Índice de contenidos de los artículos de la serie.
- Entrevista sobre Java 2024 (1) - Capítulo de primavera
- Entrevista sobre Java 2024 (2) - Capítulo de primavera
- Entrevista sobre Java 2024 (3) - Capítulo de primavera
- Entrevista sobre Java 2024 (4) - Capítulo de primavera
Directorio de artículos
- Índice de contenidos de los artículos de la serie.
- Tolerancia a fallas de partición de Redis
- 1. ¿Por qué Redis es rápido?
- 2. ¿Por qué Redis tiene un solo subproceso?
- 3. ¿Cuánta memoria tiene el servidor Redis?
- 4. ¿Por qué las operaciones de Redis son atómicas y cómo garantizar la atomicidad?
- 5. Cómo lograr coherencia entre los datos de Redis y la base de datos MySQL
- 6. Algoritmos de limitación de corriente de uso común
- 7. El concepto de ranura hash de Redis
- 8. ¿Cuáles son los escenarios adecuados para Redis?
- 9. Aplicación de Redis en proyectos
Tolerancia a fallas de partición de Redis
1. partición de datos de redis
Hash: (inestable)
Fragmentación del cliente: hash + resto
Escalado de nodos: las relaciones de los nodos de datos cambian, lo que lleva a la migración de datos
El número de migraciones está relacionado con el número de nodos agregados: se recomienda duplicar la capacidad.
Una idea simple e intuitiva es usar Hash para calcular directamente, usar Key para hacer hash y luego tomar el módulo del número de nodos. Se puede ver que cuando las claves están lo suficientemente dispersas, se puede lograr uniformidad, pero una vez que un nodo se une o sale, todos los nodos originales se verán afectados y la estabilidad está fuera de discusión.
Hash consistente: (desequilibrado)
Fragmentación del cliente: Hash + en el sentido de las agujas del reloj (resto optimizado)
Escalado de nodos: solo afecta a los nodos vecinos, pero aún hay migración de datos
Doble escalamiento: garantizar una migración de datos y un equilibrio de carga mínimos
Consistent Hash puede resolver muy bien el problema de estabilidad. Todos los nodos de almacenamiento se pueden organizar en anillos Hash contiguos. Después de calcular el Hash, cada clave encontrará el primer grupo de nodos de almacenamiento encontrado en el sentido de las agujas del reloj para su almacenamiento. Cuando un nodo se une o sale, solo afecta a los nodos posteriores adyacentes al nodo en el sentido de las agujas del reloj en el anillo Hash y recibe o proporciona datos del nodo. Pero esto genera el problema de la uniformidad: incluso si los nodos de almacenamiento se pueden organizar equidistantemente, los datos serán desiguales cuando cambie el número de nodos de almacenamiento .
Ranura Codis Hash
Codis divide todas las claves en 1024 ranuras de forma predeterminada. Primero realiza la operación crc32 en la clave pasada por el cliente para calcular el valor hash y luego modula el valor entero hash de 1024 para obtener un resto. Este resto es la ranura correspondiente a la clave.
RedisClúster
Redis-cluster asigna todos los nodos físicos a las ranuras [0-16383] y utiliza el algoritmo crc16 para obtener el valor hash de la clave y el módulo 16384. Básicamente, utiliza distribución promedio y distribución continua.
2. Modo maestro-esclavo = simple
La mayor ventaja del modo maestro-esclavo es que es fácil de implementar . Al menos dos nodos pueden formar el modo maestro-esclavo , y la separación de lectura y escritura puede evitar la falta de disponibilidad simultánea de lectura y escritura . Sin embargo, una vez que falla el nodo maestro, los nodos maestro y esclavo no pueden cambiar automáticamente , lo que conduce directamente a una caída en el SLA. Por lo tanto, el modelo maestro-esclavo generalmente es adecuado para situaciones en las primeras etapas del desarrollo empresarial, baja concurrencia y bajos costos de operación y mantenimiento.
