
Directorio de artículos
- Arquitectura von Neumann
- Sistema operativo (SO)
- comprensión del proceso
-
estado del proceso
-
proceso prioritario
-
Variables de entorno
-
espacio de direcciones de proceso
-
Cola de programación de procesos del kernel Linux2.6
1. Arquitectura de von Neumann

- Dispositivos de entrada : incluidos teclado, mouse, escáner, tableta de escritura, etc.
- Memoria : solo memoria.
- Dispositivo de salida : monitor, impresora, etc.
- Unidad central de procesamiento (CPU): contiene unidades aritméticas, controladores, registros, etc.
Aviso:
- El hardware como los discos no se considera almacenamiento.
- Los dispositivos de entrada y los dispositivos de salida se denominan colectivamente periféricos, por lo que el hardware como los discos son periféricos.
-
Independientemente del caché, la CPU aquí solo puede leer y escribir memoria, y no puede acceder a periféricos (dispositivos de entrada o salida).
-
Los periféricos (dispositivos de entrada o salida) necesitan ingresar o emitir datos y solo pueden escribir o leer en la memoria.
-
Todos los dispositivos sólo pueden manejar la memoria directamente.
CPU>Memoria>Periféricos
Cuando los datos se extraen del periférico, primero se cargan en la memoria y luego se entregan a la CPU para su procesamiento. Después del procesamiento, el resultado se devuelve a la memoria y luego al periférico. Esto acelerará la velocidad general. Si no hay memoria, entonces la interacción entre la CPU y los periféricos reducirá la velocidad general en comparación con no agregar memoria.
Primero, ingrese el mensaje que envió a su amigo desde el teclado. En este momento, el periférico tiene datos. Luego, el periférico carga los datos en la memoria y la CPU los procesa. Luego, el resultado del procesamiento se devuelve al periférico y luego se envían los datos. Después de recibir el mensaje, la tarjeta de red en la computadora host de la otra parte carga los datos de la tarjeta de red en la memoria, luego deja que la CPU los procese, los devuelve a la memoria después del procesamiento y finalmente devuelve el datos al periférico de visualización del ordenador.
en conclusión:
- En la arquitectura von Neumann, la CPU no interactúa directamente con los periféricos, sino a través de la memoria.
- La arquitectura von Neumann mejora la eficiencia de toda la máquina.
2. Sistema operativo (SO)
Sistema operativo: Es un software que gestiona la interacción entre software y hardware.
La esencia de la gestión es gestionar los datos. El sistema operativo gestiona este hardware mediante el uso de estructuras que almacenan información diversa sobre los atributos de este hardware. Debido a que Linux está escrito en lenguaje C, las estructuras de estructura se utilizan para registrar las propiedades de los recursos, se organizan mediante estructuras de datos y algoritmos relevantes y luego se administran.
La siguiente figura es un diagrama esquemático de la arquitectura de software y hardware de la computadora:

Conceptos de funciones de biblioteca y llamadas al sistema
- Desde una perspectiva de desarrollo, el sistema operativo aparecerá como un todo para el mundo exterior, pero expondrá algunas de sus interfaces para el desarrollo de la capa superior. Esta parte de la interfaz proporcionada por el sistema operativo se denomina llamada al sistema.
- En términos de uso, las funciones de las llamadas al sistema son relativamente básicas y los requisitos para los usuarios son relativamente altos. Por lo tanto, los desarrolladores reflexivos pueden encapsular adecuadamente algunas llamadas al sistema para formar bibliotecas. Con las bibliotecas, es muy beneficioso para los usuarios o desarrolladores de nivel superior. llevar a cabo el desarrollo secundario.
Resumir:hardware de gestión informática1. Para describir, use la estructura de estructura.2. Organícelo mediante listas vinculadas u otras estructuras de datos eficientes.
3. Comprensión del proceso
1. Conceptos básicos:
Concepto : una instancia de ejecución de un programa, un programa en ejecución, etc.Perspectiva del kernel : la entidad responsable de asignar los recursos del sistema (tiempo de CPU, memoria).
Proceso = estructura de PCB correspondiente + código y datos correspondientes
2. Proceso: comprensión de la estructura de PCB
La información del proceso se coloca en una estructura de datos llamada bloque de control de proceso, que puede entenderse como una colección de atributos del proceso.En el sistema operativo se llama PCB (bloque de control de procesos), y en el sistema operativo Linux, el PCB es: task_struct ttask_struct es una estructura de datos del kernel de Linux, se carga en la RAM (memoria) y contiene información del proceso. Esta estructura se utiliza principalmente para registrar atributos relacionados con el proceso.
3.task_struct clasificación de contenido
- Identificador : un identificador único que describe este proceso y se utiliza para distinguir otros procesos.
- Estado : Estado de la tarea, código de salida, señal de salida, etc.
- Prioridad : Prioridad relativa a otros procesos.
- Contador de programa : la dirección de la siguiente instrucción que se ejecutará en el programa.
- Punteros de memoria : incluidos punteros al código del programa y datos relacionados con el proceso, así como punteros a bloques de memoria compartidos con otros procesos.
- Datos de contexto : los datos en los registros del procesador cuando se ejecuta el proceso [ejemplo de licencia, agregue la figura de CPU, registro].
- Información de estado de E/S : incluye solicitudes de E/S mostradas, dispositivos de E/S asignados al proceso y una lista de archivos utilizados por el proceso.
- Información contable: puede incluir el tiempo total del procesador, el número total de relojes utilizados, límites de tiempo, cuentas contables, etc.
- otra información
4. Organizar y visualizar procesos.
Proceso de organización: se puede encontrar en el código fuente del kernel. Todos los procesos que se ejecutan en el sistema se almacenan en el kernel en forma de listas vinculadas task_struct.
Ver proceso: la información del proceso se puede ver a través de la carpeta del sistema /proc

Por ejemplo: para obtener la información del proceso con PID 1, necesita ver la carpeta /proc/1.

