Tabla de contenido
1. Introducción a los antecedentes del gráfico de conocimiento.
(3) Introducción y comparación de mapas conceptuales de sentido común.
2. Introducción a los mapas conceptuales de sentido común
(1) Ejemplo de diagrama de relación de mapa conceptual de sentido común
(2) Tres tipos de nodos en el gráfico.
(3) Cuatro tipos de relaciones en el mapa.
Es una relación | Parte de la relación | Instancia de relación | Relación propiedad-valor
3. Construcción de un mapa conceptual de sentido común
(1) Marco general para la construcción de gráficos.
Minería de conceptos complejos
(3) Minería de la relación hipónima de conceptos.
Concepto-Taxonomía, relación superior y subordinada
Relación concepto-hiperónimo entre conceptos
(4) Minería de relaciones de atributos de conceptos
Minería de relaciones de atributos públicos basadas en conceptos compuestos.
Minería de relaciones de atributos específicos basadas en palabras de atributos abiertos
(5) Relaciones de herencia del concepto minero
Minería de datos de semillas basados en características de coocurrencia
Entrenamiento de modelos profundos basados en datos semilla
Finalización de la relación basada en la estructura del gráfico existente
(6) Construcción de la relación POI/SPU-concepto
(1) Ejemplos de aplicaciones específicas dentro de Meituan
A la construcción de un mapa de palabras de categorías integral.
Marcado de contenido completo de belleza médica.
(2) Ejemplos de aplicaciones en la industria
Campo de transporte inteligente
5. Ejemplo de simulación simple
(1) Visualización de consultas de la base de datos del gráfico de conocimiento de Neo4j
(2) Sugerencias e ideas de aprendizaje
Referencias, libros y enlaces.
1. Introducción a los antecedentes del gráfico de conocimiento.
(1) Antecedentes básicos
El gráfico de conocimiento es una tecnología para representar y gestionar el conocimiento. Organiza el conocimiento en una estructura de gráfico, donde cada nodo representa una entidad y cada borde representa la relación entre entidades . El concepto de gráfico de conocimiento fue propuesto por primera vez por Google en 2012 y posteriormente recibió amplia atención e investigación por parte del mundo académico y de la industria.
Los antecedentes del gráfico de conocimiento se remontan al desarrollo de la inteligencia artificial. La primera inteligencia artificial se basaba principalmente en sistemas de razonamiento de reglas . La gente escribía una gran cantidad de reglas para permitir que las computadoras simularan la inteligencia humana. Sin embargo, este método tiene problemas como reglas complejas, dificultad de mantenimiento y capacidades de generalización insuficientes, lo que lo hace incapaz de hacer frente a escenarios complejos del mundo real.
Con el desarrollo continuo de la tecnología de Internet y la tecnología de minería de datos, la gente ha comenzado a prestar atención a los métodos para descubrir automáticamente conocimiento a partir de datos a gran escala . El gráfico de conocimiento, como tecnología para el descubrimiento y la gestión automatizados del conocimiento, ha recibido una atención generalizada.
En el proceso de desarrollo del gráfico de conocimiento, el proyecto "Knowledge Graph" de Google ha desempeñado un papel importante en su promoción. El objetivo de este proyecto es construir una base de conocimientos a gran escala que contenga diversas entidades y relaciones que puedan ayudar a las personas a comprender mejor el mundo y permitir búsquedas más inteligentes.

Además de Google, muchas empresas y organizaciones de renombre también están promoviendo activamente la aplicación e investigación de gráficos de conocimiento, como Microsoft, IBM, Alibaba, Tencent, Baidu, etc. Los gráficos de conocimiento se han utilizado ampliamente en diversos campos, incluidos motores de búsqueda, respuesta inteligente a preguntas, análisis semántico, recomendaciones inteligentes, procesamiento del lenguaje natural, etc.
(2) Relación con la PNL
Existe una estrecha relación entre los gráficos de conocimiento y el procesamiento del lenguaje natural (PLN). El procesamiento del lenguaje natural se refiere a la capacidad de utilizar tecnología informática para procesar y comprender el lenguaje natural humano, incluido el análisis, la generación, la comprensión y la aplicación del lenguaje natural. El gráfico de conocimiento es una base de conocimientos creada para implementar mejor las tareas de procesamiento del lenguaje natural.
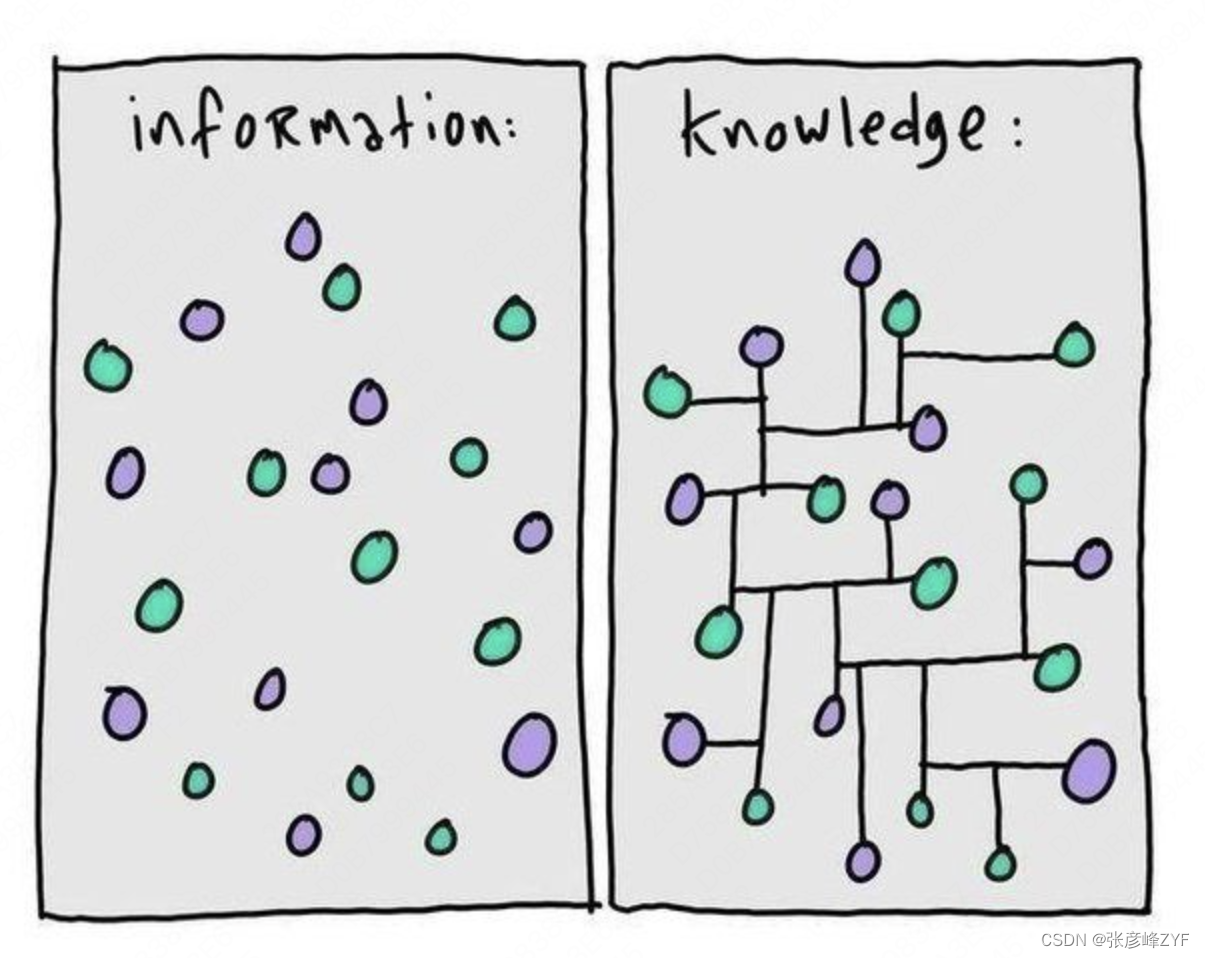
En concreto, una de las tareas del procesamiento del lenguaje natural es la comprensión semántica , que consiste en permitir que las computadoras comprendan el lenguaje humano y extraigan información significativa de él. Los gráficos de conocimiento pueden proporcionar a los algoritmos de procesamiento del lenguaje natural los conocimientos previos y la información contextual necesarios para comprender e interpretar mejor entidades, relaciones, eventos, etc. en textos en lenguaje natural .
Por ejemplo, los sistemas de respuesta a preguntas en lenguaje natural generalmente necesitan extraer las entidades y relaciones involucradas en la pregunta de la pregunta de entrada en lenguaje natural para poder responder la pregunta correctamente. El gráfico de conocimiento puede proporcionar la información necesaria sobre entidades y relaciones para ayudar al sistema de preguntas y respuestas a lograr una comprensión más precisa y completa. Por otro ejemplo, en los sistemas de recomendación inteligentes, los gráficos de conocimiento pueden proporcionar información sobre relaciones y atributos entre usuarios y productos, lo que ayuda al sistema de recomendación a predecir con mayor precisión las preferencias y comportamientos de los usuarios.
(3) Introducción y comparación de mapas conceptuales de sentido común.
Los gráficos de conocimiento, los gráficos conceptuales de sentido común y los gráficos conceptuales son tecnologías utilizadas para representar y almacenar conocimiento. Existen algunas similitudes y superposiciones entre ellos, pero cada uno tiene su propio enfoque y diferencias.
El gráfico de conocimiento es una base de conocimiento multimodal a gran escala que almacena conocimientos como entidades, atributos y relaciones en forma de una estructura gráfica, y organiza y vincula este conocimiento a través de asociaciones semánticas. Los gráficos de conocimiento se utilizan principalmente para el almacenamiento, razonamiento, consulta y aplicación de conocimientos, y se utilizan ampliamente en inteligencia artificial, procesamiento de lenguaje natural, sistemas de recomendación y otros campos.
El gráfico conceptual es un método de representación del conocimiento más general . Puede representar conceptos, entidades y relaciones en cualquier campo. Es más flexible y gratuito que el gráfico de conocimiento y el gráfico conceptual de sentido común. Los gráficos conceptuales se utilizan principalmente para investigaciones sobre representación y razonamiento del conocimiento, y también pueden usarse como una de las tecnologías subyacentes para los gráficos de conocimiento y los gráficos conceptuales de sentido común.
El mapa conceptual de sentido común es un mapa de conocimiento en un campo específico, se utiliza principalmente para representar algunos conceptos, entidades y relaciones básicas involucradas en la vida diaria humana, como personas, lugares, tiempo, objetos, eventos, etc. Los mapas conceptuales de sentido común están diseñados para ayudar a las computadoras a comprender y simular mejor la vida diaria humana y brindar soporte básico para aplicaciones como el procesamiento del lenguaje natural, el diálogo inteligente y el análisis de sentimientos.
Por tanto, la relación entre mapa de conocimiento, mapa conceptual de sentido común y mapa conceptual puede entenderse como una relación jerárquica. El mapa conceptual es el nivel más bajo de método de representación del conocimiento. El mapa de conocimiento es una base de conocimiento más grande con un valor de aplicación más práctico construido sobre la base del mapa conceptual. El mapa conceptual de sentido común es una aplicación del mapa de conocimiento en un campo específico. Se utiliza para representar lo común. conocimiento sensorial en la vida diaria humana.
2. Introducción a los mapas conceptuales de sentido común
El mapa conceptual de sentido común es un mapa de conocimiento basado en el sentido común humano. Construye y mantiene elementos de conocimiento multidimensionales como entidades, conceptos, atributos, relaciones, eventos, etc., y los organiza en forma de un mapa para facilitar la computadora. comprensión y razonamiento .
En comparación con los mapas de conocimiento tradicionales, los mapas conceptuales de sentido común prestan más atención a la expresión y aplicación del sentido común humano y contienen elementos de conocimiento más ricos y detallados . Por ejemplo, en un mapa conceptual de sentido común en el campo del turismo, además de entidades como atracciones y hoteles, también incluye conceptos de sentido común como el propósito, método y precauciones de los viajes de las personas, así como el atributos y relaciones entre ellos.
