Índice de contenidos de los artículos de la serie.
- Entrevista sobre Java 2024 (1) - Capítulo de primavera
- Entrevista sobre Java 2024 (2) - Capítulo de primavera
- Entrevista sobre Java 2024 (3) - Capítulo de primavera
- Entrevista sobre Java 2024 (4) - Capítulo de primavera
- Entrevista Java 2024 - Colección
- Entrevista de Java 2024: redis (1)
- Entrevista sobre Java 2024: Redis (2)
Directorio de artículos
- Índice de contenidos de los artículos de la serie.
- índice
-
- El significado del índice.
- Crear índice
- Las funciones y desventajas de la indexación.
- Escenarios de uso de índices
- Los principios subyacentes de la indexación
- Árbol B
- B+árbol
- La diferencia entre el árbol B y el árbol B+
- cuatro tipos de árboles
- Ventajas de los árboles B+
- Motor Innodb y Myisam
- Selección del motor de almacenamiento
- La diferencia entre InnoDB y MyISAM
- Transacciones InnoDB
índice
El significado del índice.
Un índice de base de datos es una estructura de datos ordenada en un sistema de gestión de bases de datos para ayudar a consultar y actualizar rápidamente datos en tablas de la base de datos. La implementación de índices generalmente utiliza árboles B y variantes de árboles B+ (los índices comúnmente utilizados en MySQL son árboles B+). Además de los datos, los sistemas de bases de datos también mantienen estructuras de datos que hacen referencia a los datos de alguna manera para satisfacer algoritmos de búsqueda específicos. Esta estructura de datos es un índice. En resumen, un índice es similar al índice de un libro o diccionario.
- Índice de clave principal : una tabla solo puede tener un índice de clave principal y la columna del índice de clave principal no puede tener valores nulos o valores duplicados.
- Índice único : los índices únicos no pueden tener el mismo valor, pero pueden estar vacíos
- Índice ordinario : se permiten valores duplicados
- Índice combinado : cree un índice conjunto en varios campos para reducir la sobrecarga del índice y seguir el principio de coincidencia más a la izquierda
- Índice de texto completo : compatibilidad con el motor Myisam, mejora la eficiencia de recuperación al establecer un índice invertido, ampliamente utilizado en los motores de búsqueda.
Crear índice
CREATE [UNIQUE | FULLTEXT] INDEX 索引名 ON 表名(字段名) [USING 索引方法];
说明:
UNIQUE:可选。表示索引为唯一性索引。
FULLTEXT:可选。表示索引为全文索引。
INDEX和KEY:用于指定字段为索引,两者选择其中之一就可以了,作用是一样的。
索引名:可选。给创建的索引取一个新名称。
字段名1:指定索引对应的字段的名称,该字段必须是前面定义好的字段。
注:索引方法默认使用B+TREE。
Las funciones y desventajas de la indexación.
efecto
Al crear índices, puede mejorar el rendimiento del sistema durante el proceso de consulta.
Al crear un índice único, puede mantener la unicidad de cada fila de datos en la tabla de la base de datos.
Al utilizar cláusulas de agrupación y clasificación para la recuperación de datos, puede reducir el tiempo dedicado a agrupar y ordenar las consultas.
defecto
Crear y mantener índices lleva tiempo, y el tiempo aumenta a medida que aumenta la cantidad de datos.
Los índices deben ocupar espacio físico, si desea crear un índice agrupado, el espacio requerido será mayor.
Se necesita mucho tiempo para agregar, eliminar y modificar datos en la tabla porque el índice también debe mantenerse dinámicamente.
Escenarios de uso de índices
Escenarios donde se deben crear índices
1. En columnas en las que es necesario buscar con frecuencia
2. En la columna como clave principal.
3. A menudo se utiliza en columnas conectadas. Estas columnas son principalmente claves externas, que pueden acelerar la conexión.
4. Columnas en las que a menudo es necesario buscar según el rango
5. Columnas que a menudo requieren condiciones de consulta (dónde), clasificación (ordenar por) y agrupación (agrupar por)
6. Si es un tipo de cadena y la longitud de la cadena es relativamente larga, puede establecer un índice de prefijo según las características del campo.
Los principios subyacentes de la indexación
Dejando de lado otras implementaciones de índices de bases de datos, me centraré en la implementación subyacente de los índices MySQL, que es el almacenamiento de estructuras de datos implementado a través de árboles B+. El almacenamiento de la estructura de datos determina la eficiencia de la búsqueda y operación de datos, incluida la complejidad del tiempo y la complejidad del espacio. Al hacer una compensación, no es más que una compensación entre tiempo por espacio y espacio por tiempo. Por lo tanto, esto es muy bueno. Explica por qué MySQL utiliza árboles B+ en el diseño subyacente del índice en lugar de árboles B, árboles rojo-negro, árboles AVL y otras estructuras de datos. En resumen, utilizar el árbol B+ como almacenamiento de la estructura de índice puede obtener una mayor ventaja en el rendimiento de E/S.