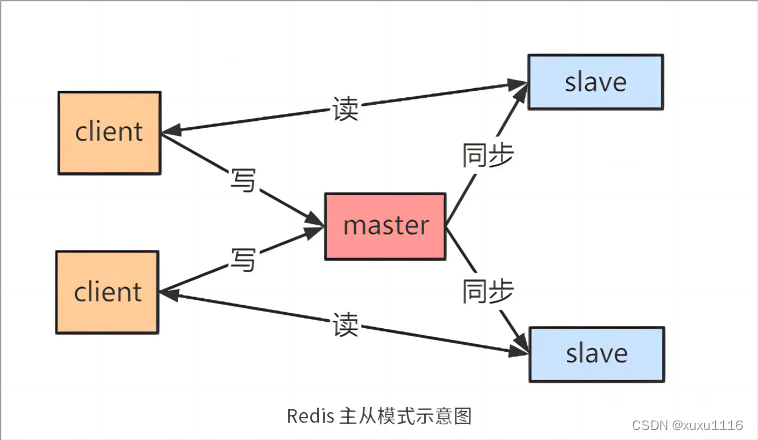
Principio de replicación maestro-esclavo:
① Envíe el comando PSYNC desde el servidor esclavo al servidor maestro
② Si es la primera vez que se conecta, active una copia completa . En este momento, el nodo maestro iniciará un hilo en segundo plano y generará un archivo de instantánea RDB.
③El nodo maestro enviará este RDB al nodo esclavo, y el esclavo primero lo escribirá en el disco local y luego lo cargará desde el disco local a la memoria.
④El maestro escribirá los comandos de escritura en este proceso en el caché y los nodos esclavos sincronizarán estos datos en tiempo real.
⑤ Si la red se desconecta, después de la reconexión automática, el nodo maestro propaga copias incrementales de los datos faltantes al nodo esclavo mediante comandos.
defecto
Toda la replicación y sincronización de los datos del nodo esclavo son manejadas por el nodo maestro. Esto hará que el nodo maestro esté bajo demasiada presión. Esto se resuelve usando la estructura maestro-esclavo. La introducción de psync2 en redis4.0 resuelve el problema esa sincronización incremental aún se puede realizar después de reiniciar el esclavo.
3. Modo centinela = leer más
Un clúster centinela compuesto por una o más instancias centinela puede monitorear uno o más servidores maestros y múltiples servidores esclavos. El modo Sentinel es adecuado para escenarios empresariales en los que hay muchas más solicitudes de lectura que de escritura , como el almacenamiento en caché de información de actividad en un sistema de venta flash . Si hay muchas solicitudes de escritura y aumenta la cantidad de nodos esclavos en el clúster, la presión sobre el nodo maestro para sincronizar los datos será muy alta.
Cuando el servidor maestro se desconecta, Sentinel puede actualizar un servidor esclavo bajo el servidor maestro para continuar brindando servicios al servidor maestro, asegurando así la alta disponibilidad de redis.
Detectar estado subjetivo fuera de línea
Sentinel envía un comando PING una vez por segundo a todas las instancias (servidores maestros, servidores esclavos y otros Sentinels) que han establecido conexiones de comando con él.
Si una instancia devuelve una respuesta no válida dentro de los milisegundos de inactividad después de milisegundos, Sentinel considerará que la instancia está subjetivamente fuera de línea ( SDown ).
Verificar el estado objetivo fuera de línea
Cuando un Sentinel determina que un servidor principal está subjetivamente fuera de línea, Sentinel enviará comandos para consultar el estado del host a todos los demás Sentinel que monitorean el servidor principal.
Si todas las instancias de Sentinel que alcanzan el número de quórum en la configuración de Sentinel determinan que el servidor principal está subjetivamente fuera de línea, se determinará que el servidor principal está objetivamente fuera de línea ( ODown ).
Elegir líder centinela
Cuando se determina que un servidor maestro está objetivamente fuera de línea, todos los Sentinels que monitorean el servidor maestro seleccionarán un Leader Sentinel para realizar una operación de conmutación por error a través de un algoritmo de elección (balsa).
Algoritmo de balsa
El protocolo Raft es un protocolo utilizado para resolver el problema de coherencia de los sistemas distribuidos. Hay tres estados de nodos descritos por el protocolo Raft: líder, seguidor y candidato. El protocolo Raft divide el tiempo en Término, que puede considerarse una especie de "tiempo lógico". Proceso electoral:
①Raft utiliza el mecanismo de latido para activar el sistema de elección de Líder. Una vez iniciado el sistema, todos los nodos se inicializan como Seguidor y el término es 0.
