Tabla de contenido
2. El propósito de diseñar el sistema operativo
5. Obtenga el identificador del proceso a través de la llamada al sistema
6. Crear un proceso a través de una llamada al sistema - bifurcación
1. Arquitectura Von Neumann
Nuestras computadoras comunes, como las notebooks. La mayoría de nuestras computadoras poco comunes, como los servidores, obedecen al sistema von Neumann.
El siguiente es un diagrama de la arquitectura de von Neumann:

Las computadoras que conocemos están compuestas de dispositivos de entrada , memoria , unidades aritméticas , controladores y dispositivos de salida .
- Unidad de entrada: incluye teclado, mouse, escáner, tableta, tarjeta de red, disco, etc.;
- Unidad Central de Procesamiento (CPU): Contiene calculadoras y controladores, etc.;
- Unidad de salida: pantalla, tarjeta de red, impresora, etc.
Se deben enfatizar algunos puntos sobre von Neumann:
- El almacenamiento aquí se refiere a la memoria;
- Independientemente de la situación del caché, la CPU aquí puede y solo puede leer y escribir memoria, y no puede acceder a los periféricos (dispositivos de entrada o salida);
- Los periféricos (dispositivos de entrada o salida) solo se pueden escribir o leer en la memoria si desean ingresar o generar datos;
- En una palabra, todos los dispositivos solo pueden tratar directamente con la memoria .
Nuestros datos deben cargarse primero desde el disco a la memoria, luego leerlos y calcularlos mediante la CPU, cargar los resultados calculados en la memoria nuevamente y, finalmente, escribir los datos en el disco desde la memoria y entregarnos los datos a través de el dispositivo de salida.
¿Por qué la CPU no puede acceder directamente a los periféricos?
Debido a que los dispositivos de entrada y salida se denominan periféricos, los periféricos son generalmente muy lentos, como los discos, en comparación con la memoria, su velocidad es muy lenta, pero la velocidad de cálculo de la CPU es realmente muy rápida. Es como si la velocidad de lectura del disco fuera muy lenta, pero la velocidad de cálculo de la CPU es muy rápida, pero la velocidad general aún está dominada por la velocidad de lectura del disco, por lo que la eficiencia general está dominada por el exterior.
La comprensión de von Neumann no debe detenerse en el concepto, sino profundizar en la comprensión del flujo de datos del software. Explique, desde el momento en que inicia sesión en QQ y comienza a chatear con un amigo, el proceso del flujo de datos. Desde el momento en que abre la ventana, comience a enviarle un mensaje, al proceso de flujo de datos después de que reciba el mensaje. ¿Qué pasa si el archivo se envía en qq?