La mayor parte de la información del proceso también se puede obtener utilizando herramientas a nivel de usuario como top y ps.
Utilice ps aux solo para mostrar toda la información del proceso y utilice el comando grep para especificar información relacionada con un determinado proceso.

Para terminar un proceso, puede usar ctrl+c, o puede usar kill -9 para terminar el pid de un proceso. Ctrl+c esencialmente envía la señal No. 9.
5. Obtener el identificador del proceso mediante llamadas al sistema.
1. Obtenga el identificador del proceso padre-hijo mediante getpid y getppid.
identificación del proceso (PID)Identificación del proceso principal (PPID)

#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid:%d\n",getpid());
printf("ppid:%d\n",getppid());
return 0;
}

2. Utilice fork para obtener el identificador del proceso.

Fork es una interfaz de llamada al sistema, que crea principalmente un proceso hijo. Esta función se ejecuta una vez y tiene dos valores de retorno. El proceso padre devuelve el pid del proceso hijo y el proceso hijo devuelve 0. Entre ellos, se comparte el código de los procesos de padre e hijo, y los datos de cada uno abren espacio y tienen una copia privada (se utiliza copia en escritura)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
pid_t id=fork();
if(id==0){
//子进程
while(1){
printf("I am child process,我的pid是:%d,我的父进程是:%d\n",getpid(),getppid());
sleep(1);
}
}
else{
//父进程
while(1){
printf("I am father process,我的pid是:%d,我的父进程是:%d\n",getpid(),getppid());
sleep(1);
}
}
return 0;
}
![]()

Porque después de la bifurcación, los procesos padre e hijo compartirán código y se produce la copia en escritura. Desde después de la bifurcación, los valores de retorno son diferentes y se pueden ejecutar diferentes bloques de código. Después de la bifurcación, el orden en el que proceden los procesos padre e hijo lo determina el programador de la CPU y el algoritmo de programación correspondiente.
Función bifurcación, ¿por qué regresa dos veces? enlaces relacionados
4. Estado del proceso
1. Estado del proceso en Linux
- Estado de ejecución de R (en ejecución): no significa que el proceso definitivamente se esté ejecutando, indica que el proceso se está ejecutando o en la cola de ejecución.
- S estado de sueño (dormir): significa que el proceso está esperando a que se complete el evento (el sueño aquí a veces se denomina sueño interrumpible).
Código fuente del estado del proceso en el kernel de Linux:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
2. Bloqueo de procesos y suspensión de procesos
Bloqueo de procesos: cuando un proceso en ejecución no puede ejecutarse porque está esperando que ocurra un evento, abandona el procesador y entra en un estado bloqueado. Hay muchos tipos de eventos que causan el bloqueo del proceso, como esperar a que se complete la E/S, solicitar un búfer que no se puede satisfacer, esperar una señal, etc.

El proceso se bloquea: cuando no hay memoria suficiente, el sistema operativo reemplaza el código y los datos del proceso en el disco de manera adecuada y el estado del proceso se denomina suspendido.

3. Ver el estado del proceso
comando ps aux/ps axjComandos comunes de visualización del estado del proceso:
- ps auxiliar | cabeza -1 && ps aux | grep PID
- ps ajx |head -1 && ps ajx |grop especificación PID


- 1) ps a muestra todos los programas en el terminal actual, incluidos los programas de otros usuarios.
- 2) ps -A muestra todos los programas.
- 3) Cuando ps c enumera programas, muestra el nombre real de la instrucción de cada programa, sin incluir la ruta, los parámetros o la identificación de los servicios residentes.
- 4) ps -e El efecto de este parámetro es el mismo que especificar el parámetro "A".
- 5) Cuando ps e enumera programas, muestra las variables de entorno utilizadas por cada programa.
- 6) ps f usa caracteres ASCII para mostrar la estructura de árbol y expresar la relación entre programas.
- 7) ps -H muestra una estructura de árbol, que indica la relación entre programas.
- 8) ps -N muestra todos los programas, excepto los programas en la terminal que ejecutan el comando ps.
- 9) ps s utiliza el formato de señal del programa para mostrar el estado del programa.
- 10) Cuando ps S enumera programas, incluye información de subrutina interrumpida.
- 11) ps -t especifica el número de terminal y enumera el estado de los programas que pertenecen al terminal.
- 12) ps u muestra el estado del programa en un formato orientado al usuario.
- 13) ps x muestra todos los programas, no distinguidos por terminal.
- ps muestra los procesos en ejecución actuales, grep los busca y ps aux muestra todos los procesos y su estado.
4. Procesos frontal y posterior
Proceso de primer plano:
De forma predeterminada, cada proceso que iniciamos es un proceso en primer plano. Recibe información del teclado y envía su salida a la pantalla.
Cuando un proceso se ejecuta en primer plano, no podemos ejecutar ningún otro comando (iniciar cualquier otro proceso) en la misma línea de comando porque la línea de comando no está disponible hasta que el programa finaliza su proceso.
![]()
Se puede ver desde aquí que + indica que el proceso es un proceso en primer plano.
proceso entre bastidores:
Utilice kill -19 PID para pausar el proceso
Utilice kill -18 PID para continuar ejecutando el proceso