② Si el nodo recibe RequestVote o AppendEntries, mantendrá su identidad de Seguidor
③ Si el nodo no recibe el mensaje AppendEntries dentro de un período de tiempo y no se ha encontrado al líder dentro del período de tiempo de espera del nodo, el seguidor se convertirá en candidato y comenzará a postularse para líder. Una vez convertido a Candidato, el nodo inmediatamente inicia lo siguiente: --Agregar su propio término, iniciar un nuevo cronómetro --Votar por sí mismo, enviar RequestVote a todos los demás nodos y esperar respuestas de otros nodos.
④ Si el nodo recibe el voto de aprobación de la mayoría de los nodos antes de que expire el tiempo, se convertirá en Líder. Al mismo tiempo, las notificaciones se envían a otros nodos a través de AppendEntries.
⑤Cada nodo solo puede emitir un voto por período, adoptando una estrategia por orden de llegada: el candidato vota por sí mismo y el seguidor votará por el primer nodo que reciba RequestVote.
⑥El temporizador del protocolo Raft adopta un tiempo de espera aleatorio (la clave para la elección). El nodo que se convierta primero en Candidato iniciará la votación primero, obteniendo así la mayoría de votos.
Selección de servidor primario
Cuando se elige el líder Sentinel, el líder Sentinel seleccionará un nuevo servidor maestro entre los servidores de acuerdo con las siguientes reglas.
① Filtrar nodos fuera de línea subjetivos y objetivos
② Seleccione el nodo con la configuración de prioridad de esclavo más alta. Si hay uno, devuelva no y continúe seleccionando.
③Seleccione el nodo del sistema con el mayor desplazamiento de replicación, porque cuanto mayor sea el desplazamiento de replicación, más completa será la replicación de datos.
④ Seleccione el nodo con el run_id más pequeño, porque cuanto más pequeño sea el run_id, menor será el número de reinicios.
conmutación por error
Después de que Leader Sentinel complete la selección de un nuevo servidor maestro, Leader Sentinel realizará una operación de conmutación por error en el servidor maestro fuera de línea. Hay tres pasos principales:
1. Actualizará uno de los Esclavos del Maestro fallido a un nuevo Maestro y permitirá que otros Esclavos del Maestro fallido cambien para copiar el nuevo Maestro;
2. Cuando el cliente intenta conectarse al Maestro fallido, el clúster devolverá la dirección del nuevo Maestro al cliente, dejando el clúster con un solo Maestro en su estado actual.
3. Después de cambiar los servidores maestro y esclavo, el contenido de los archivos de configuración redis.conf del maestro, redis.conf y sentinel.conf del esclavo cambiarán en consecuencia, es decir, habrá una línea adicional de replicaof en el redis del maestro. conf configuración, el objetivo de monitoreo de sentinel.conf se cambiará en consecuencia.
4. Modo clúster = escribir más
Para evitar la inestabilidad causada por una carga excesiva en un solo nodo, el modo de clúster utiliza un algoritmo hash consistente o un método de ranura hash para distribuir la clave a cada nodo. Entre ellos, a cada nodo maestro le siguen varios nodos esclavos, que se utilizan para la conmutación activa y de respaldo en caso de falla. El cliente puede conectarse a cualquier nodo maestro y el clúster reenviará solicitudes a diferentes nodos maestros de acuerdo con diferentes claves.¿Cómo logra el modo de clúster una alta disponibilidad
? Los nodos dentro del clúster detectarán periódicamente la supervivencia de los demás. Si la mayoría de los nodos determinan que un nodo está inactivo, lo expulsarán del clúster y luego elegirán un nodo de los nodos esclavos para reemplazar el nodo maestro fallido. El principio completo es básicamente el mismo que el del modo centinela:
aunque el modo de clúster evita el problema de un solo nodo maestro, se ocupará una cierta cantidad de ancho de banda al sincronizar datos dentro del clúster. Por lo tanto, las personas solo usan el modo de clúster cuando hay muchas operaciones de escritura. En la mayoría de los demás casos, el modo centinela puede satisfacer las necesidades.
