Documentos de referencia:
https://blog.csdn.net/github_37882837/article/details/90672881
http://c.biancheng.net/view/880.html
https://blog.csdn.net/qq_22613757/article/details/80853391
https://www.iteye.com/topic/816268
Prefacio
El contenido de archivos y sistemas de archivos en Internet está relativamente fragmentado, por lo que solo estoy moviendo ladrillos aquí. Después de leer los artículos de varios grandes dioses, publíquelos de una manera que entienda para referencia futura.
Uno, sistema de archivos
1. Concepto de sistema de archivos
El sistema de archivos es un mecanismo para organizar datos y metadatos en un dispositivo.
El sistema de archivos que usa cada sistema operativo es diferente, por ejemplo, los sistemas operativos de Microsoft anteriores a WINDOWS98 usan el sistema de archivos FAT (FAT16) y las versiones posteriores a WINDOWS 2000 usan el sistema de archivos NTFS. El sistema de archivos ortodoxo de Linux es EXT2.
Formatear el disco duro solo borra los datos en el disco duro. De hecho, no lo es. El sistema de archivos se escribe en el disco duro durante el proceso de formateo. Debido a que los diferentes sistemas operativos tienen diferentes formas de administrar archivos en el sistema (los atributos y permisos establecidos para los archivos no son exactamente los mismos), por lo tanto, para que el disco duro almacene de manera efectiva los datos del archivo en el sistema actual, el disco duro debe estar Formatee de modo que utilice el mismo (o similar) formato de sistema de archivos que el sistema operativo.
2. Nivel del sistema de archivos

Figura 1 Jerarquía del sistema de archivos de Linux
De arriba a abajo, se divide principalmente en capa de usuario, capa VFS, capa de sistema de archivos, capa de controlador de bloque general, capa de controlador y capa física
1) Aplicación: La capa de usuario superior son los diversos programas que utilizamos a diario. Las interfaces necesarias son principalmente la creación, eliminación, apertura, cierre, escritura, lectura de archivos, etc.
2) Interfaz de llamada al sistema (SCI): Encapsule la interfaz proporcionada por el sistema de archivos virtual.
3) Capa VFS: sistema de archivos virtual, abstrae diferentes sistemas de archivos y proporciona una interfaz API unificada para aplicaciones de nivel superior. El espacio de usuario no necesita preocuparse por diferentes API en diferentes sistemas de archivos. Después de que la interfaz de llamada del sistema encapsule la API unificada proporcionada por VFS, los usuarios pueden usar las llamadas al sistema SCI para operar diferentes sistemas de archivos.
4) Capa del sistema de archivos: diferentes sistemas de archivos implementan estas funciones de VFS y las registran en VFS a través de punteros. Por lo tanto, las operaciones del usuario se transfieren a varios sistemas de archivos a través de VFS.
5) Capa de controlador de bloque general: Oculte los detalles de diferentes dispositivos de hardware y proporcione una interfaz de operación IO unificada para el kernel; si modifica esta capa, afectará a todos los sistemas de archivos, ya sea ext3, ext4 u otros sistemas de archivos.
6) Controlador de dispositivo: capa de controlador de disco, el controlador de disco convierte los comandos de lectura y escritura en el disco en sus propios protocolos, o comandos personalizados que pueden ser reconocidos por su propio hardware y los envía al controlador de disco.
7) Disco físico: Capa física del disco, lee y escribe datos físicos en medios de disco.