Antes de la suspensión:

Cuando está en pausa:

Continuar la ejecución:

De la imagen de arriba, podemos saber que el proceso ha cambiado de un proceso en primer plano a un proceso en segundo plano. Tenga en cuenta que el proceso en segundo plano no se puede detener con Ctrl + C. Solo puede usar Kill -9 para finalizar el proceso.
5. Clasificación del estado del proceso
1.Estado de funcionamiento (R)
Código de estado de prueba R:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int a=0;
while(1){
a=1+1;
}
return 0;
}

Aquí podemos encontrar que el estado del proceso es R+, lo que significa que el proceso es un proceso en primer plano que se está ejecutando o en la cola de ejecución.
2. Estado de sueño (S)
Código de estado de prueba S:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("I am running\n");
printf("我的pid是:%d\n",getpid());
sleep(10);
return 0;
}

De la figura anterior, podemos saber que el proceso está en el estado S, lo que significa que el proceso está esperando que se complete el evento. Estar en un estado de sueño ligero puede ser interrumpido o terminado en cualquier momento, por lo que este estado puede denominarse estado de sueño interrumpible.
3. Estado de hibernación del disco (D)
A veces también llamado estado de sueño ininterrumpido (sueño ininterrumpido), el proceso en este estado generalmente espera el final de IO.

Por lo tanto, este estado indica que un proceso está en un estado de suspensión profunda, el sistema operativo no liberará el proceso y solo podrá restaurarlo cuando el proceso se despierte automáticamente.
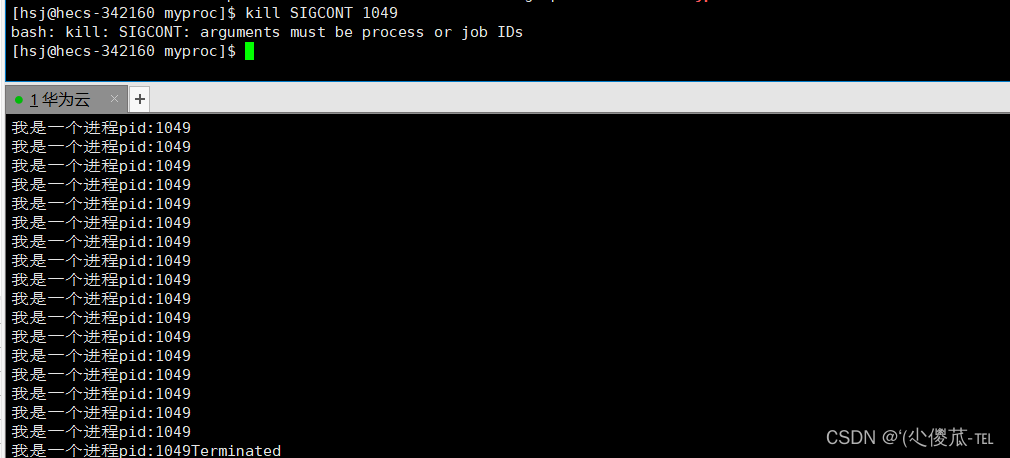
4. Estado de parada (T)
Un proceso (T) se puede detener enviando una señal SIGSTOP al proceso. El proceso suspendido puede continuar ejecutándose enviando la señal SIGCONT .
Código de estado de prueba T:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while(1){
printf("我是一个进程pid:%d\n",getpid());
}
return 0;
}
5.Estado de muerte(X)
Este estado es solo un estado de devolución; no verá este estado en la lista de tareas. Cuando el proceso padre lee el resultado devuelto del proceso hijo, el proceso hijo libera inmediatamente los recursos. El estado de muerte es de muy corta duración y casi imposible de capturar mediante comandos PS.
6. Estado zombi (Z)
- Los zombis son un estado bastante especial. Un proceso zombie ocurre cuando un proceso sale y el proceso padre (usando la llamada al sistema wait()) no lee el código de retorno de la salida del proceso hijo.
- Un proceso zombie permanece en la tabla de procesos en un estado terminado y está esperando que el proceso principal lea el código de estado de salida.
- Por lo tanto, mientras el proceso hijo salga, el proceso padre seguirá ejecutándose, pero el proceso padre no lee el estado del proceso hijo y el proceso hijo entra en el estado Z.
Código de estado de prueba Z:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("I am running...\n");
pid_t id=fork();
if(id==0){
//child
int cnt=5;
while(cnt){
printf("I am child,我的pid是:%d,我的ppid:%d,cnt:%d\n",getpid(),getppid(),--cnt);
sleep(1);
}
printf("child quit\n");
exit(1);
}
else{
while(1){
printf("I am father,我的pid是:%d,我的ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
return 0;
}
Aquí podemos ver que el proceso hijo cambia al estado Z +, que se llama estado zombie, y el proceso se llama proceso zombie.
Peligros del proceso zombie
- El estado de salida del proceso debe mantenerse, porque necesita decirle al proceso que se preocupa por él (el proceso padre) qué tan Pero si el proceso padre nunca lee, el proceso hijo siempre estará en el estado Z.
- Mantener el estado de salida en sí requiere mantenimiento de datos, y también es la información básica del proceso, por lo que se almacena en task_struct (PCB), en otras palabras estado Z nunca saldrá y la PCB siempre se mantendrá.
- Ese proceso padre ha creado muchos procesos hijos, pero si no se reciclan, ¿provocará un desperdicio de recursos de memoria? Debido a que el objeto de estructura de datos en sí ocupa memoria, piense en definir una variable de estructura (objeto) en C para abrir espacio .
- pérdida de memoria
7. Estado de huérfano
Si el proceso padre sale temprano, el proceso hijo sale más tarde y entra en Z. ¿Qué se debe hacer?
- Si el proceso padre sale primero, el proceso hijo se denomina "proceso huérfano".
- El proceso huérfano es adoptado por el proceso init número 1. Por supuesto, debe ser reciclado por el proceso init.
Pruebe el código de estado huérfano:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork");
return 1;
}
else if(id == 0){//child
printf("I am child, pid : %d\n", getpid());
sleep(10);
}else{//parent
printf("I am parent, pid: %d\n", getpid());
sleep(3);
exit(0);
}
return 0;
}

