Derzeit ist die digitale Transformation für den Markt nichts Neues. Aus technischer Sicht befinden sich künstliche Intelligenz und Big-Data-bezogene Technologien, wie auch verschiedene Branchen, noch im Innovationsstadium, obwohl das Aufkommen großer Modelle den Menschen mehr Aufmerksamkeit geschenkt hat Suche und Erforschung des Gleichgewichtspunkts der Integration von Wertszenarien und neuen Technologien in der Hoffnung, mit der Unterstützung neuer Technologien eine günstige Position im harten Wettbewerb einzunehmen.
Daten, Daten
Daten sind ein Produktionsfaktor in der neuen Generation der technologischen Revolution. Die Beherrschung der Produktionsfaktoren und ihrer Verarbeitungsmethoden bedeutet die Beherrschung des Wertecodes in der digitalen Wirtschaft. Dies ist bereits ein grundlegender Konsens in der Branche.
Wenn Unternehmen Daten besser verwalten und nutzen wollen, müssen sie die Quelle und Organisationsform der Daten in modernen Unternehmen verstehen. Die digitale Transformation von Unternehmen gliedert sich im Allgemeinen in drei Phasen:
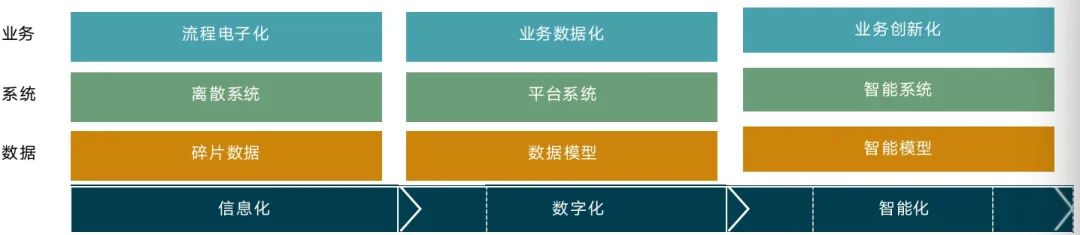
Im Prozess von der Datengenerierung bis zur Datenwertimplementierung wird die Informationsdichte der Daten immer höher und das darin enthaltene Wissen immer reichhaltiger. Durch die Analyse des gesamten Prozesses der Unternehmensdaten können Unternehmen wichtige Zusammenhänge erkennen und Umsetzungspläne entsprechend den örtlichen Gegebenheiten formulieren. Die Analyse des gesamten Datenprozesses ist für jedes Unternehmen die Voraussetzung für die Implementierung von Data Engineering.
Datentechnik
Von der Entstehung der Softwareentwicklung bis zur schrittweisen Ausweitung der Softwareentwicklung haben IT-Praktiker nach und nach Best Practices in Bezug auf Anforderungen, Design, Implementierung, Tests, Betrieb und Wartung usw. gesammelt. Der Datenfluss innerhalb eines Unternehmens durchläuft mehrere Phasen, und zwischen den einzelnen Phasen treten verschiedene Probleme auf.