5. Cerradura distribuida
Uso de Watch para implementar el bloqueo optimista de Redis
El bloqueo optimista se basa en la idea de comparación y reemplazo CAS (Compare And Swap), que no provoca bloqueos en espera ni consume recursos, pero requiere reintentos repetidos, pero también se debe al mecanismo de reintento que puede responder más rápido. Por lo tanto, podemos usar redis para implementar un bloqueo optimista (segunda eliminación). Las ideas específicas son las siguientes:
1. Utilice la función de vigilancia de redis para monitorear el valor de estado de redisKey. 2. Obtenga el valor de redisKey, cree una transacción de redis y agregue 1 al valor de la clave. 3. Ejecute la transacción. Si el valor de la clave se modifica, retroceda la clave. No agregue 1
Utilice setnx para evitar la sobreventa de inventario. Los bloqueos distribuidos son una forma de controlar el acceso sincrónico a recursos compartidos entre sistemas distribuidos. Utilice la función de subproceso único de Redis para serializar recursos compartidos
// 获取锁推荐使用set的方式
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);
String result = jedis.setnx(lockKey, requestId); //如线程死掉,其他线程无法获取到锁
// 释放锁,非原子操作,可能会释放其他线程刚加上的锁
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
// 推荐使用redis+lua脚本
String lua = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object result = jedis.eval(lua, Collections.singletonList(lockKey),
Problemas con bloqueos distribuidos:
- El cliente está bloqueado durante mucho tiempo provocando un problema de falla de bloqueo
Durante el tiempo de cálculo, se inicia otro subproceso de forma asincrónica para verificar si la clave ha agotado el tiempo de espera. Cuando el tiempo de espera de bloqueo está a punto de expirar y la lógica no se ha completado, extienda el tiempo de espera de bloqueo.
-
El problema de la desviación del reloj del servidor Redis hace que el tiempo de vencimiento de Redis bloqueado simultáneamente dependa del reloj del sistema. Si la desviación del reloj es demasiado grande, es teóricamente posible y afectará el cálculo del tiempo de vencimiento .
-
Falla de instancia de punto único, los bloqueos no se sincronizan en el tiempo, lo que resulta en pérdida
Algoritmo de bloqueo rojo
1. Obtenga la marca de tiempo actual T0 y configure el error de deriva del reloj T1
2. Adquiera todos los candados N/2+1 uno por uno en un corto período de tiempo, finalizando en el momento T2
3. El tiempo de procesamiento de bloqueo real se convierte en: TTL - (T2 - T0) - T1.
Esta solución utiliza múltiples nodos para evitar el punto único de falla de Redis . El efecto es promedio y no se puede prevenir:
- Dos clientes mantienen bloqueos al mismo tiempo causados por el cambio maestro-esclavo
En la mayoría de los casos, la duración es extremadamente corta y también existen problemas al usar Redlock para obtener el bloqueo del nodo en el momento del cambio. Ya es un momento de probabilidad extremadamente baja y no se puede evitar. El bloqueo distribuido de Redis es adecuado para transacciones idempotentes . Si se debe garantizar la seguridad , se debe utilizar Zookeeper o DB , pero el rendimiento disminuirá drásticamente .
Comparación con el bloqueo distribuido del cuidador del zoológico
- El bloqueo distribuido de Redis en realidad requiere que intentes adquirir el bloqueo constantemente, lo que consume rendimiento.
- Para los bloqueos distribuidos de zk, simplemente registre un oyente. No es necesario intentar constantemente adquirir bloqueos. ZK adquiere los bloqueos en el orden de bloqueo, por lo que es un bloqueo justo. Su rendimiento es similar al de mysql, pero es muy diferente de redis.
Cerraduras distribuidas para el entorno de producción de Redission
Redisson es un componente de código abierto de bloqueo distribuido Java In-Memory Data Grid (In-Memory Data Grid) basado en el marco Netty de NIO.
Pero cuando la empresa debe tener una gran coherencia de datos, es decir, no se permite la adquisición repetida de bloqueos, como escenarios financieros (órdenes repetidas, transferencias repetidas), no utilice bloqueos distribuidos de Redis . Se puede implementar utilizando el modelo CP, como: zookeeper y etcd .
| Redis | cuidador del zoológico | etcétera | |
|---|---|---|---|
| algoritmo de consenso | ninguno | Paxos (ZAB) | balsa |
| GORRA | AP | CP | CP |
| Alta disponibilidad | grupo maestro-esclavo | n+1 | n+1 |
| lograr | conjuntoNX | crearNodo | API de descanso |
Seis, detección de latidos del corazón de Redis
Durante la fase de propagación del comando, el servidor esclavo enviará un comando ACK al servidor maestro una vez por segundo de forma predeterminada:
1. Detectar el estado de conexión del maestro y el esclavo. Detectar el estado de conexión de red de los servidores maestro y esclavo.
