
1. 説明
画像出典:
コード: https://github.com/OpenAI/CLIP
初版発行: 2021 年 26 月<>
著者:アレック・ラドフォード、キム・、クリス・ハラシ、アディティア・ラメシュ、ガブリエル・ウー、サンディニ・アガルワル、ギリシュ・サス・テリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツコフ
カテゴリ: マルチモーダルディープラーニング、コンピュータビジョン、自然言語処理、基本モデル、表現学習
2.簡単な背景説明
CLIP ( Contrastive Language -Image Pre -Training) は、自然言語と画像の対応関係を学習するために使用されるマルチモーダル モデルです。 これは、インターネットから収集された 400 億のテキストと画像のペアでトレーニングされます。この記事の後半で説明するように、CLIP は強力なゼロショット パフォーマンスを備えています。これは、微調整を行わないトレーニングとは異なる下流タスクで優れたパフォーマンスを発揮することを意味します。
CLIP の目的は次のとおりです。
- 自然言語処理 (GPT ファミリ、T5、BERT など)で知られている大規模な事前トレーニング手法の成功をコンピューター ビジョンに適用します。
- 固定のコレクション クラス ラベルの代わりに自然言語を使用することで、柔軟なゼロショット機能を有効にします。
なぜこれが大したことなのか、自問するかもしれません。まず、多くのコンピューター ビジョン モデルは、クラウドソースのラベル付きデータセットでトレーニングされます。これらのデータセットには通常、数十万のサンプルが含まれています。一部の例外は、数百万または 2 桁のサンプルの範囲にあります。ご想像のとおり、これは非常に時間と費用がかかるプロセスです。一方、自然言語モデルのデータセットは通常、桁違いに大きく、インターネットから収集されたものです。次に、物体検出モデルがいくつかのクラスでトレーニングされており、さらにクラスを追加したい場合は、データ内でこの新しいクラスにラベルを付け、モデルを再トレーニングする必要があります。
自然言語と画像の特徴を組み合わせる CLIP の機能と、そのゼロショット パフォーマンスは、UnCLIP、EVA、SAM、安定拡散、GLIDE、VQGAN-CLIP など、他の多くの人気のある基本モデルの広範な採用につながりまし た。いくつか。