La construcción de un mapa conceptual de sentido común requiere la ayuda de una gran cantidad de corpus y bibliotecas de sentido común, así como la extracción automatizada de conocimientos, la vinculación de entidades, la extracción de relaciones y otras tecnologías para construir y actualizar rápidamente el mapa. Los mapas conceptuales de sentido común también se utilizan ampliamente. Por ejemplo, en los campos de servicio al cliente inteligente, búsqueda inteligente, recomendación inteligente, preguntas y respuestas inteligentes, etc., pueden mejorar en gran medida la capacidad de la computadora para comprender y procesar el lenguaje natural, mejorando así sirviendo a los seres humanos. Después de leer muchos artículos, finalmente utilizamos la aplicación práctica del algoritmo MATLAB: [Caso de aplicación] Construcción de un mapa conceptual de sentido común y su aplicación en escenarios de Meituan_caso práctico de matlab_blog-blog CSDN de Lin Congmu como análisis principal
(1) Ejemplo de diagrama de relación de mapa conceptual de sentido común
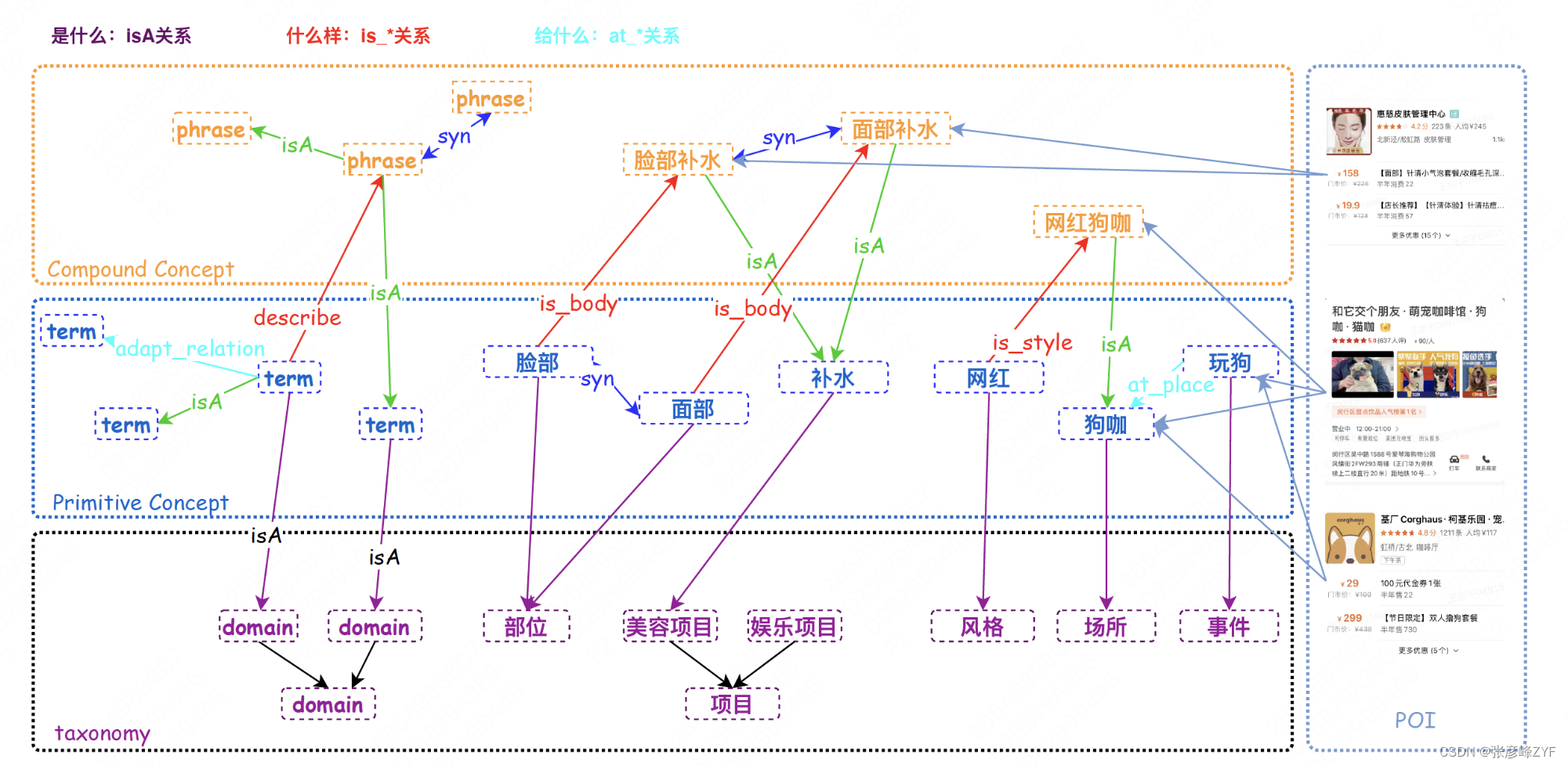
Como se mencionó anteriormente, " construyendo y manteniendo elementos de conocimiento multidimensionales como entidades, conceptos, atributos, relaciones y eventos, y organizándolos en forma de gráficos para facilitar la comprensión y el razonamiento por computadora". En resumen, Meituan puede usar el siguiente figura Expanda y analice el gráfico de conocimiento,
Cubre la arquitectura taxonómica del concepto de "lo que es", la relación de atributos del concepto de "qué" y el concepto de relación de herencia de "lo que se da". Al mismo tiempo, los puntos de interés (puntos de interés), SPU (unidades de productos estándar) y pedidos grupales, como ejemplos en el escenario de Meituan, deben conectarse a los conceptos del mapa.
(2) Tres tipos de nodos en el gráfico.
Los tres tipos de nodos en el gráfico de conocimiento se refieren a nodos de entidad, nodos de atributos y nodos de relación. El método de clasificación de nodos basado en la clasificación de conceptos se usa generalmente para la representación semántica de ontologías o gráficos de conocimiento para ayudar a la comprensión y el razonamiento de la máquina. Entre ellos, son comunes los siguientes tres tipos de nodos:
- Nodo de taxonomía (nodo del árbol de clasificación) : representa un nodo en el árbol de clasificación, cada nodo representa una categoría. Es una estructura jerárquica, con nodos de nivel superior que representan categorías más abstractas y nodos de nivel inferior que representan entidades específicas.
- Nodo de concepto atómico : representa la unidad de concepto más básica y no se puede dividir en conceptos más pequeños . Los conceptos atómicos suelen representar las propiedades esenciales de una cosa y son la base de otros conceptos. Por ejemplo, en un gráfico de conocimiento de clasificación animal, perros, gatos, pájaros, etc. son nodos de conceptos atómicos.
- Nodo de concepto compuesto : un concepto compuesto compuesto por múltiples nodos de concepto atómico. Puede representar entidades y conceptos más complejos y es un nodo de nivel superior en el gráfico de conocimiento. Por ejemplo, en un gráfico de conocimiento de clasificación humana, los nodos de conceptos compuestos pueden ser "jóvenes", "personas mayores", "hombres", "mujeres", etc.
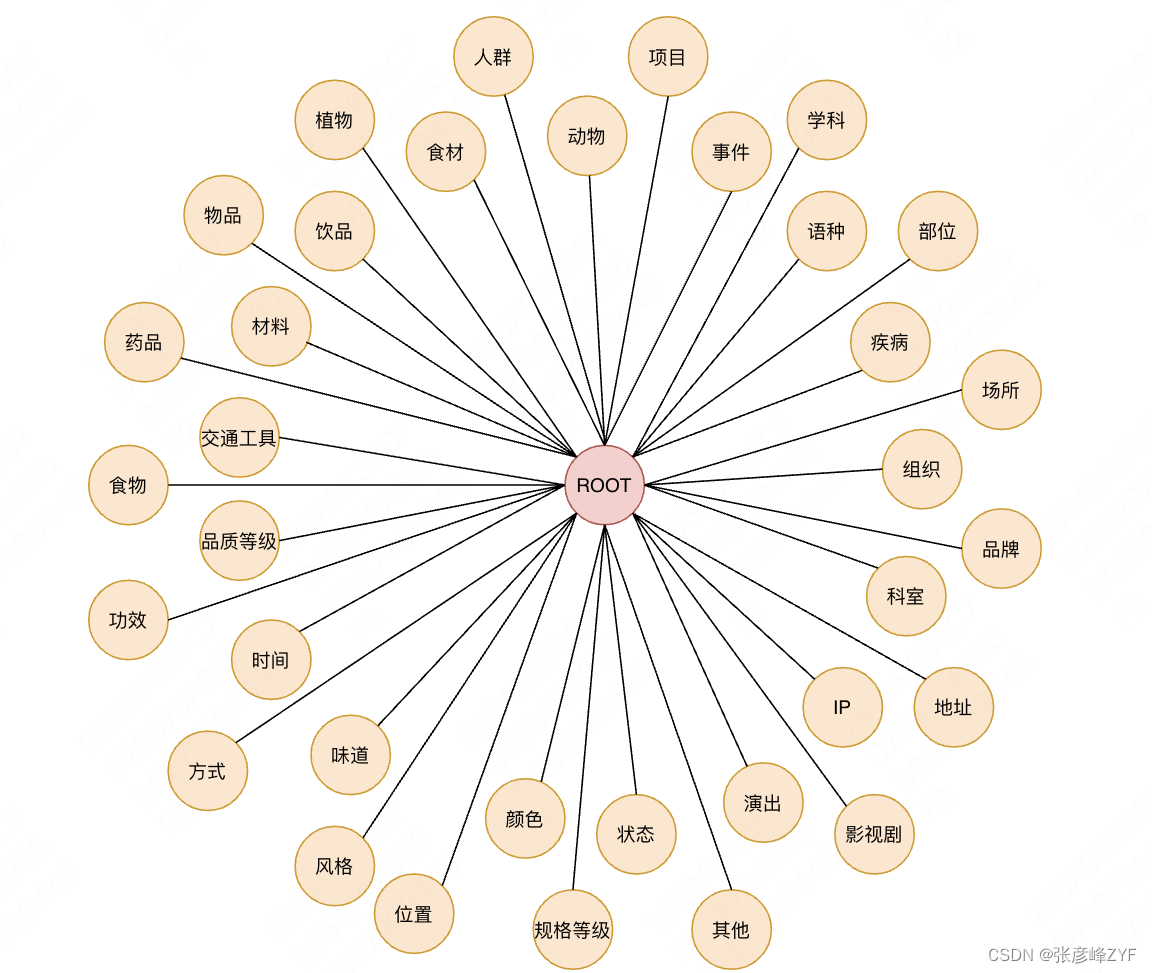
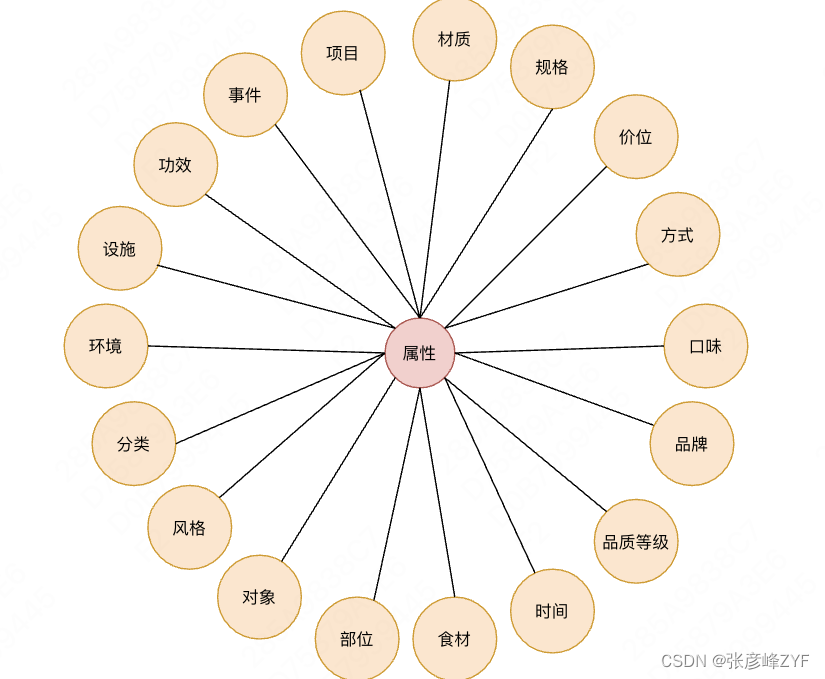
Comprender un concepto requiere un sistema de conocimiento razonable. El sistema de conocimiento de Taxonomía predefinido sirve como base para la comprensión. El sistema predefinido se divide en dos tipos de nodos: el primer tipo puede aparecer como una categoría central en el escenario de Meituan, por ejemplo, Ingredientes , elementos, lugares; el otro tipo aparece como una forma de limitar categorías centrales, como color, método, estilo. La definición de estos dos tipos de nodos puede ayudar a comprender la búsqueda, recomendación, etc. Los nodos de taxonomía actualmente predefinidos se muestran en la siguiente figura:
(3) Cuatro tipos de relaciones en el mapa.
Es una relación | Parte de la relación | Instancia de relación | Relación propiedad-valor
Los mapas basados en la clasificación de conceptos suelen contener los siguientes cuatro tipos de relaciones:
- Relación es-a : Indica la relación híbrida superior entre conceptos. Por ejemplo, "gato" es un tipo de "animal", que se puede expresar como Gato es un tipo de animal.
- Relación parte de : Indica que un objeto o concepto es parte de otro objeto o concepto. Por ejemplo, "rueda" es parte de "automóvil", que se puede expresar como Rueda es parte de Auto.
- Relación instancia-de : Indica que una cosa específica es una instancia de un determinado concepto, por ejemplo, "Garfield" es una instancia de "gato", que se puede expresar como Garfield es una instancia de Cat.
- Relación propiedad-valor : representa la relación entre un concepto y sus propiedades, por ejemplo, el color de "Garfield" es "naranja", lo que se puede expresar como Garfield tiene la propiedad de Color con valor Naranja.
Estas relaciones se pueden utilizar para describir las asociaciones semánticas entre conceptos y se utilizan ampliamente en el procesamiento del lenguaje natural, el razonamiento del conocimiento y otros campos. Tomando el caso de Meituan como ejemplo, se puede detallar y ampliar en las siguientes cuatro introducciones detalladas.
Relación sinónimo/hiperónimo
Sinónimos/hiperónimos semánticos, como hidratación facial-syn-hidratación facial, etc. El sistema de taxonomía definido también es una relación de hiperónimo, por lo que se fusiona en la relación sinónimo/hiperónimo.
