Índice de contenidos de los artículos de la serie.
- Entrevista sobre Java 2024 (1) - Capítulo de primavera
- Entrevista sobre Java 2024 (2) - Capítulo de primavera
- Entrevista sobre Java 2024 (3) - Capítulo de primavera
- Entrevista sobre Java 2024 (4) - Capítulo de primavera
- Entrevista Java 2024 - Colección
- Entrevista de Java 2024: redis (1)
- Entrevista sobre Java 2024: Redis (2)
Directorio de artículos
- Índice de contenidos de los artículos de la serie.
- optimización de mysql
-
- 1. Optimización del índice
- 2. Optimización de consultas
- 3. Optimización de la estructura de la tabla de la base de datos.
- 4. Optimización de caché
- 5.Optimización de particiones
- 6. Optimización de la configuración
- 7. Optimización de hardware
- sintaxis DQL
- estructura lógica de almacenamiento
- 1. Insertar datos
- 2. Optimización de clave primaria
- 3. ordenar por optimización
- Cuarto, agrupar por optimización
- Cinco, optimización de límites
- Seis, optimización del conteo
- Siete, optimización de la actualización
optimización de mysql
1. Optimización del índice
Los índices son clave para acelerar las consultas de bases de datos. Al diseñar la estructura de la tabla, se deben agregar índices apropiados según los requisitos de la consulta. Los índices de uso común incluyen claves primarias, índices únicos, índices ordinarios, índices conjuntos, índices de prefijo (los datos largos como vachar y texto solo requieren los primeros para lograr una alta diferenciación), etc.
Al mismo tiempo, evite demasiados índices, porque cada índice requiere espacio de almacenamiento y afectará el rendimiento de escritura.
2. Optimización de consultas
La optimización de las declaraciones de consulta es un medio importante para mejorar el rendimiento de MySQL. Utilice índices siempre que sea posible y evite escaneos completos de tablas. Al mismo tiempo, evite el uso de subconsultas y utilice consultas de combinación tanto como sea posible; evite el uso del carácter comodín "%" en las consultas; evite campos redundantes, etc.
3. Optimización de la estructura de la tabla de la base de datos.
Una estructura de tabla razonable puede mejorar la eficiencia de las consultas y reducir el espacio de almacenamiento. Se deben evitar campos grandes como TEXTO, BLOB, etc. porque ocupan mucho espacio de almacenamiento. Al mismo tiempo, se deben evitar campos redundantes para evitar complejidad durante las actualizaciones y el mantenimiento.
①Una sola base de datos no debe exceder las 200 tablas
②Una sola tabla no supera los 5 millones de datos
③Una sola tabla no debe exceder las 40 columnas
④No más de 5 índices de tabla única
4. Optimización de caché
El uso de caché puede reducir en gran medida la presión sobre la base de datos MySQL y mejorar la eficiencia de las consultas. Las tecnologías de almacenamiento en caché más utilizadas incluyen Memcached y Redis.
5.Optimización de particiones
Para tablas con grandes cantidades de datos, se puede utilizar tecnología de partición para dividir la tabla en varias partes. Esto mejora la eficiencia de las consultas al tiempo que reduce el espacio de almacenamiento y el tamaño del índice de una sola tabla.
6. Optimización de la configuración
La configuración de los parámetros de MySQL afectará el rendimiento de MySQL. Debe ajustarse de acuerdo con la situación real, incluidos los búferes, la cantidad de conexiones, la cantidad de subprocesos, el caché de consultas, etc.