El valor del retraso debe saltar entre 0 o 1. Si excede 1, significa que la conexión entre el maestro y el esclavo El esclavo está defectuoso.
2. Para ayudar en la implementación de mini-slaves, Redis se puede configurar para evitar que el servidor principal ejecute comandos de escritura en situaciones inseguras.
min-slaves-to-write 3 (min-replicas-to-write 3 )
min-slaves-max-lag 10 (min-replicas-max-lag 10)
La configuración anterior significa que cuando el número de servidores esclavos es inferior a 3, o el valor de retraso (retraso) de los tres servidores esclavos es mayor o igual a 10 segundos, el servidor maestro se negará a ejecutar el comando de escritura.
3. Detectar la pérdida de comando y agregar un mecanismo de retransmisión.
Si el comando de escritura transmitido desde el servidor maestro al servidor esclavo se pierde a la mitad debido a una falla de la red, cuando el servidor esclavo envía el comando REPLCONF ACK al servidor maestro, el maestro El servidor descubrirá la replicación actual del servidor esclavo. Si el desplazamiento es menor que su propio desplazamiento de replicación, entonces el servidor maestro encontrará los datos faltantes del servidor esclavo en el búfer de trabajo pendiente de replicación en función del desplazamiento de replicación enviado por el servidor esclavo. y reenviar los datos al servidor esclavo.
1. ¿Por qué Redis es rápido?
1) Completamente basado en la memoria, la mayoría de las solicitudes son operaciones de memoria pura y muy rápidas. Los datos se almacenan en la memoria, similar a HashMap. La ventaja de HashMap es que la complejidad temporal de la búsqueda y la operación es O (1)
2) La estructura de datos es simple y las operaciones de datos también lo son. La estructura de datos en Redis está especialmente diseñada
3) El uso de un solo subproceso evita cambios de contexto innecesarios y condiciones de competencia. No hay cambios causados por múltiples procesos o subprocesos múltiples que consumen la CPU. No es necesario considerar varios problemas de bloqueo. No hay operación de liberación de bloqueo. Consumo de rendimiento causado por posibles interbloqueos
4) Utilice el modelo de multiplexación de E/S, IO sin bloqueo
5) Los modelos subyacentes son diferentes, los métodos de implementación subyacentes y los protocolos de aplicación para la comunicación con el cliente son diferentes. Redis construye directamente su propio mecanismo VM, porque si el sistema general llama a las funciones del sistema, perderá una cierta cantidad de tiempo. moverse y solicitar
2. ¿Por qué Redis tiene un solo subproceso?
Las preguntas frecuentes oficiales afirman que debido a que Redis es una operación basada en memoria, la CPU no es el cuello de botella de Redis, lo más probable es que el cuello de botella de Redis sea el tamaño de la memoria de la máquina o el ancho de banda de la red. Dado que el subproceso único es fácil de implementar y la CPU no se convertirá en un cuello de botella, es lógico adoptar una solución de subproceso único. Redis utiliza tecnología de cola para convertir el acceso concurrente en acceso en serie.
1) La gran mayoría de las solicitudes son operaciones de memoria pura.
2) Usar un solo hilo para evitar cambios de contexto y condiciones de carrera innecesarios
3. ¿Cuánta memoria tiene el servidor Redis?
Establezca los parámetros de la memoria de Redis en el archivo de configuración:.
Si este parámetro no está configurado o se establece en 0, el tamaño de memoria predeterminado de redis es:
El valor predeterminado es 3G en modo de 32 bits.
Sin restricciones en 64 bits
Generalmente se recomienda que Redis configure la memoria en tres cuartas partes de la memoria física máxima, que es 0,75.
La configuración de la línea de comando config set maxmemory <tamaño de memoria en bytes> fallará cuando se reinicie el servidor.
config get maxmemory obtiene el tamaño de memoria actual
Si es permanente, debe configurar el parámetro maxmemory, maxmemory es el tipo de byte bytes, preste atención a la conversión.
4. ¿Por qué las operaciones de Redis son atómicas y cómo garantizar la atomicidad?
Para Redis, la atomicidad de un comando significa que una operación no se puede subdividir y la operación se ejecuta o no.
La razón por la que las operaciones de Redis son atómicas es porque Redis tiene un solo subproceso.
Todas las API proporcionadas por Redis son operaciones atómicas y las transacciones en Redis en realidad garantizan la atomicidad de las operaciones por lotes.