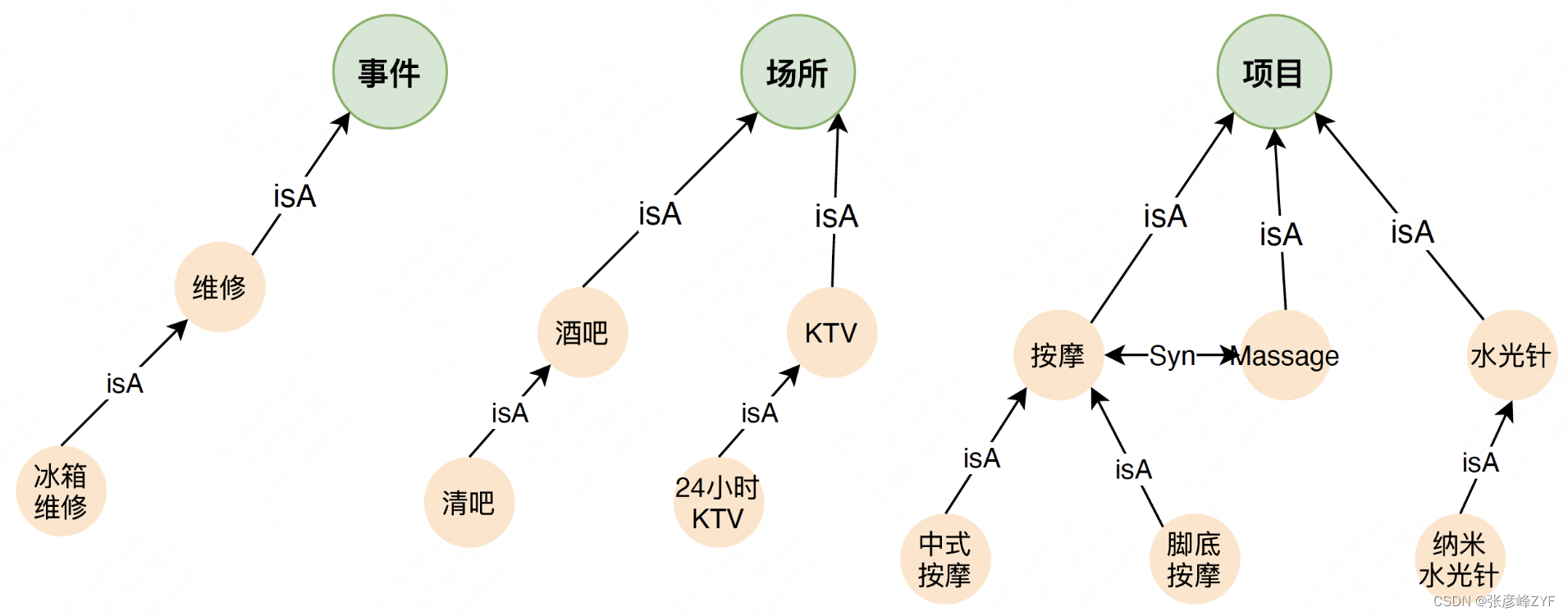
relación concepto atributo
Una relación CPV (Concepto-Propiedad-Valor) típica describe y define conceptos de varias dimensiones de atributos, como estofado - sabor - no picante, estofado - especificaciones - una sola persona, etc. Los ejemplos son los siguientes:
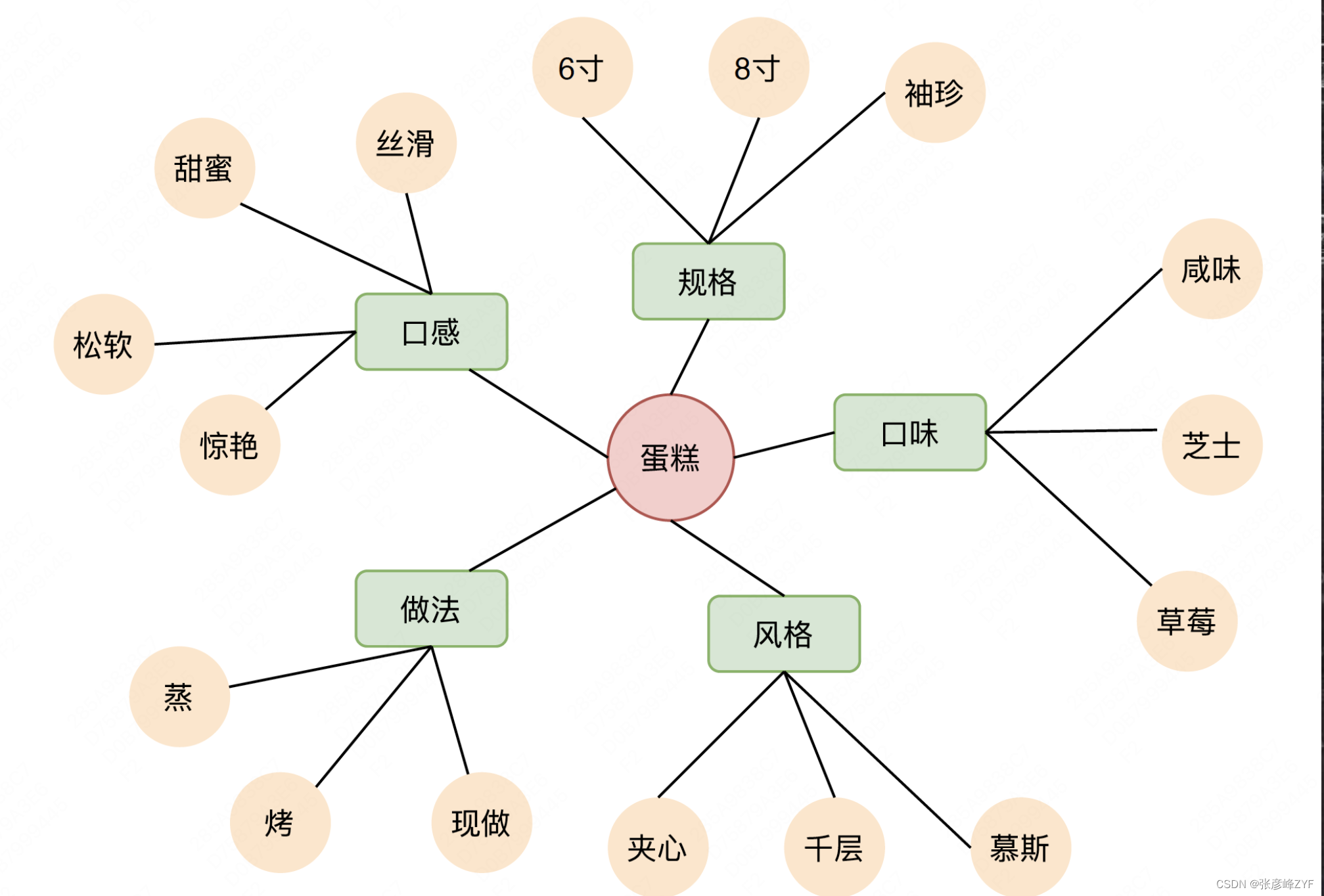
Las relaciones de atributos de conceptos incluyen dos categorías:
Atributos de concepto predefinidos: actualmente predefinimos atributos de concepto típicos como se muestra a continuación.
Atributos de concepto abierto: además de los atributos de concepto público definidos por nosotros mismos, también extraemos algunas palabras de atributos específicos del texto y complementamos algunas palabras de atributos específicos. Por ejemplo, postura, tema, comodidad, reputación, etc.
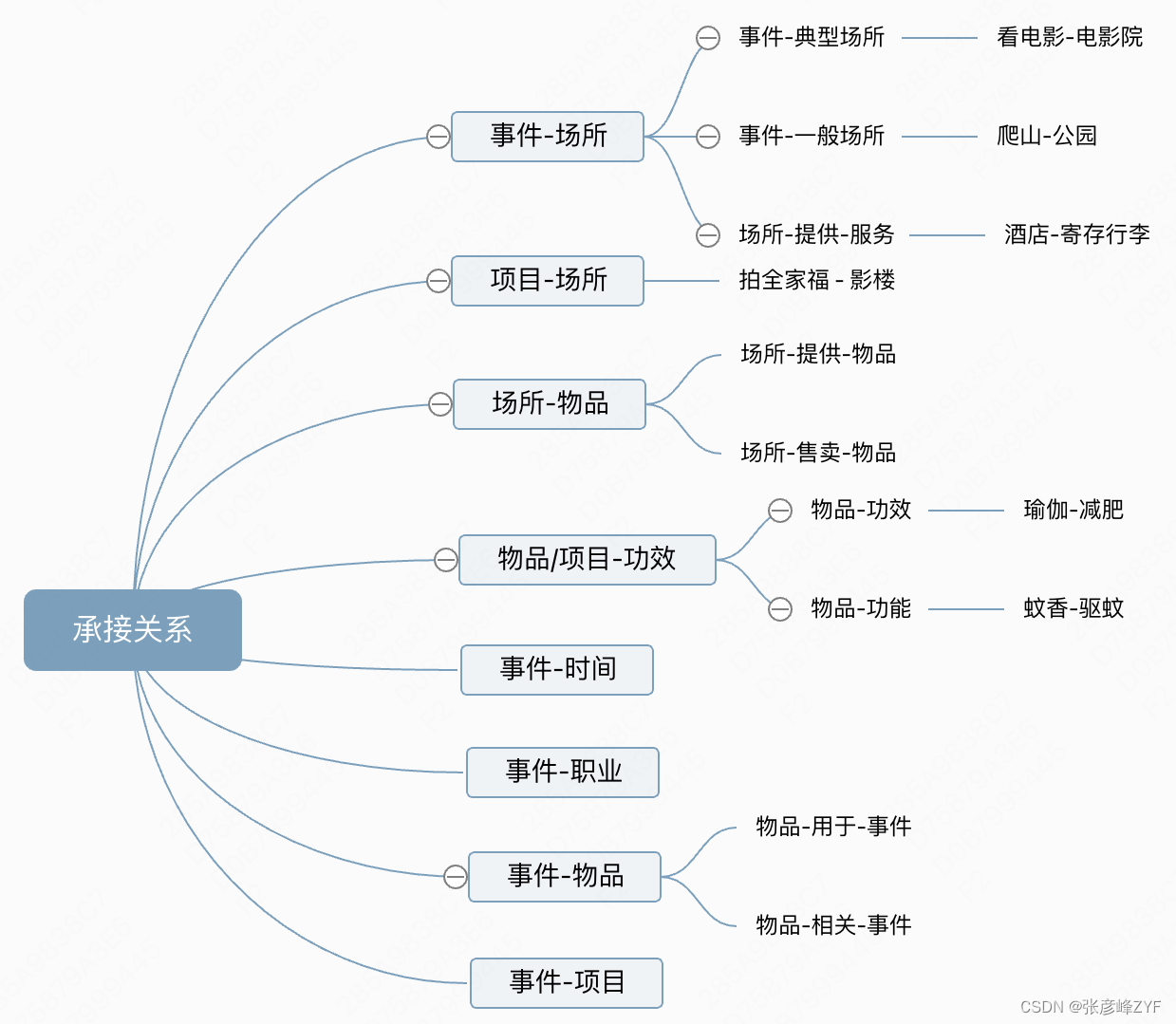
concepto de relación de herencia
Este tipo de relación establece principalmente vínculos entre los conceptos de búsqueda de los usuarios y los conceptos de emprendimiento de Meituan, como salida de primavera-lugar-jardín botánico, alivio del estrés-proyecto-boxeo, etc.
El concepto de relación de herencia toma "evento" como núcleo y define un tipo de conceptos de suministro que pueden satisfacer las necesidades del usuario, como "lugar", "artículo", "multitud", "tiempo" y "función". Tomemos como ejemplo el evento "blanqueamiento": como demanda del usuario, el "blanqueamiento" se puede satisfacer mediante diferentes conceptos de suministro, como salones de belleza, inyecciones de agua y luz, etc. Actualmente, se definen varios tipos de relaciones de herencia como se muestra en la siguiente figura:
Relación POI/SPU-concepto
POI es una instancia en el escenario de Meituan, y la relación instancia-concepto es la última parada en el gráfico de conocimiento y, a menudo, es el lugar donde se puede utilizar plenamente el valor comercial del gráfico de conocimiento. En escenarios comerciales como búsqueda y recomendación, el objetivo final es poder mostrar PDI que satisfagan las necesidades del usuario, por lo que establecer la relación PDI/concepto SPU es una parte importante del mapa conceptual de sentido común de todo el escenario de Meituan. y además son datos relativamente valiosos. .
3. Construcción de un mapa conceptual de sentido común
Tomemos como ejemplo el artículo de Meituan para seguir viendo el proceso correspondiente.
(1) Marco general para la construcción de gráficos.
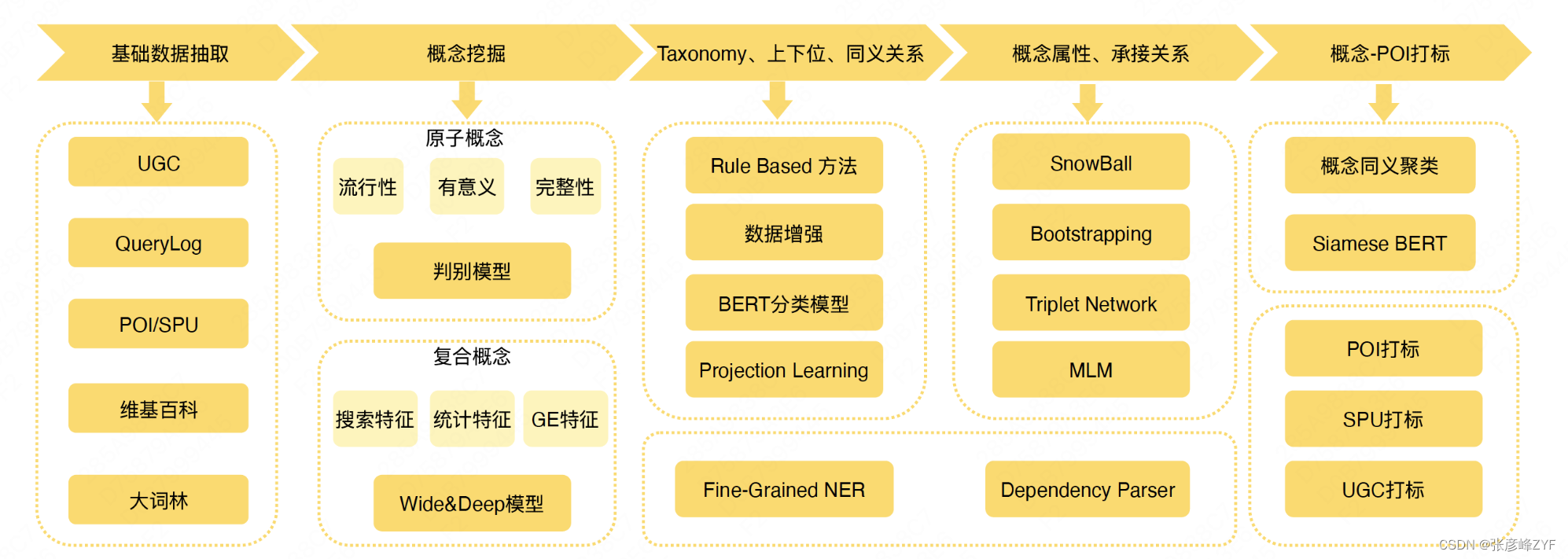
(2) Minería de conceptos
Varias relaciones en el mapa conceptual de sentido común se construyen en torno a conceptos, y la extracción de estos conceptos es el primer paso en la construcción del mapa conceptual de sentido común. Según los dos tipos de conceptos atómicos y conceptos compuestos, se adoptan los métodos correspondientes para la minería.