Árbol B
El árbol B es un árbol de búsqueda autoequilibrado de múltiples rutas, similar a un árbol binario equilibrado ordinario, con la diferencia de que el árbol B permite que cada nodo tenga más nodos secundarios. En comparación con AVLTree, B-Tree reduce la cantidad de nodos, de modo que los datos se obtienen de la memoria cada vez que se utiliza la E/S del disco, mejorando así la eficiencia de las consultas. Nota: B-Tree es lo que a menudo llamamos árbol B. Entonces, B-Tree de orden m es una estructura de datos que cumple las siguientes condiciones: Todos los valores clave se distribuyen en todo el árbol. La búsqueda puede finalizar en no- nodos hoja, y se realiza dentro del conjunto completo de palabras clave. Una búsqueda, el rendimiento es cercano a la búsqueda binaria. Cada nodo tiene como máximo m subárboles. El nodo raíz tiene al menos 2 subárboles. El nodo rama tiene al menos m/2 subárboles (excepto el nodo raíz y los nodos hoja, todos son nodos de rama). Todos los nodos hoja están en la misma capa, cada nodo puede tener hasta m-1 claves y están organizados en orden ascendente. Pero B-Tree también tiene problemas: cada nodo tiene claves y datos, y el espacio de almacenamiento de cada página es limitado. Si los datos Cuando los datos son grandes, la cantidad de claves que cada nodo (es decir, una página) puede almacenar será muy pequeño. Cuando la cantidad de datos almacenados es grande, la profundidad del árbol B también será mayor, lo que aumentará la cantidad de E/S del disco durante la consulta y, por lo tanto, afectará la eficiencia de la consulta.
B+árbol
B + Tree es una optimización basada en B-Tree. El motor de almacenamiento InnoDB utiliza B + Tree para implementar su estructura de índice. Los cambios que trae: cada nodo del árbol B+ puede contener más nodos, hay dos razones para esto: una es reducir la altura del árbol. La otra es cambiar el rango de datos en múltiples intervalos. Cuantos más intervalos, más rápida será la recuperación de datos. Los nodos que no son hojas almacenan claves, y las claves de almacenamiento de los nodos hoja y los punteros de datos de los nodos hoja están vinculados entre sí (de acuerdo con la lectura). -características adelantadas del disco), y consulta secuencial mayor rendimiento
El árbol B + tiene bajos costos de lectura y escritura en disco, menos consultas y una eficiencia de consulta más estable, lo que favorece el escaneo de la base de datos.
El árbol B+ es una versión mejorada del árbol B. El árbol B+ solo tiene nodos hoja para almacenar datos y los nodos restantes se utilizan para la indexación. Todos los nodos de índice se pueden agregar a la memoria para aumentar la eficiencia de la consulta, y los nodos hoja se pueden convertir en listas doblemente vinculadas, mejorando así la eficiencia de la búsqueda de rango y aumentando el alcance del índice.
Al almacenar datos a gran escala, los árboles rojo-negro a menudo hacen que las lecturas y escrituras de E/S del disco sean demasiado frecuentes debido a que la profundidad del árbol es demasiado grande , lo que a su vez conduce a una baja eficiencia. Por lo tanto, siempre que reduzcamos la estructura del árbol y reduzcamos la altura del árbol tanto como sea posible mediante una mejor estructura de árbol, el árbol B y el árbol B+ pueden tener varios hijos, desde docenas hasta miles, lo que puede reducir la altura del árbol. .
Nota: El motor de almacenamiento InnoDB de MySQL está diseñado con el nodo raíz residente en la memoria, por lo que se esfuerza por lograr una profundidad de árbol de no más de 3, lo que significa que no es necesario realizar E/S más de 3 veces. Por lo general, hay dos punteros principales en el árbol B +, uno apunta al nodo raíz y el otro apunta al nodo hoja con la clave más pequeña, y hay una estructura de anillo de cadena entre todos los nodos hoja (es decir, nodos de datos), por lo que B + puede be Tree realiza dos operaciones de búsqueda: una es una búsqueda paginada para la búsqueda de rango de la clave principal y la otra es una búsqueda aleatoria que comienza desde el nodo raíz.
La diferencia entre el árbol B y el árbol B+
Los nodos en el árbol B + no almacenan datos, todos los datos se almacenan en nodos hoja, lo que da como resultado una complejidad de tiempo de consulta fija de log n.
