CLIP и работа по улучшению
Направление совершенствования CLIP
Семантическая сегментация Lseg, обнаружение целей
GroupViT ViLD, GLIP v1/v2 понимание видео VideoCLIP, CLIP4clip, генерация изображений ActionCLIP VQGAN-CLIP, CLIPasso, CLIP-Draw мультимодальные последующие задачи VL Нисходящие другие
оперативное проектирование (CoOp и т. д.)
deepCLIP, pointCLIP (облако точек), audioCLIP (аудио)
КЛИП: Изучение переносимых визуальных моделей под контролем естественного языка (2021 г.)
Набор данных 400 миллионов
предтренировочный этап
В названии статьи есть важный момент – контроль естественного языка. Это показывает, что CLIP — это работа в мультимодальной области, включающая текст и изображения. Он получает сигналы контроля из текста для решения задачи визуальной классификации.
Фактически, вход предварительно обученной сети — это сочетание текста и изображений, а текст — это «фотография
Передайте текст и изображения через кодировщик соответственно, чтобы получить вложения. Кодировщиком текста здесь является Transformer, а кодировщиком img может быть либо Resnet, либо VIT.Автор исследовал обе структуры.

Были получены вложения N изображений и N текстов соответственно. Далее нам нужно провести на них контрастное обучение. Контрастное обучение требует наличия нескольких положительных и отрицательных образцов. Здесь парные предложение и текст представляют собой пару положительных образцов (то есть по диагонали), и наоборот, непарные — отрицательные образцы (вне диагонали). Цель предварительно обученной сети — максимизировать косинусное сходство пар положительных образцов и минимизировать косинусное сходство отрицательных образцов.
Этот метод обучения без учителя требует большого объема данных. Как мы упомянем позже, OpenAI специально собрал огромный набор данных из 400 миллионов пар выборок. Действительно богатый и своенравный.
процесс рассуждения
Далее следует процесс нулевого рассуждения. Учитывая изображение, как использовать предварительно обученный CLIP для классификации? Здесь автор хитро настроил "множественный выбор". В частности, я дал сети несколько классификационных меток, таких как кошка, собака, птица, и использовал текстовый кодировщик для получения вложений. Затем вычислите косинусное сходство между этими метками и изображением соответственно; в конце концов, метка с наибольшим сходством является прогнозируемым результатом классификации (или установите пороговое значение и выведите его, если оно больше порогового значения).
Автор упомянул, что по сравнению с простым присвоением классификационной метки эффект классификации данного предложения лучше: большая часть того, что модель видит во время предварительного обучения, — это предложения. Если во время вывода оно внезапно станет словом, эффект определенно уменьшится. Автор также сообщил, что это тоже обсуждалось конкретно prompt engineering.

ограничение
Автор знакомит с ограничениями CLIP в главе 6.
Во-первых, хотя CLIP связан с Resnet 50 на Imagenet. Но последняя далека от современной модели. CLIP все еще отстает более чем на дюжину пунктов точности от самой эффективной модели. Хотя крупномасштабное обучение может значительно повысить точность модели, по оценкам авторов, чтобы соответствовать сегодняшним наиболее эффективным моделям, вычислительные усилия необходимо будет увеличить как минимум в 1000 раз.
Другая проблема заключается в том, что если данные, используемые для вывода, действительно далеки от обучающих данных (вне распределения), то эффект обобщения CLIP будет очень плохим. Автор привел пример: на наборе данных MNIST (изображения рукописных цифр 1-9) CLIP достиг точности всего 88%, что не так хорошо, как логистическая регрессия, действующая на пиксели. Хотя набор данных в 400 миллионов велик, весьма вероятно, что не существует изображений, содержащих такие необычные рукописные цифры. Это поднимает некоторые вопросы о том, насколько мощь CLIP зависит от этого высококачественного крупномасштабного набора данных .
Другой момент заключается в том, что CLIP требует от нас вручную задавать «вопросы с множественным выбором» на этапе рассуждения. Автор представлял, что было бы здорово, если бы сеть могла автоматически генерировать текст для описания изображения (кто-то сделал это позже). Кроме того, автор также упомянул проблему низкой эффективности использования данных.
Lseg: семантическая сегментация на основе языка.
Используется контролируемая помеченная карта сегментации.
деталь:
Весь текстовый кодер LSeg является моделью и весом текстового кодировщика CLIP и замораживается на протяжении всего процесса обучения и вывода;
Кодером изображения LSeg может быть любая сеть (CNN/ViT), и его необходимо обучить;
Блоки пространственной регуляризации — это модуль, предложенный в этой статье. Чтобы иметь некоторые изучаемые параметры для понимания результатов вычислений после расчета сходства изображения и текста на уровне пикселей, он состоит из некоторых сверток и сверток по глубине;

