[Linux] Concepto de hilo
Directorio de artículos
¿Qué es un hilo?
Un hilo es una rama de ejecución dentro de un proceso. Su granularidad de ejecución es más fina que la de un proceso y su costo de programación es menor que el de un proceso.
Los subprocesos son la unidad básica de programación de la CPU y los procesos son las entidades básicas para la asignación de recursos del sistema.
Implementación de subprocesos en el sistema Linux.
En el sistema Linux, la creación de un proceso requiere la creación de task_struct, el espacio de direcciones del proceso y la tabla de páginas, y cargar datos y código en la memoria. Luego, a través del mapeo de la tabla de páginas, se convierte la dirección virtual del espacio de direcciones del proceso. en la dirección de memoria real para acceso a datos y códigos.
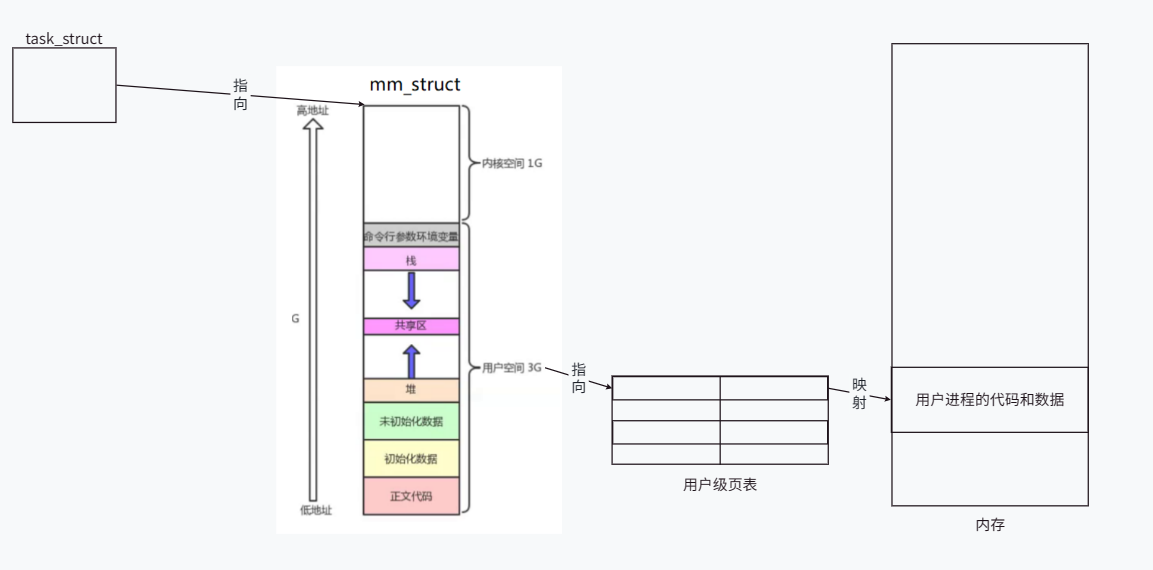
Una vez creado el proceso, el sistema operativo encuentra el espacio de direcciones del proceso a través de task_struct y utiliza el mapeo de la tabla de páginas para completar la ejecución del código.
¿Qué pasa si creamos algunos de estos "procesos": simplemente creamos task_struct y lo apuntamos al espacio de direcciones de proceso de un proceso existente? Debido al espacio de direcciones, estas task_structs también pueden ser llamadas normalmente por el sistema operativo como procesos.