7. Optimización de hardware
Los dispositivos de hardware también pueden afectar el rendimiento de MySQL. Elija dispositivos de hardware más rápidos, como discos más rápidos, CPU más rápidas, más memoria, etc. Al mismo tiempo, la decisión de utilizar RAID, SSD y otras tecnologías debe basarse en las condiciones reales.
sintaxis DQL

estructura lógica de almacenamiento
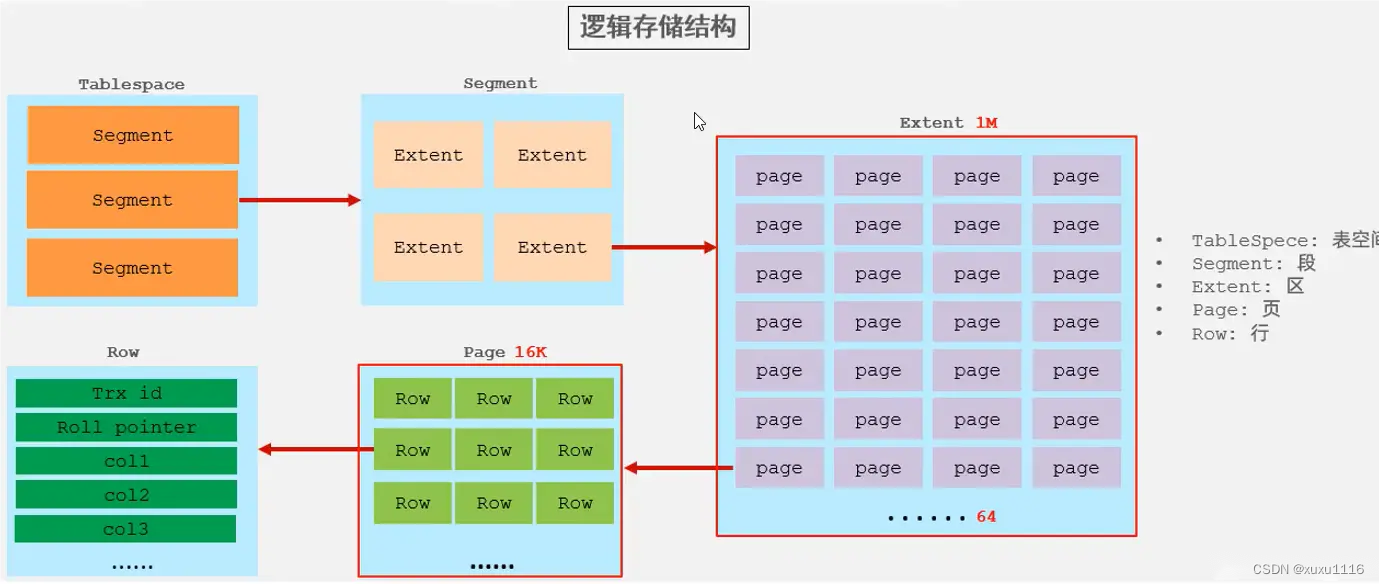
1. Insertar datos
#客户端连接服务端时,加上参数--local-infile
mysql --local-infile -u root-p
#设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
#执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.loginto table tb_user fields terminated by ',' lines terminated by '\n';
主键顺序插入性能高于乱序插入
2. Optimización de clave primaria
Cuando satisfaga las necesidades comerciales, intente reducir la longitud de la clave principal tanto como sea posible.
Al insertar datos, intente insertarlos secuencialmente y use AUTO_INCREMENT para incrementar automáticamente la clave principal.
Intente no utilizar UUID como clave principal u otras claves primarias naturales, como el número de identificación.
Durante las operaciones comerciales, evite la modificación de las claves primarias.
3. ordenar por optimización
- El uso de filesort lee las filas de datos que cumplen las condiciones a través del índice de la tabla o el escaneo completo de la tabla, y luego completa la operación de clasificación en el búfer de clasificación. Toda clasificación que no devuelve directamente los resultados de la clasificación a través del índice se denomina clasificación FileSot.
- Uso del índice: los datos ordenados se devuelven directamente mediante el escaneo secuencial del índice ordenado. En este caso, el uso del índice no requiere clasificación adicional y la eficiencia de la operación es alta.