Minería de conceptos atómicos
Los candidatos a conceptos atómicos provienen de los fragmentos más pequeños después de la segmentación de palabras del texto, como consulta, UGC (contenido generado por el usuario) y Tuandan. Los criterios de evaluación para los conceptos atómicos son que deben cumplir con las tres características de popularidad, importancia e integridad.
- Popularidad , un concepto debe ser una palabra con alta popularidad en un determinado o determinado corpus. Esta característica se mide principalmente por características de frecuencia. Por ejemplo, el volumen de búsqueda de la palabra "desktop kill" es muy bajo y la frecuencia en el corpus UGC es también muy bajo. , no cumple con los requisitos de popularidad.
- Significativo , un concepto debe ser una palabra significativa. Esta característica se mide principalmente por características semánticas. Por ejemplo, "gato" y "perro" generalmente solo representan un nombre simple sin otros significados reales.
- Completitud , un concepto debe ser una palabra completa. Esta característica se mide principalmente por la proporción de búsquedas independientes (el volumen de búsqueda de la palabra como Consulta / el volumen total de búsqueda de la Consulta que contiene la palabra). Por ejemplo, "diseño infantil "Es un error de segmentación de palabras. Los candidatos tienen una alta frecuencia en UGC, pero tienen una baja proporción de búsquedas independientes.
Según las características anteriores del concepto atómico, el modelo de clasificación XGBoost se entrena con datos de entrenamiento construidos automáticamente mediante anotaciones manuales y reglas para juzgar si el concepto atómico es razonable.
Minería de conceptos complejos
Los candidatos a conceptos compuestos provienen de la combinación de conceptos atómicos. Dado que se trata de combinaciones, el juicio de conceptos compuestos es más complejo que el juicio de conceptos atómicos. El concepto compuesto requiere un cierto nivel de comprensión dentro de Meituan y al mismo tiempo garantiza una semántica completa. Según el tipo de problema, se adopta la estructura modelo de Wide&Deep: el lado profundo es responsable del juicio semántico y el lado ancho introduce la información en el sitio.
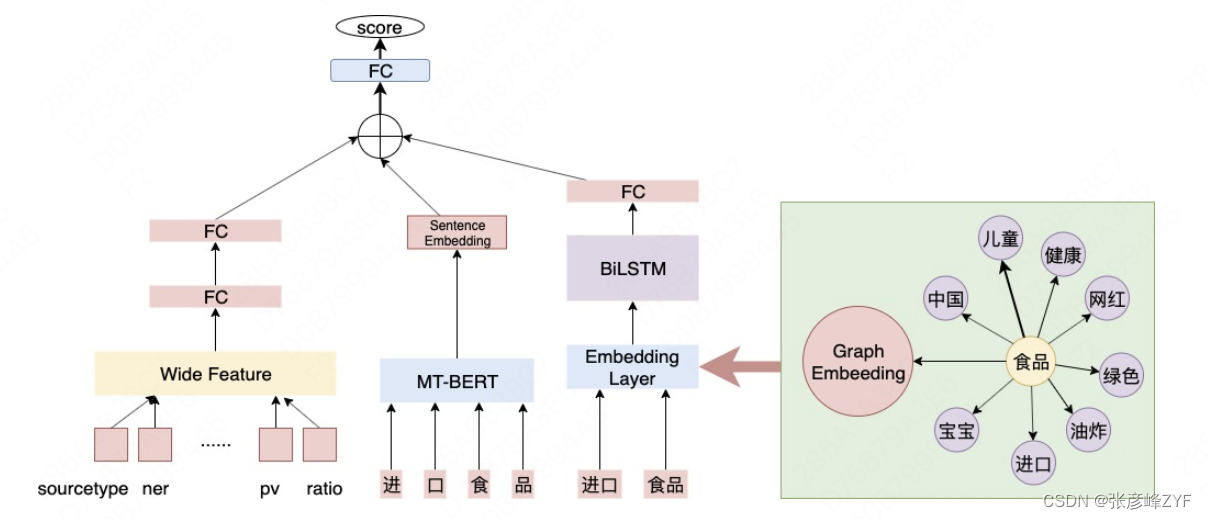
La estructura del modelo tiene las dos características siguientes para juzgar con mayor precisión la racionalidad de los conceptos compuestos:
- Estructura de modelo amplia y profunda : combinación de características discretas con modelos profundos para determinar si los conceptos compuestos son razonables.
- Función de incrustación de gráficos : introduzca la información asociada entre combinaciones de palabras, como "comida" que puede coincidir con "multitud", "métodos de cocción", "calidad", etc.
(3) Minería de la relación hipónima de conceptos.
Después de adquirir un concepto, aún necesita comprender "qué" es un concepto. Por un lado, puede comprenderlo a través de la relación de hiperónimo en el sistema de conocimiento de Taxonomía definido artificialmente y, por otro lado, puede comprenderlo a través de la Relación hipónima entre conceptos.
Concepto-Taxonomía, relación superior y subordinada
La relación epinima entre conceptos y taxonomía es comprender qué es un concepto a través de un sistema de conocimiento definido manualmente. Dado que el tipo de taxonomía es un tipo definido manualmente, este problema se puede transformar en un problema de clasificación. Al mismo tiempo, un concepto puede tener varios tipos en el sistema de taxonomía. Por ejemplo, "pescado lima" es tanto un "animal" como un "ingrediente alimentario", por lo que este problema finalmente se trata como una tarea de tipificación de entidades. El concepto y su contexto correspondiente se utilizan como entrada del modelo, y se colocan diferentes categorías de taxonomía en el mismo espacio para el juicio. La estructura del modelo específico se muestra en la siguiente figura:
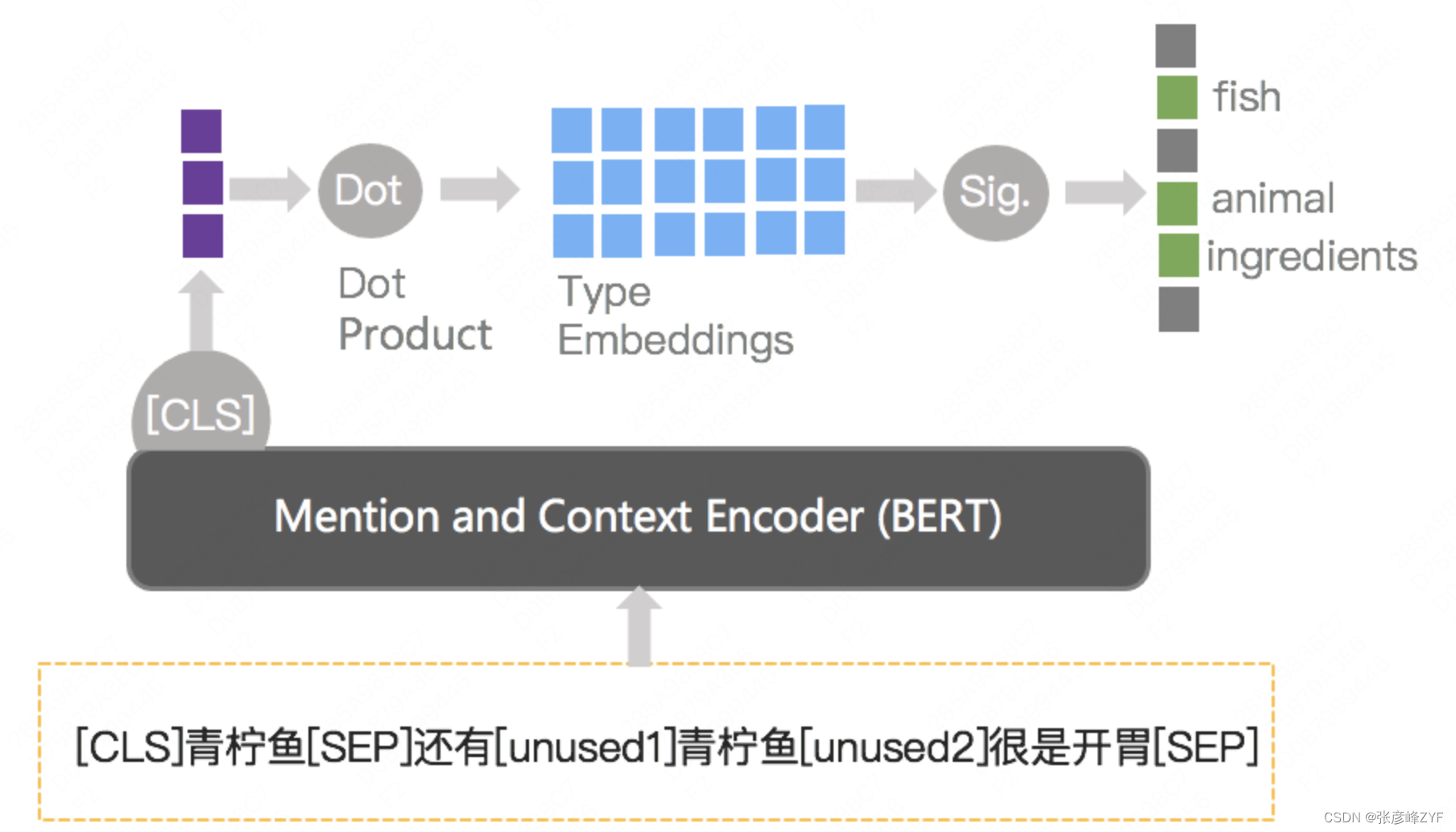
Relación concepto-hiperónimo entre conceptos
El sistema de conocimiento utiliza tipos definidos artificialmente para comprender qué es un concepto, pero los tipos definidos artificialmente siempre son limitados. Si el hiperónimo no está en el tipo definido artificialmente, dicha relación de hiperónimo no se puede entender. Por ejemplo, a través de la relación concepto-Taxonomía se puede entender que "instrumentos musicales occidentales", "instrumentos musicales" y "Erhu" son todos una especie de "elemento", pero no hay forma de obtener la relación entre "instrumentos musicales occidentales". instrumentos" e "Instrumentos musicales", "Erhu" e "Instrumentos musicales". la relación superior-subordinado entre ellos. Con base en los problemas anteriores, actualmente se utilizan los dos métodos siguientes para explorar la relación hiperhíbrida entre conceptos.
Métodos basados en reglas léxicas.
Resuelve principalmente la relación de hiponimia entre conceptos atómicos y conceptos compuestos, y utiliza la relación de inclusión léxica de pares de relaciones candidatas (como instrumentos musicales occidentales - instrumentos musicales) para extraer las relaciones de hipernimia.
Método de juicio basado en el contexto
Las reglas léxicas pueden resolver el juicio de pares de relaciones de hipernimia e hiponimia que contienen relaciones léxicas. Para pares de relaciones de hiperónimo e hiponimia que no tienen relaciones de inclusión léxica, como "erhu-instrumento", primero es necesario descubrir la relación de hiperónimo y extraer candidatos de relación como "erhu-instrumento", y luego juzgar la relación de hiperónimo y determine que "el "instrumento Erhu" es un par de relación híbrido superior razonable. Considerando que cuando las personas explican un objeto, introducirán el tipo de objeto, por ejemplo, al explicar el concepto de "erhu", mencionarán "erhu es un instrumento musical tradicional", de dicho texto explicativo, ambos pares candidatos a relación como "erhu-instrumento" se puede extraer, y al mismo tiempo también se puede juzgar si el par candidato de relación es razonable. Aquí, la extracción de relaciones superiores e hiponímicas se divide en dos partes: extracción de la descripción de la relación candidata y clasificación de las relaciones superiores e hiponímicas:
- Extracción de descripción de relación candidata : dos conceptos pertenecen al mismo tipo de taxonomía. Es un par de conceptos candidatos y una condición necesaria para un par de relaciones de hipónimo. Por ejemplo, "erhu" e "instrumento" pertenecen a "elementos" definidos en la taxonomía. sistema. Según el concepto: El resultado de la relación de hiponimia de la taxonomía. Para que el concepto se extraiga para la relación de hiponimia, se encuentra que los conceptos candidatos que son consistentes con su tipo de taxonomía forman pares de relaciones candidatas y luego, en función de la coocurrencia De los pares de relaciones candidatos en el texto, se seleccionan los utilizados para la clasificación de relaciones de hiponimia. Oraciones descriptivas relacionales candidatas.