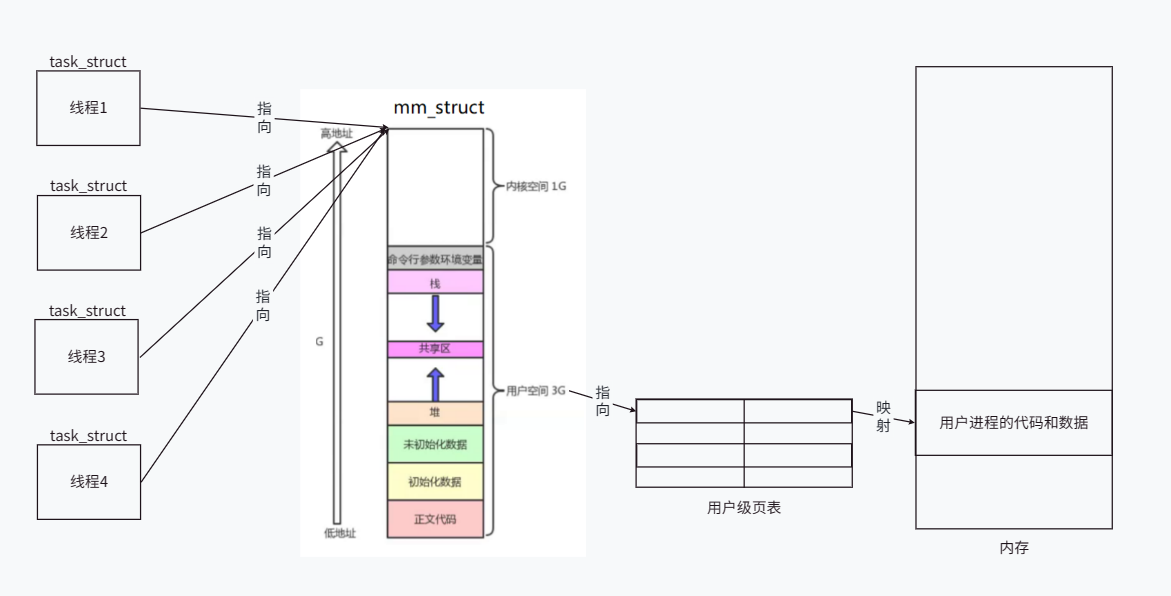
De hecho, simplemente crear task_structs y dejar que apunten al espacio de direcciones de los procesos existentes es la forma en que el sistema operativo Linux implementa subprocesos. El hilo correspondiente a cada task_struct solo ejecuta parte del código del proceso.
Los subprocesos en el sistema Linux tienen las características de pequeña sobrecarga de recursos, comunicación conveniente y alta concurrencia, y son adecuados para implementar programación concurrente y mejorar el rendimiento del sistema, por lo que se denominan procesos livianos (LWP).
ilustrar:
Los diferentes sistemas operativos implementan subprocesos de diferentes maneras. Por ejemplo, la implementación del sistema operativo Windows diseña estructuras de datos de administración y métodos de llamada separados para subprocesos, lo que también conduce a que el bloque de administración de subprocesos ocupe una gran cantidad de memoria y sea incompatible entre diferentes versiones. , mecanismos de sincronización más complejos y otras cuestiones.
- Un hilo es una rama de ejecución dentro de un proceso: el código del proceso se divide en partes y es ejecutado por diferentes hilos. El hilo proporciona la entrada de ejecución para esta parte y el sistema operativo programa cada hilo al mismo tiempo.
- **La granularidad de ejecución de subprocesos es más fina que la de los procesos: **Cada subproceso generalmente solo ejecuta una parte del código del proceso.
- El costo de programación de los subprocesos es menor que el de los procesos: al cambiar de subproceso, no es necesario modificar el espacio de direcciones, la tabla de páginas ni el caché (cargado en consecuencia según el principio de localidad).
Thread es la unidad básica de programación de CPU.
Como hardware, la CPU solo ejecuta mecánicamente los comandos pasados por el sistema operativo. La CPU no puede distinguir entre procesos y subprocesos. Siempre que el sistema operativo pase task_struct y los datos relacionados a la CPU, la CPU ejecutará el código correspondiente de acuerdo con task_struct, independientemente de si solo hay uno en el proceso, todavía hay múltiples flujos de ejecución y la CPU está programada en unidades de task_struct, por lo que los subprocesos son la unidad básica de programación de la CPU.