3. Estructura de almacenamiento del sistema de archivos
Tome el sistema de archivos EXT4 como ejemplo. El sistema de archivos EXT4 utiliza principalmente la tabla de descriptores de superbloques y grupos de bloques en el grupo de bloques 0, y hay copias de seguridad redundantes de la tabla de descriptores de superbloques y grupos de bloques en algunos otros grupos de bloques específicos. Si no hay una copia de seguridad redundante en el grupo de bloques, el grupo de bloques comenzará con el mapa de bits del bloque de datos. Cuando el disco formateado se convierte en un sistema de archivos Ext4, mkfs asignará bloques de datos de la tabla GDT reservados ("bloques GDT de reserva") detrás de la tabla de descriptores del grupo de bloques para una futura expansión del sistema de archivos. Inmediatamente después del bloque de datos de la tabla GDT reservado está el mapa de bits del bloque de datos y el mapa de bits de la tabla de inodos, estos dos mapas de bits representan respectivamente el uso del bloque de datos y la tabla de inodos en el grupo de bloques, después del bloque de datos de la tabla de inodos. Es el bloque de datos que almacena el archivo. Entre estos varios bloques, el superbloque, GDT, mapa de bits de bloque y mapa de bits de nodo de índice son los metadatos de todo el sistema de archivos. Por supuesto, la tabla de inodo también son los metadatos del sistema de archivos, pero la tabla de nodos de inodo está relacionada con el archivo. Para la correspondencia uno a uno, prefiero tratar el nodo de índice como los metadatos del archivo, porque cuando el sistema de archivos está realmente formateado, en realidad no hay datos en las otras tablas de inodo, excepto por las diez o más que ya se usaron. La tabla de inodo que no se asignará hasta que se cree el archivo correspondiente, y el sistema de archivos escribirá la información de inodo relacionada con el archivo en la tabla de inodo.
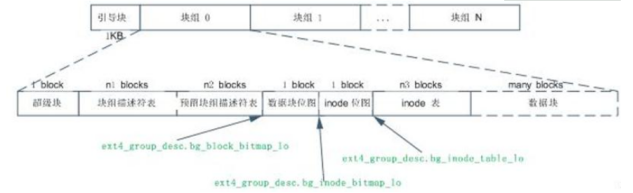
Figura 2 Diseño de disco estándar del sistema de archivos EXT4
1) Superbloque: El primer bloque del sistema de archivos se denomina superbloque (registra la información de todo el sistema de archivos), este bloque almacena la información estructural del propio sistema de archivos. Por ejemplo, el superbloque registra el número de bloques de datos, el número de inodos, el número de bloques no utilizados, las funciones admitidas y la información de gestión.
2) Descriptor de grupo rápido: Cada grupo de bloques tiene un descriptor de grupo correspondiente para describirlo. Todos los descriptores de grupo forman una tabla de descriptores de grupo, que puede ocupar varios bloques de datos. El descriptor de grupo es equivalente al superbloque de cada grupo de bloques. Una vez que se destruye un descriptor de grupo, todo el grupo de bloques quedará inutilizable, por lo que la tabla de descriptores de grupo también se respalda en cada grupo de bloques como un superbloque. Para evitar daños. El bloque ocupado por la tabla de descriptores de grupo es el mismo que el bloque de datos ordinario, que se transfiere al caché de bloques durante el uso.
3) Mapa de bits de bloques de datos y mapa de bits de inodo: El mapa de bits de bloques de datos rastrea el uso de bloques de datos en el grupo de bloques. El mapa de bits de Inode rastrea el uso de Inode en el grupo de bloques. Cada mapa de bits tiene un bloque de datos y cada bit usa 0 o 1 para indicar el uso del bloque de datos en un grupo de bloques o el inodo en la tabla de inodo. Si el tamaño de un bloque de datos es 4 KB, ese bloque de mapa de bits puede representar el uso de 4 * 1024 * 8 bloques de datos, que también es el número máximo de bloques de datos en un solo grupo de bloques. Se puede calcular que el tamaño de un grupo de bloques es de 128 MB. Por supuesto, un bloque de mapa de bits también puede representar el uso de 4 * 1024 * 8 inodos, pero de hecho, incluso si un grupo de bloques está lleno de archivos, no se utilizarán tantos inodos, porque básicamente no hay inodos en el sistema real. Todos los tamaños de archivo son menores o iguales al tamaño de 1 bloque de datos. De hecho, el número de inodos en un grupo de bloques se determina en el descriptor del grupo de bloques. Este valor también se verá durante el proceso de formateo del sistema de archivos. Si recuerda correctamente, probablemente sea cada 4 u 8 datos Block asigna un espacio de inodo.
4) La tabla de nodos contiene una lista, que enumera todos los números de inodo del sistema de archivos correspondiente. Cuando un usuario busca o accede a un archivo, el sistema Linux busca el número de inodo correcto a través de la tabla de inodo. Después de encontrar el número de inodo, los comandos relacionados pueden acceder al inodo y realizar los cambios apropiados.