Primero lea la información del teclado y cárguela en la memoria , luego envíe los datos de la memoria al dispositivo de salida (tarjeta de red) a través de una serie de operaciones, y luego envíe los datos al dispositivo de entrada del amigo (tarjeta de red) a través de una serie de operaciones de red, la computadora del amigo lee los datos del dispositivo de entrada a la memoria y luego envía la información a la computadora del amigo a través del dispositivo de salida (pantalla).
2. Sistema operativo
1. Concepto
Cualquier sistema informático contiene una colección básica de programas llamada sistema operativo (SO). En términos generales, el sistema operativo incluye:
- Kernel (gestión de procesos, gestión de memoria, gestión de archivos, gestión de controladores);
- Otros programas (como bibliotecas de funciones, programas de shell, etc.).
Un sistema operativo es una pieza de software que administra los recursos de hardware y software. ¿Por qué el sistema operativo gestiona el software y el hardware?
Porque el sistema operativo necesita administrar bien los recursos de software y hardware, y debe proporcionar a los usuarios un buen entorno de ejecución (seguro, estable, eficiente, rico en funciones, etc.).
La esencia de la gestión del sistema operativo : primero describir, luego organizar .
- Descripción: describe varios datos a través de la estructura struct ;
- Organización : organice y administre datos a través de estructuras de datos eficientes, como listas vinculadas.
En una computadora, el sistema operativo es equivalente a nuestro administrador , el controlador de hardware es equivalente a nuestro ejecutor y el software es nuestro administrado .
En primer lugar, el sistema operativo no confía en nadie , así como somos usuarios de los bancos, muchas veces vamos al banco a ahorrar dinero, pero ¿los bancos confían en nosotros? Para evitar la destrucción maliciosa por parte de algunos de los usuarios y causar daños al sistema operativo, el sistema operativo no expone todas sus funciones sino que utiliza llamadas al sistema para acceder al sistema operativo. Debido a que el costo de usar llamadas al sistema puede ser alto, algunas personas llevaron a cabo un desarrollo de software secundario sobre esta base, lo que resultó en una interfaz gráfica , un shell y un conjunto de herramientas .
Llamadas al sistema y funciones de biblioteca
- Desde la perspectiva del desarrollo, el sistema operativo aparecerá como un todo para el mundo exterior, pero expondrá parte de su interfaz para el desarrollo de nivel superior.Esta parte de la interfaz proporcionada por el sistema operativo se denomina llamada al sistema;
- En el uso de llamadas al sistema, las funciones son relativamente básicas y los requisitos para los usuarios son relativamente altos. Por lo tanto, los desarrolladores interesados pueden encapsular correctamente algunas llamadas al sistema para formar una biblioteca. Con una biblioteca, es muy beneficioso para los usuarios de nivel superior. o Los desarrolladores llevan a cabo el desarrollo secundario.
2. El propósito de diseñar el sistema operativo
- Interactuar con el hardware y administrar todos los recursos de hardware y software;
- Proporcionar un buen entorno de ejecución para los programas de usuario (aplicaciones).
La estructura del sistema informático está en capas y, por lo general, no es posible omitir una determinada capa.

3. Proceso
1. Conceptos básicos
- Conceptos de libros de texto: una instancia de ejecución de un programa, un programa en ejecución, etc.;
- Punto de vista del kernel: Actúa como la entidad que asigna los recursos del sistema (tiempo de CPU, memoria).
Cuando abrimos el administrador de tareas, encontraremos que estos archivos ejecutables en ejecución son todos procesos.

2. Describa el proceso-PCB
- La información del proceso se coloca en una estructura de datos llamada bloque de control del proceso , que puede entenderse como una colección de atributos del proceso ;
- El libro de texto se llama PCB (bloque de control de procesos), y el PCB bajo el sistema operativo Linux es: task_struct
Un tipo de task_struct-PCB
- La estructura que describe el proceso en Linux se llama task_struct;
- task_struct es una estructura de datos del kernel de Linux que se carga en la RAM (memoria) y contiene información del proceso.

Cuando el sistema operativo primero describe nuestro proceso y luego lo organiza, primero creará una estructura con los atributos comunes de nuestro programa, y luego creará un objeto de estructura para cada uno de nuestros procesos.Este es el proceso descrito primero. A continuación, nuestro sistema operativo utilizará estructuras de datos características (como listas enlazadas) para organizar nuestros objetos de estructura, que es el proceso posterior a la organización. Entonces la gestión de procesos de nuestro sistema operativo se convertirá en la gestión de estructuras de datos específicas.
Por lo tanto, proceso = estructura de datos del kernel relacionada con el proceso + código y datos del proceso actual.
clasificación del contenido de la estructura task_
- Identificador: describa el identificador único de este proceso, que se utiliza para distinguir otros procesos;
- Estado: estado de la tarea, código de salida, señal de salida, etc.;
- Prioridad: Prioridad relativa a otros procesos;
- Contador de programa: la dirección de la siguiente instrucción a ejecutar en el programa;
- Punteros de memoria: incluidos punteros al código del programa y datos relacionados con el proceso, así como punteros a bloques de memoria compartidos con otros procesos;
- Datos de contexto: los datos en los registros del procesador cuando se ejecuta el proceso [ejemplo de suspensión de estudios, agregar cuadros de CPU, registros];
- Información de estado de E/S: incluidas las solicitudes de E/S mostradas, los dispositivos de E/S asignados al proceso y una lista de archivos utilizados por el proceso;
- Información de facturación: puede incluir la suma del tiempo del procesador, la suma de los relojes utilizados, el límite de tiempo, el número de cuenta de facturación, etc.;
- otra información.
3. Proceso de organización
Se puede encontrar en el código fuente del kernel. Todos los procesos que se ejecutan en el sistema se almacenan en el kernel en forma de lista enlazada task_struct.
4. Ver proceso y terminar
Para ver la información básica de un proceso, podemos usar el comando ps -axj para listar la información del proceso que usa el sistema actual;
Primero prueba un fragmento de código:
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
printf("我是一个进程!\n");
sleep(1);
}
return 0;
}
Ingrese el comando para ver el proceso, de la siguiente manera:
Ingrese ps -axj | head -1 && ps -axj | grep "test" para obtener el encabezado y el proceso con test.