Aquí podemos encontrar que el proceso hijo es adoptado por el proceso No. 1. Este estado se llama estado huérfano y el proceso se llama proceso huérfano.
5. Prioridad del proceso
concepto basico:
- El orden en que se asignan los recursos de la CPU se refiere a la prioridad del proceso.
- Los procesos con mayor prioridad tienen derechos de ejecución prioritarios. Configurar prioridades de procesos es muy útil para Linux en un entorno multitarea y puede mejorar el rendimiento del sistema.
- También puede ejecutar el proceso en una CPU designada. De esta manera, programar procesos sin importancia en una determinada CPU puede mejorar en gran medida el rendimiento general .
1. Ver los procesos del sistema

- UID: representa la identidad del ejecutor
- PID: representa el nombre en clave de este proceso.
- PPID: representa de qué proceso se deriva este proceso, es decir, el nombre en clave del proceso principal
- PRI: representa la prioridad con la que se puede ejecutar este proceso, cuanto menor sea el valor, antes se ejecutará.
- NI: representa el gran valor de este proceso.
2. PRI y NI
- PRI es la prioridad del proceso, o en términos simples, el orden en que la CPU ejecuta los programas. Cuanto menor sea el valor, mayor será la prioridad del proceso. El valor predeterminado es 80.
- NI es el valor agradable del que estamos hablando, que representa el valor modificado de la prioridad con la que se puede ejecutar el proceso.
- Cuanto menor sea el valor PRI, más rápido se ejecutará. Después de agregar el valor agradable, el PRI se convertirá en: PRI(nuevo)=PRI(antiguo)+nice
- De esta forma, cuando el valor agradable es negativo, el valor de prioridad del programa será menor, es decir, su prioridad será mayor y más rápido se ejecutará.
- Por lo tanto, ajustar la prioridad del proceso en Linux significa ajustar el valor agradable del proceso, el rango de valores agradable es de -20 a 19, con un total de 40 niveles.
Nota: El buen valor de un proceso no es la prioridad del proceso. No son un concepto, pero el buen valor del proceso afectará el cambio de prioridad del proceso. Se puede entender que el buen valor son los datos modificados de la prioridad del proceso.
3. Comando para ver la prioridad del proceso.
arribaDespués de ingresar a la parte superior, presione "r" -> ingrese el PID del proceso -> ingrese el valor agradable
4. Otros conceptos sobre procesos
- Competencia: hay muchos procesos del sistema, pero solo hay una pequeña cantidad de recursos de CPU, o incluso uno, por lo que existe competencia entre procesos. Para completar las tareas de manera eficiente y competir por los recursos relacionados de manera más razonable, se da prioridad
- Independencia: la operación multiproceso requiere el uso exclusivo de varios recursos y las operaciones multiproceso no interfieren entre sí.
- Paralelismo: varios procesos se ejecutan en varias CPU al mismo tiempo, lo que se denomina paralelismo.
- Concurrencia: varios procesos utilizan la conmutación de procesos en una CPU para avanzar en varios procesos dentro de un período de tiempo, lo que se denomina concurrencia.
5. Cambio de proceso
El cambio de procesos es una función básica que deberían tener los sistemas operativos multitarea y multiusuario actuales.
Para controlar la ejecución de un proceso, el sistema operativo debe tener la capacidad de suspender el proceso que se ejecuta en la CPU y reanudar la ejecución de un proceso previamente suspendido, este comportamiento se denomina cambio de proceso, cambio de tarea o cambio de contexto. En otras palabras, el cambio de proceso significa retirar el procesador del proceso en ejecución y luego dejar que el proceso en espera ocupe el procesador. Lo que se dice aquí acerca de recuperar el procesador de un proceso es esencialmente encontrar un lugar para almacenar los datos intermedios almacenados en el registro del procesador por el proceso, liberando así el registro del procesador para que lo utilicen otros procesos. Entonces, ¿dónde se pueden almacenar los datos intermedios del proceso en ejecución suspendido? Por supuesto, este lugar debería ser la pila privada del proceso.
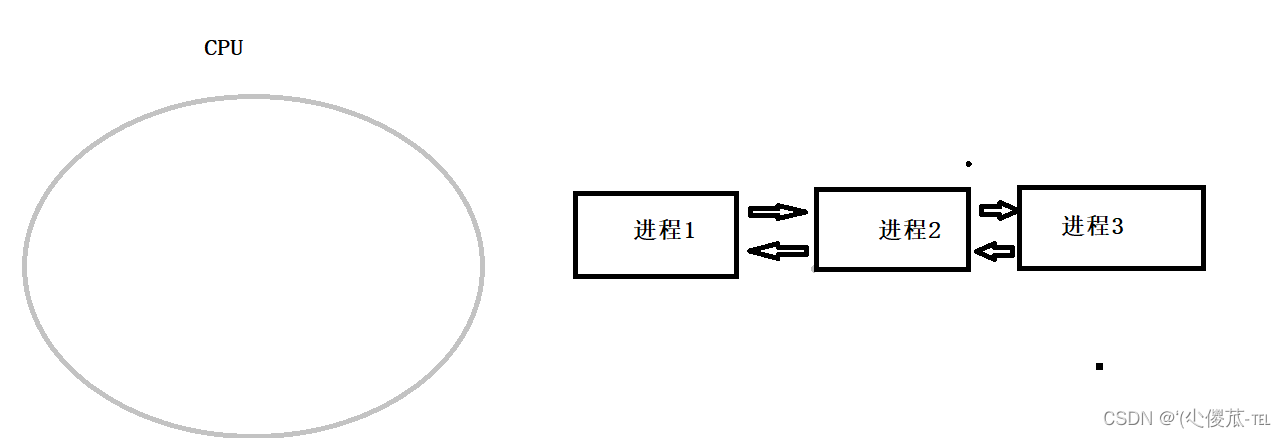
Por ejemplo: cuando se ejecuta el proceso 1, el contenido de los registros en la CPU está relacionado con el proceso 1. Debido a la concurrencia, cuando la CPU cambia de ejecutar el proceso 1 a ejecutar el proceso 2, los registros originalmente pertenecen al contenido del proceso. 1 debe guardarse, porque el proceso 2 también utilizará estos registros y sobrescribirá el contenido original. Actualmente se puede considerar que el contenido de los registros relacionados con el proceso 1 se copia al PCB. Este proceso se denomina protección de contexto en el cambio de procesos. Cuando la CPU cambia de ejecutar el proceso 2 a ejecutar el proceso 1 nuevamente, el contenido de los registros relacionados con el proceso 2 también estará protegido, y el contenido protegido por contexto en la PCB del proceso 1 se restaurará en los registros de la CPU, sobrescribiendo Eliminar el contenido que pertenece al proceso 2, y luego continúa la ejecución en la posición ejecutada anteriormente. Esta posición es leída de los datos recuperados por el registro eip (puntero de PC). Este proceso se llama recuperación de contexto en cambio de proceso.
Intervalo de tiempo: (intervalo de tiempo), también conocido como "cuántico" o "intervalo de procesador", es un período microscópico de tiempo de CPU asignado por el sistema operativo de tiempo compartido a cada proceso en ejecución (en el kernel de preferencia es: el tiempo desde que el proceso comienza a ejecutarse hasta que se adelanta). Supongamos que este tiempo es de 10 ms. Cuando el proceso 1 se ejecuta durante 10 ms, los datos temporales generados por el proceso 1 estarán protegidos por contexto, es decir, el contenido de los registros de la CPU se copiará en la PCB correspondiente. Luego comience a ejecutar el proceso 2. Cuando el proceso 2 se ejecute durante 10 ms, el contexto del proceso 2 también estará protegido, luego se restaurará el contexto del proceso 1 y se continuará ejecutando el proceso 1. Esto se repite hasta que los dos procesos fin. El contenido de los registros de la CPU sólo pertenece al proceso que se está ejecutando actualmente. Dado que la velocidad de ejecución de la CPU es muy rápida y el tiempo para ejecutar un proceso es muy corto, el resultado de múltiples procesos es que se ejecutan juntos. El período de tiempo que se ejecuta un proceso es el intervalo de tiempo.
6. Variables ambientales
- Las variables de entorno generalmente se refieren a algunos parámetros utilizados en el sistema operativo para especificar el entorno operativo del sistema operativo. Por ejemplo: cuando escribimos código C/C++ y vinculamos, nunca sabemos a qué variables dinámicas y estáticas estamos vinculando. Donde está la biblioteca, aún puede vincular con éxito y generar un programa ejecutable, la razón es que existen variables de entorno relevantes para ayudar al compilador a encontrarla.
- Las variables de entorno suelen tener algún propósito especial y suelen tener propiedades globales en el sistema.
1. Variables de entorno comunes
- RUTA: especifique la ruta de búsqueda para el comando
- INICIO: especifique el directorio de trabajo de inicio del usuario (es decir, el directorio predeterminado cuando el usuario inicia sesión en el sistema Linux)
SHELL: El Shell actual, su valor suele ser /bin/bash.
2. Cómo ver las variables de entorno
echo $PATH //PATH: el nombre de la variable de entornoentorno | grep RUTA

3. Comandos relacionados con variables de entorno.
- 1. echo: muestra el valor de una variable de entorno
- 2. exportar: establecer una nueva variable de entorno
- 3. env: muestra todas las variables de entorno
- 4. desarmado: borrar variables de entorno
- 5. set: muestra variables de shell y variables de entorno definidas localmente
4. Cómo se organizan las variables de entorno

5. Cómo obtener variables de entorno a través del código.
Imprime el tercer parámetro de la línea de comando.
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
//我们给main函数传递的argc、argv[]参数,其实是传递的命令行中输入的程序名和选项!
//char *env[]存储的是环境变量的地址
int i = 0;
for(; env[i]; i++)
{
printf("%s\n", env[i]);
}
return 0;
}

