
print(data1['ethnicity'].value_counts())
data2['Ethnicity'].value_counts()
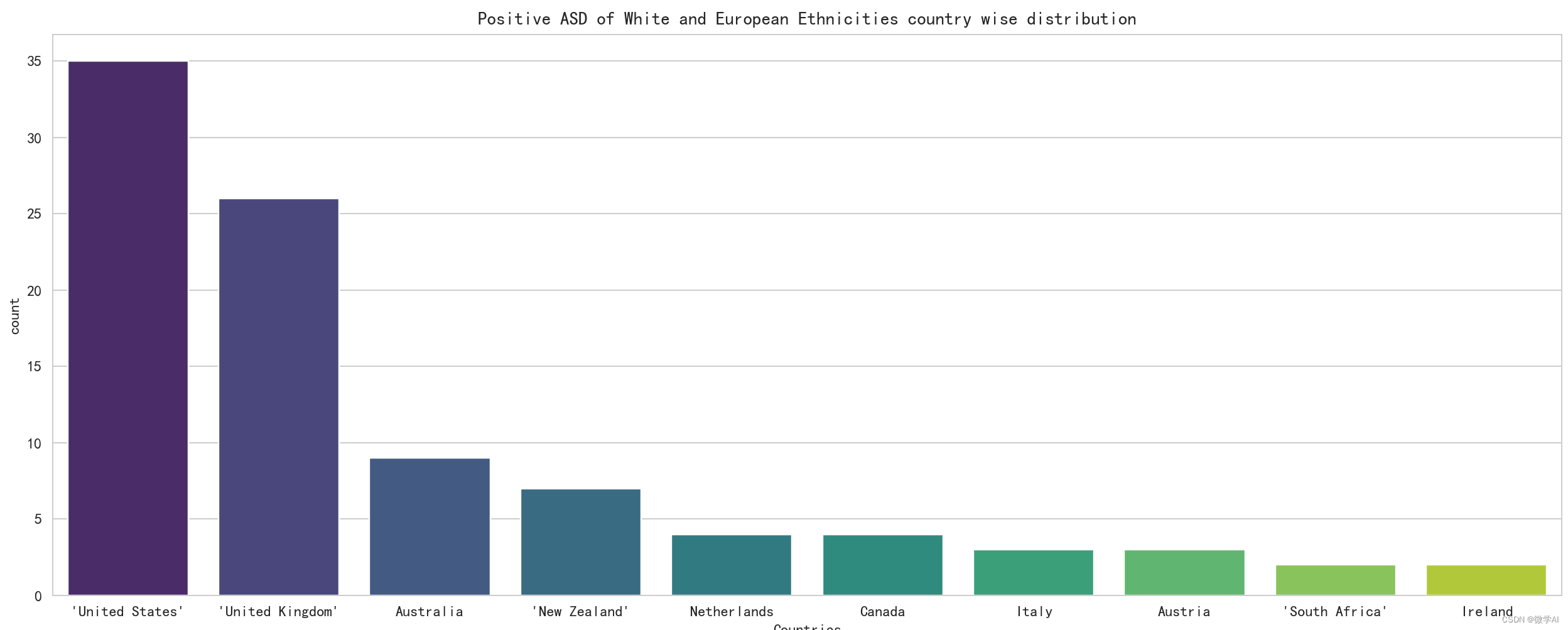
# 绘制白人和欧洲人种族在各个国家的分布图
plt.figure(figsize=(15,6))
sns.countplot(x='contry_of_res',data=data1[data1['ethnicity']=='White-European'],order=data1[data1['ethnicity']=='White-European']['contry_of_res'].value_counts().index[:10],palette='viridis')
plt.title('Positive ASD of White and European Ethnicities country wise distribution')
plt.xlabel('Countries')
plt.tight_layout()
plt.show() # 显示图形
# 绘制不同种族的 ASD 成人亲属中有无自闭症分布和不同种族的 ASD 儿童亲属中有无自闭症分布
fig, ax = plt.subplots(1,2,figsize=(20,6))
sns.countplot(x='austim',data=data1,hue='ethnicity',palette='rainbow',ax=ax[0])
ax[0].set_title('Positive ASD Adult relatives with Autism distribution for different ethnicities')
ax[0].set_xlabel('Adult Relatives with ASD')
sns.countplot(x='Family_mem_with_ASD',data=data2,hue='Ethnicity',palette='rainbow',ax=ax[1])
ax[1].set_title('Positive ASD Toddler relatives with Autism distribution for different ethnicities')
ax[1].set_xlabel('Toddler Relatives with ASD')
plt.tight_layout()
4. 머신러닝 모델 분석
4.1 데이터 원-핫 인코딩
within24_36= pd.get_dummies(df2['Age_Mons']>24,drop_first=True) # 大于24个月的为1,否则为0
within0_12 = pd.get_dummies(df2['Age_Mons']<13,drop_first=True) # 小于13个月的为1,否则为0
male=pd.get_dummies(df2['Sex'],drop_first=True) # 性别为男性的为1,否则为0
ethnics=pd.get_dummies(df2['Ethnicity'],drop_first=True) # 使用独热编码表示种族
jaundice=pd.get_dummies(df2['Jaundice'],drop_first=True) # 是否有黄疸,有黄疸为1,否则为0
ASD_genes=pd.get_dummies(df2['Family_mem_with_ASD'],drop_first=True) # 亲属中是否有自闭症,有自闭症为1,否则为0
ASD_traits=pd.get_dummies(df2['Class/ASD Traits '],drop_first=True) # ASD 特征,有特征为1,否则为0
4.2 데이터 정렬
import pandas as pd
# 将多个数据集按列合并
final_data = pd.concat([within0_12, within24_36, male, ethnics, jaundice, ASD_genes, ASD_traits], axis=1)
# 设置列名
final_data.columns = ['within0_12', 'within24_36', 'male', 'Latino', 'Native Indian', 'Others', 'Pacifica', 'White European', 'asian', 'black', 'middle eastern', 'mixed', 'south asian', 'jaundice', 'ASD_genes', 'ASD_traits']
# 显示合并后的数据的前几行
final_data.head()
from sklearn.model_selection import train_test_split
# 划分特征和标签
X = final_data.iloc[:, :-1]
y = final_data.iloc[:, -1]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
4.3 로지스틱 회귀 모델
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型
logmodel = LogisticRegression()
# 在训练集上训练逻辑回归模型
logmodel.fit(X_train, y_train)
from sklearn.model_selection import GridSearchCV
# 设置网格搜索的参数
param_grid = {
'C': [0.01, 0.1, 1, 10, 100, 1000]}
# 创建逻辑回归模型的网格搜索对象
grid_log = GridSearchCV(LogisticRegression(), param_grid, refit=True)
# 在训练集上进行网格搜索
grid_log.fit(X_train, y_train)
print('GridSearchCV')
# 输出网格搜索得到的最佳模型参数
print(grid_log.best_estimator_)
# 使用网格搜索得到的最佳模型在测试集上进行预测
pred_log = grid_log.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
# 输出逻辑回归模型在测试集上的混淆矩阵和分类报告
print(confusion_matrix(y_test, pred_log))
print(classification_report(y_test, pred_log))
4.4 랜덤 포레스트 모델
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rfc = RandomForestClassifier(n_estimators=100)
# 在训练集上训练随机森林分类器
rfc.fit(X_train, y_train)
# 使用随机森林分类器在测试集上进行预测
pred_rfc = rfc.predict(X_test)
print('RandomForestClassifier')
# 输出随机森林分类器在测试集上的混淆矩阵和分类报告
print(confusion_matrix(y_test, pred_rfc))
print(classification_report(y_test, pred_rfc))
4.5K 최근접 이웃 모델
from sklearn.preprocessing import StandardScaler
# 对特征进行标准化处理
scaler = StandardScaler()
scaler.fit(X)
scaled_features = scaler.transform(X)
X_scaled = pd.DataFrame(scaled_features, columns=X.columns)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=101)
from sklearn.neighbors import KNeighborsClassifier
# 计算不同的K值下的分类错误率
error_rate = []
for i in range(1, 50):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
# 绘制K值和错误率的关系图
plt.figure(figsize=(10, 6))
plt.plot(range(1, 50), error_rate, color='blue', linestyle='dashed', marker='o', markerfacecolor='red', markersize=10)
plt.title('Error rate vs K-value')
plt.xlabel('K')
plt.ylabel('Error Rate')
# 根据错误率最低的K值创建K近邻分类器
knn = KNeighborsClassifier(n_neighbors=13)
knn.fit(X_train, y_train)
# 使用K近邻分类器在测试集上进行预测
pred_knn = knn.predict(X_test)
print(confusion_matrix(y_test, pred_knn))
print(classification_report(y_test, pred_knn))
4.6 실행 결과
로지스틱 회귀 모델:
precision recall f1-score support
0 0.00 0.00 0.00 78
1 0.63 1.00 0.77 133
accuracy 0.63 211
macro avg 0.32 0.50 0.39 211
weighted avg 0.40 0.63 0.49 211
랜덤 포레스트 모델:
precision recall f1-score support
0 0.71 0.37 0.49 78
1 0.71 0.91 0.80 133
accuracy 0.71 211
macro avg 0.71 0.64 0.64 211
weighted avg 0.71 0.71 0.68 211
K 최근접 이웃 분류 모델:
precision recall f1-score support
0 0.68 0.32 0.43 78
1 0.70 0.91 0.79 133
accuracy 0.69 211
macro avg 0.69 0.62 0.61 211
weighted avg 0.69 0.69 0.66 211
5. 요약
pd.concat()이 글은 2018년 7월 유아 자폐증 데이터셋을 통해 자폐증의 상황을 분석하고, 코드와 차트를 통해 시각적 분석을 수행하는데, 여기서 여러 데이터셋을 final_data열별로 하나의 데이터셋 으로 결합하는 함수를 사용합니다. 그런 다음 기능과 레이블을 분리하고 train_test_split()함수를 사용하여 데이터를 교육 및 테스트 세트로 분할합니다.
본 논문에서는 그리드 검색 로지스틱 회귀 모델, 랜덤 포레스트 모델 및 K-최근접 이웃 분류기를 사용하여 훈련 세트를 훈련하고 테스트 세트에 대한 예측을 수행합니다. 마지막으로 모델 성능을 평가하기 위해 모델의 혼동 행렬 및 분류 보고서를 출력합니다.
그 중 특징을 표준화한 후 K 값을 이용하여 1~49 범위 내에서 검색하여 오류율이 가장 낮은 K 값을 찾아 예측 및 평가를 위한 최종 K-최근접 이웃 분류기를 생성한다. .