- Clasificación de relaciones de hiperónimo e hipónimo : Después de obtener las oraciones de descripción de la relación candidata, es necesario juzgar si las relaciones de hiperónimo e hipónimo son razonables según el contexto. Aquí, las posiciones inicial y final de los dos conceptos en el texto están marcadas con marcadores especiales, y dos Los vectores en la marca de posición inicial del concepto en el texto se unen como una representación de la relación entre los dos. Con base en esta representación, se clasifican las relaciones superiores e inferiores. El vector representa la Salida de resultados utilizando BERT. La estructura detallada del modelo se muestra en la siguiente figura:
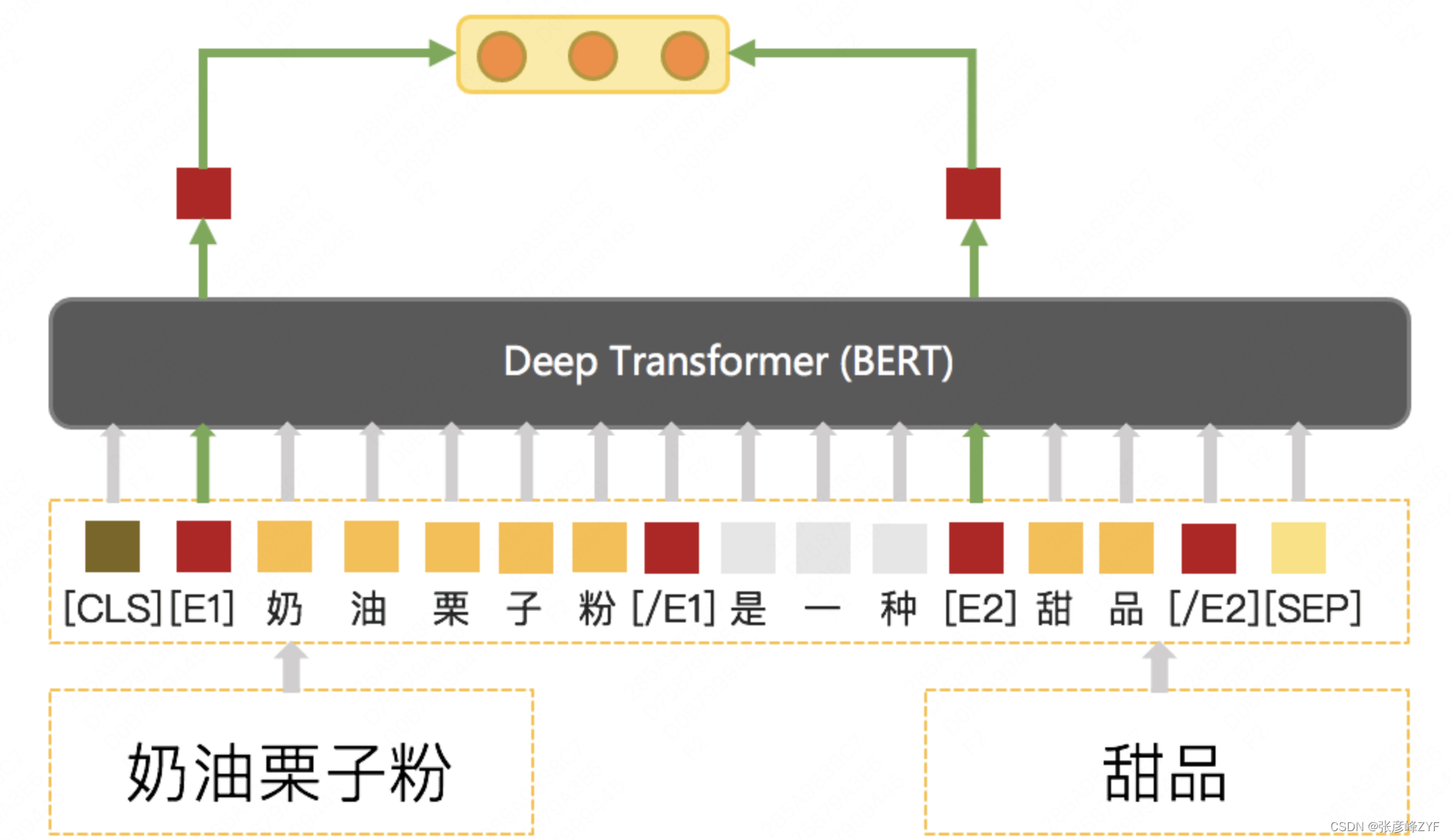
En la construcción de datos de entrenamiento, dado que las oraciones que expresan la relación de hipónimo son muy escasas, una gran cantidad de oraciones concurrentes no indican claramente si el par de relaciones candidatas tiene una relación de hipónimo. La relación de hiperónimo existente se utiliza para construir el entrenamiento. datos mediante supervisión remota. Esto no es factible, por lo que el modelo se entrena directamente utilizando el conjunto de entrenamiento etiquetado manualmente. Dado que el número de anotaciones manuales es relativamente limitado y la magnitud es de miles, se utiliza el algoritmo de aprendizaje semi-supervisado UDA (aumento de datos no supervisado) de Google para mejorar el efecto del modelo. La precisión final puede alcanzar más del 90%. Los indicadores detallados son como sigue:

(4) Minería de relaciones de atributos de conceptos
Los atributos contenidos en un concepto se pueden dividir en atributos públicos y atributos abiertos según si los atributos son universales. Los atributos públicos son atributos definidos manualmente que se incluyen en la mayoría de conceptos, como precio, estilo, calidad, etc. Los atributos abiertos se refieren a atributos que solo están incluidos en ciertos conceptos específicos, por ejemplo, "trasplante de cabello", "extensiones de pestañas" y "eliminación de guiones" contienen atributos abiertos "densidad", "curvatura" y "lógica" respectivamente. Hay muchas más propiedades abiertas que propiedades públicas. Para estas dos relaciones de atributos, utilizamos los siguientes dos métodos para extraer.
Minería de relaciones de atributos públicos basadas en conceptos compuestos.
Debido a la versatilidad de los atributos públicos, el valor en la relación de atributos públicos (CPV) suele aparecer en combinación con el concepto en forma de un concepto compuesto, por ejemplo, centros comerciales asequibles, cocina japonesa y películas rojas en alta definición. Transformamos la tarea de minería de relaciones en análisis de dependencia y tareas NER detalladas (consulte el artículo " Exploración y práctica de la tecnología NER en la búsqueda de Meituan "). El análisis de dependencia identifica las entidades centrales y los componentes modificados en el concepto compuesto, y finamente Juicio NER detallado Genera valores de atributos específicos. Por ejemplo, dado el concepto compuesto "película roja HD", el análisis de dependencia identifica el concepto central de "película", "rojo" y "HD" son atributos de "película", y NER detallado predice que los valores del atributo son "Estilo" respectivamente. )", "Evaluación de calidad (HD)".
El análisis de dependencia y el NER detallado tienen información que se puede utilizar entre sí, como los tipos de entidad de "Muñeca de graduación", "Tiempo" y "Producto", y "Muñeca" es la información de dependencia de la palabra central, que puede utilizarse mutuamente Facilita la formación para que las dos tareas se aprendan de forma conjunta. Sin embargo, dado que el grado de correlación entre las dos tareas no está claro y hay mucho ruido, Meta-LSTM se utiliza para optimizar el aprendizaje conjunto de Feature-Level en el aprendizaje conjunto de Function-Level y cambiar el intercambio duro a dinámico. compartir y reducir el costo de ambas tareas. El impacto del ruido entre tareas.
La arquitectura general del modelo es la siguiente: actualmente, la precisión general de la relación de modificación del concepto es de alrededor del 85%:
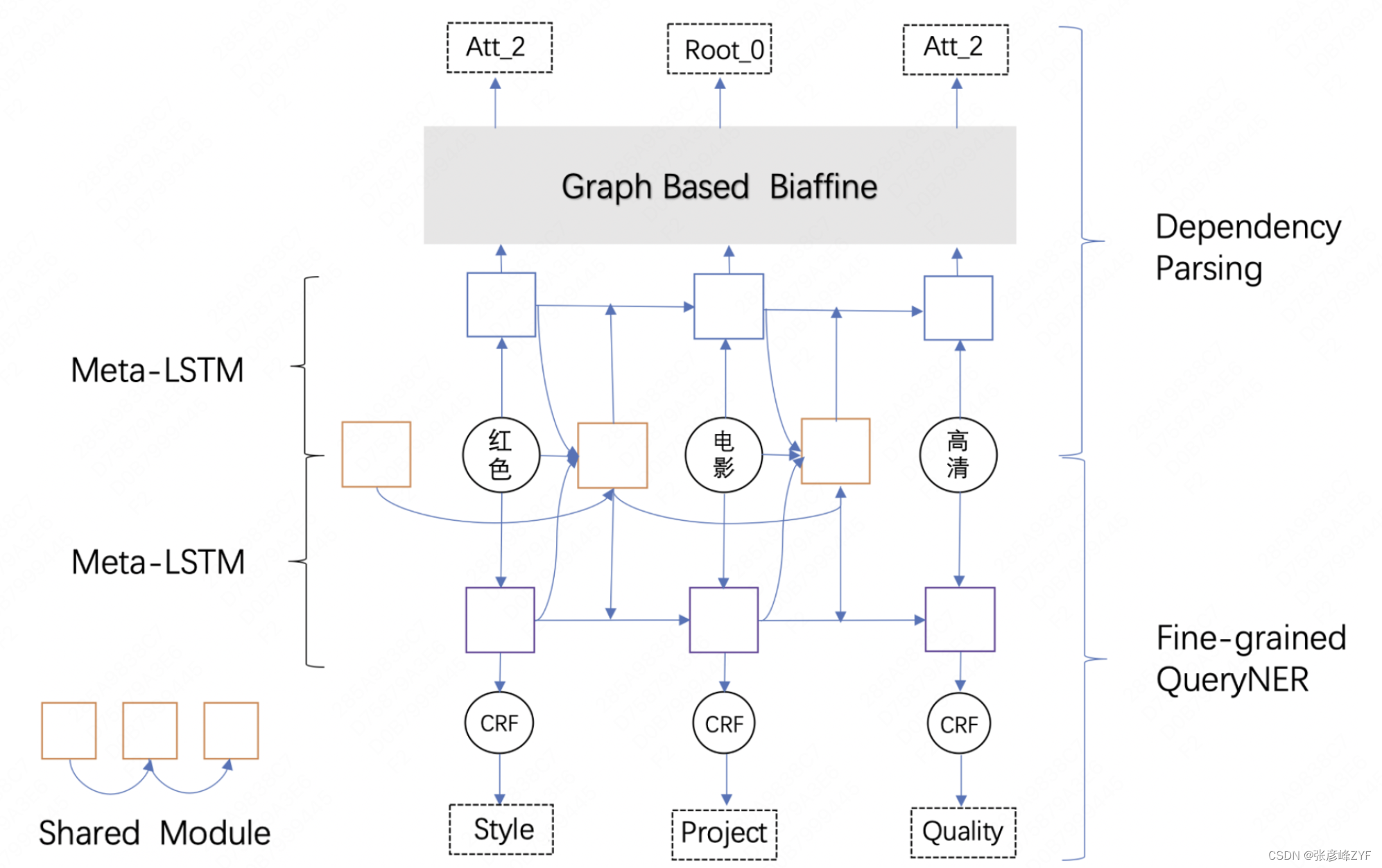
Minería de relaciones de atributos específicos basadas en palabras de atributos abiertos
Minería de palabras de atributos abiertos y valores de atributos
Las relaciones de atributos abiertos requieren extraer atributos únicos y valores de atributos de diferentes conceptos. La dificultad radica en la identificación de atributos abiertos y valores de atributos abiertos. Al observar los datos, encontramos que algunos valores de atributos comunes (por ejemplo: bueno, malo, alto, bajo, más, menos) generalmente aparecen junto con atributos (por ejemplo: buen ambiente, temperatura alta, gran flujo de personas). ). Por lo tanto, adoptamos un método Bootstrapping basado en plantillas para extraer automáticamente atributos y valores de atributos de los comentarios de los usuarios. El proceso de extracción es el siguiente:
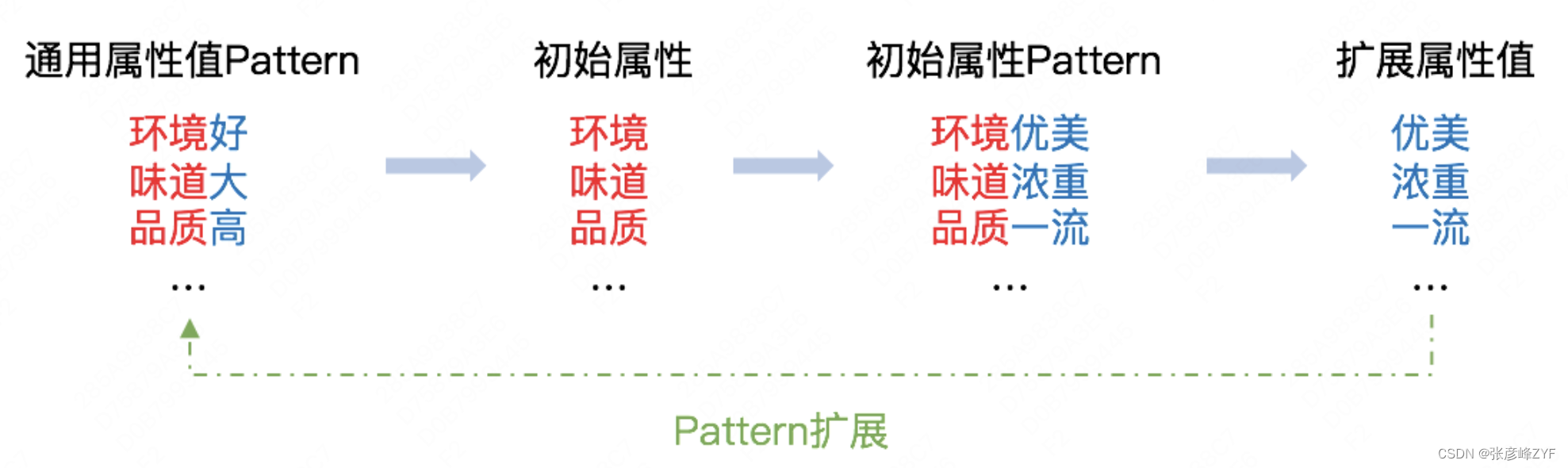
Después de extraer palabras de atributos abiertos y valores de atributos, la extracción de relaciones de atributos abiertos se divide en la extracción de tuplas "concepto-atributo" y la extracción de tripletas "concepto-atributo-valor de atributo".