Obtenido a través del entorno variable de terceros.
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{
//libc中定义的全局变量environ指向环境变量表,environ没有包含在任何头文件中,所以在使用时 要用extern声明
extern char** environ;
for(int i=0;environ[i];i++)
{
printf("%s\n",environ[i]);
}
return 0;
}
Obtener o configurar variables de entorno a través de llamadas al sistema
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n", getenv("PATH"));
return 0;
}7. Espacio de direcciones de proceso
Código de espacio de direcciones de prueba:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>
#include<malloc.h>
int g_val=100;
int g_unval;
int main(int argc,char* argv[],char* envp[])
{
printf("code addr:%p\n",main);
char* str = "hello world";
printf("read only addr:%p\n",str);
printf("init addr:%p\n",&g_val);
printf("uninit addr:%p\n",&g_unval);
int* p = malloc(10);
printf("heap addr:%p\n",p);
printf("stack addr:%p\n",&str);
printf("stack addr:%p\n",&p);
int i=0;
for(;i<argc;i++)
{
printf("args addr:%p\n",argv[i]);
}
i=0;
while(envp[i])
{
printf("env addr:%p\n",envp[i]);
i++;
}
return 0;
}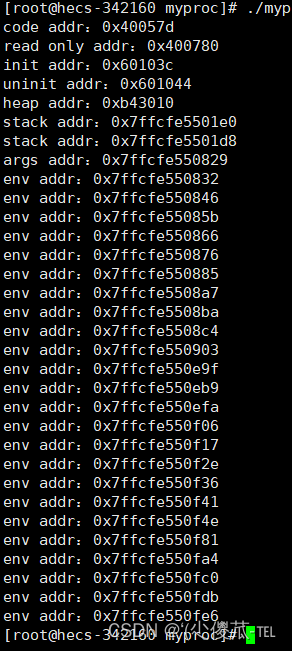
Como puede verse en la imagen de arriba, las direcciones se imprimen de menor a mayor. Luego se verificó la distribución del espacio de direcciones.
1. Comprender profundamente el espacio de direcciones del proceso.
Primero mire un fragmento de código:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val=100;
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
int flag = 0;
while(1)
{
printf("我是子进程:%d, ppid: %d, g_val: %d, &g_val: %p\n\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
flag++;
if(flag == 5)
{
g_val=200;
printf("我是子进程,全局数据我已经改了,用户你注意查看!\n");
}
}
}
else
{
//parent
while(1)
{
printf("我是父进程:%d, ppid: %d, g_val: %d, &g_val: %p\n\n", getpid(), getppid(), g_val, &g_val);
sleep(2);
}
}
}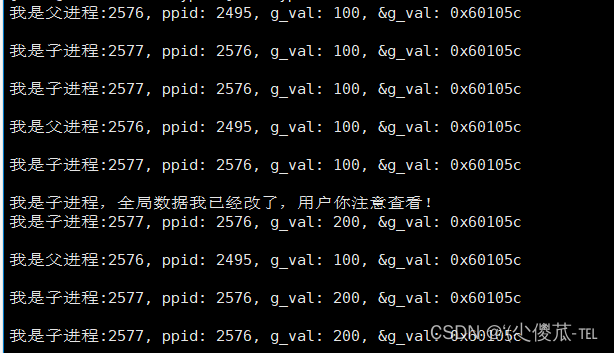
g_val todos apuntan a la misma dirección, ¿por qué se imprimen dos valores diferentes?
En primer lugar, el valor y la dirección que imprimimos antes de que la variable global no haya cambiado son los mismos. Cuando g_val cambia en el proceso hijo, podemos encontrar que g_val no ha cambiado en el proceso padre. En este momento las direcciones son todas iguales. Es comprensible en base a la independencia entre procesos. La dirección es la misma. Hay dos valores bajo la misma dirección física. Esto es poco probable, lo que indica que la dirección en este momento no es una dirección física real.
En Linux, este tipo de dirección se denomina dirección lineal (dirección virtual), a veces también llamada dirección lógica. A nivel de lenguaje, las direcciones que llamamos son direcciones virtuales. Las direcciones físicas son básicamente gestionadas por el sistema operativo.
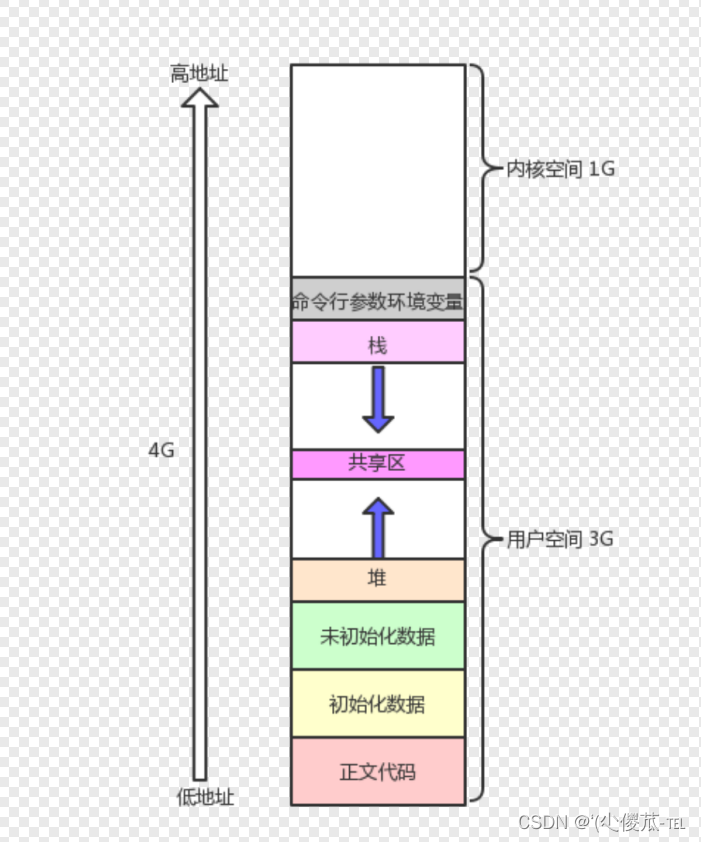
2. División de áreas de espacio de direcciones de proceso
El "espacio de direcciones virtuales del usuario" incluye las siguientes áreas:
① Segmento de código
② Segmento de datos
③ Segmento de datos no inicializados
④ Segmento de código de biblioteca dinámica, segmento de datos, segmento de datos no inicializados;
⑤ Memoria de montón:
mallocbrkvmallocmemoria asignada dinámicamente y aplicada a través de funciones como;⑥ Memoria de pila: almacena variables locales y pila de llamadas de funciones;
⑦ Área de mapeo de memoria: asigne el archivo
mmapal "área de mapeo de memoria" del "espacio de direcciones virtuales" a través de la función;⑧ Variables y parámetros de entorno: las variables de entorno y la información de configuración de parámetros para la ejecución del programa se almacenan en la parte inferior de la pila;
En el sistema operativo Linux cada proceso ocupa 4G en exclusiva. Al programar, debido a los recursos limitados de la CPU, un proceso solo se puede designar para ejecutar los recursos correspondientes en un momento determinado a través de intervalos de tiempo.
Hay un puntero mm en cada proceso que apunta a la estructura mm_struct. Esta estructura divide el espacio de 4GB.
El siguiente es el código fuente subyacente de mm_struct en Linux:
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
u32 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES
/* Base adresses for compatible mmap() */
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
#endif
unsigned long task_size; /* size of task vm space */
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd;
/**
* @mm_users: The number of users including userspace.
*
* Use mmget()/mmget_not_zero()/mmput() to modify. When this drops
* to 0 (i.e. when the task exits and there are no other temporary
* reference holders), we also release a reference on @mm_count
* (which may then free the &struct mm_struct if @mm_count also
* drops to 0).
*/
atomic_t mm_users;
/**
* @mm_count: The number of references to &struct mm_struct
* (@mm_users count as 1).
*
* Use mmgrab()/mmdrop() to modify. When this drops to 0, the