3.CLIP方式
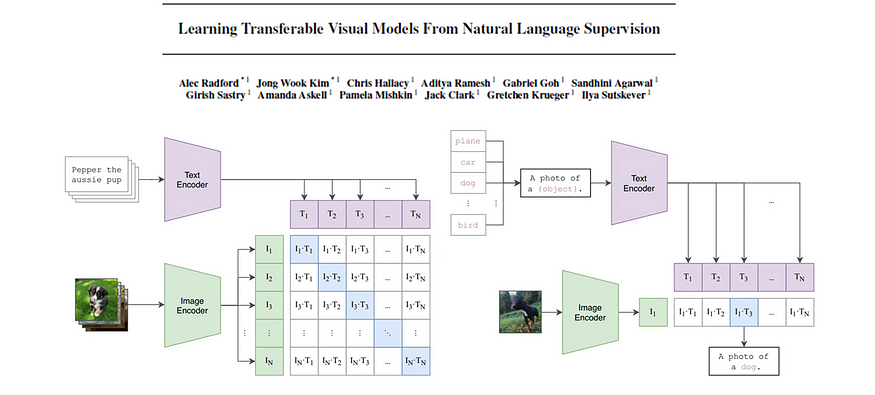
それでは、CLIP アプローチについて詳しく見ていきましょう。図 1 は、CLIP のアーキテクチャとそのトレーニング プロセスを示しています。
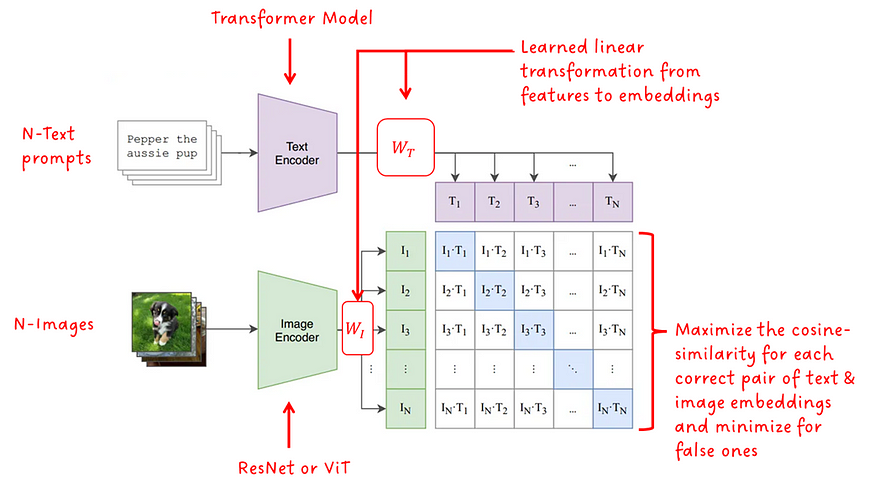
モデル アーキテクチャは、モダリティごとに 1 つずつ、合計 2 つのエンコーダー モデルで構成されます。テキスト エンコーダの場合はトランスフォーマが使用され、画像エンコーダの場合は ResNet またはViT (Visual Transformer)のバージョンが使用されます。学習された線形変換 (モダリティごとに 1 つ) は、特徴をサイズが一致した埋め込みに変換します。最後に、反対のモダリティの各埋め込み間のコサイン類似度が計算され、学習された温度スカラーによってスケーリングされます。トレーニング中、一致するペア間のコサイン類似度は最大化され、不正確なペア間のコサイン類似度は最小化されるため、フレームワークの名前に「コントラスト」という用語が含まれています。
もちろん、大規模なデータセット以外にも、成功には重要な微妙な点があります。まず、対照学習方法はバッチ サイズ N に強く依存します。正しい例とともに提供される否定的な例が多いほど、学習シグナルは強くなります。CLIP のバッチ サイズは 32,768 と非常に大きいです。第 2 に、CLIP は正確な語句の一致を学習するのではなく、テキスト全体のみを学習する単純なプロキシ タスク (Bag of Words (BoW) とも呼ばれます) を学習します。
興味深い事実:画像エンコーダーとして ResNet50x64 を使用する CLIP のバージョンは 18 V592 GPU で 100 日間トレーニングされましたが、ViT モデルを使用するバージョンは 12 V256 GPU でトレーニングされました。言い換えれば、単一の GPU ではそれぞれ 29 年以上、 8 年以上になります (異なるバッチ サイズが使用されるという事実は無視します)。
モデルをトレーニングした後、それを使用して画像上でオブジェクト分類を実行できます。問題は、画像を分類するようにトレーニングされておらず、テキスト プロンプト以外に入力クラス ラベルがないモデルを使用して分類する方法です。図 2. 次の方法を示します。
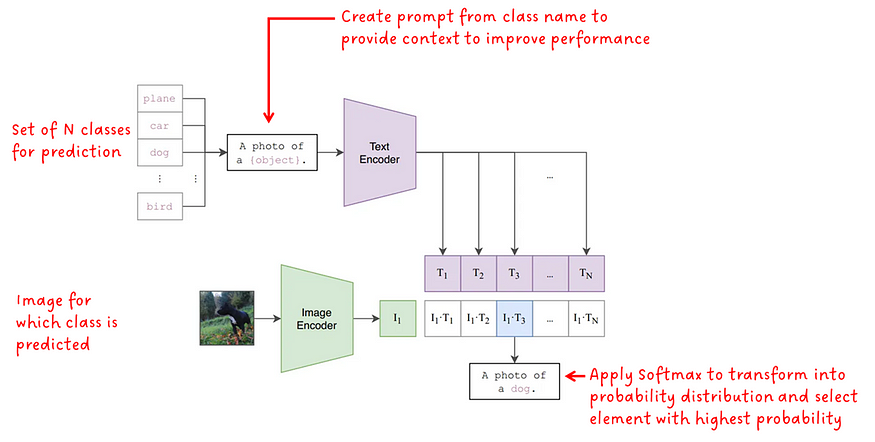
クラス ラベルは、単一の単語で構成されるテキスト キューと考えることができます。どのクラスを分類タスクに使用できるかをモデルに伝えるために、N クラスのセットがモデルに入力されます。これは、固定されたラベルのセットでトレーニングされた分類モデルと比較して、大きな利点です。3 クラスまたは 100 クラスを入力できるようになりました。これは私たちの選択です。後で説明するように、CLIP のパフォーマンスを向上させるために、クラス ラベルはモデルにさらなるコンテキストを提供するヒントに変換されます。次に、各チップはテキスト エンコーダーに供給され、埋め込みベクトルに変換されます。
入力画像は画像エンコーダに供給されて、埋め込みベクトルが取得されます。
次に、テキストと画像の埋め込みの各ペアのコサイン類似度が計算されます。得られた類似度値にソフトマックスを適用して確率分布を形成します。最後に、最も高い確率を持つ値が最終予測として選択されます。
4. 実験とアブレーション
CLIP の論文には、多数の実験とアブレーションが記載されています。ここでは、CLIPの成功を理解する上で重要だと思う5つのポイントを紹介します。主要なポイント (CLIP の作成者によって策定されたもの) を簡単に概要説明し、次に詳細を説明します。
- トレーニングの効率性: CLIP は、ゼロショット配信時の画像キャプション ベースラインよりも効率的です。
- テキスト入力形式:迅速なエンジニアリングと統合により、ゼロショットのパフォーマンスが向上します。
- ゼロショットのパフォーマンス:ゼロショット編集は、完全に監視されたベースラインと競争力があります。
- 狭いレンズのパフォーマンス:ゼロレンジ CLIP は狭い距離のリニア プローブよりも優れています
- 分布の変化:ゼロショット CLIP は、標準の ImageNet モデルよりも分布の変化に対して耐性があります。
4.1 トレーニングの効率
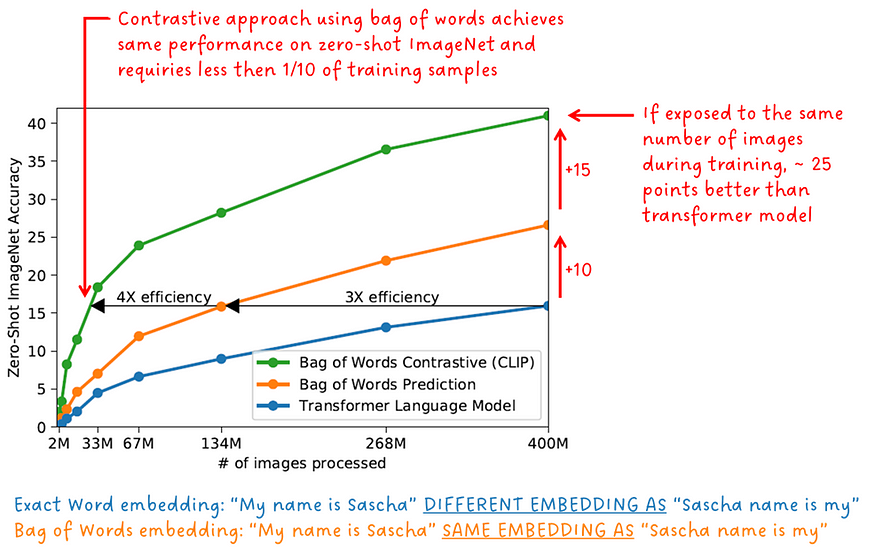
トレーニング中、画像エンコーダーとテキスト エンコーダーは共同でトレーニングされます。これは、単一のトレーニング目標が同時に使用されることを意味します。CLIP は、対比学習スキームを実行するだけでなく、テキスト プロンプト全体を指定された画像と比較するため、単語の順序は問題になりません。まさに「言葉袋」です。「私の名前はサーシャです」というフレーズは、「サーシャの名前は私のものです」と同じ埋め込みを生成します。
正しい単語とフレーズ内のその位置を予測するのではなく、単語の集まりを予測する方が、エージェントの目標としては簡単です。図 3. 以下は、正確な単語を予測するようにトレーニングされた初期コンバーター モデル、バッグ オブ ワードを予測するようにトレーニングされた初期コンバーター モデル、およびバッグ オブ ワードを使用して対照学習を実行する CLIP モデルについて、ImageNet 上のトレーニング サンプル数のゼロ ショットを示しています。正確さ。
「CLIP は、画像キャプションのベースラインよりもゼロショット配信で大幅に効率的です。」 - CLIP 著者
4.2 テキスト入力形式
図 2 からわかるように、オブジェクト分類を実行するために、クラス ラベルがテキスト ヒントに変換されます。もちろん、CLIP は 1 つの単語で使用できるため、これは偶然ではありません。これは、言語の説明的な性質を利用し、起こり得る曖昧さを解決するためのコンテキストを提供するために行われます。「ボクサー」という単語を例に考えてみましょう。それは犬の一種かもしれないし、スポーツ選手かもしれません。CLIP の作成者は、テキスト プロンプトの形式が重要であり、パフォーマンスと効率を向上させることができることを示しました。
「迅速なエンジニアリングと統合により、ゼロショットのパフォーマンスが向上します」 — CLIP 著者
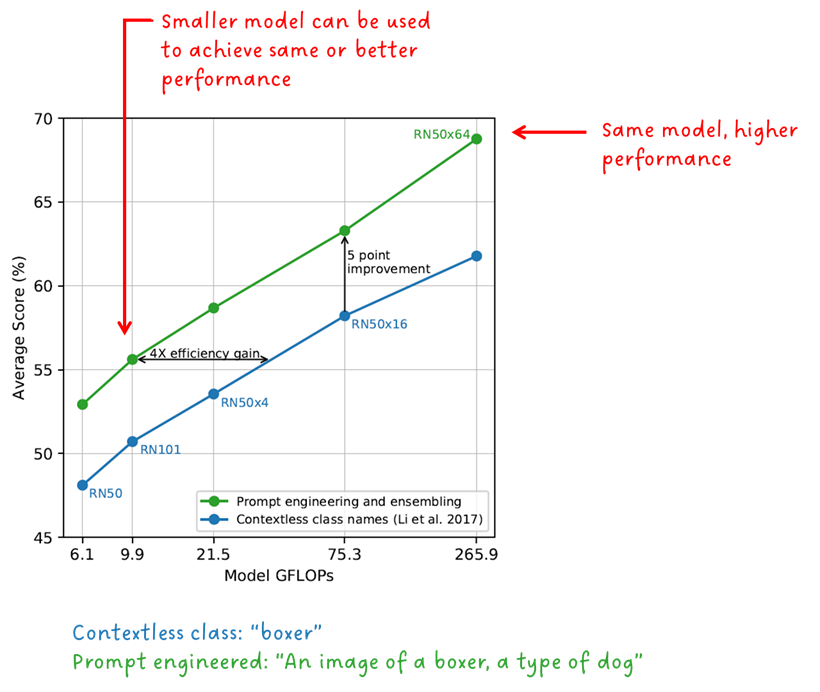
4.3 ゼロのレンズ性能
別の実験で、著者らは、CLIP のゼロショット画像分類パフォーマンスを、比較データセットのみでトレーニングされたモデルと比較しました。
「ゼロショット CLIP は、完全に監視されたベースラインで競争力があります」 — CLIP 著者
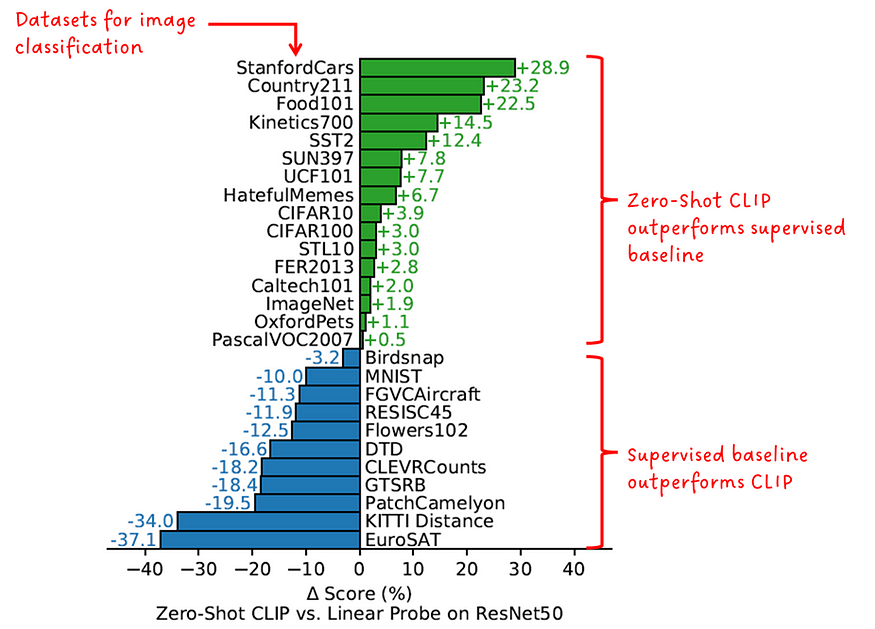
4.4 レンズ性能の低下
ゼロショット予測器は下流タスク用に微調整されていませんが、ショット検出器はほとんどありません。著者らは、公開されている複数の事前トレーニング済みモデルで実験を実施し、20 の異なるデータセットでそれらの数ショットのパフォーマンスをゼロショットおよび数ショット CLIP と比較しました。マイノリティ ショット モデルは、クラスごとに 1、2、4、8、16 個のサンプルで微調整されました。
興味深いことに、ゼロレンズ CLIP は 4 レンズ CLIP とほぼ同じパフォーマンスを示しました。
CLIP を他のモデルと比較する場合は、比較対象の公開されているモデル ( BiT、SimCLR、ResNet) が、異なる小規模なデータセットで CLIP モデルとして事前トレーニングされていることを考慮する必要があります。
「ゼロレンズ CLIP は、少数レンズのリニア プローブよりも優れています」 — CLIP 著者
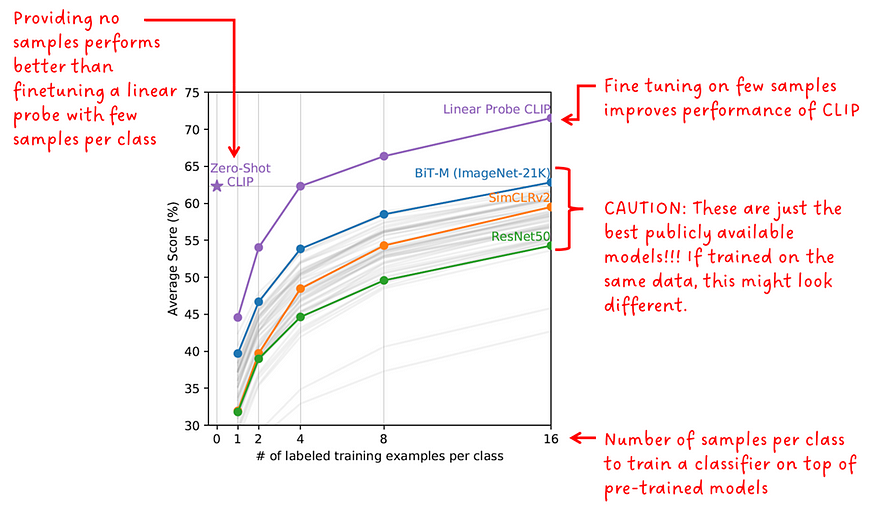
4.5 配布譲渡
一般に、分布シフトに対するモデルの堅牢性とは、トレーニング データのデータ分布と同様に、異なるデータ分布のデータでもパフォーマンスを発揮できる能力を指します。理想的には、同様にパフォーマンスが向上するはずです。実際、性能は低下します。
ゼロショット CLIP の堅牢性は、ResNet101 ImageNet モデルと比較されました。図 7 に示すように、どちらのモデルも ImageNet の自然分布オフセットに基づいて評価されます。
「ゼロショット CLIP は、標準の ImageNet モデルよりも配布の変化によく適応します」 - CLIP 著者
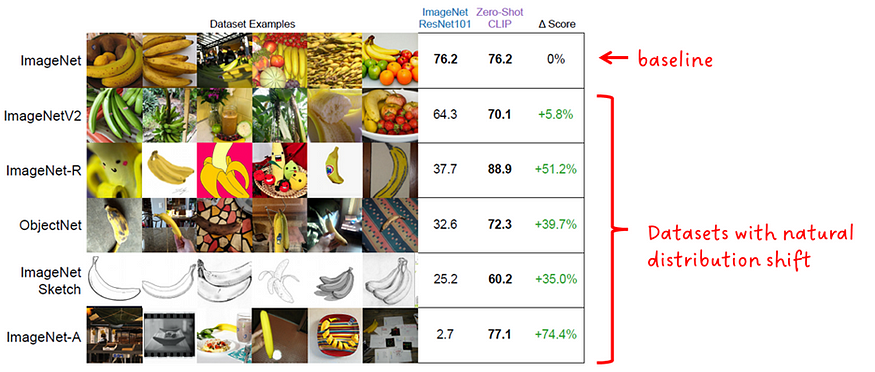
5. その他の資料とリソース
この記事の冒頭で述べたように、CLIP は多くのプロジェクトで広く採用されています。以下はCLIPを使用した論文のリストです。
- [アンクリッピング] CLIP 潜在を使用して階層テキストの条件付き画像を生成する
- [Eva] 大規模マスク視覚表現学習の限界を探る
- [サム] 何でもセグメント化する
- 【安定拡散】潜在拡散モデルに基づく高解像度画像合成
- [ GLIDE]テキストガイド付き拡散モデルを使用したリアルな画像の生成と編集
- [VQGAN-CLIP] 自然言語ガイダンスを使用してオープン ドメイン画像を生成および編集する
実装を詳しく調べて自分でテストしたい場合は、リポジトリのリストが提供されます。