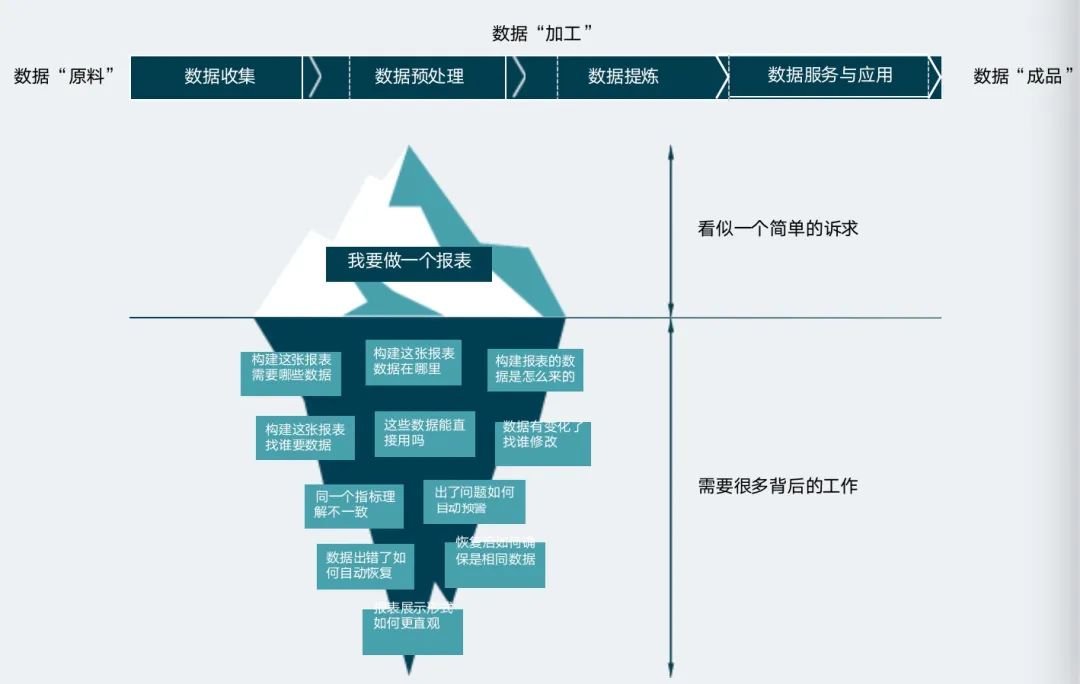
Data Engineering ist die beste Vorgehensweise, um Unternehmen dabei zu helfen, den Wert von Daten effizient auszuschöpfen, das Geschäftswachstum kontinuierlich zu fördern und den Prozess der Sublimation von Daten zu Vermögenswerten zu beschleunigen.
Das Data Engineering umfasst Phasen wie Anforderungen, Design, Konstruktion, Tests, Wartung und Entwicklung und umfasst Projektmanagement, Entwicklungsprozessmanagement, Engineering-Tools und -Methoden, Baumanagement und Qualitätsmanagement. Es handelt sich um eine Reihe von Anforderungen für die Produktion in großem Maßstab und Nutzung von Daten. Das Unternehmen bietet Datenunterstützung und generiert letztendlich Wert.
Data Engineering ist ein System
Data Engineering ist eine Best Practice für die Skalierung, um den Data-to-Value-Prozess zu beschleunigen
Data Engineering ist Teil des Software Engineerings
Beim Data Engineering handelt es sich nicht einfach um ein Wiederaufleben des traditionellen Software-Engineerings im Datenbereich
Für Unternehmen umfasst Data Engineering drei strategische Verbindungen: Ausrichtung der Datenvision, Implementierung des Data Engineering und kontinuierlicher Datenbetrieb.

Der erste Schritt bei der Ausrichtung der Vision besteht darin, Geschäftswertszenarien zu identifizieren, indem das Rahmenwerk zur Messung des Geschäftswerts definiert und vereinheitlicht wird. Die untersuchten Geschäftswertszenarien müssen den Hintergrund des Szenarios, Wertpunkte, beteiligte Benutzer, die erforderlichen Fähigkeiten, Benutzerreisen, beteiligte Entitäten, Risiken und andere Informationen umfassen.
Der Implementierungsprozess ist wie die Geburt eines neuen Lebens, in dem die Datensortierung und -planung, der Datenarchitekturentwurf und das Planungsskelett, der Datenmodellentwurf die Organe bilden, der Datenzugriff die Fähigkeit zur Informationswahrnehmung verleiht, die Datenverarbeitung das zentrale Gehirn bildet und das Test- und Sicherheitsteile sind für das Neugeborene verantwortlich. Um Schutz zu bieten, ist jeder Schritt voneinander abhängig und unverzichtbar. Die Datentechnik wird durch sieben Schritte implementiert: Datensortierung, Datenarchitekturdesign, Datenzugriff, Datenverarbeitung, Datentests, Datensicherheit und Wiederverwendung von Fähigkeiten und Gewissheit.