La complejidad temporal de la consulta del árbol B no es fija y depende de la posición de la clave en el árbol. Es mejor ser O (1)
Los nodos hoja B+ conectados en pares pueden aumentar en gran medida la accesibilidad del intervalo y pueden usarse en consultas de rango, etc.
Los árboles B+ son más adecuados para almacenamiento externo (almacenamiento de datos en disco). Dado que no hay ningún campo de datos en los nodos internos, el rango que cada nodo puede indexar es mayor y más preciso.
cuatro tipos de árboles
Árbol binario: los campos del índice están ordenados y, en casos extremos, se convertirá en una lista vinculada.
Número AVL: la altura del árbol es incontrolable
Número B: controla la altura del árbol, pero el valor del índice y los datos se distribuyen en cada nodo específico. Si desea realizar una consulta de rango, debe realizar múltiples retrocesos, lo que requiere una alta sobrecarga de IO.
Árbol B+: los nodos que no son hoja solo almacenan valores de índice, y los nodos hoja almacenan índice + datos específicos. Están conectados de pequeño a grande mediante listas vinculadas. Las consultas de rango se pueden recorrer directamente sin retroceder7
Ventajas de los árboles B+
(1) El costo de IO es menor. Dado que el árbol B + no almacena datos en nodos que no son hoja, puede almacenar más valores de índice (la capacidad de un solo nodo grande es fija y el tamaño de cada unidad pequeña se vuelve más pequeño), lo que da como resultado una altura más baja de el árbol y menos veces de E/S del disco.
(2) La eficiencia de las consultas es estable. Dado que todos los datos del árbol B + se colocan en nodos hoja, cada consulta debe tomar la ruta completa desde el nodo raíz hasta el nodo hoja. La longitud de la ruta de todas las consultas es la misma y la eficiencia de la consulta es más estable.
(3) Más propicio para consultas de rango. Hay punteros entre los nodos de hoja del árbol B +. Tenga en cuenta que son punteros bidireccionales, que son más propicios para consultas de rango.
Motor Innodb y Myisam
Myisam: admite bloqueos de tabla, adecuado para escenarios de lectura intensiva, no admite claves externas, no admite transacciones, los índices y los datos están en archivos diferentes
Innodb: admite bloqueos de filas y tablas, el valor predeterminado es bloqueo de filas, adecuado para escenarios concurrentes, admite claves externas, admite transacciones, el índice y los datos están en el mismo archivo
- InnoDB utiliza índices agrupados
- Myisam utiliza índices no agrupados
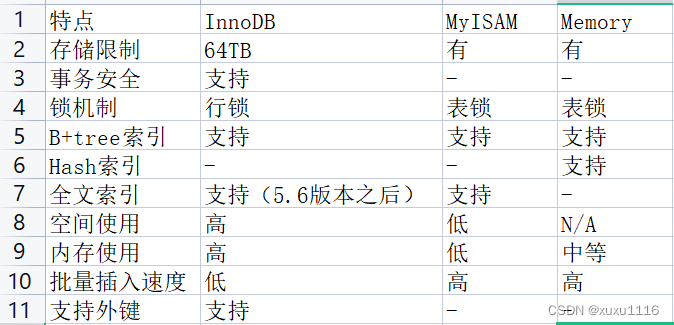
Selección del motor de almacenamiento
Al seleccionar un motor de almacenamiento, debe elegir un motor de almacenamiento apropiado según las características del sistema de aplicación. Para sistemas de aplicaciones complejos, se pueden seleccionar y combinar múltiples motores de almacenamiento de acuerdo con las condiciones reales.
- InnoDB: es el motor de almacenamiento predeterminado de Mysql, que admite transacciones y claves externas. Si la aplicación tiene requisitos relativamente altos para la integridad de las transacciones y requiere coherencia de los datos en condiciones concurrentes, y las operaciones de datos incluyen muchas operaciones de actualización y eliminación además de la inserción y consulta, entonces el motor de almacenamiento InnoDB es una opción más adecuada.
