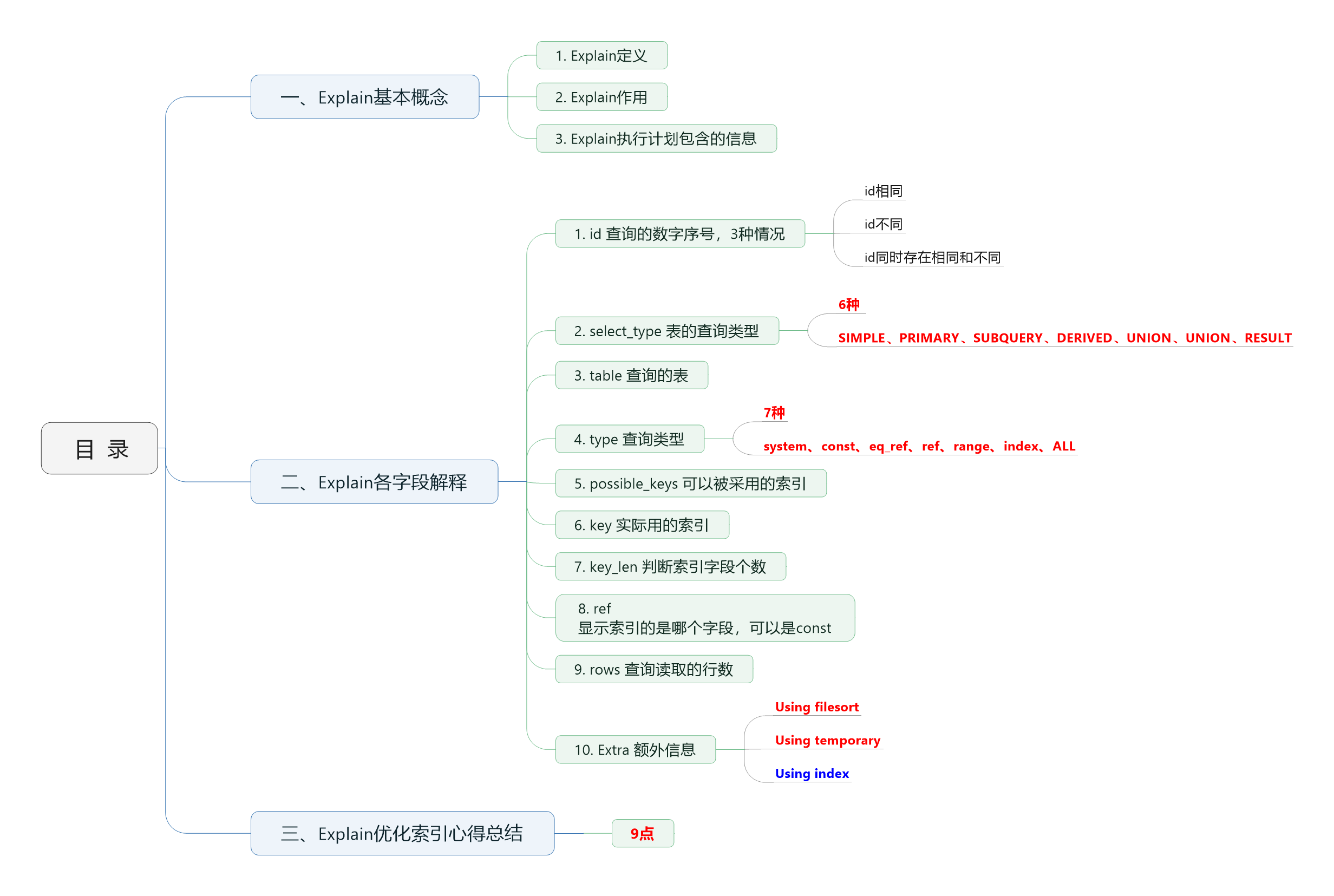
Tabla de contenido
3. Explica el significado y función de cada campo.
3. Secuencia de ejecución de SQL
4. Hablar en lenguaje humano----Explicar el significado de cada análisis de caso de campo.
1. ¿Qué hace EXPLAIN?
El uso de la palabra clave EXPLAIN puede simular la ejecución de declaraciones de consulta SQL por parte del optimizador, sabiendo así cómo MySQL procesa sus declaraciones SQL. Analice los cuellos de botella de rendimiento de sus declaraciones de consulta o estructuras de tablas.
2. El papel de Explicar
Por supuesto, nos guía para escribir mejores declaraciones SQL y mejorar la velocidad de las consultas. De hecho, para decirlo sin rodeos, escribamos una consulta SQL que utilice índices tanto como sea posible y que la cantidad total de datos consultados sea lo más pequeña posible, mejorando así la velocidad de la consulta.
Al agregar explicar antes de la instrucción select+sql, podemos ver:
(1) El orden de lectura de la tabla, id (la tabla es la tabla correspondiente al id)
(2) El tipo de operación de la operación de lectura de datos, tipo de selección
( 3) Qué índices se pueden usar, posibles_claves
(4) Qué índices se usan realmente, clave
(5) Referencias entre tablas, referencia
(6) Cuántas filas en cada tabla consulta el optimizador, filas
3. Explica el significado y función de cada campo.
| número de serie | Nombre del campo | Descripción de la función de campo |
|---|---|---|
| 1 | identificación | El número de secuencia de la consulta, incluido un grupo de números, indica el orden en que se ejecuta la cláusula de selección o la tabla de operaciones en la consulta ** Ambos casos** La identificación es la misma, pero el orden de ejecución es diferente de arriba a inferior . Cuanto mayor sea el valor de id, mayor será la prioridad. Ejecute primero |
| 2 | seleccione tipo | Tipo de consulta, utilizado principalmente para distinguir entre consultas ordinarias, consultas conjuntas, subconsultas, etc. consultas complejas 1. simple : consulta de selección simple, la consulta no contiene subconsultas ni UNION 2. primaria : si la consulta contiene alguna parte de subconsulta compleja, la la consulta más externa está marcada 3. subconsulta : la subconsulta contenida en la lista de selección o dónde 4. derivada : la subconsulta contenida en la lista de está marcada como derivada (derivada), MySQL ejecutará recursivamente estas subconsultas Consulta y colocará los resultados en una consulta temporal tabla 5. Unión : si la segunda selección aparece después de UNION, se marca como UNION. Si union se incluye en la subconsulta de la cláusula from, la selección externa se marca como derivada 6, resultado de la unión: el resultado de UNION |
| 3 | mesa | La tabla a la que hace referencia la fila de salida. |
| 4 | tipo | Muestra el tipo de conexión, muestra qué tipo se utiliza en la consulta, ordena de mejor a peor tipo sistema > const > eq_ref > ref > rango > índice > todo
|
| 5 | llaves_posibles | Indica qué índice MySQL puede usar para encontrar la tabla ( posiblemente índices usados ) |
| 6 | llave | Muestra las claves (índices) que MySQL realmente decidió utilizar . Si no se selecciona ningún índice, la clave es NULL. Si se utiliza un índice de cobertura en una consulta, el índice se superpone con el campo de selección de la consulta. |
| 7 | clave_len | Representa el número de bytes utilizados en el índice. Esta columna calcula la longitud del índice utilizado en la consulta . Cuanto más corta sea la longitud , mejor sin perder precisión . Si la clave es NULL, la longitud es NULL. Este campo se muestra como la longitud máxima posible del campo de índice, no como la longitud real utilizada. |
| 8 | árbitro | Muestra qué columna del índice se utiliza , si es posible una constante, qué columnas o constantes se utilizan para consultar el valor en la columna del índice |
| 9 | filas | Según las estadísticas de la tabla y la selección del índice, estime aproximadamente el número de filas que deben leerse para encontrar los registros necesarios. |
| 10 | Extra | Contiene información adicional que no es adecuada para mostrar en otras columnas, pero que es muy importante. 1. Uso de clasificación de archivos : indica que MySQL aplicará una clasificación de índice externo a los datos. En lugar de leer en orden de índice dentro de la tabla. La imposibilidad de utilizar índices para completar la operación de clasificación en MySQL se denomina "clasificación de archivos" 2. Uso temporal : se utiliza una tabla temporal para guardar resultados intermedios MySQL utiliza tablas temporales al ordenar los resultados de la consulta. Comúnmente utilizado para ordenar por y agrupar consultas por. 3. Usando índice : Indica que la operación de selección correspondiente usa un índice de cobertura para evitar el acceso a las filas de datos de la tabla. Si usa Where aparece al mismo tiempo, el índice del nombre de la tabla se usa para realizar la búsqueda del valor de la clave del índice; si usa Where no aparece al mismo tiempo, el índice del nombre de la tabla se usa para leer datos en lugar de realizar acciones de consulta. 4. Usando dónde : indica el uso del filtrado dónde 5. Usando el búfer de unión : usa el caché de conexión 6. Imposible dónde : el valor de la cláusula dónde siempre es falso y no se puede usar para obtener ninguna tupla 7. Seleccione tablas optimizadas : Cuando no hay grupo En el caso de la cláusula by, optimizar las operaciones Min y max en función del índice u optimizar el recuento (*) para el motor de almacenamiento MyISAM no tiene que esperar hasta la etapa de ejecución para el cálculo. completado durante la etapa de generación del plan de ejecución de la consulta. 8. distinto: Optimice la operación distinta y deje de buscar el mismo valor después de encontrar la primera tupla coincidente. |
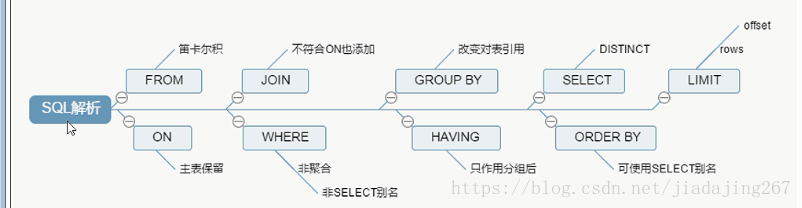
3. Secuencia de ejecución de SQL
Si desea optimizar SQL, debe conocer claramente el orden de ejecución de SQL. De esta manera, puede obtener el doble de resultado con la mitad de esfuerzo usando explicar.
3.1 Declaración SQL completa
select distinct
<select_list>
from
<left_table><join_type>
join <right_table> on <join_condition>
where
<where_condition>
group by
<group_by_list>
having
<having_condition>
order by
<order_by_condition>
limit <limit number>
3.2 Secuencia de ejecución de SQL
1、from <left_table><join_type>
2、on <join_condition>
3、<join_type> join <right_table>
4、where <where_condition>
5、group by <group_by_list>
6、having <having_condition>
7、select
8、distinct <select_list>
9、order by <order_by_condition>
10、limit <limit_number>
4. Hablar en lenguaje humano----Explicar el significado de cada análisis de caso de campo.
4.1, identificación
El número de secuencia digital de la consulta de selección indica el orden en que se operan las tablas al ejecutar la cláusula de selección o la consulta conjunta de varias tablas en la consulta ;
· (1) Los ID son los mismos y el orden de ejecución es desde arriba Hacia abajo.
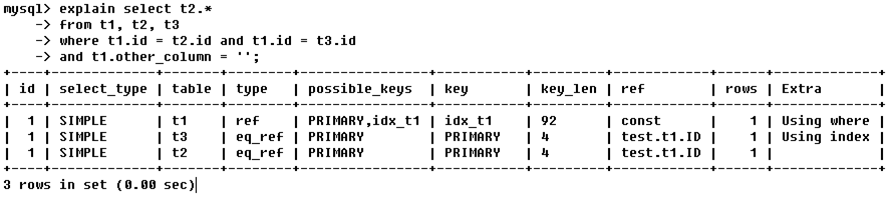
Consulta toda la tabla t2 de las tres tablas t1, t2 y t3. Las condiciones de consulta son: t1.id = t2.id, t1.id = t3.id y otros campos de t1 están vacíos; el optimizador trata las condiciones. dentro del mismo
donde, el valor predeterminado es leer de derecha a izquierda,
por lo que el orden de ejecución de las tres tablas es: t1 -> t3 -> t2;
(2) Los ID son diferentes: cuanto mayor sea el ID, mayor será la prioridad de ejecución.
Si es una subconsulta, el número de secuencia de la identificación se incrementará y la subconsulta interna se ejecutará primero, similar a la idea de recursividad; la declaración en () tiene prioridad.
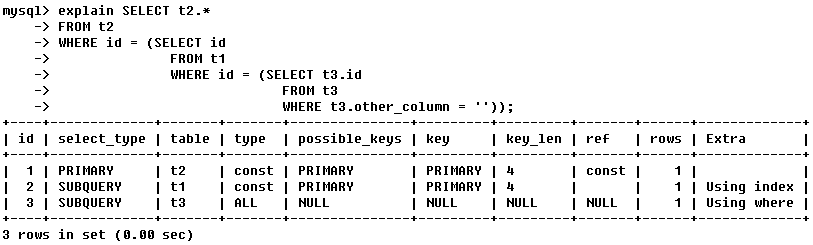
Consulta toda la tabla t2 desde la tabla t2. La condición de consulta es id y la condición de consulta son tres niveles de anidamiento:
Consulta la identificación de la tabla t1 - id es la identificación de la tabla t3 consultada desde la tabla t3 - otra Los campos de la tabla t3 están vacíos;
usando el pensamiento recursivo, es fácil juzgar el orden de ejecución de la tabla: t3 -> t1 -> t2
(3) Hay situaciones en las que los ID son iguales y diferentes al mismo tiempo: aquellos con ID diferentes y más grandes se ejecutarán primero, y aquellos con el mismo ID se ejecutarán de arriba a abajo.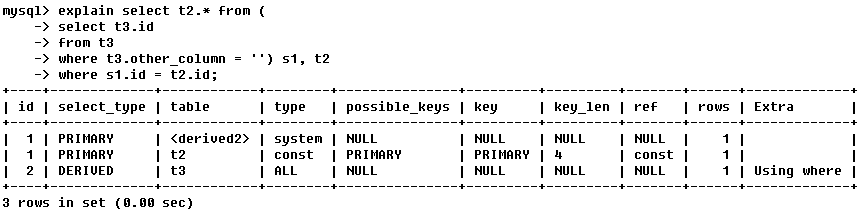
Aquí es necesario introducir un concepto, consulta de tabla virtual derivada (Derivada):
se intercepta información parcial de la tabla original y el conjunto resultante puede formar una nueva tabla. Esta tabla en realidad no existe y se llama tabla virtual; esto tipo de consulta Se llama consulta de tabla virtual derivada;
(Consulte el ID de la tabla t3 de la tabla t3, y la condición de consulta es que otros campos estén vacíos) Utilice el conjunto de resultados de la condición de consulta de la tabla t3 entre paréntesis como una tabla virtual s1, y consulte la tabla t2 desde la tabla virtual s1 y tabla t2
. En todas ellas, la condición de consulta es s1.id=t2.id,
por lo tanto, la secuencia de consulta es: t3 -> derivada2 -> t2
derivada2 se refiere a la tabla virtual s1 formada al derivar el conjunto de resultados de la tabla t3 cuando identificación=2;
4.2、seleccionar_tipo
Tipos de consulta, hay un total de los siguientes 6 tipos de consulta de tabla:
· (1) consulta SIMPLE
simple, la consulta no incluye subconsultas ni uniones (consultas conjuntas);
· (2)
Si la consulta PRIMARIA contiene una subconsulta, la consulta más externa se marca como PRIMARIA;
· (3)
Subconsulta de SUBCONSULTA en la lista de selección o dónde
· (4)
Sintaxis típica DERIVADA: de (subconsulta) s1,
la subconsulta incluida en la lista de se marca como DERIVADA (derivada) y el conjunto de resultados después de la ejecución de esta subconsulta se coloca en una tabla virtual s1;
· (5) UNION
Si la segunda selección aparece después de la unión, se marca como consulta de múltiples tablas de unión;
si la unión está incluida en la consulta de la cláusula from, es decir, el atributo de selección de (subconsulta 1 subconsulta unión 2) s1, esta La selección externa está marcada como DERIVADA;
· (6) SELECCIONAR RESULTADO UNION
para obtener resultados de la tabla UNION
4.3 、 tabla
Se refiere a la tabla correspondiente a la identificación, y el orden de ejecución de la tabla está determinada por la identificación, y
también se refiere a qué tabla se relacionan los datos de esta fila;
4.4 、 tipo
Al mostrar consultas, ¿qué tipo de consulta se utiliza? Los siguientes 7 tipos se encuentran a menudo en el trabajo diario. El rendimiento de mejor a peor es:
system > const > eq_ref > ref > range > index > ALL
generalmente necesita garantizar la consulta. el nivel de tipo alcanza el rango, preferiblemente ref, y evite usar TODOS.
· (1) La consulta del sistema
significa que solo hay una fila de datos en la tabla. Este es un caso especial de constante y generalmente no aparece. Debido a que solo hay una fila de información, no se llama big data, por lo que tiene poca importancia;
· (2) constante
La consulta constante significa que se puede encontrar a través del índice una vez. Se utiliza para comparar índices como clave principal = constante y única = constante.
Si la clave principal se coloca en la lista donde, MySQL tiene la función de conversión automática de tipos. y convertirá automáticamente la consulta como una constante

d1 es una tabla virtual y los paréntesis tienen prioridad. La tabla t1 se ejecuta primero, donde id = 1 es una consulta constante, la tabla
virtual d1 tiene solo una fila de datos, por lo que el tipo de consulta es sistema de consulta del sistema;
· (3)eq_ref
Escaneo de índice único. Para cada clave de índice, solo hay una fila de datos en la tabla, lo cual es común en las claves primarias.

No hay paréntesis después de dónde. El optimizador de MySQL se ejecuta de izquierda a derecha. Por lo tanto, primero se ejecuta la tabla t2 y el tipo es TODO. La consulta de la tabla completa corresponde a 639 filas de información. Luego se consulta la tabla t1. El tipo es eq_ref
, y la identificación en la tabla 1 solo corresponde a 1 fila de información. , escaneo de índice único;
· (4)
escaneo de índice no único de referencia; para cada clave de índice, puede haber varias filas de datos en la tabla;
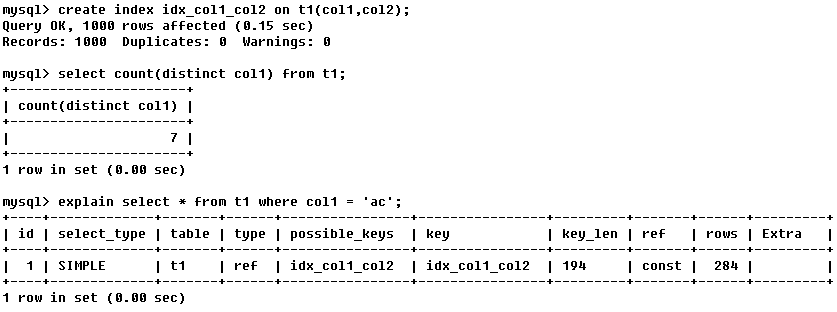
En la tabla de consulta t1, hay 7 campos únicos col1, y el resto son todos duplicados;
hay 284 filas de registros que cumplen con la condición de consulta col1 = 'ac', por lo que es un escaneo de índice no único de referencia;
· (5) Consulta de rango , la lista después de dónde está la consulta entre, <, >, en, etc.;

Las palabras clave entre y tipo son búsquedas de rango;

Las palabras clave en y tipo son búsquedas por rango;
★ La palabra clave me gusta también es una búsqueda por rango y se escribirá más adelante;
· (6)
escaneo de índice completo, escaneo de índice completo, solo atraviesa el árbol de índice, generalmente más rápido que TODO (
índice y TODO son consultas de tabla completa, pero el índice lee del índice, TODO lee de la tabla completa);
· (7) TODO
el escaneo completo de la tabla, FULL TABLE SCAN, recorre toda la tabla para encontrar filas coincidentes; es el más lento, evite usarlo;
4.5. llaves_posibles
Si hay un índice en el campo consultado, se enumerarán uno o más índices , pero es posible que en realidad no se utilicen durante la consulta;
4.6. llave
El índice real utilizado , si es NULL, el índice no se utiliza. Posibles razones comunes:
· (1) No se crea ningún índice
· (2) La instrucción SQL está escrita incorrectamente y el índice no es válido;
· (3) Cuando es posible_clave también es NULL, significa que se usa No indexado
4.7. clave_len
Puede ver la cantidad de campos de índice a través de key_len, 74 se refiere a 1, 78 se refiere a 2 y 140 se refiere a 3;
4.8. árbitro
Muestra qué campo se está indexando, que puede ser una constante constante;
ps: el tipo de referencia se refiere a un escaneo de índice no único. Para los campos de índice, puede haber múltiples valores duplicados;

Consulta todo de la tabla t1 y la tabla t2, condiciones de consulta: t1.col1=t2.col1, t1.col2='ac';
en la misma lista donde, el optimizador se ejecuta de derecha a izquierda, el índice tiene dos campos;
prioridad Ejecutar el valor del campo 'ac', que es una constante constante,
luego ejecuta el campo col1 en la tabla t2 en la base de datos compartida, es decir, compartida.t2.col1;
4.9
Al consultar el índice de filas, estime aproximadamente el número de filas necesarias para leer los registros requeridos. Cuanto más pequeñas sean las filas, mejor;
4.10. Extra
La información adicional incluye los siguientes tres tipos:
· (1) El uso de clasificación de archivos
indica que el índice creado y preparado para su uso no se ha utilizado y que se ha realizado la clasificación de archivos;
puede haber un problema con la escritura de la declaración SQL, que entra en conflicto con el índice índice previamente establecido. ;
· (2) El uso temporal utiliza
una tabla temporal para guardar resultados intermedios, lo que indica que el índice establecido no se utiliza por completo;
es común en la clasificación por y en la consulta de grupo por;
· (3)
El índice de cobertura se utiliza en la operación de selección de índice, lo que muestra que la eficiencia de la ejecución de SQL es buena.
Índice de cobertura:
por ejemplo: primero cree un índice, campo_índice a_campo b;
luego seleccione el campo a, campo b en la tabla donde campo a=..., campo b=...
es decir, primero cree un índice con ciertos campos Índice, y luego consulta los campos en el índice. La lista donde es el valor del campo de índice, es decir, cuando el valor del campo de índice es XXX, consulta el campo, esta es la forma más eficiente de seleccionar.
··· Si usa Where aparece al mismo tiempo, indica que el índice se usa para realizar la búsqueda del valor de la clave de índice;
··· Si usa Where no aparece al mismo tiempo, indica que el índice no se usa para realizar la búsqueda del valor de la clave de índice, pero solo se usa para leer datos;