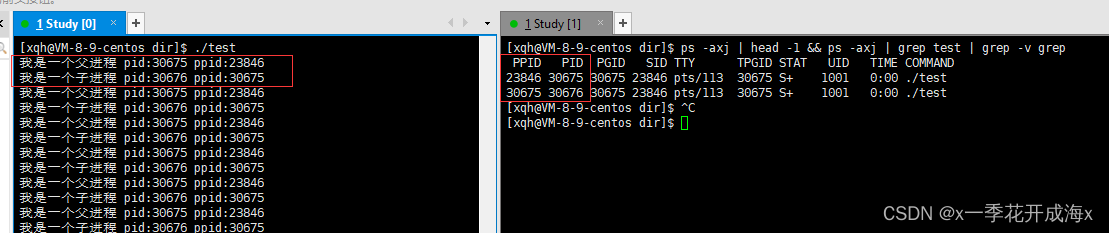
Aquí también necesitamos explicar un concepto que es el concepto de PID y PPID, que hace referencia al número de identificación del proceso en el sistema operativo, es decir, el identificador del proceso . Cada vez que se abre un programa en el sistema operativo, se crea un ID de proceso o PID. Por supuesto, PPID es el número de identificación del proceso principal.
proceso de matanza
Hay dos métodos: el primero es Ctrl + c para finalizar el proceso por la fuerza, y el segundo es: en forma de comando, matar -9 PID, especifique el proceso de destino para matar.