GroupVIiT: GroupViT: семантическая сегментация возникает в результате контроля текста
Хотя LSeg может обеспечить семантическую сегментацию с нулевым выстрелом, метод обучения не является контрастным обучением и не использует текст в качестве сигнала контроля . Поэтому для обучения по-прежнему требуется аннотация карты контролируемой сегментации. Более того, поскольку аннотация семантической сегментации очень затруднительна, наборы данных в области сегментации невелики.Семь наборов данных, используемых LSeg, могут составлять до одного или двух миллионов выборок. Как использовать текст для самостоятельного обучения, например CLIP? GroupViT — одна из представительных работ в области семантической сегментации, которая использует обучение с учителем на основе текста, такое как CLIP. GroupViT проводит обучение семантической сегментации посредством контрастного обучения с самоконтролем. На этапе вывода может быть достигнут нулевой вывод.
Как следует из названия, основная идея GroupViT заключается в использовании идеи группировки неконтролируемой сегментации перед глубоким обучением . Подход в то время, вероятно, заключался в продолжении расхождения наружу после определения определенной центральной точки, разделении всех близких точек на группу и, наконец, расхождение было завершено для получения результата сегментации. Группировка в GroupViT заключается в распределении токенов блоков изображений в ViT по разным токенам семантических категорий.

Структура модели и процесс обучения
Давайте посмотрим, как конкретно тренируется GroupViT. Структура модели и процесс обучения показаны на рисунке ниже. В дополнение к токену блока изображения si 1 \mathbf{s}_i^1, отправленному в Transformerся1(размер N×DN\times DН×D ), существует также обучаемый токен группыgi 1 \mathbf{g}_i^1гя1(Размер М 1×Д М_1×ДМ1×D , немного похоже на запрос объекта). Токены группы здесь эквивалентны токену cls в задаче классификации. Поскольку изображению в задаче классификации требуется только один признак полного изображения, можно использовать только один токен. При семантической сегментации для одного изображения требуется несколько признаков, поэтому Несколько групповых токенов.
64 группы — это центры кластеризации, которые мы надеемся иметь. Они будут объединены в блок позже. Предыдущая представляет собой все изображение.
(Случайно инициализированы или сгруппированы?)
После изучения шести слоев слоев-трансформеров группировка завершается с помощью группового блока, и токены блока изображения назначаются каждому групповому токену и объединяются в более крупные с семантической информацией более высокого уровня. Метод группировки токена показан в правой части рисунка 7. Он аналогичен механизму самообслуживания, который заключается в вычислении сходства между токеном блока изображения и токеном группировки и распределении его по наибольшему из них.
Чтобы преодолеть недифференцируемость argmax, здесь используется гумбел softmax.
После завершения слияния мы получаем si 2 \mathbf{s}_i^2ся2(размер M 1 × D M_1\times DМ1×Д ). Затем добавьте новые токены группыgi 2 \mathbf{g}_i^2гя2(Размеры: M 2 × D M_2\times DМ2×D ), повторите описанный выше процесс: после изучения трех слоев слоев преобразователя и после еще одного распределения блоков группировкиsi 3 \mathbf{s}_i^3ся3(размер M 2 × D M_2\times DМ2×Д ).
Здесь нам нужно использовать семантические признаки, извлеченные семантическим кодировщиком, для контроля,но в отличие от задачи классификации, где имеется только один признак изображения, здесь есть M 2 M_2М2Как рассчитать сходство между функциями изображения (8*384) и текстовыми функциями ?
Здесь автор использовал самый простой метод — прямое объединение средних значений , чтобы получить DD.Характеристики D- мерного изображенияz I \mathbf{z}^IяI с текстовым признакомz T \mathbf{z}^TяT рассчитывает потерю контрастности.
Эта модель имеет всего 8 групп и может быть разделена максимум на 8 категорий. Больше не подойдет.
ограничение: нет многомасштабной информации и используется только энкодер
Другие детали:
Помимо самого текста в паре с графикой, также извлекаются существительные из текста, формируется подсказка (например, «Фотография {дерева}.») по методу, аналогичному CLIP, и происходит потеря сравнения рассчитывается с учетом признака изображения, см. исходный текст, рисунок 3;

