Si la IA de modelos grandes como ChatGPT es lo más popular, los modelos mundiales son la bandera.
Dos de los tres investigadores de IA más influyentes de la historia, Yann LeCun y Yoshua Bengio, han sido aclamados como el camino más probable hacia la superinteligencia de IA, representando una visión de la IA que no aprendemos sobre nuestro mundo ni por fuerza bruta ni por aprendizaje de memoria ( como ChatGPT), pero formando representaciones abstractas de él, la forma en que piensan los humanos.
En esta narrativa, la Arquitectura de predicción de incrustación conjunta basada en imágenes (I-JEPA) construida por Meta se convierte en el primer éxito tangible en la realización de esta visión.
Requiere diez veces menos recursos y no requiere trucos humanos para ayudar a las máquinas a comprender los conceptos más simples de nuestro mundo, lo que nos permite vislumbrar un futuro en el que la inteligencia artificial aprende como lo hacen los humanos.
Mucho se ha dicho sobre GPT-4 y su potencial para ser el primer precursor de AGI (Inteligencia General Artificial), o el momento en que nace en nuestro mundo vida IA superinteligente y sensible.
Pero, ¿qué tan inteligente es el GPT-4?
"No es tan bueno como un perro ", afirma el científico jefe de Meta, Yann LeCun .
Pero ¿cómo puede considerarse estúpido a un modelo que puede imitar impecablemente a Shakespeare?
por ejemplo, conducción autónoma
Piensa en aprender a conducir un coche.
En promedio, una persona tarda unas 20 horas en aprender a hacerlo correctamente.
Los sistemas de conducción autónoma, por otro lado, requieren miles de horas de formación y miles de millones de puntos de datos, pero son menos capaces de conducir que los humanos.
Entonces, ¿ cómo aprendemos los humanos de una manera que sea más eficiente que nuestros modelos de última generación?
La razón de esto puede ser el modelo mundial, una teoría que recientemente ha ganado popularidad en la comunidad científica.
Un modelo mundial es una representación abstracta del mundo creado por el cerebro humano para ayudar a los humanos a interactuar y esencialmente sobrevivir en su entorno.
Estos modelos mundiales tienen un concepto clave: son capaces de predecir eventos imprevistos para ayudar a impulsar nuestras acciones y minimizar la posibilidad de lesiones o muerte.
En otras palabras, se supone que son lo que llamamos "sentido común ", un sentido que nos ayuda a pensar qué decisiones son mejores en cada paso de nuestras vidas.
Si hay algo que está claro acerca de grandes modelos como ChatGPT es que, a día de hoy, carecen por completo de sentido común.
Los perros te mostrarán por qué.
Perros y GPT
Comparando ChatGPT con lo que Yann hizo con los perros, podemos ver claramente cuán diferentes son los métodos de aprendizaje.
Por ejemplo, un perro sabe que saltar desde el balcón de un tercer piso no es la mejor idea en términos de supervivencia, aunque ese perro nunca o nunca haya experimentado lo que sería saltar desde tal altura.
Sin embargo, para entrenar a un robot con IA, hay que convencerlo para que salte, haciéndole entender que para mantener su integridad debe evitar saltar desde grandes alturas.
Sin embargo, los perros, al igual que los humanos, deben afrontar decisiones en la vida, sin posibilidad de ensayo y sin margen de error.
En este caso, el sentido común entra en juego y te salva el día diciéndote “si saltas no verás el día siguiente” eliminando la incertidumbre.
¿Pero qué significa eso realmente?
En pocas palabras, a diferencia de los modelos más avanzados de hoy en día, no necesitamos aprender todo mediante prueba y error.
De hecho, gran parte de nuestro aprendizaje proviene de la observación parcial del mundo.
En ninguna parte esto es más evidente que en nosotros mismos más jóvenes, los bebés.
insinuando la causa a partir de la observación
El siguiente gráfico muestra el tiempo promedio que les toma a los bebés aprender una variedad de conceptos humanos básicos:

Como explicó Yann en su primer artículo sobre el tema , el gráfico anterior muestra a qué edad los bebés suelen adquirir diversos conceptos sobre cómo funciona el mundo.
Es coherente con la idea de que los conceptos abstractos (como el hecho de que los objetos están sujetos a la gravedad y la inercia) se adquieren además de conceptos no abstractos (como la persistencia de los objetos y la asignación de objetos a categorías amplias).
El concepto clave aquí es que la mayor parte del conocimiento se obtiene principalmente a través de la observación, con poca intervención directa, especialmente en las primeras semanas y meses.
Así, podemos ver claramente lo que le falta a la IA de última generación: la capacidad de aprender eficazmente mediante la observación, permitiéndole echar raíces en nuestro mundo y ayudarla a superar las incertidumbres que lo gobiernan.
En términos sencillos, crear un modelo mundial para una IA es darle sentido común.
Entonces, ¿cómo pretende Meta potenciar más poderosamente la inteligencia artificial?
modelo de mundo artificial
Si le preguntaras al científico jefe de IA de Meta cómo sería la inteligencia autónoma, te mostraría este diagrama:

Fuente: Yann LeCun
No entraré en detalles, pero básicamente lo que debes entender es que el modelo mundial hace dos cosas:
- Estimar la información faltante sobre el estado del mundo no proporcionada por el módulo de percepción (recibió datos sensoriales del mundo como entrada)
- Predecir posibles estados futuros del mundo.
En otras palabras, es un elemento necesario para ayudar a los sistemas de IA (modelos grandes o no) a tomar mejores decisiones que suponen que el mundo tiene resultados inciertos que el modelo debe resolver para sobrevivir.
Su sistema basado en ChatGPT podría ser capaz de escribir como la mayoría de los humanos, pero también es capaz de hacer las suposiciones más tontas jamás hechas simplemente porque no comprenden inherentemente nuestro mundo; simplemente aprendieron a imitar el lenguaje.
Por ejemplo, si tomamos MidJourney como ejemplo, hasta hace poco este modelo de texto a imagen tenía serios problemas con las manos humanas porque casi siempre agregaba o omitía un número aleatorio de dedos en cada mano que dibujaba.
La razón es obvia.
Aunque era capaz de generar dibujos y fotografías impresionantes, naturalmente no entendía lo que estaba dibujando.
Es un paradigma paradójico en el que la IA puede mapear las cosas de la mejor manera, pero no logra comprender en absoluto lo que está dibujando.
¿Es así como entiendes la vida? Por supuesto que no.
Acabas de aprender qué es una mano, has aprendido la representación abstracta de las manos, lo cual nos basta para reconocerlas y saber que suelen tener cinco dedos.
Sin embargo, la máquina necesita analizar cada píxel de la imagen para llegar a una conclusión, y de todos esos miles de píxeles, un cierto número de ellos están agrupados de forma que representan una mano, que normalmente tiene cinco dedos.
Entonces, para evitar una gran cantidad de errores como el problema de los dedos, los modelos reciben tanta información que se convierten en increíbles imitadores.
Pero aquí existe claramente una brecha de conocimiento porque se aprende de memoria.
Pero I-JEPA es el primer modelo que realmente se parece a cómo aprendemos.
Modelo I-JEPA
I-JEPA es el primer intento de lograr que la inteligencia artificial aprenda representaciones complejas y abstractas de nuestro mundo.
Con muy poco entrenamiento (como el que necesitarían los humanos), un modelo de IA debería poder ver a un perro en cualquier situación posible y aún así entender que es un perro.