Der Zweck von Datenoperationen besteht darin, eine „Datenkultur“ zu schaffen, in der Unternehmen Daten betrachten, Daten nutzen und Daten als Kommunikationssprache und -tool nutzen. Nur wenn Daten leicht zu entdecken sind, können sie einen Wert generieren.
Data-Engineering-Kompetenzmodell
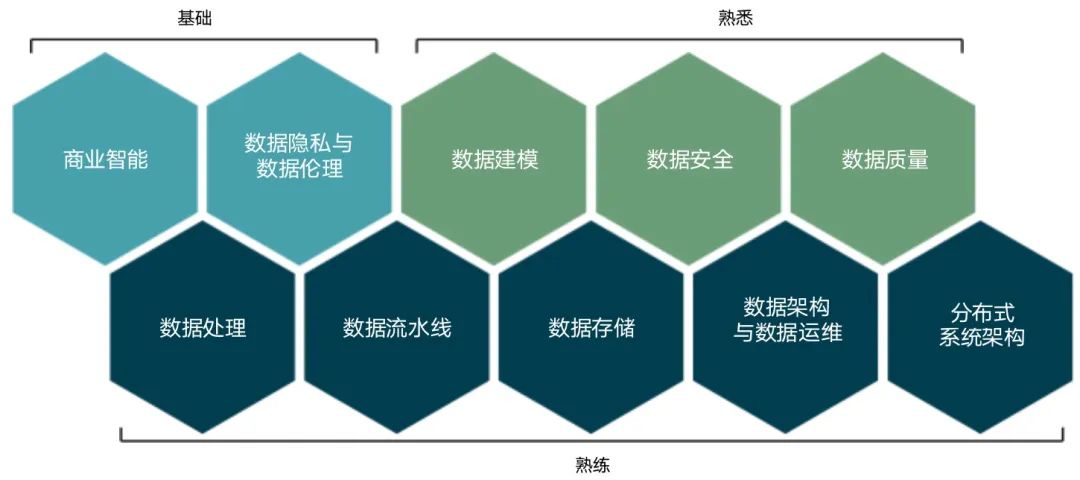
Letztendlich muss die Implementierung des Data Engineering noch von Menschen durchgeführt werden. Der Aufbau eines unternehmenseigenen Schulungsmechanismus für Personalfähigkeiten und der Aufbau eines Kanals zur Verbesserung der Datenfähigkeiten des Unternehmenspersonals sind wichtige Garantien für die kontinuierliche Iteration der Datentechnikfähigkeiten.