¿Hay varios comandos atómicos en concurrencia?
No necesariamente, cambie get y set en operaciones de comando único, incr. Utilice transacciones de Redis o utilice Redis+Lua==.
5. Cómo lograr coherencia entre los datos de Redis y la base de datos MySQL
1. Estrategia de doble eliminación retrasada:
realice operaciones redis.del (clave) antes y después de escribir la base de datos y establezca un tiempo de espera razonable. Los pasos específicos son:
1) Eliminar el caché primero
2) Luego escribir en la base de datos
3) Suspender durante 500 milisegundos (dependiendo del tiempo comercial específico)
4) Eliminar el caché nuevamente.
Entonces, ¿cómo se determinan estos 500 milisegundos y cuánto tiempo debe dormir?
Debe evaluar la lógica empresarial de lectura de datos de su proyecto que requiere mucho tiempo. El propósito de esto es garantizar que la solicitud de lectura finalice y que la solicitud de escritura pueda eliminar los datos sucios almacenados en caché causados por la solicitud de lectura. Por supuesto, esta estrategia también tiene en cuenta la lenta sincronización entre redis y la base de datos maestro-esclavo. El tiempo de inactividad final para escribir datos: en función del tiempo que lleva leer la lógica empresarial de datos, solo agregue unos cientos de milisegundos. Por ejemplo: dormir 1 segundo.
2. Establecer el tiempo de caducidad de la caché.En
teoría, establecer el tiempo de caducidad de la caché es una solución para garantizar la coherencia final. Todas las operaciones de escritura están sujetas a la base de datos. Siempre que se alcance el tiempo de caducidad de la caché, las solicitudes de lectura posteriores leerán naturalmente nuevos valores de la base de datos y luego rellenarán la caché en combinación con la estrategia de doble eliminación + configuración de tiempo de espera de caché
. El peor de los casos es que dentro del período de tiempo de espera haya inconsistencia en los datos internos y aumente el tiempo de redacción de solicitudes.
3. ¿Cómo volver a eliminar con éxito el caché después de escribir en la base de datos?
La solución anterior tiene una desventaja, es decir, después de operar la base de datos, la eliminación del caché falla por varias razones, en este momento pueden ocurrir inconsistencias en los datos. Aquí, debemos proporcionar una solución para garantizar el reintento.
1. Proceso específico del plan 1
(1) Actualizar los datos de la base de datos;
(2) La eliminación de la caché falla debido a varios problemas;
(3) Enviar la clave que debe eliminarse a la cola de mensajes;
(4) Consumir el mensaje usted mismo y obtenerlo la clave que necesita ser eliminada;
(5) Continúe reintentando la operación de eliminación hasta que tenga éxito.
Sin embargo, esta solución tiene la desventaja de provocar una gran intrusión en el código de la línea de negocio. Entonces tenemos la segunda opción, en la segunda opción, iniciar un programa de suscripción para suscribirse al binlog de la base de datos para obtener los datos que necesitan ser operados. En la aplicación, inicie un nuevo programa para obtener la información de este programa de suscripción y elimine el caché.
2. Proceso específico de la opción 2
(1) Actualizar los datos de la base de datos;
(2) La base de datos escribirá la información de la operación en el registro binlog;
(3) El programa de suscripción extrae los datos y la clave requeridos;
(4) Iniciar una nueva sección de código no comercial, obtener la información;
(5) intentar eliminar la operación de caché y descubrir que la eliminación falló;
(6) enviar la información a la cola de mensajes;
(7) volver a obtener los datos de la cola de mensajes y reintente la operación.
6. Algoritmos de limitación de corriente de uso común
Algoritmo de contador: implementado utilizando los mecanismos setnx y de vencimiento de redis
Algoritmo de depósito con fugas: generalmente implementado mediante una cola de mensajes, el sistema procesa las solicitudes en la cola a una velocidad constante y comienza a rechazar solicitudes cuando la cola está llena.
Algoritmo de depósito de tokens: ni el algoritmo de contador ni el algoritmo de depósito con fugas pueden resolver una gran concurrencia repentina. El algoritmo del depósito de tokens coloca una cierta cantidad de tokens en el depósito por adelantado y luego coloca los tokens en el depósito a una velocidad constante hasta que el depósito esté lleno. completo Todas las solicitudes deben Necesitas obtener el token para acceder al sistema
7. El concepto de ranura hash de Redis
El clúster de Redis no utiliza hash consistente, pero introduce el concepto de ranuras de hash. El clúster de Redis tiene 16384 ranuras de hash. Cada clave es verificada por CRC16 y el módulo 16384 se utiliza para determinar qué ranura colocar. Cada nodo del clúster es responsable de parte de la ranura hash.