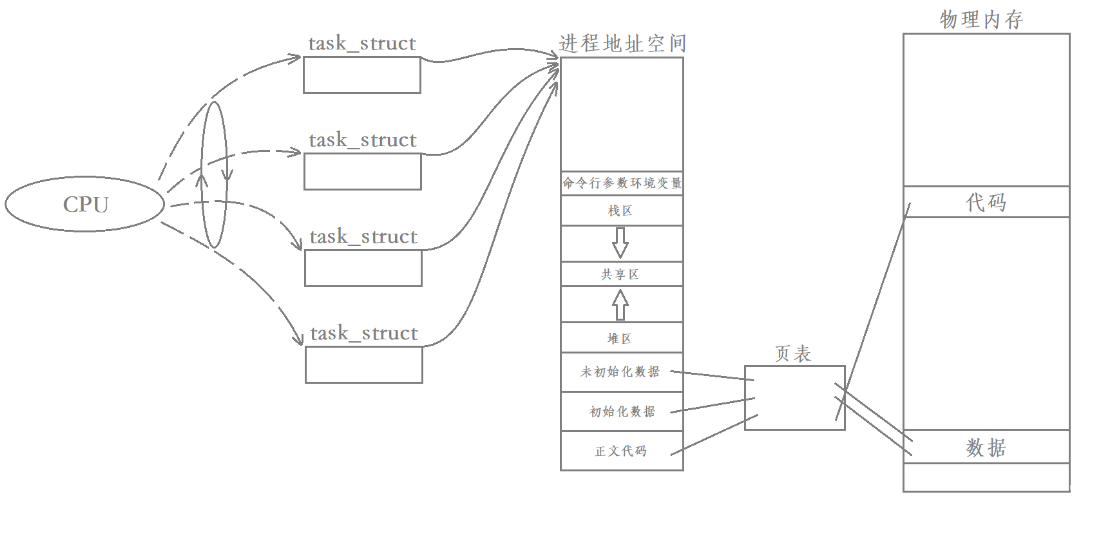
El proceso es la entidad básica para la asignación de recursos del sistema.
Un proceso se compone de uno o más task_struct "flujo de ejecución", espacio de direcciones del proceso, tabla de páginas, código y datos.
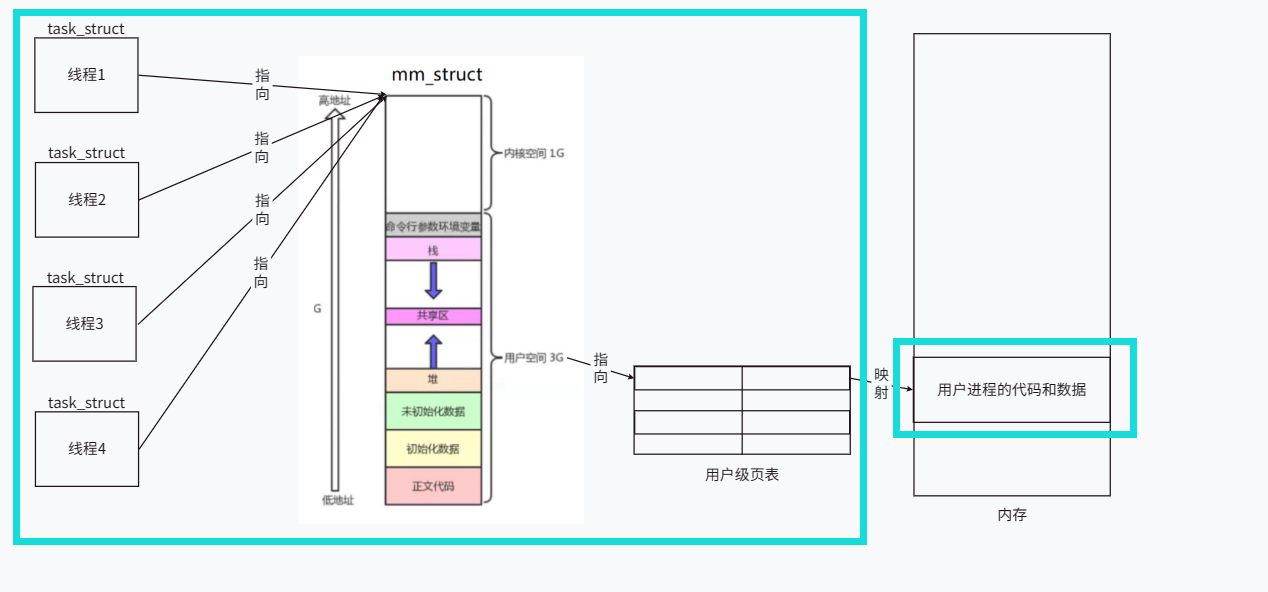
Solo cuando se crea un proceso, el sistema operativo solicitará recursos de memoria, creará estructuras como espacio de direcciones y cargará código y datos para él. Por lo tanto, el proceso es la entidad básica para que el sistema asigne recursos. Debido a que el sistema operativo asigna recursos del sistema al proceso, habrá espacio de memoria para la creación de task_struct para implementar subprocesos.