Minería de atributos de concepto
La extracción de pares "concepto-atributo" tiene como objetivo determinar si el concepto Concepto contiene el atributo Propiedad. Los pasos de minería son los siguientes:
- De acuerdo con las características de coocurrencia de conceptos y atributos en UGC, el algoritmo variante TFIDF se utiliza para extraer atributos típicos correspondientes a los conceptos como candidatos.
- Construya los atributos del concepto candidato en oraciones simples de expresión natural, utilice el modelo de lenguaje de fluidez para determinar la fluidez de la oración y conserve los atributos del concepto con alta fluidez.
Minería de concepto-atributo-valor de atributo
Después de obtener la tupla "concepto-atributo", los pasos para extraer los valores de atributo correspondientes son los siguientes:
- Excavación de semillas . La minería de semillas se triplica a partir de UGC en función de características de coocurrencia y modelos de lenguaje.
- Minería de plantillas . Utilice triples de semillas para crear plantillas adecuadas a partir de UGC (por ejemplo, "Que la temperatura del agua sea adecuada es un criterio importante a la hora de elegir una piscina").
- Generación de relaciones . La plantilla se llena con triples semilla y se entrena un modelo de lenguaje enmascarado para la generación de relaciones.
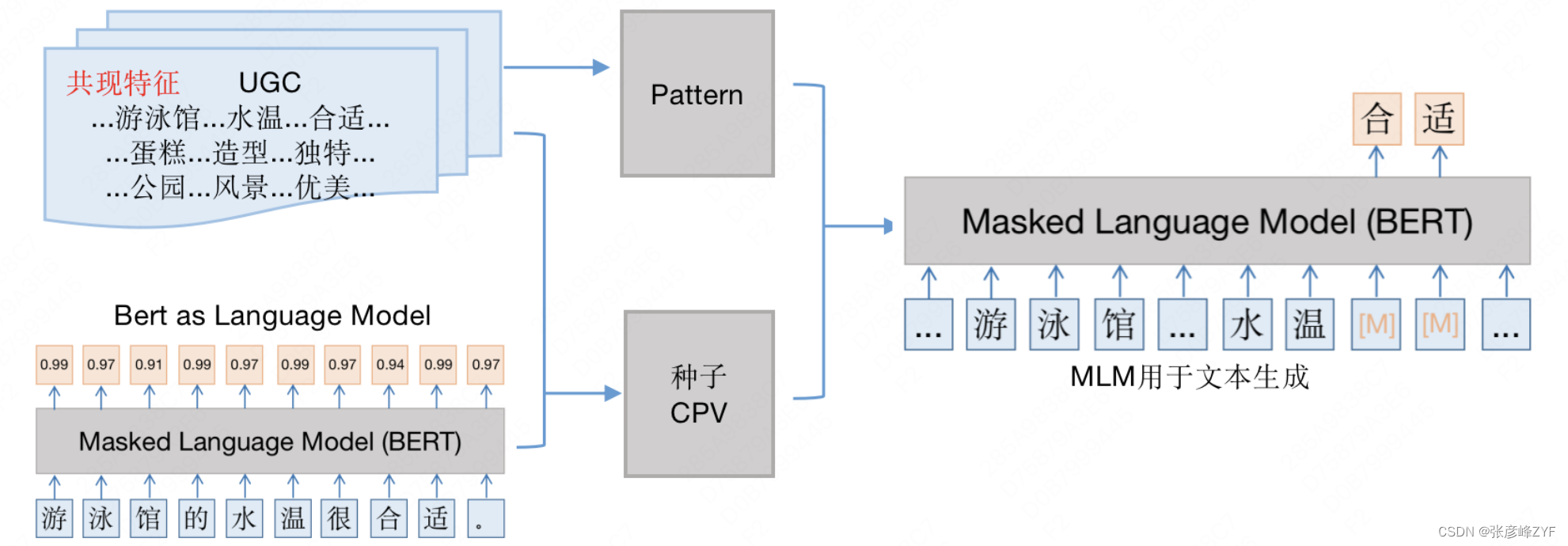
Actualmente, la precisión de las relaciones entre conceptos y atributos en campos abiertos es de alrededor del 80%.
(5) Relaciones de herencia del concepto minero
La relación de herencia de conceptos consiste en establecer la asociación entre el concepto de búsqueda del usuario y el concepto de herencia de Meituan. Por ejemplo, cuando un usuario busca "excursión", la verdadera intención es encontrar "un lugar apto para realizar una excursión", por lo que la plataforma lo realiza a través de conceptos como "parque rural" y "jardín botánico". La minería de relaciones debe realizarse de 0 a 1, por lo que todo el concepto de minería de relaciones se basa en el diseño de diferentes algoritmos de minería según el enfoque de minería en diferentes etapas, que se pueden dividir en tres etapas: ① minería de semillas en la etapa inicial; ② minería de modelos discriminantes profundos en el mediano plazo; ③ Finalización de la relación en el período posterior. Los detalles son los siguientes:
Minería de datos de semillas basados en características de coocurrencia
Para resolver el problema del arranque en frío en las tareas de extracción de relaciones, la industria generalmente utiliza el método Bootstrapping para expandir automáticamente los datos del corpus a través de una pequeña cantidad de semillas y plantillas configuradas manualmente. Sin embargo, el método Bootstrapping no solo está limitado por la calidad de la plantilla, sino que también tiene fallas naturales cuando se aplica a escenarios de Meituan. La fuente principal del corpus de Meituan son las opiniones de los usuarios, y las expresiones de las opiniones de los usuarios son muy coloquiales y diversas, lo que dificulta el diseño de una plantilla universal y eficaz. Por lo tanto, abandonamos el método basado en plantillas y en su lugar construimos una red de aprendizaje de comparación ternaria basada en las características de coocurrencia y características de categoría entre entidades para extraer automáticamente información de correlación potencial entre relaciones entre entidades a partir de texto no estructurado.
Específicamente, observamos grandes diferencias en la distribución de entidades en las reseñas de los usuarios en diferentes categorías de comerciantes. Por ejemplo, el CGU en la categoría de alimentos a menudo implica "cenar juntos", "pedir platos" y "restaurantes"; el CGU en la categoría de fitness a menudo implica "pérdida de peso", "entrenamiento personal" y "gimnasio"; y "decoración". ", "lobby" y otras entidades comunes aparecerán en cada categoría. Por lo tanto, construimos una red de aprendizaje de comparación ternaria para que los comentarios de los usuarios en la misma categoría se representen como cercanos y los comentarios de los usuarios en diferentes categorías se representen como lejanos. De manera similar a los sistemas de vectores de palabras previamente entrenados como Word2Vec, la capa de vectores de palabras obtenida a través de esta estrategia de aprendizaje comparativo contiene naturalmente información rica sobre relaciones. Durante la predicción, para cualquier concepto de búsqueda de usuario, se puede obtener un lote de datos semilla de alta calidad calculando la similitud semántica entre este y todos los conceptos heredados, complementados con las características estadísticas del negocio de búsqueda.
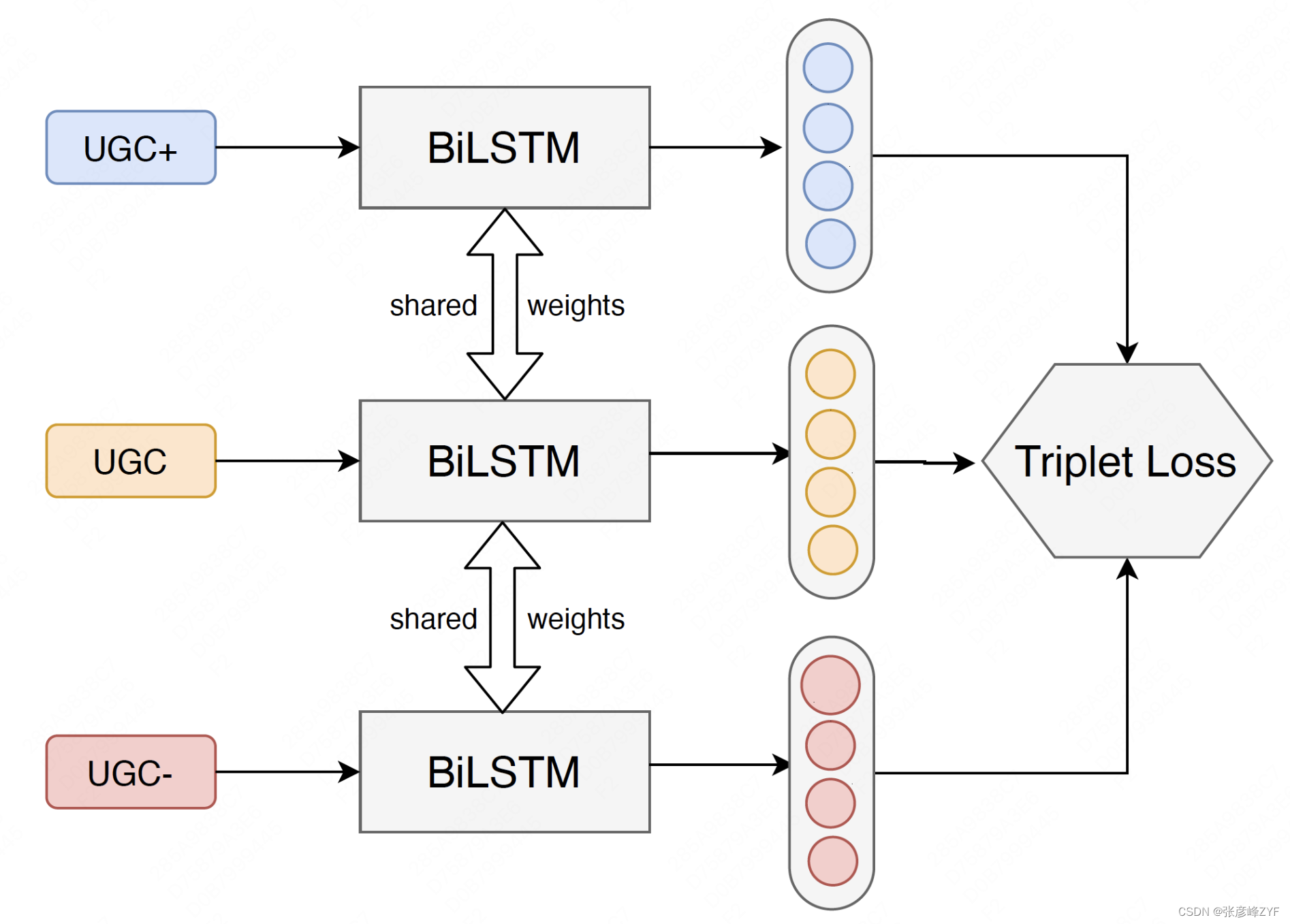
Entrenamiento de modelos profundos basados en datos semilla
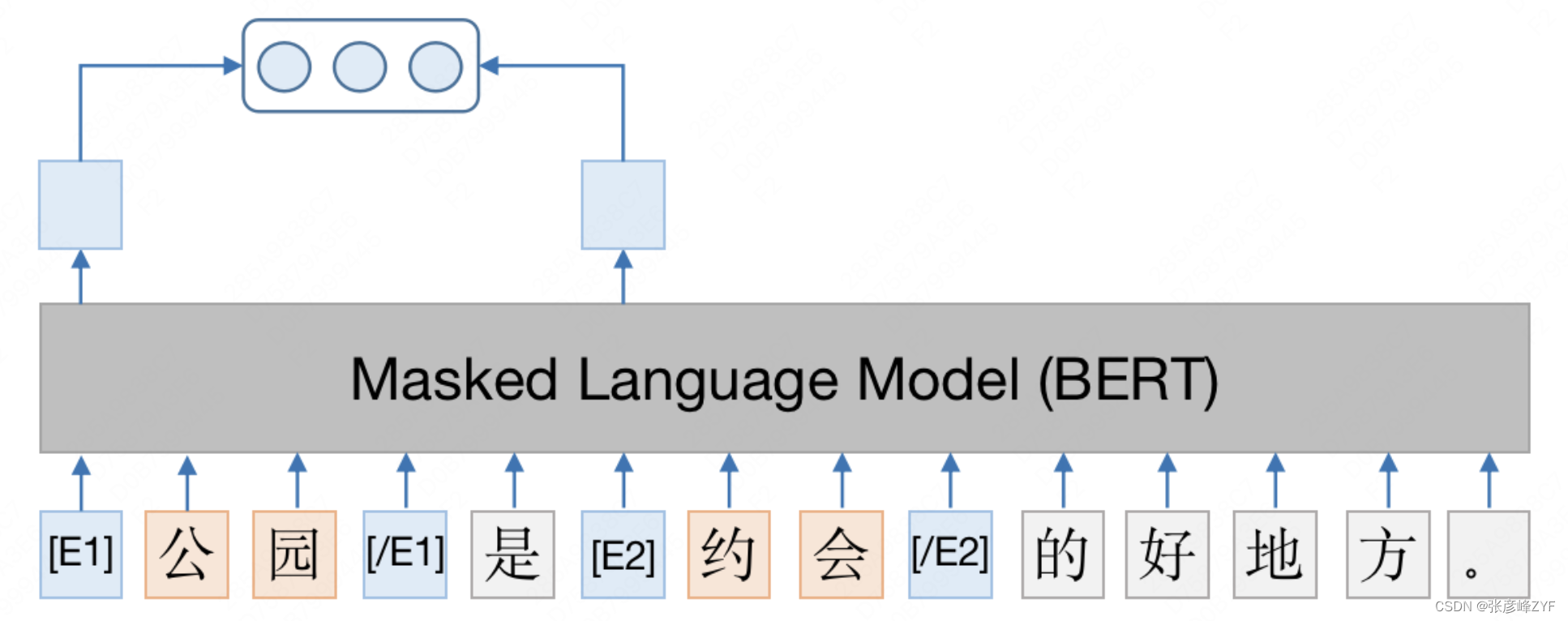
Los modelos de lenguaje previamente entrenados han logrado grandes avances en el campo de la PNL en los últimos dos años. El ajuste fino de las tareas posteriores basadas en modelos preentrenados a gran escala es una práctica muy popular en el campo de la PNL. Por lo tanto, en la etapa intermedia de la minería de relaciones, adoptamos el modelo de discriminación de relaciones basado en BERT (consulte el artículo " Exploración y práctica de Meituan BERT ") y utilizamos la gran cantidad de conocimiento del lenguaje aprendido durante la preparación de BERT. capacitación para ayudar con la tarea de extracción de relaciones.
La estructura del modelo se muestra en la siguiente figura. Primero, los pares de entidades candidatas se obtienen en función de las características de coocurrencia entre entidades, y se recuerdan los comentarios de los usuarios que contienen los pares de entidades candidatas; luego, se utiliza el método de etiquetado de entidades en el documento MTB para insertar símbolos de logotipo especiales al principio y al final. posiciones de las dos entidades. Después del modelado BERT, los símbolos especiales en las posiciones iniciales de las dos entidades se empalman como una representación de relación; finalmente, la representación de la relación se ingresa en la capa Softmax para determinar si existe una relación. entre entidades.
Finalización de la relación basada en la estructura del gráfico existente
A través de las dos etapas anteriores, se ha construido un mapa de relaciones de conexión conceptual que ha comenzado a tomar forma a partir de información textual no estructurada. Sin embargo, debido a las limitaciones del modelo semántico, faltan una gran cantidad de tripletas en el gráfico actual. Para enriquecer aún más el mapa conceptual y completar la información de relación faltante, aplicamos el algoritmo TransE en la predicción de enlaces del mapa de conocimiento y graficamos redes neuronales y otras tecnologías para completar el mapa conceptual existente.
Para aprovechar al máximo la información estructural del gráfico conocido, utilizamos la Relational Graph Attention Network (RGAT, Relational Graph Attention Network) para modelar la información estructural del gráfico. RGAT utiliza el mecanismo de atención relacional para superar las deficiencias de GCN y GAT tradicionales que no pueden modelar tipos de bordes, y es más adecuado para modelar redes heterogéneas como gráficos conceptuales. Después de usar RGAT para obtener incrustaciones densas de entidades, usamos TransE como función de pérdida. TransE considera r en el triplete (h, r, t) como el vector de traducción de h a t, y acepta que h+r≈t. Este método se usa ampliamente en tareas de finalización de gráficos de conocimiento y muestra una gran solidez y escalabilidad.
Los detalles específicos se muestran en la siguiente figura. Las características de cada capa de nodos en RGAT se ponderan por la media de las características de los nodos vecinos y la media de las características de los bordes adyacentes. A través del mecanismo de atención relacional, diferentes nodos y bordes tienen diferentes coeficientes de peso. . . Después de obtener las características de nodo y borde de la última capa, utilizamos TransE como objetivo de entrenamiento para minimizar ||h+r=t|| para cada par de triples (h, r, t) en el conjunto de entrenamiento. Durante la predicción, para cada entidad principal y cada relación, todos los nodos del gráfico se utilizan como entidades de cola candidatas y sus distancias se calculan para obtener la entidad de cola final. En la actualidad, la tasa de precisión general de las relaciones de compromiso conceptual es de aproximadamente el 90%.
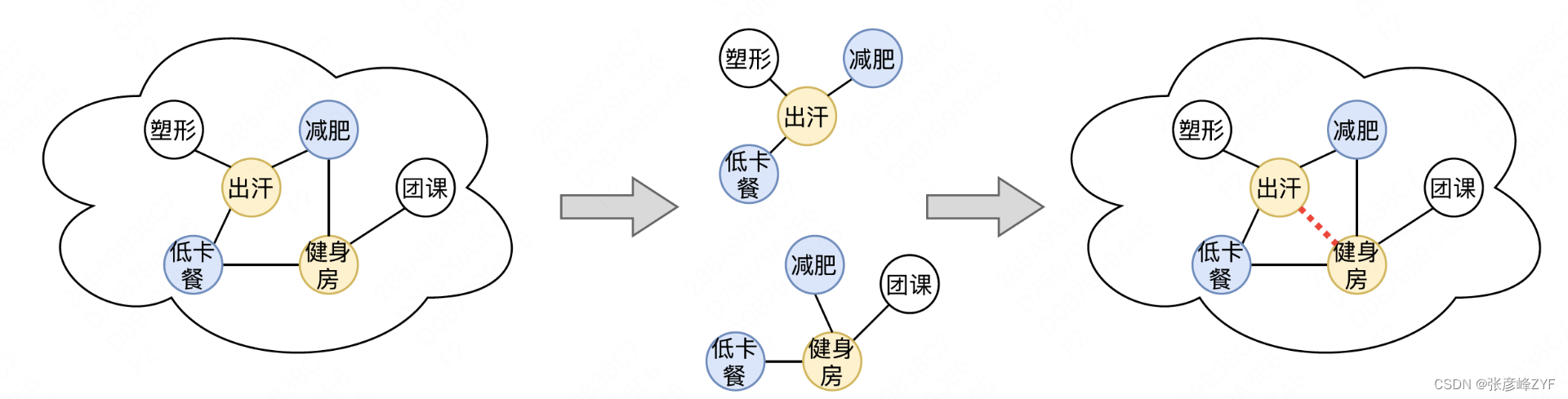
(6) Construcción de la relación POI/SPU-concepto
Para establecer la asociación entre conceptos de mapas y instancias de Meituan, se utilizará información de múltiples dimensiones, como nombres de PDI/SPU, categorías y comentarios de usuarios. La dificultad para establecer correlación es cómo obtener información relacionada con el concepto de mapa a partir de información diversa. Por lo tanto, recordamos todas las cláusulas relacionadas con la semántica del concepto bajo la instancia a través de sinónimos y luego usamos el modelo discriminante para determinar el grado de asociación entre el concepto y las cláusulas. El proceso específico es el siguiente:
- Agrupación de sinónimos . Para marcar el concepto, se obtienen múltiples expresiones del concepto en función de los datos de sinónimos del mapa.
- Generación de cláusula candidata . Según los resultados de la agrupación de sinónimos, las cláusulas candidatas se recuperan de múltiples fuentes, como nombres de comerciantes, nombres de grupos, reseñas de usuarios, etc.
- modelo discriminante . Utilice el modelo de discriminación de asociación concepto-texto (como se muestra en la figura siguiente) para determinar si el concepto y la cláusula coinciden.
- Resultados de marcado. Ajuste el umbral para obtener el resultado final de discriminación.

4. Análisis de aplicaciones
(1) Ejemplos de aplicaciones específicas dentro de Meituan
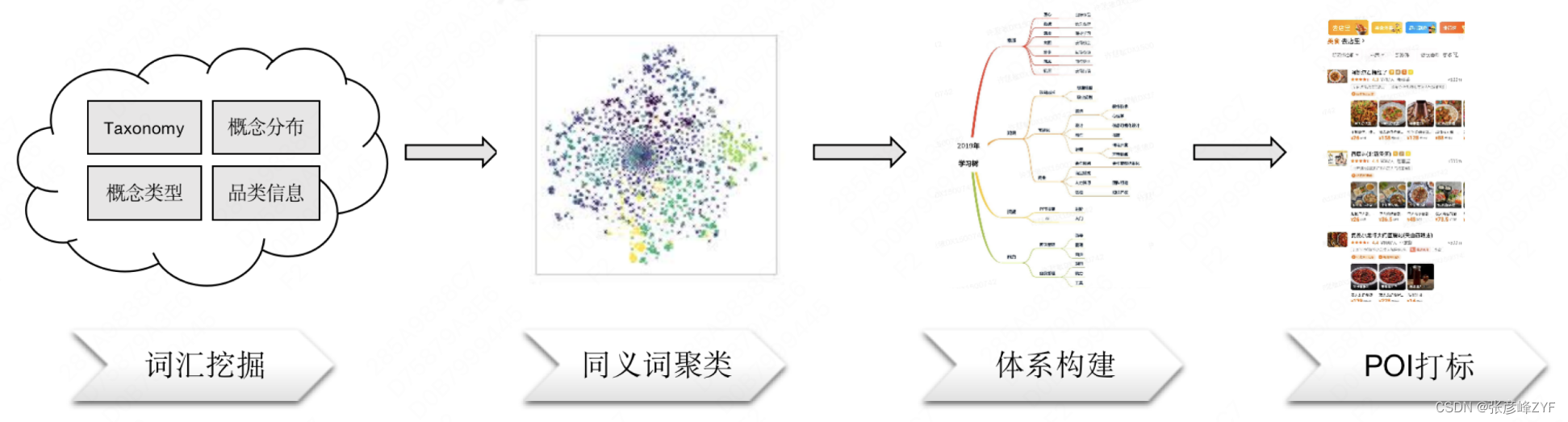
A la construcción de un mapa de palabras de categorías integral.
El negocio integral de Meituan cubre una amplia gama de campos de conocimiento, incluidos padres e hijos, educación, belleza médica, ocio y entretenimiento, etc. Al mismo tiempo, cada campo contiene más subcampos pequeños, por lo que se construyen mapas de conocimiento en el campo para diferentes Los campos pueden ayudar a realizar búsquedas, retiradas, selección, recomendaciones y otros servicios.
Además de los datos conceptuales de sentido común, el mapa conceptual de sentido común también incluye datos de la escena de Meituan y la acumulación de capacidades de algoritmos básicos, por lo que podemos utilizar las capacidades del mapa de sentido común para ayudar a construir datos de mapas para palabras de categorías completas.
Con la ayuda de mapas de sentido común, podemos complementar los datos de palabras de categorías que faltan, crear un mapa de palabras de categorías razonable y ayudar a mejorar la recuperación de la búsqueda mediante la reescritura de la búsqueda, el marcado de puntos de interés, etc. Actualmente en el campo de la educación, la escala del gráfico se ha ampliado de los más de 1000 nodos iniciales a más de 2000, y los sinónimos se han ampliado de mil niveles a más de 20000, logrando buenos resultados.
El proceso de construcción del mapa de palabras de categorías se muestra en la siguiente figura:
Revisar la guía de búsqueda
Las reseñas buscan recomendaciones SUG, que no solo guían la cognición de los usuarios, sino que también ayudan a reducir el tiempo que les lleva completar las búsquedas y mejorar la eficiencia de la búsqueda. Por lo tanto, al recomendar SUG, debemos centrarnos en dos objetivos: ① Ayudar a enriquecer la cognición de los usuarios y aumentar su conocimiento de la búsqueda de texto natural a partir de puntos de interés y búsquedas de categorías para reseñas; ② Refinar las necesidades de búsqueda de los usuarios, cuando los usuarios buscan algo. Al comparar palabras de categorías generales, puede ayudar a refinar las necesidades de búsqueda de los usuarios.
En el mapa conceptual de sentido común se establece un rico conjunto de conceptos y la relación entre los atributos correspondientes y sus valores de atributos. A través de una Consulta relativamente general se puede generar la Consulta detallada correspondiente. Por ejemplo, los pasteles pueden producir pasteles de fresa y pasteles de queso mediante el atributo de sabor, y pueden producir pasteles de 6 pulgadas, pasteles de bolsillo, etc. mediante el atributo de especificaciones.