* &struct mm_struct is freed.
*/
atomic_t mm_count;
atomic_long_t nr_ptes; /* PTE page table pages */
#if CONFIG_PGTABLE_LEVELS > 2
atomic_long_t nr_pmds; /* PMD page table pages */
#endif
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
struct user_namespace *user_ns;
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and migrate
* pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads setting pte_numa */
int numa_scan_seq;
#endif
#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)
/*
* An operation with batched TLB flushing is going on. Anything that
* can move process memory needs to flush the TLB when moving a
* PROT_NONE or PROT_NUMA mapped page.
*/
bool tlb_flush_pending;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
};3. La conexión entre el espacio de direcciones del proceso y la memoria física.
Cuando un archivo de programa ejecutable en el disco ha pasado por cuatro procesos: preprocesamiento, compilación, ensamblaje y vinculación, durante este proceso el compilador formará la dirección del archivo de acuerdo con la distribución del espacio de direcciones del proceso, lo que se denomina lógica. Dirección, también llamada dirección virtual. De esta manera, el archivo se carga desde el disco a la memoria y la memoria le asignará espacio para almacenar el código, pero la dirección en el código es una dirección virtual. Luego, el sistema operativo asigna la dirección virtual a la dirección física a través de una tabla de páginas.
De esta manera, ¿podemos responder a la situación anterior en la que los valores de g_val son diferentes?
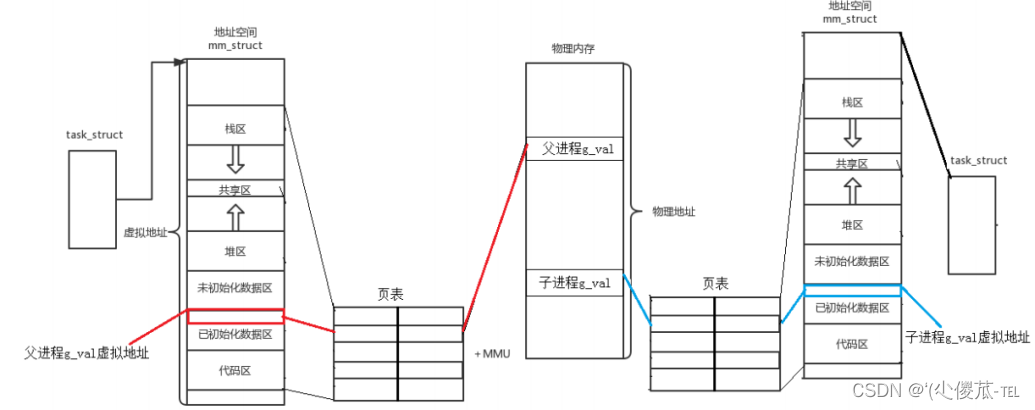
- En el espacio de direcciones del proceso de los procesos padre e hijo, hay una variable global g_val en la misma dirección, que se asigna en la memoria física a través de sus respectivas tablas de páginas.
- Cada vez que esta variable global cambia, el valor en los procesos padre e hijo es el mismo, por lo que los dos procesos solo necesitan asignarse a un espacio físico en la memoria física. Cuando el proceso hijo cambia su variable global, el valor de la variable en los dos procesos es diferente, por lo que ya no se puede asignar a un espacio físico. Entonces, en este momento, el sistema operativo copiará las variables globales originalmente en el espacio físico, las colocará en otro espacio y actualizará la dirección física del nuevo espacio físico en la tabla de páginas del proceso hijo. En este momento, en los procesos padre e hijo, las direcciones virtuales de las variables globales en sus respectivos espacios de direcciones de proceso siguen siendo las mismas, pero las direcciones físicas correspondientes en sus respectivas tablas de páginas son diferentes.
- Durante el proceso de apelación, cuando el proceso hijo cambia la variable global, el sistema operativo copia el valor en el espacio físico original en el nuevo espacio, este comportamiento se denomina copia en escritura.
4. La importancia de la existencia del espacio de direcciones del proceso.
- 1. Se identifica cualquier acceso o mapeo ilegal al sistema operativo y se finaliza el proceso, protegiendo así de manera efectiva la memoria física. Debido a que el sistema operativo crea y mantiene el espacio de direcciones y la tabla de páginas, cualquiera que quiera utilizar el espacio de direcciones y la tabla de páginas para mapear debe acceder a ellos bajo la supervisión del sistema operativo. Esto protege todos los datos legales en la memoria física, así como todos los procesos y datos válidos relevantes del kernel.
- 2. Debido a la existencia de espacio de direcciones y asignación de tablas de páginas, los datos del disco se pueden cargar arbitrariamente en la memoria física. Dado que el módulo de gestión de memoria y el módulo de gestión de procesos están desacoplados, se garantiza la independencia del proceso. Debido a la existencia del espacio de direcciones, cuando la capa superior solicita espacio, en realidad lo solicita en el espacio de direcciones. El sistema operativo adopta una estrategia de asignación retrasada para mejorar la eficiencia de toda la máquina. Cuando realmente accede al espacio de direcciones físicas, se ejecuta el algoritmo de administración correspondiente para ayudarlo a solicitar memoria y construir una relación de mapeo de tablas de páginas.
- 3. En teoría, la memoria física se puede cargar arbitrariamente, es precisamente debido a la existencia de la tabla de páginas que la dirección virtual en el espacio de direcciones se puede asignar a través de la tabla y la dirección física. Es precisamente por la existencia del espacio de direcciones que cada proceso cree que tiene 4 GB de espacio, y cada área está ordenada, cada proceso se asigna a diferentes áreas a través de la tabla de páginas para lograr la independencia del proceso.
8. Cola de programación de procesos del kernel Linux2.6