Tabla de páginas secundarias
Nota: La tabla de páginas de segundo nivel se usa para computadoras de 32 bits y la tabla de páginas de tercer nivel es necesaria para computadoras de 64 bits. Los principios de uso de la tabla de páginas de segundo nivel y la tabla de páginas de tercer nivel son los mismo.
Para mejorar la eficiencia de IO entre el disco y la memoria, el sistema de archivos del sistema operativo Linux divide el disco en bloques de datos (generalmente de 4 KB de tamaño, 8 sectores) y luego administra los bloques de datos como un todo. También está en unidades de bloques, y cuando el sistema operativo y el disco realizan IO, también se accede a los datos en unidades de bloques de datos. De manera similar, para leer datos del disco en bloques, la memoria debe dividirse en partes y discos. Las partes con el mismo tamaño de bloque de datos se denominan páginas/marcos de página. La esencia del intercambio de datos entre la memoria y el disco es el intercambio de datos entre la página correspondiente y el bloque de datos del disco correspondiente:
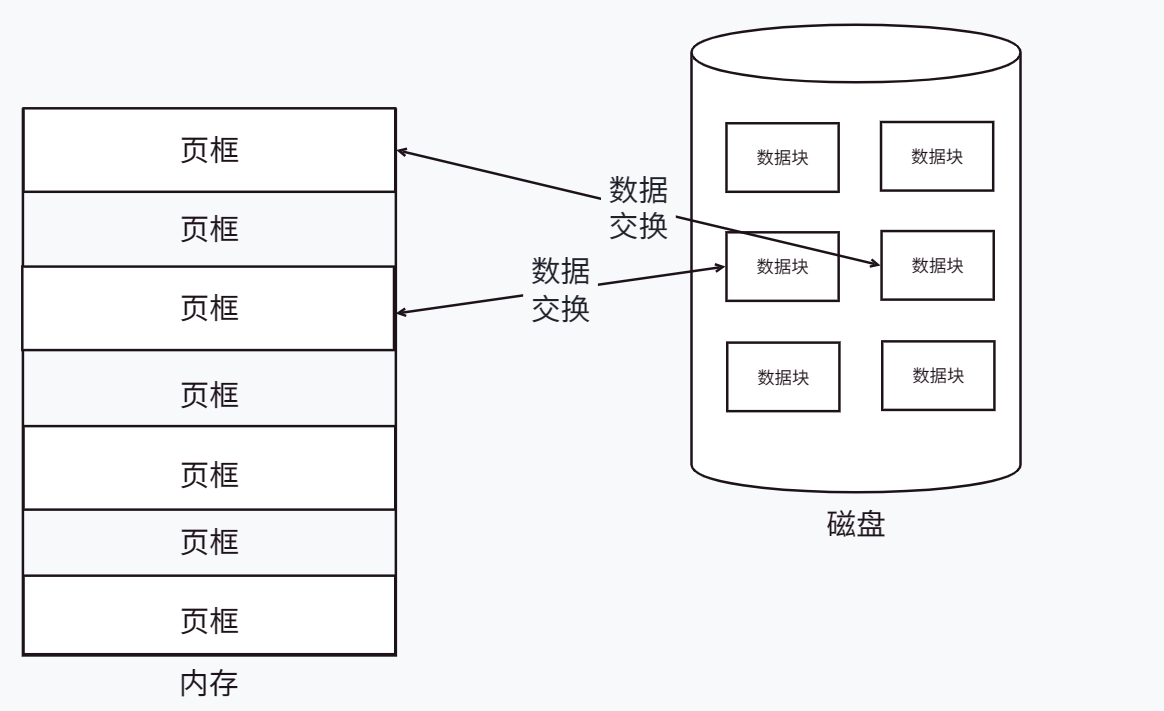
La esencia de la gestión de la memoria: almacenar bloques de datos específicos (contenido de datos) en el disco en el marco de la página (espacio para cargar datos) en la memoria física.