Das Kompetenzmodell des Dateningenieurs sieht wie folgt aus:
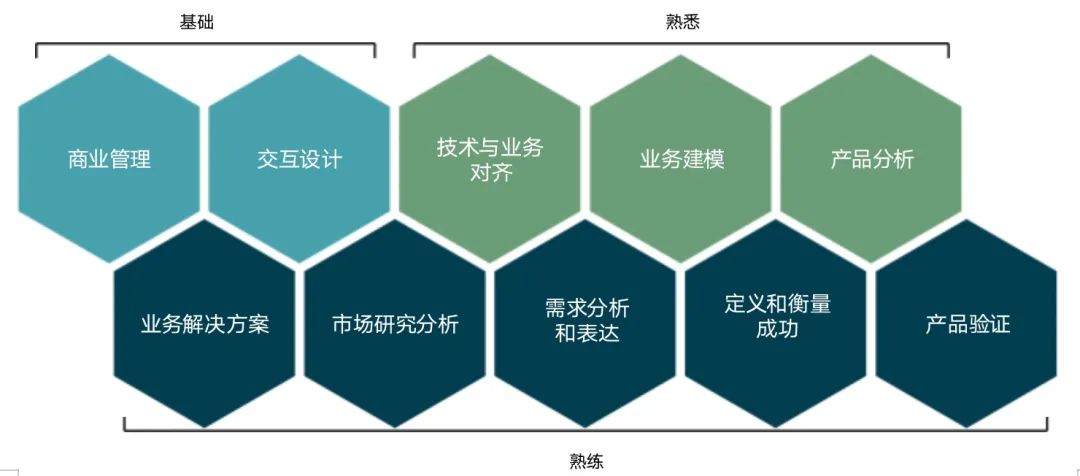
Das Kompetenzmodell von Datenproduktmanagern sieht wie folgt aus:
Das Kompetenzmodell von Datenanalysten sieht wie folgt aus:
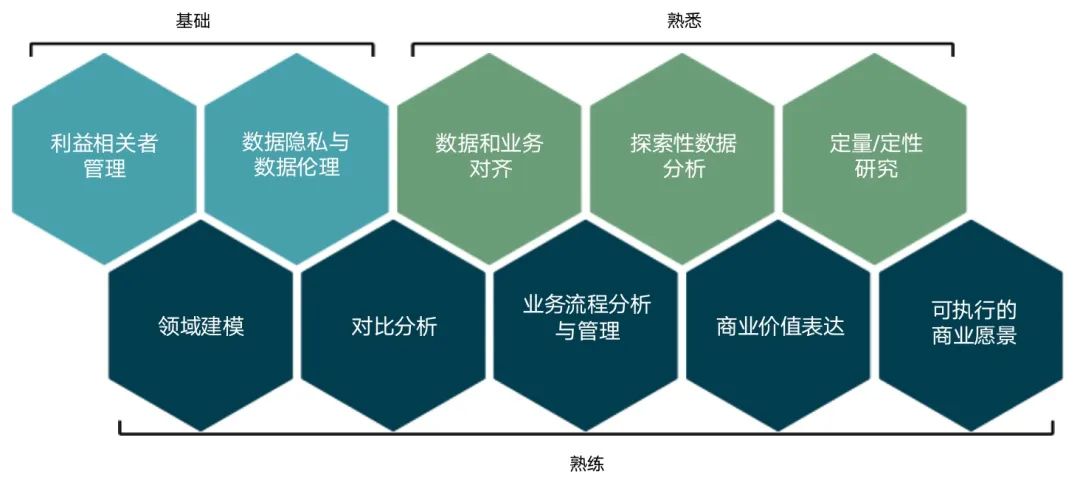
Data Engineering ist eine wichtige Garantie, um die Umwandlung von Datenwerten in der digitalen Wirtschaft sicherzustellen. Es ist ein wichtiges Mittel, um die Umwandlung von Daten in Werte zu beschleunigen. Es muss dem allgemeinen Trend der zukünftigen digitalen Wirtschaft gerecht werden. Um verschiedene neue Probleme im Datenbereich zu bewältigen, entstehen nach und nach verschiedene neue Technologien und neue Konzepte. Moderne Data Warehouses, Data Lakes, Lake-Warehouse-Integration, verteilte Datenarchitektur, maschinelles Lernen, Data Cloud Native usw. sind entstanden einer nach dem anderen auf die Bühne.
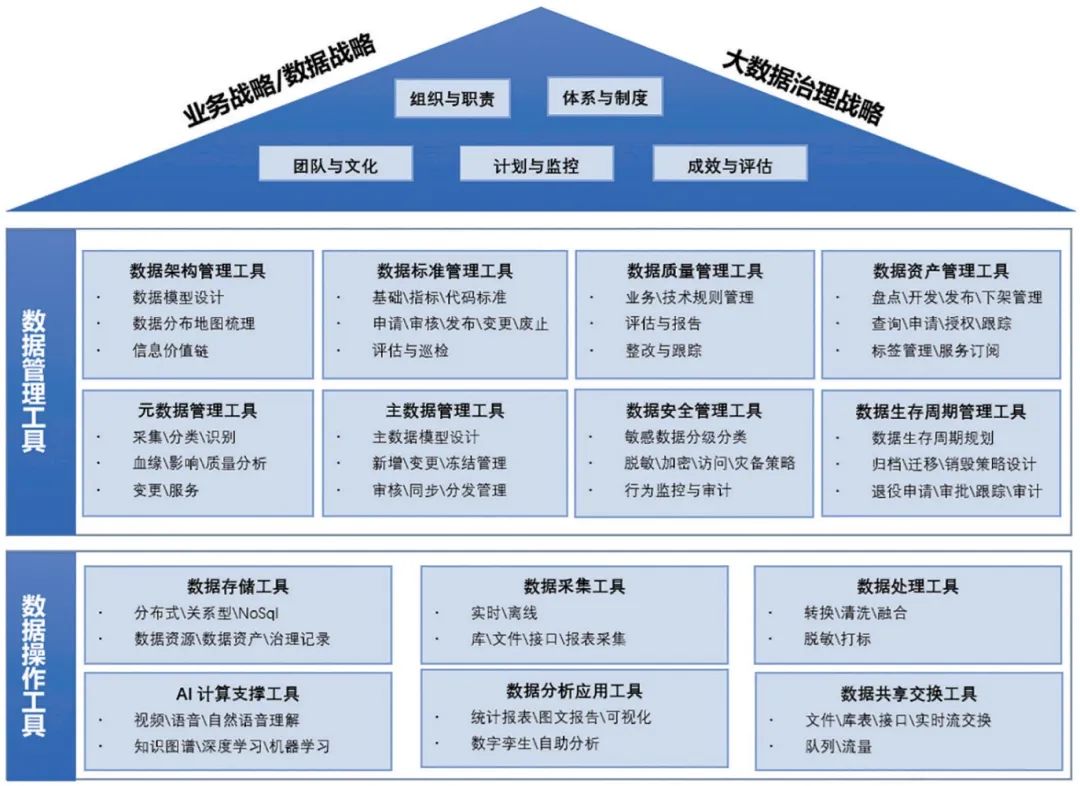
Daten-Engineering-Tool-Karte
Data Engineering ist ein Konzept des Beratungsunternehmens Thoughtworks, aber es ist immer noch alter Wein in neuen Schläuchen. Ich persönlich denke, dass es sich auf Data Governance im herkömmlichen Sinne übertragen lässt. Für die Datenverwaltung gibt es bereits ein relativ ausgereiftes System. Das Folgende ist ein Panorama der Datenverwaltungstools:
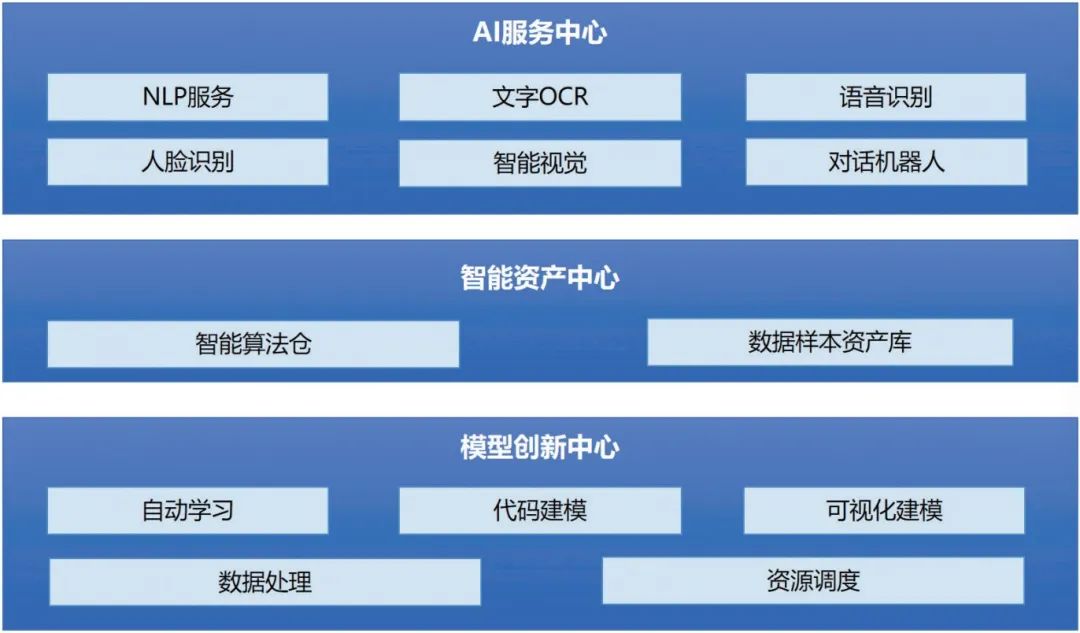
Insbesondere ist die Karte der Tools zur Unterstützung der KI-Rechenfähigkeit in der folgenden Abbildung dargestellt:
Große Modelle und Datentechnik
Durchbrüche in der Entwicklung künstlicher Intelligenz profitieren von der Entwicklung hochwertiger Daten. Daten sind eines der Schlüsselelemente im Wettbewerb großer Modelle. Das Training großer Modelle erfordert hochwertige, umfangreiche und vielfältige Datensätze. und qualitativ hochwertige chinesische Datensätze sind rar. . Der Wert von Branchendaten ist sehr hoch, und Unternehmen mit qualitativ hochwertigen Daten und bestimmten Fähigkeiten für große Modelle können ihr Geschäft durch branchenweite Modelle stärken.
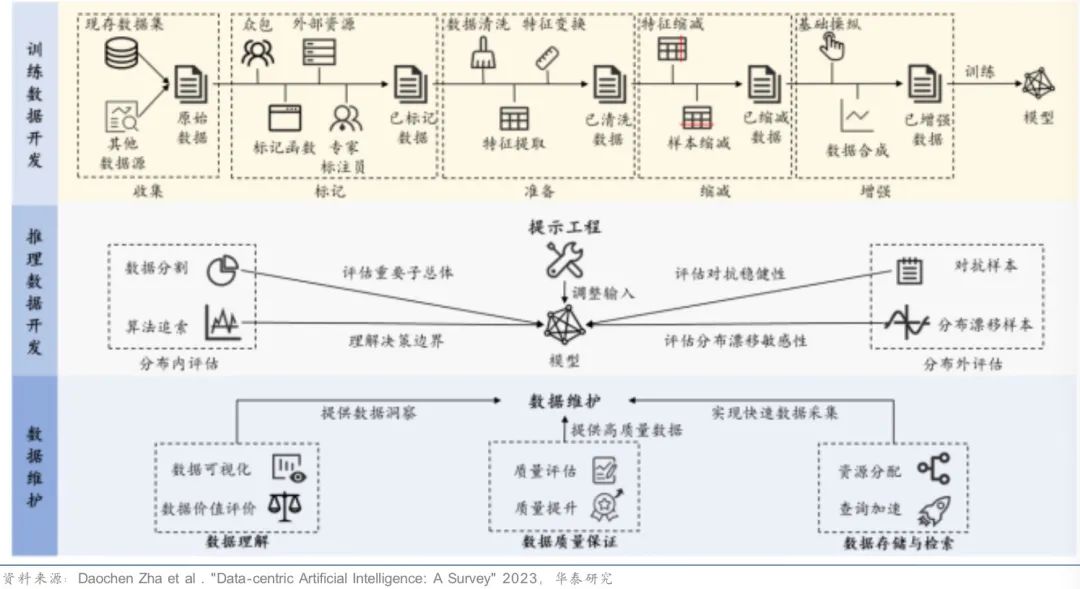
In Zukunft könnte der Anteil der Datenkosten bei der Entwicklung großer Modelle steigen, hauptsächlich einschließlich Datenerfassung, Reinigung, Kennzeichnung und anderer Kosten. Unter der Voraussetzung, dass das Modell relativ fest ist, kann der Trainingseffekt des gesamten Modells durch Verbesserung der Datenqualität und -quantität verbessert werden. Der datenzentrierte KI-Workflow ist in der folgenden Abbildung dargestellt:
Große Sprachmodelldatensätze von GPT-1 bis LLaMA umfassen hauptsächlich sechs Kategorien: Wikipedia, Bücher, Zeitschriften, Reddit-Links, Common Crawl und andere Datensätze. Multimodale große Modelle erfordern tiefere Netzwerke und größere Datensätze für das Vortraining. In den letzten Jahren hat die Menge an multimodalen Parametern und Daten für große Modalitäten weiter zugenommen. Beispielsweise enthält der von Stability AI im Jahr 2022 veröffentlichte Stable Diffusion-Datensatz 5,84 Milliarden Bild-Text-Paare/Bilder, was 23-mal so viel ist wie der von OpenAI im Jahr 2021 veröffentlichte DALL-E-Datensatz.
Inländische Industrien verfügen über reichlich Datenressourcen, und die CAGR des Datenvolumens von 2021 bis 2026 ist höher als die der Welt. Die Daten stammen hauptsächlich aus Regierung/Medien/Dienstleistung/Einzelhandel und anderen Branchen. Laut IDC wird Chinas Datenvolumen von 2021 bis 2026 von 18,51 ZB auf 56,16 ZB steigen, mit einer CAGR von 24,9 %, die über der weltweiten durchschnittlichen CAGR liegt. Obwohl inländische Datenressourcen reichlich vorhanden sind, sind qualitativ hochwertige chinesische Datensätze immer noch rar, da die Datengewinnung unzureichend ist und die Daten nicht frei auf dem Markt zirkulieren können.
Die einzigartigen Daten für das Training des großen Modells „Wenxin“ von Baidu umfassen hauptsächlich Billionen von Webseitendaten, Milliarden von Suchdaten und Bilddaten usw. Die Trainingsdaten für Alibabas großes Modell „Tongyi“ stammen hauptsächlich von der Alibaba DAMO Academy. Die einzigartigen Trainingsdaten des großen Modells „Hunyuan“ von Tencent stammen hauptsächlich aus hochwertigen Daten wie öffentlichen WeChat-Konten und WeChat-Suchen. Neben öffentlichen Daten werden die Trainingsdaten des Huawei-Großmodells „Pangu“ auch durch B-seitige Industriedaten unterstützt, darunter meteorologische, Bergbau-, Eisenbahn- und andere Industriedaten. Die Trainingsdaten des „RiRiXin“-Modells von SenseTime umfassen den selbst generierten multimodalen Omni Objects 3D-Datensatz.
Daher muss das Daten-Engineering von Unternehmen im Zeitalter großer Modelle eine große modellorientierte Datenarchitektur integrieren, bei der Generierung der Daten eine vollständige Selbstanmerkung durchführen und diese durch Daten ergänzen, die von Datendienstanbietern bereitgestellt werden, wobei standardmäßig große Modelle verwendet werden Möglichkeit, ein eigenes Domänenmodell zu bilden.
Warten wir ab!
[Referenzmaterialien und zugehörige Lektüre]
Whitepaper zur Datentechnik – Thoughtworks
Forschungsbericht zur Data-Governance-Tool-Map – China Electronics Technology Standards Institute
Welche Art von Daten werden für große Modelle benötigt – Huatai Securities
Huaweis Datenansatz: Datenklassifizierungsmanagement-Framework und Erfahrung