4. La conexión y la diferencia entre vínculos físicos y vínculos flexibles
Enlace físico y enlace flexible (también llamado enlace simbólico, enlace flexible o enlace simbólico). La vinculación resuelve el intercambio de archivos para el sistema Linux y también brinda beneficios como ocultar rutas de archivos, aumentar la seguridad de los permisos y ahorrar almacenamiento.
Si un número de inodo corresponde a varios nombres de archivo, estos archivos se denominan enlaces físicos. En otras palabras, un vínculo físico es el uso de múltiples alias al mismo archivo (vea la Figura 3, un vínculo físico de alias es el archivo, tienen un inodo común). El vínculo físico se puede crear mediante el vínculo de comando o ln. Lo siguiente es crear un enlace duro al archivo oldfile.
enlazar archivo antiguo archivo nuevo 或
en archivo antiguo archivo nuevo
Dado que los enlaces físicos son archivos con el mismo número de inodo pero diferentes nombres de archivo, los enlaces físicos tienen las siguientes características:
1) Los archivos tienen el mismo inodo y bloque de datos;
2) Solo se pueden crear archivos existentes;
3) No es posible crear vínculos físicos entre sistemas de archivos;
4) No se pueden crear directorios, solo archivos;
5) La eliminación de un archivo vinculado no afecta a otros archivos con el mismo número de inodo.
Un vínculo suave es diferente de un vínculo físico. Si el contenido almacenado en el bloque de datos del usuario de un archivo es señalado por el nombre de la ruta de otro archivo, el archivo es un vínculo suave. Un enlace flexible es un archivo normal, pero el contenido del bloque de datos es un poco especial. El enlace suave tiene su propio número de inodo y el bloque de datos del usuario (ver Figura 3 ). Por lo tanto, la creación y uso de enlaces suaves no tiene muchas restricciones similares a los enlaces físicos:
1) El enlace flexible tiene sus propios atributos y permisos de archivo;
2) Cree enlaces suaves a archivos o directorios inexistentes;
3) El enlace suave puede cruzar el sistema de archivos;
4) Se pueden crear enlaces suaves para archivos o directorios;
5) Al crear un enlace flexible, el número de enlaces i_nlink no aumentará;
6) La eliminación de un enlace suave no afecta al archivo señalado, pero si se elimina el archivo original al que se apunta, el enlace suave relacionado se denomina enlace inactivo (es decir, enlace colgante, si se recrea el archivo de ruta señalada, el enlace inactivo se puede restaurar Es un enlace suave normal).
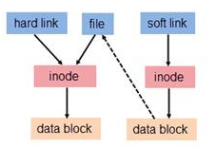
Figura 3 Acceso al enlace suave
Cree un enlace flexible: ln -s oldfile newfile.soft
El impacto de copiar archivos, mover archivos y eliminar archivos en el inodo:
1) Copiar archivos es crear archivos y dar cuenta de Inode y Block.
El proceso de creación del archivo es: primero busque un Inode vacío, escriba una nueva tabla de Inode, cree un directorio, corresponda al nombre del archivo y escriba el contenido del archivo en el bloque;
2) Hay dos situaciones para mover archivos:
Mueva archivos en el mismo sistema de archivos, cree un nuevo nombre de archivo y correspondencia de inodo, es decir, escriba información en el Directorio, luego elimine la información anterior en el Directorio, actualice CTIME (tiempo de archivo), otra información como inodo, etc. Sin impacto;
Al mover archivos en diferentes sistemas de archivos, primero busque un inodo vacío, escriba en una nueva tabla de inodo, cree una relación correspondiente en el directorio, escriba el contenido del archivo en el bloque y cambie el CTIME al mismo tiempo.
3) Eliminar un archivo es esencialmente reducir el recuento de enlaces. Cuando el recuento de enlaces es 0, significa que se puede usar el inodo y el bloque se marca como modificable, pero los datos en el bloque no se eliminan a menos que haya nuevos datos para usar. Este bloque.
5. Sistemas de archivos comunes compatibles con Linux

Ver los tipos de sistemas de archivos admitidos por el sistema Linux actual en el dispositivo: cat / proc / filesystems
2. Documentos
1. Estructura de almacenamiento de archivos
Sistema de archivos ortodoxo de Linux (como ext2, ext3) Un archivo se compone de entradas de directorio, inodos y bloques de datos.