процесс рассуждения
Затем давайте посмотрим, как GroupViT выполняет нулевое рассуждение. Как показано на рисунке 8, способ, которым GroupViT реализует нулевой вывод, очень похож на CLIP. M 2 M_2 сначала получается с помощью кодировщика изображений.М2функции изображения , а затем вычислить сходство между ними и текстовыми объектами, извлеченными с помощью подсказки данной категории, и принять максимальное значение. Однако очевидным недостатком реализации нулевого кадра таким способом является то, что количество категорий, которые могут быть обнаружены в изображении, может составлять не более M 2 M_2 .М2индивидуальный.
Другие детали:
Что касается фоновых классов при семантической сегментации , GroupViT обрабатывает их во время рассуждения следующим образом: Как процесс рассуждения учитывает фоновые классы? Чтобы улучшить порог сегментации класса переднего плана, устанавливается порог. Только если сходство превышает 0,9 (принять максимум), он считается классом. Если сходства нет, он считается фоном. Это полезно для с небольшим количеством категорий. Если категорий много, а сходство относительно низкое, сходство переднего плана и фона не сильно отличается. Если порог установлен очень низко, произойдет неправильная классификация.
Визуализируйте результаты
Результаты визуализации областей внимания, соответствующих разным групповым токенам на разных этапах в GroupViT, показаны на рисунке 9. Видно, что на первом этапе каждый токен замечает некоторые семантически ясные области, такие как глаза и конечности, и все они являются относительно небольшими областями; на втором этапе каждый токен замечает семантические области. Он относительно большой, например лицо. и тело. Это соответствует эффекту слияния групп, которого хочет автор.

- GroupViT — первая работа, реализующая нулевую семантическую сегментацию;
- GroupViT значительно улучшился по сравнению с другими методами семантической сегментации с самоконтролем.

Однако контролируемый уровень PASCAL VOC уже находится на уровне 90+, так что еще есть много возможностей для улучшения.
Последующая проверка
Автор считает, что сегментация CLIP выполнена очень хорошо, но классификация неверна. Чтобы проверить, приводит ли ошибка классификации к низкому верхнему пределу, автор сравнивает маску и GTmask и напрямую использует метку с наибольшим значением IOU в качестве метки. что почти то же самое, что контролируемая производительность. Сегментация выполнена очень хорошо.
Причина в том, что **clip может изучать только вещи с сильной семантической информацией, ** не может изучать размытие, фон и тому подобное, а также не может изучать фоновые классы
. Решение: установите пороговое значение в соответствии с категорией и измените его на «Обучаемый порог» меняет процесс вывода нулевого выстрела и добавляет ограничения во время обучения для интеграции в фоновый класс.
Обнаружение цели
ViLD: Обнаружение объектов с открытым словарным запасом с помощью зрительного и языкового знания.
Время обучения очень длительное.Письменный метод: придумать картинку, задать вопросы, выявить исследовательскую мотивацию.
Пример обнаружения цели открытого словаря, который необходимо выполнить в этой статье, показан на рисунке ниже. На рисунке ниже фиолетовые — это базовые категории, а розовые — новые категории. ViLD хочет сделать следующее: нужно обучать только базовый класс во время обучения, а затем учиться на модели CLIP посредством дистилляции знаний , чтобы она могла обнаруживать новые классы во время вывода.
Текущие категории аннотаций обнаружения целей очень ограничены и могут обнаруживать только ограниченные категории. Может ли модель обнаруживать новые категории на основе существующего набора данных?