Para ello, I-JEPA cuenta con la siguiente arquitectura:
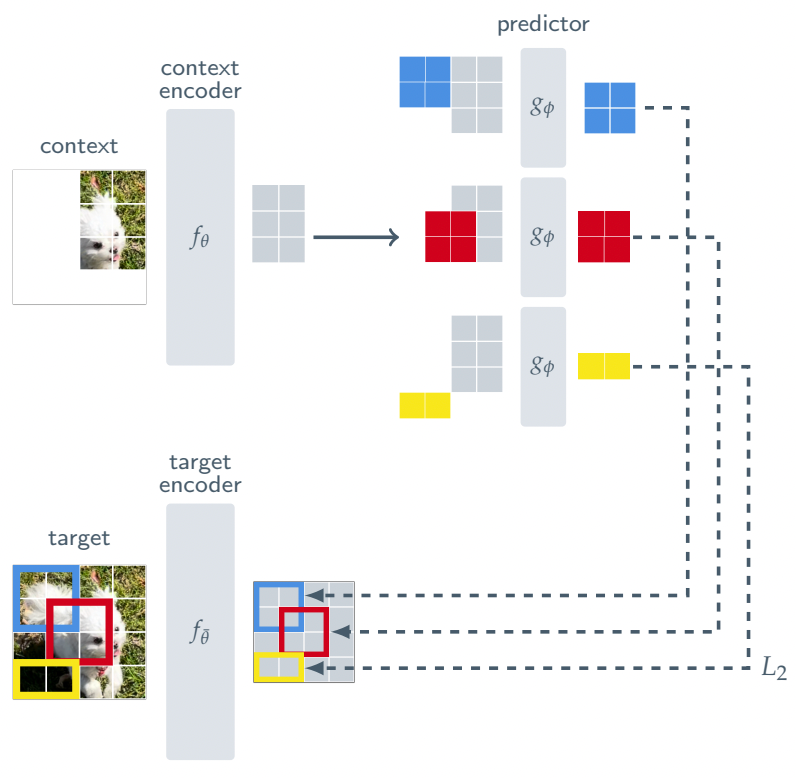
En lugar de intentar reconstruir cada píxel de una imagen como lo hacen los modelos generativos actuales, obligándolos a examinar cada píxel durante el entrenamiento, I-JEPA solo mira una pequeña porción de la imagen y está entrenado para predecir otros bloques en la representación de la imagen Imagen (indicada por el color de arriba).
De esta manera, en lugar de reconstruir imágenes completas una y otra vez para ocultar lagunas cada vez más profundas en la comprensión, se impide que el modelo vea observaciones completas de los objetos que tiene que aprender, lo que lo obliga a comprender realmente la semántica detrás de ellas .
Más importante aún, I-JEPA puede predecir las representaciones faltantes de estos parches. En términos sencillos, esto significa que es necesario evitar detalles innecesarios y centrarse en comprender lo que es realmente importante en la imagen, o fracasará.
Es más, al exponer los modelos a visiones parcialmente observables de la realidad, se pueden entrenar estos modelos para afrontar la incertidumbre.
Por ejemplo, si ves la cara de tu perro acechando afuera de la puerta de tu habitación, no necesitas verlo completo para saber que está allí, porque incluso si solo puedes ver la mitad de su cara, ya lo has desarrollado. resumen que el resto del cuerpo del perro también está ahí.
Si entrena un modelo para detectar perros, pero no incluye miles de imágenes recortadas de perros en su conjunto de datos, fallará terriblemente.
Incluso con ellos, los resultados no son malos en el mejor de los casos, porque para este modelo, eso no es un perro, porque su representación semántica no es lo suficientemente buena, aunque obviamente sí lo es.
la abstracción es inteligencia
La idea de este modelo de mundo seguía creciendo en mi mente.
No hay duda de que entrenar sistemas de IA para que comprendan verdaderamente lo que ven al lidiar con las incertidumbres creadas por las observaciones parciales es un siguiente paso innegable en nuestra búsqueda de una inteligencia artificial general.
También ayuda el hecho de que I-JEPA básicamente supera a casi todos los demás modelos de clasificación de imágenes de la industria con diez veces más requisitos de formación.
Pero la clave aquí no es el resultado, sino la visión que Meta intenta lograr con I-JEPA.
Dado que I-JEPA tiene una comprensión más profunda de lo que ve, no necesita millones de imágenes ni tiempo de entrenamiento para comprender lo que ve... como lo hace un humano.
No creo que los grandes modelos, los modelos que aprenden sobre nuestro mundo leyendo textos que lo describen, sean el camino hacia la superinteligencia.
Pero si logramos integrar el modelo mundial en el modelo más grande...esa es otra historia.
Meta e I-JEPA comenzaron a liderar el camino.