- MyISAM: si la aplicación se basa principalmente en operaciones de lectura e inserción, con solo unas pocas operaciones de actualización y eliminación, y los requisitos de integridad y concurrencia de las transacciones no son muy altos, entonces elegir este motor de almacenamiento es muy adecuado. (Datos relacionados con registros, huellas de comercio electrónico, datos relacionados con comentarios)
- MEMORIA: Guarda todos los datos en la memoria con una velocidad de acceso rápida. Generalmente se usa para tablas temporales y cachés. La desventaja de MEMORIA es que existe un límite en el tamaño de la tabla: las tablas que son demasiado grandes no se pueden almacenar en caché en la memoria y no se puede garantizar la seguridad de los datos. (usualmente usado para almacenamiento en caché)
La diferencia entre InnoDB y MyISAM
-
InnoDB admite transacciones, pero MyISAM no. Para InnoDB, cada declaración SQL se encapsula en una transacción de forma predeterminada y se envía automáticamente. Esto afectará la velocidad, por lo que es mejor colocar varias declaraciones SQL entre el inicio y el compromiso para formar una transacción;
-
InnoDB admite claves externas, pero MyISAM no. La conversión de una tabla InnoDB que contiene claves foráneas a MYISAM fallará;
-
InnoDB es un índice agrupado que utiliza B+Tree como estructura de índice. El archivo de datos está vinculado al índice (clave principal) (el archivo de datos de la tabla en sí es una estructura de índice organizada por B+Tree). Debe haber una clave principal. y se utiliza el índice de clave primaria de alta eficiencia. Sin embargo, el índice auxiliar requiere dos consultas, primero para consultar la clave principal y luego para consultar los datos a través de la clave principal. Por lo tanto, la clave principal no debe ser demasiado grande, porque si la clave principal es demasiado grande, otros índices también lo serán. MyISAM es un índice no agrupado y también utiliza B + Tree como estructura de índice. Los archivos de índice y de datos están separados y el índice guarda el puntero del archivo de datos. Los índices de clave primaria y los índices secundarios son independientes.
Es decir: los nodos hoja del índice de clave primaria del árbol B+ de InnoDB son los archivos de datos, y los nodos hoja del índice auxiliar son los valores de la clave primaria; mientras que los nodos hoja del índice de clave primaria del árbol B+ de MyISAM y El índice auxiliar son los punteros de dirección de los archivos de datos. -
InnoDB no guarda el número específico de filas en la tabla. Al ejecutar select count(*) from table, se requiere un escaneo completo de la tabla. MyISAM usa una variable para guardar el número de filas en toda la tabla. Al ejecutar la declaración anterior, solo necesita leer la variable, lo cual es muy rápido (tenga en cuenta que no se pueden agregar condiciones WHERE);
-
Innodb no admite la indexación de texto completo, pero MyISAM admite la indexación de texto completo. MyISAM es cada vez más rápido en la eficiencia de las consultas que involucran la indexación de texto completo; PD: InnoDB después de 5.7 admite la indexación de texto completo.
-
Las tablas MyISAM se pueden comprimir para operaciones de consulta.
-
InnoDB admite bloqueos a nivel de tabla y fila (predeterminado), mientras que MyISAM admite bloqueos a nivel de tabla. Los
bloqueos de fila de InnoDB se implementan en índices, en lugar de bloquear registros de filas físicos. El subtexto es que si el acceso no llega al índice y no se puede usar el bloqueo de fila, degenerará en un bloqueo de tabla. -
La tabla InnoDB debe tener un índice único (como una clave principal) (si el usuario no lo especifica, encontrará/producirá una columna oculta Row_id para que sirva como clave principal predeterminada), mientras que Myisam no la necesita.
-
Los archivos de almacenamiento de Innodb incluyen frm e ibd, mientras que Myisam almacena frm, MYD y MYI.
Transacciones InnoDB
Consistencia, persistencia: (rehacer registro)
El registro de rehacer registra la modificación física de la página de datos cuando se confirma la transacción y se utiliza para lograr la durabilidad de la transacción.
El archivo de registro consta de dos partes: búfer de registro de rehacer (búfer de registro de rehacer) y archivo de registro de rehacer ((archivo de registro de rehacer). El primero está en la memoria y el segundo en el disco. Cuando se confirma la transacción, toda la información de modificación será Todo se almacena en este archivo de registro, que se utiliza para la recuperación de datos cuando se descargan páginas sucias en el disco y se produce un error.
Atomicidad: (deshacer registro)
El registro de reversión se utiliza para registrar información antes de modificar los datos y tiene dos funciones: proporcionar reversión y MVCC (control de concurrencia de múltiples versiones).
Deshacer registro y rehacer registro registran los registros físicos de manera diferente: son registros lógicos. Se puede pensar que cuando se elimina un registro, se registrará un registro de inserción correspondiente en el registro de deshacer, y viceversa, cuando se actualiza un registro, se registrará un registro de actualización correspondiente en el registro de deshacer. Cuando se ejecuta la reversión, el contenido correspondiente se puede leer del registro lógico en el registro de deshacer y revertir.
Destrucción del registro de deshacer: el registro de deshacer se genera cuando se ejecuta la transacción. Cuando se confirma la transacción, el registro de deshacer no se eliminará inmediatamente porque estos registros también se pueden usar para MVCC.
Almacenamiento del registro de deshacer: el registro de deshacer se administra y registra en segmentos y se almacena en el segmento de reversión presentado anteriormente, que contiene 1024 segmentos de registro de deshacer internamente.