Después de dividir la memoria en marcos de páginas, el sistema operativo puede usar una estructura de matriz para describir la memoria física y luego usar esta estructura para continuar administrando la memoria física. Vale la pena señalar que, según el principio de localidad, cargar un bloque de datos del disco a la memoria es en realidad una operación de precarga, que puede reducir la cantidad de IO y mejorar la eficiencia de toda la máquina.
El tamaño de la memoria física de una computadora de 32 bits es 4 GB. La unidad básica de la memoria física son los bytes, por lo que la dirección que representa la memoria física requiere 32 bits. Cuando se utiliza la tabla de páginas secundaria, la dirección de 32 bits se divide en 10+ 10+12 Tres partes:
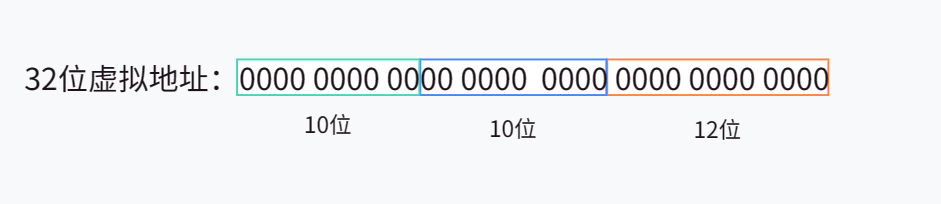
Las primeras direcciones de 10 bits actúan en la tabla de páginas de primer nivel (directorio de páginas), y el directorio de páginas almacena la relación de mapeo de todas las direcciones binarias compuestas por las primeras direcciones de 10 bits y las asigna a la tabla de páginas de segundo nivel correspondiente ( entrada de la tabla de páginas). La dirección intermedia de 10 bits actúa en la tabla de páginas de segundo nivel (entrada de la tabla de páginas). Dado que cada entrada de la tabla de páginas se encuentra de acuerdo con la asignación del directorio de páginas correspondiente, la dirección de 10 bits en la entrada de la tabla de páginas en realidad se crea con la primeros 20 bits La relación de mapeo de todas las direcciones binarias compuestas por direcciones se asigna al marco de página correspondiente. La