Структура модели и цели обучения
Структура модели и цели обучения ViLD показаны на рисунке ниже. Первый этап не показан.Фокус исследования метода ViLD находится на втором этапе двухступенчатого детектора, то есть этапе после получения предложения.

(а) — классификационная головка (маска rcnn) обычного двухкаскадного детектора, который непосредственно рассчитывает перекрестную энтропийную потерю.
(b) представляет собой текстовую модель ViLD, которая заменяет классификатор встраиванием текста фиксированной семантической категории и обучаемым встраиванием фона, а затем вычисляет сходство признаков текста изображения для расчета потери перекрестной энтропии . Встраивание текста — это функция, извлекаемая из приглашения, созданного на основе базового класса в наборе данных. Причина, по которой необходимо добавить отдельное внедрение фона, заключается в том, что во время обучения используются только базовые классы, а все другие объекты, не входящие в базовые классы, должны быть классифицированы как фоновые классы, представлены обучаемыми внедрениями фона и обновляются вместе . во время тренировки . Слой проекции введен для унификации размера текстовых элементов изображения.
В текстовой модели ViLD функции изображения и текстовые функции связаны друг с другом посредством встраивания текста. Структура модели уже поддерживает нулевое обнаружение текстовых запросов. Однако, поскольку модель еще не понимает другое семантическое содержимое, выходящее за рамки базового класса, она напрямую Нулевой выстрел не будет работать очень хорошо . Как умело внедрить CLIP (развернуть до CN)?
(c) - это ViLD-изображение, которое использует кодер изображения модели CLIP в качестве модели учителя. Есть надежда, что выходные данные встраивания области M здесь максимально совместимы с CLIP (дистилляция знаний)
Чтобы ускорить обучение модели, при обучении ViLD-изображения сначала используйте модель CLIP для извлечения признаков области изображения, сохраните их на жестком диске, а затем прочтите их непосредственно с жесткого диска во время обучения (веса клипов заблокированы) .
Учитывая, что функции изображения, извлеченные с помощью модели CLIP, тесно связаны с текстом, модель ViLD-изображения изучает возможности извлечения функций изображения открытого мира в предварительно обученном CLIP посредством дистилляции знаний. Поскольку сигнал контроля поступает от CLIP, а не от ручного аннотирования, ViLD-изображение больше не ограничивается конкретными категориями. Вместо этого CLIP может изучить любую семантическую область для извлечения функций изображения и детекторов. Таким образом, возможности модели с открытым словарем расширяются.
Рассчитывается как ПОТЕРЯ L1
Недостатки: Почему M заранее рассчитанных предложений? Главным образом, чтобы ускорить обучение, N предложений ab можно изменить в любое время.
(d) Объединяет модели ViLD-текста и ViLD-изображения для получения полной модели ViLD и одновременного ее обучения.Цели обучения были представлены в двух предыдущих пунктах.
Потери рассчитываются как потери перекрестной энтропии и потери l1.
Полная основа для обучения моделей и получения выводов
Верхняя часть рисунка — это процесс обучения модели и целевая функция, которые уже были представлены и больше описываться не будут. Нижняя часть рисунка 14 — это процесс, когда ViLD выполняет нулевой вывод. **Любая категория (базовая категория + новая категория)** создается с помощью подсказки, извлекаются признаки, а сходство рассчитывается с использованием извлеченных признаков области изображения. детектором, примите максимальное значение в качестве прогнозируемой категории кадра обнаружения.

GLIP: Предварительная тренировка по основам языка и образа
Задача локализации (нахождение объекта по предложению) очень похожа на задачу обнаружения изображения, обе задачи заключаются в поиске местоположения целевого объекта на изображении. Модель GLIP объединяет две задачи обнаружения и заземления объектов и создает единую среду обучения для использования наборов данных обеих задач. В сочетании с технологией псевдометок для усиления данных объем обучающих данных достиг беспрецедентных масштабов. После завершения обучения он тестируется непосредственно на наборе данных COCO с нулевым выстрелом и достигает 49,8 AP.
Результаты теста GLIP с нулевым выстрелом показаны на рисунке независимо от того, задано ли ему несколько категорий (например, человек, пистолет, яблоко и т. д.) или заданный абзац (например, «на дороге есть ямы») как текстовый кодер. Для любого ввода модель GLIP может найти местоположение соответствующего объекта по изображению.