#没有创建索引时,根据age, phone进行排序
explain select id,age,phone from tb_user order by age , phone;
#创建索引
create index idx_user_age_phone_aa on tb_user(age,phone);
#创建索引后,根据age, phone进行升序排序
explain select id,age,phone from tb_user order by age , phone;
#创建索引后,根据age, phone进行降序排序
explain select id,age,phone from tb_user order by age desc , phone desc ;
#根据age, phone进行降序一个升序,一个降序
explain select id,age,phone from tb_user order by age asc , phone desc;
#创建索引
create index idx_user_age _phone_ad on tb_user(age asc ,phone desc);
#根据age, phone进行降序一个升序,一个降序
explain select id,age,phone from tb_user order by age asc , phone desc;
Establezca un índice apropiado basado en el campo de clasificación. Al ordenar en varios campos, también se sigue la regla del prefijo más a la izquierda.
Intente utilizar índices de cobertura (los campos consultados se pueden consultar directamente en el índice conjunto sin la necesidad de realizar consultas de retorno de tabla).
Clasificación de varios campos, uno en orden ascendente y otro en orden descendente. En este momento, es necesario prestar atención a las reglas al crear el índice conjunto (ASC/DESC).
Si la clasificación de archivos es inevitable, puede aumentar adecuadamente el tamaño del búfer de clasificación sort_buffer_size (predeterminado 256k) al ordenar grandes cantidades de datos.
Cuarto, agrupar por optimización
Los índices se pueden utilizar para mejorar la eficiencia durante las operaciones de agrupación.
Al realizar operaciones de agrupación, el uso de índices también satisface la regla del prefijo más a la izquierda.
#执行分组操作,根据profession字段分组
explain select profession , count(*) from tb_user group by profession;
#创建索引
Create index idx_user_pro_age_sta on tb_user(profession , age , status);
#执行分组操作,根据profession字段分组
explain select profession , count(*) from tb_user group by profession;
#执行分组操作,根据profession字段分组
explain select profession , count(*) from tb_user group by profession,age;
Cinco, optimización de límites
Un problema común y muy problemático es el límite 2000000,10. En este momento, MySQL necesita ordenar los primeros 2000010 registros y solo devuelve 2000000-2000010 registros. Los otros registros se descartan y el costo de la clasificación de consultas es muy alto.
Idea de optimización: al realizar consultas de paginación generales, el rendimiento se puede mejorar creando un índice de cobertura, que se puede optimizar agregando un índice de cobertura y una subconsulta.
explain select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = aid;
Seis, optimización del conteo
Varios usos de contar
recuento (clave principal) : el motor InnoDB recorrerá toda la tabla, extraerá el valor de identificación de la clave principal de cada fila y lo devolverá a la capa de servicio. Una vez que la capa de servicio obtiene la clave principal, la acumula directamente por fila (la clave principal no puede ser nula).
recuento (campo) : No existe ninguna restricción nula: el motor InnoDB recorrerá toda la tabla, extraerá los valores de campo de cada fila y los devolverá a la capa de servicio, que determinará si es nulo o no, y el conteo será acumulado.
Existe una restricción no nula: el motor InnoDB recorrerá toda la tabla, extraerá los valores de campo de cada fila, los devolverá a la capa de servicio y los acumulará directamente por fila.
count (1) : el motor InnoDB recorre toda la tabla, pero no toma valores. Para cada fila devuelta, la capa de servicio le pone un número "1" y lo acumula directamente por fila.
count (*) : El motor InnoDB no elimina todos los campos, sino que los optimiza específicamente sin tomar valores, y la capa de servicio cuenta directamente las filas.
Si se ordena según la eficiencia, recuento (campo) recuento (identificación de clave principal) < recuento (1) ≈ recuento (*), así que intente utilizar recuento ()
El motor MyISAM almacena el número total de filas de una tabla en el disco, por lo que al ejecutar count (*) devolverá directamente este número, lo cual es muy eficiente;
El motor InnoDB tiene problemas. Cuando ejecuta el recuento (*), necesita leer los datos del motor línea por línea y luego acumular el recuento.
Siete, optimización de la actualización
El bloqueo de fila de InnoDB es un bloqueo para el índice, no para el registro, y el índice no puede fallar; de lo contrario, se actualizará de un bloqueo de fila a un bloqueo de tabla.
Si la condición donde durante el proceso de actualización es que no hay índice, el bloqueo de fila se actualizará a un bloqueo de tabla.
Si la condición donde está indexada, será un bloqueo de fila normal.