En la siguiente figura se muestra un ejemplo de salida de consulta de palabras de guía de búsqueda:

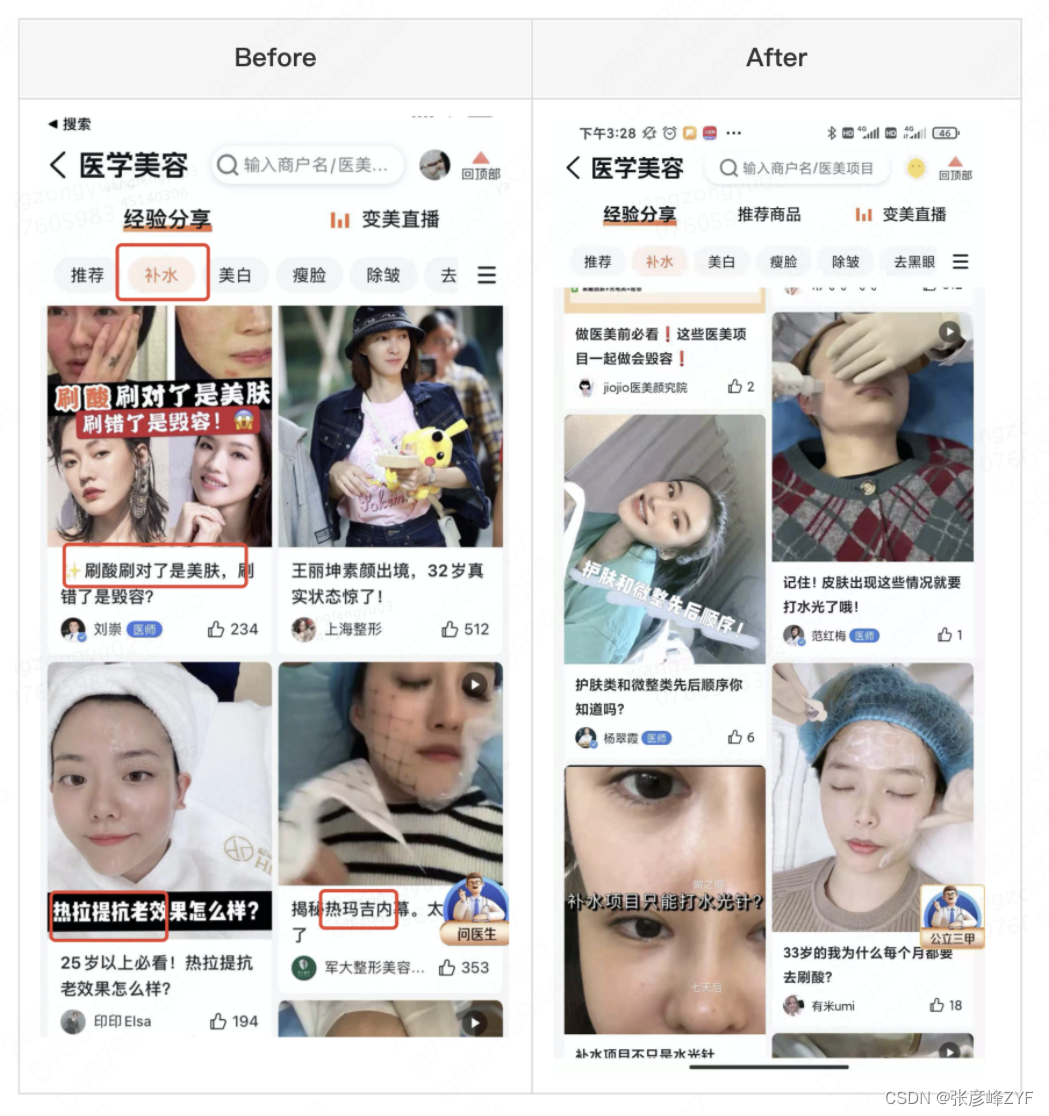
Marcado de contenido completo de belleza médica.
Al mostrar contenido de belleza médica, los usuarios generalmente están interesados en un contenido de servicio de belleza médica específico, por lo que se proporcionarán algunas etiquetas de servicio diferentes en el formulario del producto para ayudar a los usuarios a filtrar contenido de belleza médica preciso y satisfacer con precisión las necesidades del usuario. Sin embargo, al asociar etiquetas con contenido de belleza médica, se producen muchos errores de asociación y los usuarios suelen ver contenido que no satisface sus necesidades después del filtrado. Mejorar la precisión del marcado puede ayudar a los usuarios a centrarse más en sus necesidades.
Con la ayuda de la capacidad de marcado de concepto-POI del mapa y la relación de marcado de concepto-UGC, se puede mejorar la precisión del contenido de la etiqueta. El marcado mediante capacidades de mapas ha mejorado significativamente tanto la precisión como la recuperación.
- Tasa de precisión : a través del algoritmo de marcado de contenido conceptual, en comparación con la concordancia de palabras clave, la tasa de precisión aumenta del 51% al 91%.
- Tasa de recuperación : a través de la minería de sinónimos de conceptos, la tasa de recuperación aumentó del 77% al 91%.
(2) Ejemplos de aplicaciones en la industria
El sector financiero
En el ámbito financiero, los mapas conceptuales de sentido común se pueden aplicar a escenarios como el control de riesgos, el servicio al cliente y el asesoramiento inteligente en inversiones . Por ejemplo, se puede construir un mapa conceptual de sentido común financiero, incluyendo entidades, atributos y relaciones relacionadas con el campo financiero, como bancos, productos financieros, mercados, inversiones, etc. Este mapa conceptual se puede utilizar luego para brindar soporte a los modelos de control de riesgos para la evaluación y gestión de riesgos; a través del modelo de asesoramiento de inversión inteligente, se puede recomendar inteligentemente el plan de inversión más adecuado en función de la preferencia de riesgo y los objetivos de inversión del cliente.
campo médico
En el campo médico, los mapas conceptuales de sentido común se pueden aplicar al diagnóstico de enfermedades, la investigación y el desarrollo de fármacos, las preguntas y respuestas médicas inteligentes y otros escenarios . Por ejemplo, se puede construir un mapa conceptual de sentido común médico, que incluya entidades, atributos y relaciones relacionadas con enfermedades, fármacos, síntomas, métodos de tratamiento, etc. Este mapa conceptual se puede utilizar para el diagnóstico de enfermedades y el desarrollo de medicamentos, ayudando a los médicos a diagnosticar enfermedades con mayor rapidez y precisión. También puede ayudar al equipo de investigación y desarrollo de medicamentos en la investigación y el desarrollo de medicamentos; a través del modelo médico inteligente de preguntas y respuestas, responder a los pacientes. ' preguntas sobre síntomas y métodos de tratamiento y otros temas.
sector minorista
En el campo del comercio minorista, los mapas conceptuales de sentido común se pueden aplicar a recomendaciones de productos, retratos de usuarios, estrategias de marketing y otros escenarios . Por ejemplo, puede crear un mapa conceptual de sentido común del comercio minorista que contenga entidades, atributos y relaciones relacionadas con productos, usuarios, tiendas, marcas, etc. Luego, este mapa conceptual se puede utilizar para proporcionar servicios personalizados de recomendación de productos para ayudar a los usuarios a encontrar sus productos favoritos de forma más rápida y precisa; a través del modelo de retrato del usuario, comprender el comportamiento de compra y las preferencias del usuario y optimizar las estrategias de marketing y las actividades promocionales.
Campo de transporte inteligente
En el campo del transporte inteligente, los mapas conceptuales de sentido común se pueden aplicar a la predicción del flujo de tráfico, la planificación de rutas, la navegación inteligente, etc. Por ejemplo, se puede construir un mapa conceptual de sentido común, que incluya varias entidades de tráfico, carreteras, señales de tráfico, normas de conducción, etc. Este mapa conceptual se puede utilizar para predecir el flujo de tráfico, proporcionar una planificación de rutas más precisa y servicios de navegación inteligentes, y ayudar a los departamentos de gestión del tráfico a formular estrategias de gestión del tráfico más científicas.
Alibaba, Tencent
Utilice mapas conceptuales de sentido común para crear un servicio al cliente inteligente y mejorar la eficiencia y la calidad del servicio al cliente . Los mapas conceptuales de sentido común pueden ayudar a las máquinas a comprender cuestiones como la referencia y la ambigüedad en el lenguaje natural y a responder las preguntas de los usuarios con mayor precisión. También pueden ayudar a las máquinas a aprender a interactuar de forma natural con los humanos.
ByteDanza
ByteDance utiliza mapas conceptuales de sentido común para crear sistemas de búsqueda y recomendación inteligentes . Los mapas conceptuales de sentido común pueden ayudar a las máquinas a comprender el significado y el propósito de los comportamientos de búsqueda y navegación de los usuarios, recomendando así mejor contenidos y productos que coincidan con los intereses y necesidades de los usuarios . Al mismo tiempo, los mapas conceptuales de sentido común también pueden ayudar a las máquinas a manejar mejor cuestiones como la polisemia y los sinónimos, y mejorar la precisión y cobertura de la búsqueda y recomendación .
5. Ejemplo de simulación simple
(1) Visualización de consultas de la base de datos del gráfico de conocimiento de Neo4j
Código de muestra que utiliza el lenguaje Java para conectarse a la base de datos del gráfico de conocimiento de Neo4j y ejecutar declaraciones de consulta Cypher
package org.zyf.javabasic.test;
/**
* @author yanfengzhang
* @description
* @date 2022/1/3 23:18
*/
public class Neo4jExample {
public static void main(String[] args) {
// 连接到Neo4j数据库
String uri = "bolt://localhost:7687";
String user = "neo4j";
String password = "123456";
Driver driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));
Session session = driver.session();
// 定义查询语句,查找“苹果”的描述
String query = "MATCH (c:Concept{name:'苹果'})-[:HasDescription]->(d:Description) RETURN d.content";
// 执行查询语句,返回结果
StatementResult result = session.run(query);
// 输出查询结果
while (result.hasNext()) {
Record record = result.next();
String content = record.get("d.content").asString();
System.out.println(content);
}
// 关闭数据库连接
session.close();
driver.close();
}
}
Este código utiliza el controlador Java proporcionado oficialmente por Neo4j para conectarse a una base de datos de Neo4j, luego ejecuta una declaración de consulta Cypher para encontrar la descripción del concepto "manzana" en el gráfico de conocimiento y finalmente genera los resultados de la consulta.
(2) Sugerencias e ideas de aprendizaje
- Aprenda los métodos de construcción y los modelos de representación del conocimiento de los gráficos de conocimiento de sentido común : comprender los métodos de construcción y los modelos de representación del conocimiento de los gráficos de conocimiento de sentido común puede ayudarlo a comprender la estructura interna y la organización del conocimiento de los gráficos conceptuales de sentido común. Los artículos e informes de investigación relevantes pueden ayudarlo a comprender mejor este conocimiento.
- Explore los escenarios de aplicación de los gráficos de conocimiento de sentido común : los gráficos de conocimiento de sentido común se pueden utilizar en campos como el procesamiento del lenguaje natural, la respuesta inteligente a preguntas, el razonamiento de gráficos de conocimiento y el diálogo inteligente. Puede elegir el escenario de aplicación correspondiente para un estudio e investigación en profundidad según sus intereses y experiencia profesional.
- Tecnologías y herramientas de aplicación de aprendizaje para gráficos de conocimiento de sentido común : Las tecnologías y herramientas de aplicación para gráficos de conocimiento de sentido común incluyen bases de datos de gráficos de conocimiento, lenguajes de consulta de gráficos de conocimiento, herramientas de visualización de gráficos de conocimiento y herramientas de procesamiento de lenguaje natural. Dominar estas tecnologías y herramientas puede ayudarle a desarrollar y practicar aplicaciones de mapas conceptuales de sentido común de manera más eficiente.
- Participe en comunidades y proyectos de código abierto relevantes : muchas comunidades y proyectos de código abierto han comenzado a utilizar gráficos de conocimiento de sentido común para el desarrollo y la práctica de aplicaciones. Al participar en estas comunidades y proyectos, puede obtener más experiencia y conocimiento, y comunicarse y colaborar con compañeros. .
- Practique y aplique el gráfico de conocimiento de sentido común : finalmente, al practicar y aplicar el gráfico de conocimiento de sentido común, podrá comprender mejor el valor de la aplicación y los desafíos técnicos del gráfico de concepto de sentido común y dominar una experiencia de aplicación más práctica. Puede elegir algunos proyectos de gráficos de conocimiento de sentido común de código abierto para practicar o participar en competencias y capacitaciones prácticas relevantes para mejorar sus habilidades prácticas y niveles de aplicación.
Referencias, libros y enlaces.
- Alibaba: enlace "Wang Bin, científico de Big Data de Alibaba: mapeo conceptual de sentido común y comprensión del lenguaje natural": https://www.infoq.cn/article/2xcwnnybpjmml7zqxrlt
- Aplicación práctica del algoritmo MATLAB: [Caso de aplicación] Construcción de un mapa conceptual de sentido común y aplicación en el escenario de Meituan_matlab Caso práctico_Blog de Lin Congmu-Blog CSDN
- Todo el proceso de construcción del gráfico de conocimiento_Proceso de construcción del gráfico de conocimiento_Blog del Dr. Zeng Xiaojian-blog CSDN
- ByteDance: "Los expertos técnicos de ByteDance comparten: sistema inteligente de búsqueda y recomendación basado en gráficos" https://www.infoq.cn/article/Cfn6Y3bgqEPU6-krGMQh
- "Práctica de aplicación de Meituan en gráficos de conocimiento" : Presenta la práctica de aplicación de Meituan en gráficos de conocimiento, incluida la construcción de gráficos de conocimiento, escenarios de aplicación, arquitectura técnica, etc.
- "La práctica del gráfico de conocimiento en Alibaba" : Presenta la práctica de aplicación de Alibaba en el gráfico de conocimiento, incluida la construcción del gráfico de conocimiento, escenarios de aplicación, arquitectura técnica, etc.
- "Práctica de aplicación de Tencent Knowledge Graph" : Presenta la práctica de aplicación de Tencent en el gráfico de conocimiento, incluida la construcción de gráficos de conocimiento, escenarios de aplicación, arquitectura técnica, etc.
- Aplicación del gráfico de conocimiento en la inteligencia empresarial : este artículo presenta la aplicación del gráfico de conocimiento en la inteligencia empresarial y toma la gestión del conocimiento empresarial y el sistema inteligente de preguntas y respuestas como ejemplos para profundizar en el proceso de aplicación, la arquitectura técnica y el método de implementación del gráfico de conocimiento.
- Cómo utilizar gráficos de conocimiento para ayudar a las empresas en la transformación digital : este artículo presenta la aplicación de gráficos de conocimiento en la transformación digital empresarial, incluida la integración de datos empresariales, la gestión del conocimiento, los sistemas inteligentes de preguntas y respuestas, etc., y propone cómo elegir la tecnología de gráficos de conocimiento. proveedores y soluciones técnicas sugerencia.
- Cómo el servicio al cliente inteligente utiliza gráficos de conocimiento para reducir los costos del servicio y mejorar la experiencia del usuario : este artículo presenta la aplicación de gráficos de conocimiento en el campo del servicio al cliente inteligente, incluida la construcción de bases de conocimientos, comprensión semántica, preguntas y respuestas inteligentes, etc., y propone cómo lidiar con escenarios prácticos Métodos para desafiar y optimizar los gráficos de conocimiento.