Целевые функции задач обнаружения и локализации состоят из двух частей потерь, а именно потерь классификации и потерь локализации . Про потерю позиционирования говорить нечего, просто посчитайте расстояние до коробки GT в аннотации. С потерей классификации ситуация иная.
Для задачи обнаружения метка классификации представляет собой слово категории. При расчете потерь классификации логиты рассчитываются на основе каждого объекта поля области и заголовка классификации. После того, как выходные логиты фильтруются по нм, вычисляется перекрестная энтропийная потеря. с ГТ .
Для задачи заземления метка представляет собой предложение. Вместо использования заголовка классификации текстовые объекты получаются с помощью текстового кодировщика, вычисляется сходство между текстовыми объектами и функциями поля региона и получается оценка соответствия.
Автор предлагает объединить эти две задачи, определив, когда в двух задачах имеется положительное совпадение, а когда — отрицательное.
данные
Поскольку две задачи обнаружения и заземления объединены, наиболее прямым преимуществом является то, что наборы данных с обеих сторон могут использоваться для обучения этой единой системы. Все эти наборы данных помечены и недостаточно велики. Если вы хотите получить больший объем данных, вам необходимо использовать немаркированные данные изображения и текста, такие как CLIP. Однако для обучения задачам обнаружения целей требуются кадры GT, а отдельные изображения и текст не могут использоваться непосредственно для данных. Здесь автор использует метод псевдометок для самообучения, используя GLIP-T©, обученный на O365 и GoldG, для создания псевдометок на изображениях и текстовых данных Cap4M/Cap24M, и напрямую использует его в качестве поля GT для GLIP- Обучение Т/Л .
В сгенерированных псевдометках определенно есть ошибки, но эксперименты показывают, что модель GLIP-L, обученная путем расширения большого объема данных псевдометок, все равно улучшит производительность.
Структура модели
Структура модели GLIP и цели обучения показаны на рисунке 18. Модель обучается контролируемым образом. После расчета сходства между характеристиками текста и характеристиками изображения она может напрямую рассчитать потерю выравнивания (потерю выравнивания) с помощью GT. (Потери локализации) также рассчитываются непосредственно с помощью поля GT.
Слой слияния в середине модели предназначен для усиления взаимодействия между кодировщиком изображения и кодировщиком текста, чтобы можно было лучше обучить окончательное объединенное пространство признаков изображения и текста .

GLIPv2: объединение локализации и понимания языка видения
Дальнейшее расширение GLIP, GLIPv2, объединяет больше задач, связанных с позиционированием (таких как обнаружение, сегментация экземпляров), и больше мультимодальных задач (таких как ответы на вопросы, генерация субтитров).

AudioCLIP:AudioCLIP: расширение CLIP на изображение, текст и аудио
Видеоданные сами по себе представляют собой богатые мультимодальные данные, которые содержат как кадры изображения, так и речевые и текстовые аннотации. Структурная диаграмма этой статьи показана на рисунке 8. Характеристики трех модальностей изображения, текста и голоса извлекаются отдельно, а затем в парах выполняется кросс-модальное сравнительное обучение.
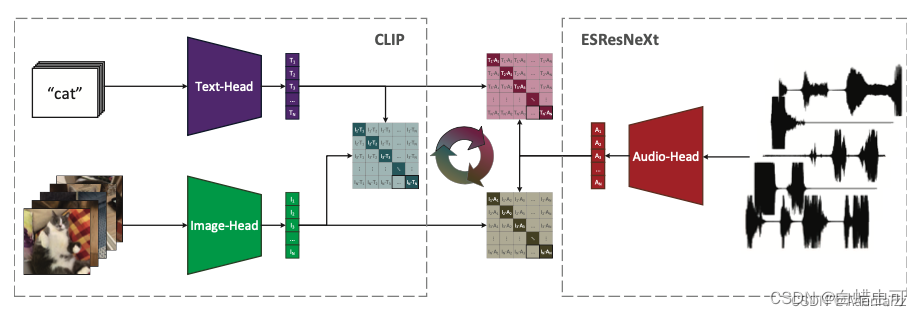
Для чего-то подобного, включающего более двух модальностей, выполните кросс-модальное сравнительное обучение в парах, чтобы получить три матрицы. Последние три матрицы можно сложить.
Кооператив: учимся предлагать модели языка видения [IJCV 2022]
Изменить подсказку на обучаемый вектор
Оптимизация контекста (CoOp)
Автор предлагает два пути реализации CoOp :
(1) Единый контекст . Во всех категориях используются одни и те же контекстные слова, а форма подсказки

Где, [ В ] м [В]_м[ В ]мЭто контекстное слово, которое можно выучить, ММ.M — суперпараметр,[КЛАСС][КЛАСС][ CL A SS ] — это слово-вставка, соответствующее слову категории. Разумеется, в дополнение к [ CLASS] [CLASS][ CL A SS ] помещается в конце, или вы можете поместить его в середине .

Эта форма более гибкая, поскольку модель может свободно узнать, нужна ли вторая половина контекстных слов. Если нет, она может заранее узнать сигнал завершения, например точку. Однако общий эффект этой формы подсказки в эксперименте не так хорош, как предыдущий
(2) Контекст, специфичный для класса (CSC). В каждой категории используются разные контекстные слова. Автор обнаружил, что CSC особенно подходит для некоторых задач мелкозернистой классификации (например, StanfordCars, Flowers102 и FGVCAircraft).

Условное быстрое обучение для моделей визуального языка[CVPR 2022]
Введение
Эта статья является улучшением CoOp. Автор обнаружил, что векторы контекста, изученные в CoOp, плохо обобщаются на невидимые классы в том же наборе данных (именно так была написана исходная статья). Это показывает, что CoOp чрезмерно имитирует базовый классы, используемые в обучении . Чтобы решить вышеуказанные проблемы, автор предлагает условную контекстную оптимизацию (CoCoOp).На основе CoOp легкая сеть дополнительно обучается генерировать условный токен (вектор) для каждого изображения, чтобы полученные динамические подсказки могли объединять каждое sample.характеристики , поэтому он более устойчив к сдвигу класса.
Эксперименты показывают, что CoCoOp имеет более сильное обобщение невидимых классов, а также более высокую производительность передачи между наборами данных и обобщения предметной области.

CoCoOp: условная оптимизация контекста

Автор считает, что условный экземплярный контекст может лучше обобщаться на невидимые (новые) классы, чем единый контекст в CoOp (он смещает фокус с конкретного набора классов — для уменьшения переобучения) на каждый входной экземпляр, а, следовательно, и на весь задача. они оптимизированы для характеристики каждого экземпляра (более устойчивы к сдвигу класса), а не для обслуживания только некоторых конкретных классов).
В частности, автор представляет Meta-Net h θ h_\thetaчася(двухслойная структура узкого места: Linear-ReLU-Linear, со скрытым слоем, уменьшающим входной размер на 16 × 16 ×16 × .), токен контекста 为vm ( x ) = vm + π v_m(x) = v_m + πвм( х )"="вм+π , гдеvm v_mвмДля вектора контекста CoOp π = h θ ( x ) \pi=h_\theta(x)Пи"="чася( х )
( х ) (х)( x ) — условный токен (вектор) извлеченного изображения.
Ограничения
(1) эффективность обучения. CoCoOp медленно обучается и потребляет значительный объем памяти графического процессора, если размер пакета установлен больше единицы.
(2) способность к обобщению. в 7 из 11 наборов данных (см. Таблицу 1) производительность CoCoOp в невидимых классах по-прежнему отстает от CLIP.
CLIP 改进工作_actionclip模型改进_连理o的博客-CSDN博客
CoCoOp на самом деле является методом, промежуточным между CoOp и CLIP. CoOp изначально был разработан для быстрой априорной адаптации CLIP к последующим задачам. Он повышает точность, жертвуя при этом обобщением, поэтому CoOp является «специализированным» и «хорошим»; в то время как CLIP обеспечивает обобщение от начала до конца, поэтому CLIP хорошо работает на всех наборах данных. но оно недостаточно «точно», то есть «широко» и «грубо». CoCoOp находится где-то между ними, поэтому вопрос: когда нам понадобится CoCoOp? Или сценарии применения CoCoOp действительно широки? Например, если я хочу выполнить определенную последующую задачу, я буду напрямую использовать CoOp. Если я хочу выполнить множество последующих задач одновременно, я выберу CLIP. С этой точки зрения мотивация CoCoOp не очень сильна.
[CVPR 2023] MaPLe: Мультимодальное быстрое обучение
Введение

Автор считает, что одномодальной подсказки недостаточно для полной адаптации к пространству представления мультимодальной модели предварительного обучения, поэтому автор предлагает Multi-modal Prompt Learning (MaPLe) для выполнения быстрого обучения по двум модальностям одновременно в то же время, тем самым еще больше повышая производительность модели в последующих задачах .
Модель MaPLe:

глубокая языковая подсказка. Автор - бывший JJ кодировщика текста.Каждый слой J представил bbb个 обучаемые жетоны{ P i ∈ R dl } i = 1 b \{P^i\in\R^{d_l}\}_{i=1}^b{ Пя€рдя}я = 1бВ соответствии с подсказками языкового контекста (т. е. глубокими подсказками, вы также можете попробовать глубокий VPT, этот, похоже, VPTshallow)


Среди них P j , W j P_j,W_jпдж,Втджсоответственно jjj LayerLj \mathcal L_jлджВывод приглашения и встраивание слова, P 0 P_0п0Инициализированные предварительно обученными внедрениями слов CLIP шаблона «фотография», подсказки остальных слоев инициализируются случайным образом из нормального распределения.
Подсказка глубокого видения. подсказки контекста зрения { P ~ i ∈ R dv } i = 1 b \{\tilde P^i\in\R^{d_v}\}_{i=1}^b{ п~я€рдв}я = 1б由 подсказки языкового контекста 通过 функция связи F : F : R dl → R dv \mathcal F:\R^{d_l}\rightarrow\R^{d_v}Ф:рдя→рдв(т.е. линейный слой) получает

Среди них cj, E j, P ~ j c_j,E_j,\tilde P_jсдж,Эдж,п~джсоответственно jjj LayerVj \mathcal V_jВджвыход [CLS][CLS][ CLS ] , вставить изображение 和подсказка
КЛИП-адаптер
В этой статье достигается лучшая точная настройка производительности по сравнению с CoOp за счет вставки модуля адаптера в кодировщик текста и изображений CLIP.
Метод
Архитектура CLIP Adaptor и ее сравнение с другими методами показаны на рисунке. Изображение пропускается через CNN/ViT для получения визуальных характеристик ff.f , цветная полоса встраивания на изображении.
(a) Наивный классификатор напрямую изучает вес матрицы классификатора WWW
(b) CLIP заключается в ручном создании некоторых подсказок, построении текста вместе с именем категории и извлечении текстовых элементов с помощью текстового кодировщика. Текстовые элементы нескольких категорий образуют матрицуWWW
(c) CoOp также конструирует текст, изучая жетоны подсказок, получает текстовые функции и формирует матрицуWWW
(d) Нижний адаптер CLIP-Adapter вставляет обучаемый адаптер в текстовую башню и визуальную башню и добавляет полученные функции к исходным остаткам функций для получения окончательных выходных функций.

Основные результаты аналогичны CoOp, немного выше.
TIP-адаптер
Tip-Adapter — это аббревиатура CLIP-Adapter без обучения . Как следует из названия, Tip-Adapter может адаптировать CLIP к задачам классификации с несколькими выстрелами без изучения каких-либо параметров. Tip-Adapter объединяет знания нескольких образцов кадров путем построения модели кэша «ключ-значение» и в сочетании с собственными возможностями расчета сходства изображений и текста CLIP выполняет последующие задачи классификации. Tip-Adapter без каких-либо обновлений параметров достиг производительности, близкой к производительности доработанного SOTA того времени. Tip-Adapter и версия Tip-Adapter-F с тонкой настройкой параметров позволяют добиться более высокой производительности.