Entrada de directorio : incluye nombre de archivo y número de nodo de inodo.
Inode : también conocido como nodo de índice de archivo, es la ubicación de almacenamiento de la información básica del archivo y la ubicación de almacenamiento del puntero del bloque de datos.
Bloque de datos : donde se almacena el contenido específico del archivo.
El sistema de archivos ortodoxo de Linux (como ext2, 3, 4, etc.) divide el disco duro en bloques de directorio, bloques de tabla de inodos y bloques de datos. Un archivo consta de una entrada de directorio, un inodo y un bloque de área de datos. Inode contiene los atributos del archivo (como atributos de lectura y escritura, propietario, etc. y punteros a bloques de datos), y el bloque del área de datos es el contenido del archivo. Al visualizar un archivo, primero averigüe los atributos del archivo y los puntos de almacenamiento de datos de la tabla de inodo y luego lea los datos del bloque de datos.
La estructura de almacenamiento de archivos es aproximadamente la siguiente:

Figura 4 Estructura de almacenamiento de archivos
La estructura de la entrada del directorio es la siguiente (la entrada del directorio de cada archivo se almacena en el contenido del archivo del directorio al que pertenece el archivo modificado):
![]()
Figura 5 Estructura de elementos de directorio
La estructura de inodo del archivo es la siguiente (la información del archivo contenida en el inodo se puede ver a través del nombre de archivo stat):
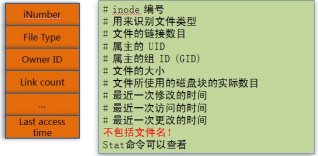
Figura 6 estructura de inodo
Lo anterior solo refleja la estructura general, el propio sistema de archivos de Linux está en constante evolución. Pero el concepto anterior básicamente no ha cambiado. Y también hay grandes diferencias entre los sistemas de archivos ext2, ext3 y ext4. Si quieres entender, puedes verificar la introducción de sistemas de archivos especiales.
2. ¿Cómo accede el sistema de archivos a los archivos?
1) Según el nombre del archivo, busque el número de inodo (número de nodo de inodo) correspondiente al archivo a través de la relación correspondiente en el Directorio;
2) Busque en la tabla Inode y encuentre el nodo de inodo correspondiente al número de inodo (el nodo almacena la dirección del bloque de datos correspondiente);
3) Leer el bloque de datos correspondiente de acuerdo con el puntero del bloque de datos en el nodo de inodo;
Nota :
1) Aquí hay un contenido importante, que es Directorio, no es un directorio como solemos decir, sino una lista que registra el número de Inode correspondiente a un nombre de archivo / directorio.
2) El nodo inodo no almacena el nombre del archivo del archivo, porque el nombre del archivo son los datos del directorio donde se encuentra el archivo, por lo que se almacenará en el bloque de datos del directorio de nivel superior.
3. Tipo de archivo
Los principales tipos de archivos en Linux son:
1) Archivos ordinarios: metacódigo en lenguaje C, script SHELL, archivo ejecutable binario, etc. Dividido en texto sin formato y binario.
2) Archivo de directorio: Directorio, el único lugar para almacenar archivos.
3) Archivos vinculados: archivos que apuntan al mismo archivo o directorio.
4) Archivos especiales: relacionados con los periféricos del sistema, generalmente en / dev. Dividido en dispositivos de bloque y dispositivos de personajes.
Puede utilizar los comandos ls -l, file, stat para ver el tipo de archivo y otra información relacionada.
a: archivo normal, que es f:
d: directorio, archivo de directorio
b: dispositivo de bloque, archivo de dispositivo de bloque, admite acceso aleatorio en unidades de bloques
c: dispositivo de caracteres, archivo de dispositivo de caracteres, admite acceso en unidades de caracteres
número principal: número de dispositivo principal, utilizado para indicar el modelo del dispositivo y luego determinar el controlador que se cargará
número menor: número de dispositivo menor, utilizado para identificar diferentes dispositivos del mismo tipo
l: enlace simbólico, archivo de enlace simbólico
p: tubería, tubería con nombre
s: socket, archivo de socket