última dirección de 12 bits actúa sobre el marco de la página. Cuando el marco de la página correspondiente se encuentra a través de la tabla de páginas secundarias, la primera dirección de los datos correspondientes se encuentra en función del tamaño representado por la dirección de 12 bits después del desplazamiento del primera dirección del marco de página. El diagrama esquemático del uso de la tabla de páginas secundarias para encontrar los datos correspondientes es el siguiente:
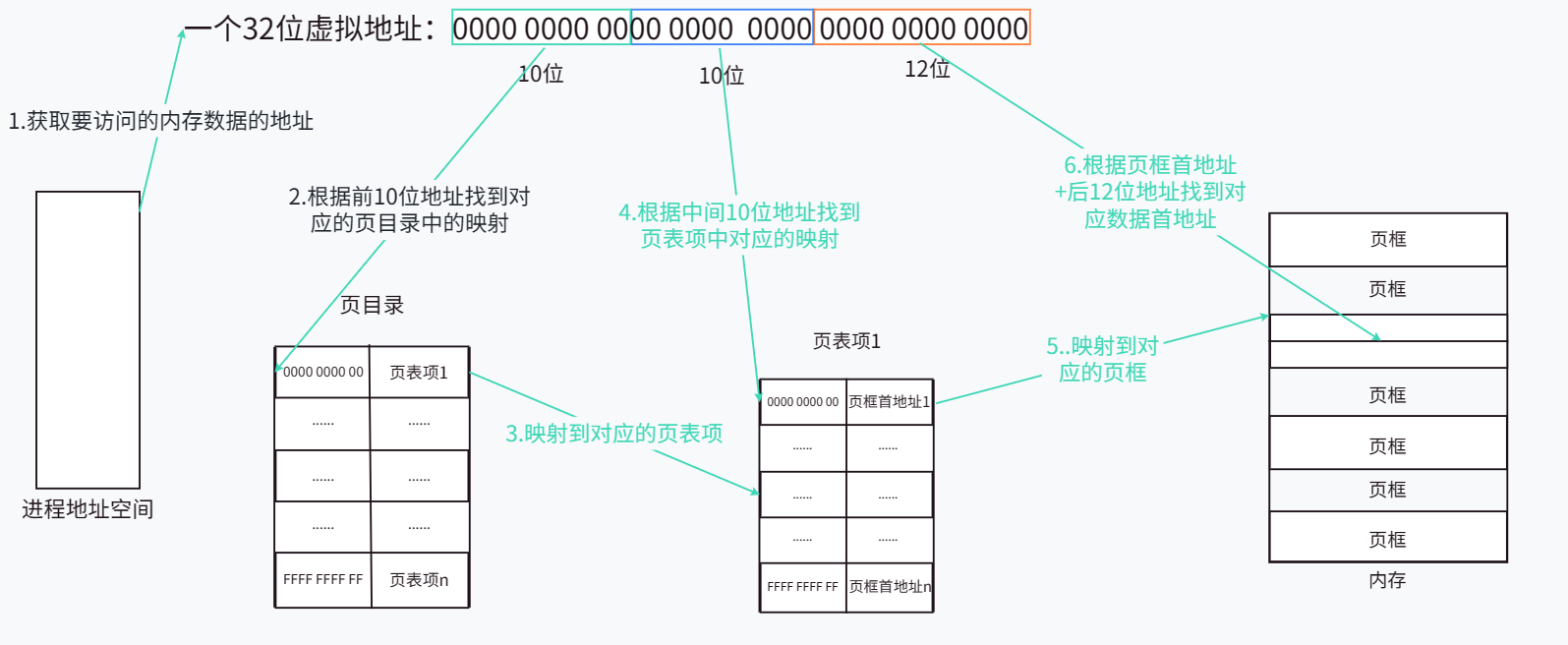
Esta estrategia de utilizar el mapeo de tablas de páginas de segundo nivel para encontrar la primera dirección del marco de página y luego usar el desplazamiento para encontrar la primera dirección de los datos correspondientes elimina la necesidad de crear una tabla de páginas de tercer nivel para mapear cada byte. en la memoria al implementar la tabla de páginas Arriba, lo que ahorra mucho espacio en la memoria.
De hecho, en la implementación específica de la tabla de páginas, no solo se registra la relación de mapeo de las direcciones, sino también los permisos de operación:
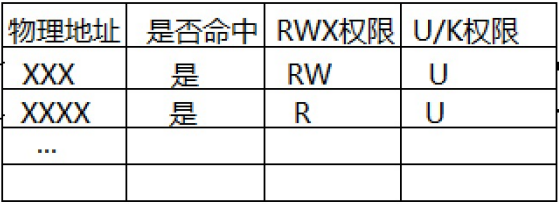
Cuando desee operar con datos, primero debe encontrar la dirección física real de los datos asignando la dirección virtual en la tabla de páginas y luego determinar si la operación es legal a través de los permisos registrados en la tabla de páginas. , la MMU de hardware generará una excepción, luego será reconocida por el sistema operativo y el sistema operativo enviará una señal al proceso que causó la excepción, lo que provocará que el proceso finalice.