Aquí recomiendo usar el segundo método.
5. Obtenga el identificador del proceso a través de la llamada al sistema
- identificación del proceso (PID);
- Identificación del proceso principal (PPID).
#include<iostream>
#include<sys/types.h>
#include<unistd.h>
using namespace std;
int main()
{
pid_t t = fork();
if (t == 0)
{
while (1)
{
cout << "我是一个子进程" << " pid:" << getpid() << " ppid:" << getppid() << endl;
sleep(1);
}
}
else if (t > 0)
{
while (1)
{
cout << "我是一个父进程" << " pid:" << getpid() << " ppid:" << getppid() << endl;
sleep(1);
}
}
return 0;
}
6. Crear un proceso a través de una llamada al sistema - bifurcación
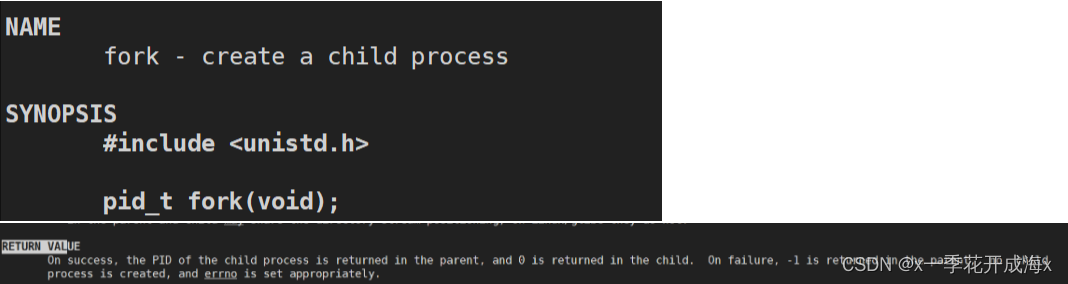
- Corre man fork para saber fork;
- fork tiene dos valores de retorno;
- Intercambio de código de proceso padre-hijo, cada espacio abierto para datos, una copia privada (usando copia en escritura);
- Después de la bifurcación, si se usa generalmente para ramificar.
 Puede ver que la función fork() es muy especial. Después de crear con éxito un proceso secundario, en realidad hay dos valores de retorno. Devuelve el pid del proceso secundario al proceso principal, devuelve 0 al proceso secundario y devuelve: 1 si la creación falla.
Puede ver que la función fork() es muy especial. Después de crear con éxito un proceso secundario, en realidad hay dos valores de retorno. Devuelve el pid del proceso secundario al proceso principal, devuelve 0 al proceso secundario y devuelve: 1 si la creación falla.
Cómo entender los dos valores de retorno
Cuando fork() quiere devolver el valor, de hecho, el trabajo de crear un proceso secundario dentro de la función se ha completado. En este momento, ya hay dos procesos, y los dos procesos continúan ejecutando la siguiente declaración. Después de ejecutar fork(), naturalmente habrá un valor de retorno, por lo que nos parece que hay dos valores de retorno. De hecho, cuando recibimos el valor de retorno, activamos la copia en escritura (la copia realista es cuando la operación El sistema detecta que el proceso secundario tiene una operación de escritura. El sistema operativo asignará el espacio físico correspondiente al proceso secundario), y los rets aparentemente idénticos se almacenan en espacios diferentes.
7. Estado del proceso
- R running status (running): No significa que el proceso deba estar ejecutándose, indica que el proceso está ejecutándose o en cola de ejecución;
- S estado dormido (sleeping): significa que el proceso está esperando que se complete el evento (dormir aquí a veces se denomina sueño interrumpible (suspensión interrumpible));
- El estado de suspensión del disco D (suspensión del disco) a veces se denomina estado de suspensión ininterrumpida (suspensión ininterrumpida), el proceso en este estado generalmente espera el final de IO;
- Estado de parada T (detenido): un proceso puede detenerse (T) enviando una señal SIGSTOP al proceso. El proceso suspendido se puede reanudar enviando la señal SIGCONT;
- X estado muerto (muerto): este estado es solo un estado de retorno, no verá este estado en la lista de tareas.
El comando ps -axj es para ver la información del proceso
(1) Estado de ejecución R (running): No significa que el proceso deba estar ejecutándose, indica que el proceso está ejecutándose o en la cola de ejecución;
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while (1)
{
;
}
return 0;
}
Al ejecutar, verifique que el estado del proceso sea R+, lo que indica que se está ejecutando.

¿Qué significa el signo + después de él?
Aquí + significa que el proceso se está ejecutando en primer plano. Cuando usamos ctrl+c, el proceso se puede terminar. Si no escribimos +, significa que el proceso se está ejecutando en segundo plano. En este momento, ctrl+c no se puede terminar el programa Use el comando matar proceso para terminar.
(2) S estado dormido (sleeping): significa que el proceso está esperando a que se complete el evento (dormir aquí a veces se denomina sueño interrumpible (interruptible sleep));
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
int n = 0;
scanf("%d", &n);
return 0;
}Al ejecutar, verifique que el estado del proceso sea S+, lo que indica que se encuentra en estado de suspensión.

(3) Estado de parada T (detenido): El proceso (T) se puede detener enviando una señal SIGSTOP al proceso. El proceso suspendido se puede reanudar enviando la señal SIGCONT;
kill -l: se pueden mostrar todas las señales, y la señal SIGSTOP corresponde a 19, y la señal SIGCONT corresponde a 18.

Cuando ingresamos kill -19 PID, el proceso se detendrá.

Cuando ingresamos kill -18 PID, el proceso se restaurará.
(4) Estado de muerte: este estado es solo un estado de retorno y es instantáneo. Es posible que no vea este estado en la lista de tareas, porque un proceso se convertirá en un proceso zombi después de morir.
(5) Estado zombi: el estado después de que el proceso muere. Después de que un proceso muere, estará en estado zombi. Si su proceso principal no se recicla, siempre ocupará recursos y causará fugas de memoria.
8. Proceso especial
8.1 Proceso zombi
- El estado Zombie (Zombies) es un estado especial. Se crea un proceso zombi cuando un proceso sale y el proceso principal (usando la llamada al sistema wait()) no lee el código de retorno de la salida del proceso secundario.
- Un proceso zombi permanecerá en la tabla de procesos en un estado terminado y seguirá esperando que el proceso principal lea el código de estado de salida.
- Siempre que el proceso secundario salga, el proceso principal aún se está ejecutando, pero el proceso principal no lee el estado del proceso secundario y el proceso secundario ingresa al estado Z
Demostremos el proceso zombie:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
//子进程
while (1)
{
printf("我是子进程,我的pid :%d,我的ppid: %d\n", getpid(), getppid());
sleep(1);
}
}
else if (id > 0)
{
//父进程
while (1)
{
printf("我是父进程,我的pid :%d,我的ppid: %d\n", getpid(), getppid());
sleep(1);
}
}
else
{
perror("fail");
exit(-1);
}
return 0;
}Cuando se ejecuta, use kill -9 PID para eliminar el proceso secundario en el medio, y el proceso secundario es un proceso zombi en este momento.

8.2 Procesos huérfanos
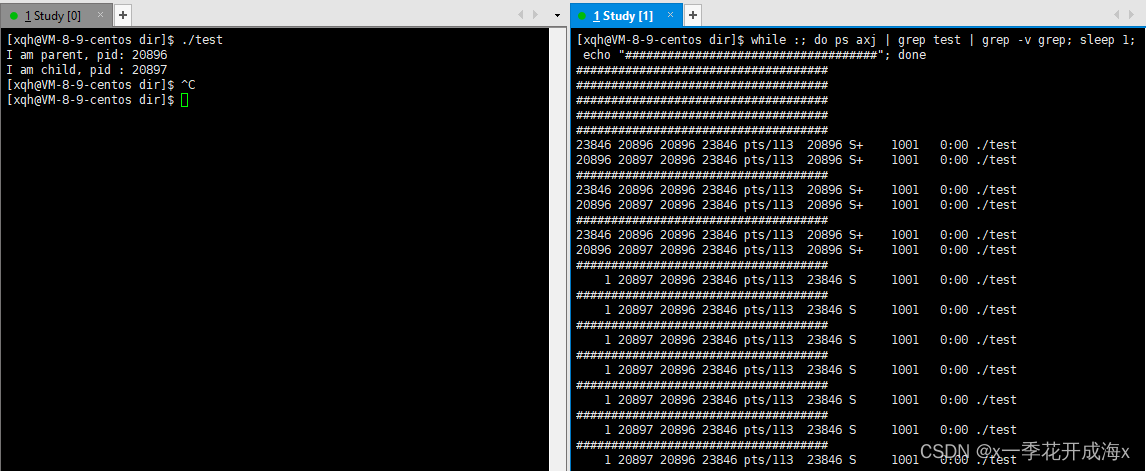
- Si el proceso principal sale antes, el proceso secundario sale más tarde y entra en Z, ¿qué debo hacer?
- El proceso principal sale primero y el proceso secundario se denomina "proceso huérfano".
- El proceso huérfano es adoptado por el proceso init No. 1 y, por supuesto, el proceso init debe reciclarse.
Observe el siguiente fragmento de código, es decir, el proceso principal se ejecuta durante 3 segundos y luego se cierra. En este momento, el proceso secundario es un proceso huérfano.
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fail");
return 1;
}
else if (id == 0)
{
//子进程
printf("I am child, pid : %d\n", getpid());
sleep(10);
}
else
{
//父进程
printf("I am parent, pid: %d\n", getpid());
sleep(3);
exit(-1);
}
return 0;
}Comparación de resultados de ejecución:
Si hay deficiencias en este artículo, puede comentar a continuación y lo corregiré lo antes posible.

Hierros viejos, recuerden darle like y atentos!!!