8. ¿Cuáles son los escenarios adecuados para Redis?
(1) Caché de sesión
Uno de los escenarios más utilizados para usar Redis es el caché de sesión. La ventaja de utilizar Redis para almacenar sesiones en caché sobre otro tipo de almacenamiento (como Memcached) es que Redis proporciona persistencia. Al mantener un caché que no requiere estrictamente coherencia, la mayoría de las personas no estarían contentas si se perdiera toda la información del carrito de compras del usuario. Ahora bien, ¿seguirían estando así?
Afortunadamente, a medida que Redis ha mejorado a lo largo de los años, es fácil descubrir cómo utilizar Redis correctamente para almacenar en caché los documentos de sesión. Incluso la conocida plataforma comercial Magento proporciona complementos de Redis.
(2) Caché de página completa (FPC)
Además del token de sesión básico, Redis también proporciona una plataforma FPC muy simple. Volviendo al problema de coherencia, incluso si se reinicia la instancia de Redis, los usuarios no verán una disminución en la velocidad de carga de la página debido a la persistencia del disco. Esta es una gran mejora, similar al FPC local de PHP.
Tomando Magento nuevamente como ejemplo, Magento proporciona un complemento para usar Redis como backend de caché de página completa.
Además, para los usuarios de WordPress, Pantheon tiene un muy buen complemento wp-redis, que puede ayudarlo a cargar las páginas que ha navegado lo más rápido posible.
(3)
Una de las grandes ventajas de la cola de Redis en el campo de los motores de almacenamiento de memoria es que proporciona operaciones de lista y configuración, lo que permite que Redis se utilice como una buena plataforma de cola de mensajes. Las operaciones utilizadas por Redis como cola son similares a las operaciones push/pop de los lenguajes de programación locales (como Python) en listas.
Si busca rápidamente "colas de Redis" en Google, encontrará inmediatamente una gran cantidad de proyectos de código abierto, cuyo propósito es utilizar Redis para crear muy buenas herramientas de back-end para satisfacer diversas necesidades de colas. Por ejemplo, Celery tiene un backend que utiliza Redis como intermediario. Puedes verlo desde aquí.
(4) Lista de clasificación/contador
Redis implementa muy bien la operación de incrementar o disminuir números en la memoria. Los conjuntos y los conjuntos ordenados también nos facilitan mucho la realización de estas operaciones. Redis solo proporciona estas dos estructuras de datos. Entonces, para obtener los 10 mejores usuarios del conjunto ordenado, llamémoslos "user_scores", solo tenemos que hacerlo así: Por supuesto, esto supone que lo estás haciendo en función de las puntuaciones de
tus usuarios. Clasificación creciente. Si desea devolver el usuario y la puntuación del usuario, debe ejecutarlo de esta manera:
ZRANGE user_scores 0 10 CONSCORES
Agora Games es un buen ejemplo, implementado en Ruby, y sus clasificaciones usan Redis para almacenar datos, puede ver aquí.
(5) Publicar/Suscribirse
Por último (pero ciertamente no menos importante) está la función de publicación/suscripción de Redis. De hecho, existen muchos casos de uso para publicar/suscribir. He visto a personas usarlo en conexiones de redes sociales, como desencadenantes de scripts basados en publicación/suscripción, ¡e incluso para crear sistemas de chat usando la funcionalidad de publicación/suscripción de Redis! (No, esto es cierto, puedes comprobarlo).
9. Aplicación de Redis en proyectos
En términos generales, Redis tiene varias aplicaciones en proyectos.
Como caché, almacene en caché los datos activos para reducir la interacción con la base de datos y mejorar la eficiencia del sistema.
Como solución de bloqueo distribuido, resuelva problemas como la avería del caché.
Como cola de mensajes, utilice la función de publicación y suscripción de Redis para publicar y suscribirse a mensajes. .
Se deben combinar escenarios de uso específicos con el proyecto, como qué escenarios del proyecto utilizan Redis como caché, bloqueos distribuidos, etc.