Ventajas de los hilos
- Crear un nuevo hilo es mucho menos costoso que crear un nuevo proceso.
- En comparación con el cambio entre procesos, el cambio entre subprocesos requiere que el sistema operativo haga mucho menos trabajo.
- Los hilos ocupan muchos menos recursos que los procesos.
- Capacidad para utilizar completamente la cantidad de procesadores paralelos disponibles
- Mientras espera que se complete la lenta operación de E/S, el programa puede realizar otras tareas informáticas.
- Para aplicaciones computacionalmente intensivas, para ejecutarse en un sistema multiprocesador, los cálculos se dividen en múltiples subprocesos.
- En aplicaciones con uso intensivo de E/S, para mejorar el rendimiento, las operaciones de E/S se superponen. Los subprocesos pueden esperar diferentes operaciones de E/S al mismo tiempo.
Desventajas de los hilos
- Pérdida de rendimiento:
Un subproceso computacionalmente intensivo que rara vez es bloqueado por eventos externos a menudo no puede compartir el mismo procesador con otros subprocesos. Si el número de subprocesos de cómputo intensivo excede los procesadores disponibles, puede haber una gran pérdida de rendimiento, donde la pérdida de rendimiento se refiere a la adición de sincronización adicional y sobrecarga de programación, mientras que los recursos disponibles permanecen sin cambios.
- Robustez reducida:
Escribir subprocesos múltiples requiere una consideración más amplia y profunda. En un programa de subprocesos múltiples, la posibilidad de efectos adversos debido a ligeras desviaciones en la asignación de tiempo o al compartir variables que no deben compartirse es muy alta. En otras palabras, los subprocesos Hay una falta de protección entre ellos. ( Cuando ocurre una excepción en un hilo, el sistema operativo enviará una señal al proceso después de detectarla y luego todo el proceso finalizará) .
- Falta de control de acceso:
El proceso es la granularidad básica del control de acceso. Llamar a ciertas funciones del sistema operativo en un hilo afectará todo el proceso. La dificultad de programación aumenta Escribir y depurar un programa de subprocesos múltiples es mucho más difícil que un programa de un solo subproceso.
- La dificultad de programación aumenta:
Escribir y depurar un programa de subprocesos múltiples es mucho más difícil que un programa de un solo subproceso.
Excepción de hilo
- Si la división por cero ocurre en un solo subproceso, el problema del puntero salvaje hará que el subproceso falle y el proceso también fallará.
- El subproceso es la rama de ejecución del proceso. Una excepción en el subproceso es similar a una excepción en el proceso, que activa el mecanismo de señal y finaliza el proceso. Cuando el proceso finaliza, todos los subprocesos del proceso saldrán inmediatamente.
Uso del hilo
- El uso razonable de subprocesos múltiples puede mejorar la eficiencia de ejecución de programas con uso intensivo de CPU.
- El uso razonable de subprocesos múltiples puede mejorar la experiencia del usuario de programas con uso intensivo de IO. (Por ejemplo, en la vida, descargamos herramientas de desarrollo mientras escribimos código, lo cual es una manifestación de operaciones de subprocesos múltiples)
Recursos del hilo
Los subprocesos comparten datos de proceso, pero también tienen su propia porción de datos:
- ID del hilo
- Un conjunto de registros (usados para guardar contexto, usados para cambiar)
- Pila (utilizada para guardar variables temporales para gestionar mejor los datos)
- errno
- palabra de máscara de señal
- Prioridad de programación
Múltiples subprocesos de un proceso comparten el mismo espacio de direcciones, por lo que el segmento de texto y el segmento de datos se comparten. Si se define una función, se puede llamar en cada subproceso. Si se define una variable global, se puede acceder a ella en cada subproceso. Además, cada hilo también comparte los siguientes recursos de proceso y entorno:
- tabla de descriptores de archivos
- Cada método de procesamiento de señal (SIG_ IGN, SIG_ DFL o función de procesamiento de señal personalizada)
- directorio de trabajo actual
- ID de usuario e ID de grupo
El flujo de ejecución de subprocesos es el siguiente: