微調整のためにトレーニング セットを送信する
JSONL ファイルを作成したら (小さなサンプルはここまたはipfs_hereにあります)、次のステップは、次のコマンドを使用して、作成したファイルを OpenAI にアップロードすることです。
openai.api_key = os.getenv("OPENAI_API_KEY")
print(openai.File.create(file=open("spider-finetuning.jsonl", "rb"),purpose='fine-tune'))ファイルをアップロードした後、次のコマンドを使用してアップロードのステータスを確認できます。
print(openai.File.retrieve(id="file-id"))
# 或者
print(openai.File.list())結果は次のようになります。
{
"object": "file",
"id": "file-id",
"purpose": "fine-tune",
"filename": "file",
"bytes": 71699079,
"created_at": 1693343752,
"status": "uploaded",
"status_details": null
}ステータスが「処理済み」に変わると (以下の例と同様)、ファイルを微調整に使用できます。
{
"object": "file",
"id": "file-id",
"purpose": "fine-tune",
"filename": "file",
"bytes": 71699079,
"created_at": 1693343752,
"status": "processed",
"status_details": null
}これで、ジョブの微調整を開始する準備が整いました。微調整ジョブは、次の Python コードを使用して作成できます。
print(openai.FineTuningJob.create(
training_file="file-id",
model="gpt-3.5-turbo",
suffix = "spider",
hyperparameters = {
"n_epochs": #number_of_epochs,
})
)微調整プロセスの所要時間は、微調整データ セットのサイズによって異なります。スピナーには最大トークン制限があり、50,000,000 トークンに設定されています。したがって、Spider データセットを使用する場合は、サンプル数を 7000 から 5750 に減らし、合計 2 エポックに対して微調整を実行します。
次のコマンドを使用して、微調整ジョブのステータスを確認できます。
print(openai.FineTuningJob.retrieve(id="ftjob-id"))結果は次のようになります。
{
"object": "fine_tuning.job",
"id": "ftjob-id",
"model": "gpt-3.5-turbo-0613",
"created_at": 1693346245,
"finished_at": 1693353313,
"fine_tuned_model": "ft:gpt-3.5-turbo-0613:dataherald:spider:id",
"organization_id": "org-id",
"result_files": [
"file-id"
],
"status": "succeeded",
"validation_file": null,
"training_file": "file-id",
"hyperparameters": {
"n_epochs": 2
},
"trained_tokens": 44722020
}モデルのパフォーマンス
DIN-SQL は、Spider データセットに関する最先端の研究結果を実現する、自然言語から SQL への変換のモデルです。DIN-SQL は、「Denoising-inductive SQL Generation」の略で、SQL クエリ ステートメントを生成するためのジェネレーター モデルとして GPT-4 を使用し、ノイズ除去オートエンコーダーと帰納的学習手法を組み合わせたモデルです。DIN-SQL は、パフォーマンスと精度を向上させるために、少数のサンプル プロンプト、アイデア チェーン プロンプト、分解プロンプトなど、さまざまな高度なプロンプト手法を使用します。このモデルは高い精度と効率を備えていますが、コストと処理時間の点でより高くなる可能性があります。
ゼロショット パフォーマンスに関して、微調整されたモデルのパフォーマンスを、微調整されていない GPT3.5-Turbo および DIN-SQL+GPT-4 (Spider の現在の最先端のメソッド) と比較してベンチマークします。

微調整された G-3.5-Turbo のパフォーマンスは、現在の最先端の方法である高度なプロンプト技術 (少数のプロンプト、思考連鎖プロンプト、分解プロンプトを含む) を含む以前の方法と一貫しています。
重要なのは、モデルを微調整することで、 DIN-SQL + GPT-4 アプローチと比較してコストと処理時間を大幅に削減することです。以下の表は、Spider ベンチマークからの問題ごとに、さまざまなモデル間のおおよそのコストと速度を示しています。
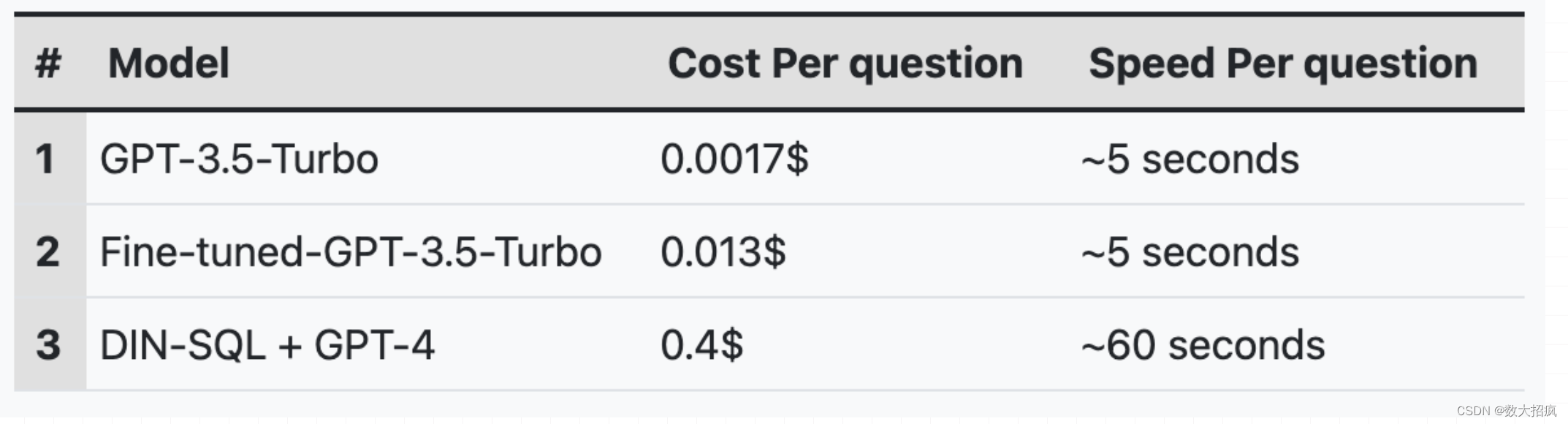
同じモデルの問題ごとのコストと速度 (Spider ベンチマークより)
上に示したように、微調整された GPT-3.5-Turbo モデルは、DIN-SQL と GPT-4 と比較して30 倍安く、12 倍高速です。
結論は
トレーニング データセットの構築に時間と資金を投資することで、12 倍高速かつ 30 分の 1 低コストでありながら、最先端の手法と正確に一致させることが可能になります。特定のビジネスにターゲットを絞った微調整が行われれば、精度はさらに向上するはずです。