Метод
Определите обученную модель CLIP и набор задач классификации из нескольких снимков N-way K-shot (N категорий, K выборок на категорию). Цель состоит в том, чтобы одновременно использовать возможности CLIP по расчету сходства изображений и текста и NK выборки. Специальные знания для создания классификатор N-класса. Структура метода Tip-Adapter представлена на рисунке.
В обучающем наборе из нескольких кадров имеются NK-изображения. После прохождения визуального кодировщика CLIP визуальные признаки F train ∈ RNK × C \bf{F}{train}\in\mathbb{R}^{NK\times C}поезд F€рNK × C , где C — размер визуального объекта. Возьмите метку OneHot для N категорий и получите ∗ L train ∈ RNK × N *\bf{L}{train}\in\mathbb{R}^{NK\times N}∗ поезд L€рNK × N。将F поезд \bf{F}{train}F train в качестве ключей используйте∗ L train *\bf{L}{train}* L обучается как значения,мы можем построить модель кэша «ключ-значение». Эта модель кэша содержит все знания в обучающем наборе из нескольких кадров и сочетается с предварительно обученным CLIP для выполнения последующих задач классификации. В этом процессе нет обучения параметров.
Во время тестирования, учитывая тестовое изображение, сначала используйте визуальный кодировщик CLIP, чтобы получить его признак ftest ∈ R 1 × C f_{test}\in\mathbb{R}^{1\times C}жт е т€р1 × C , через модель кэша и классификатор клипов соответственно полученные логиты взвешиваются и объединяются для получения окончательных логитов, которые используются для классификации изображений. Формула расчета итоговых логитов такова:
logits = α ⋅ exp ( − β ( 1 − ftest F train T ) L train + ftest W c T \text{logits}=\alpha\cdot\text{exp}(-\ бета (1-f_{test}F_{train}^T)L_{train}+f_{test}W_c^Tлогиты"="а⋅exp ( − β ( 1−жт е тФпоезд _ _Т) Лпоезд _ _+жт е тВтсТ
где α \альфаα — весовой коэффициент,W c W_cВтс — это предварительно обученный классификатор CLIP (то есть метод классификации с нулевым выстрелом в исходном тексте CLIP) , exp ( − β ( 1 − ftest F train T ) L train \text{exp}(-\beta(1- f_{тест }F_{поезд}^T)L_{поезд}exp ( − β ( 1−жт е тФпоезд _ _Т) Лпоезд _ _Вот как работает модель кэша. где ( 1 − ftest F train T ) (1-f_{test}F_{train}^T)( 1−жт е тФпоезд _ _Т) эквивалентно вычислению евклидова расстояния между характеристиками тестового изображения и характеристиками каждого изображения в обучающем наборе из нескольких кадров с взятием показателя степени, чтобы гарантировать, что все значения положительны, β\betaβ модулирует резкость распределения. Этот процесс эквивалентен извлечению наиболее похожего значения в модели кэша.
Подведем итог
Идея модели кэша аналогична методу прото (прототипа), который уже появился во многих методах малочисленного и метаобучения (таких как MAML, соответствующая сеть и т. д.). Tip-Adapter использует его в CLIP несколько выстрелов обучается, а затем учится на его основе.Метод остаточного соединения в CLIP-Adapter сочетает в себе знания из нескольких выборок в модели кэша «ключ-значение» с возможностью расчета сходства изображений и текста в предварительно обученном CLIP, достигая SOTA-производительности CLIP несколько точная настройка выстрела.
ссылка:
Лекция о работе по улучшению CLIP (Часть 1)_Блог Adenialzz-CSDN
CLIP статья интенсивное чтение по параграфу [интенсивное чтение статьи]_bilibili_bilibili
Лекция по улучшению CLIP (Часть 1) [Интенсивное чтение статьи·42]_bilibili_bilibili