Una CPU tiene una cola de ejecución
Si tiene varias CPU, debe considerar el problema del equilibrio de carga de la cantidad de procesos.prioridad
- Prioridad ordinaria: 100~139 (Todos tenemos prioridades ordinarias. ¡Piense en el rango del valor agradable y puede corresponderle!)
- Prioridad en tiempo real: 0~99 (no importa)
cola de actividad
- Todos los procesos cuyo intervalo de tiempo aún no ha finalizado se colocan en esta cola según su prioridad.
- nr_active: ¿Cuántos procesos en ejecución hay en total?
- cola [140]: Un elemento es una cola de procesos. Los procesos con la misma prioridad se ponen en cola y se programan de acuerdo con las reglas FIFO. Por lo tanto, el subíndice de la matriz es la prioridad.
- A partir de esta estructura, ¿cuál es el proceso de selección del proceso más adecuado?
- 1. Recorra la cola [140] comenzando desde la siguiente tabla 0
- 2. Busque la primera cola que no esté vacía, que debe ser la cola con mayor prioridad.
- 3. Obtenga el primer proceso en la cola seleccionada, comience a ejecutarlo y ¡la programación se completará!
- 4. ¡La complejidad temporal de atravesar la cola [140] es constante! ¡Pero sigue siendo demasiado ineficiente!
- mapa de bits [5]: un total de 140 prioridades y un total de 140 colas de procesos. Para mejorar la eficiencia de la búsqueda de colas no vacías, se pueden usar 5 * 32 bits para indicar si la cola está vacía. De esta manera ¡La eficiencia de la búsqueda se puede mejorar enormemente!
Cola de caducidad
- La estructura de la cola caducada y la cola activa son exactamente la misma
- Los procesos colocados en la cola de caducidad son todos procesos cuyos intervalos de tiempo se han agotado.
- Una vez procesados todos los procesos de la cola activa, se vuelve a calcular el intervalo de tiempo de los procesos de la cola caducada.
puntero activo y puntero caducado
- El puntero activo siempre apunta a la cola activa.
- El puntero caducado siempre apunta a la cola caducada.
- Sin embargo, habrá cada vez menos procesos en la cola activa y cada vez más procesos en la cola caducada, porque el proceso siempre existirá cuando expire su intervalo de tiempo.
- No importa, siempre que el contenido del puntero activo y el puntero caducado se puedan intercambiar en el momento adecuado, ¡es equivalente a tener un nuevo lote de procesos activos!