Código fuente práctico para el desarrollo de rastreadores web: https://github.com/MakerChen66/Python3Spider
No es fácil ser original, el plagio y la reimpresión están prohibidos en este artículo, un resumen de años de experiencia práctica en el desarrollo de rastreadores, se debe investigar la infracción !
Tabla de contenido
1. Introducción de pyquery
1.1 ¿Qué es pyquery?
Antes, presentamos el uso de Beautiful Soup, que es una biblioteca de análisis de páginas web muy poderosa, pero a veces sientes que es un poco inapropiado o inconveniente de usar. ¿Sientes que su selector de CSS no es tan potente? Como biblioteca de análisis que también usa selectores de CSS, pyquery no solo contiene muchos métodos de atributo y selectores de CSS básicos, sino que también admite operaciones de nodo y muchos selectores de pseudoclase, por lo que su función es más poderosa que Beautiful Soup.
1.2 Instalar pyquery
pip install pyquery -i https://pypi.doubanio.com/simple
También puede especificar otras fuentes de espejo
1.3 Importar pyquery
from pyquery import PyQuery as pq
Dos, uso pyquery
2.1 Inicialización
Hay muchas formas de inicializar pyquery, como pasar directamente cadenas, URL, nombres de archivos, etc. entremos en detalle
Inicialización de cadenas
Usemos un ejemplo para tener una idea
from pyquery import PyQuery as pq
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
doc = pq(html)
print(doc('li'))
Primero introduzca el objeto PyQuery, asígnele el nombre pq, luego declare una cadena HTML y pásela a la clase PyQuery como un parámetro, y se completará la inicialización del objeto. Luego pase el objeto inicializado al selector CSS, aquí pasamos el nodo li, para que todos los nodos li puedan ser seleccionados.El resultado de salida es el siguiente: Inicialización de URL Los parámetros de inicialización no solo pueden pasar cadenas,
sino

también
URL
from pyquery import PyQuery as pq
doc = pq(url='https://www.qiushibaike.com/hot/')
print(doc('title'))
El objeto PyQuery primero solicitará esta URL y luego completará la inicialización con el contenido HTML devuelto, lo que equivale a pasar el código fuente de la página web a la clase PyQuery en forma de cadena para inicializar. Tiene la misma función. como el siguiente
código
from pyquery import PyQuery as pq
import requests
doc = pq(requests.get('https://www.qiushibaike.com/hot/').text)
print(doc('title'))
Los resultados de salida son los siguientes:

Inicialización del archivo
Por supuesto, además de pasar cadenas y URL, también se pueden pasar nombres de archivos locales. En este caso, el parámetro debe especificarse como nombre de archivo
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
print(doc('li'))
Aquí se necesita un archivo HTML local demo.html, y su contenido es la cadena HTML que se analizará
2.2 Selectores básicos de CSS
Use un ejemplo para sentir el uso del selector CSS de pyquery:
from pyquery import PyQuery as pq
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li')))
Después de inicializar el objeto PyQuery, se pasa un selector de CSS #container.list li, lo que significa seleccionar primero el nodo cuyo id es container, y luego seleccionar todos los nodos li dentro del nodo cuya clase interna es list, y luego seleccionar el contenido y su tipo de impresión
Los resultados de salida son los siguientes:

Como puede ver, hemos obtenido con éxito el nodo calificado, y su tipo sigue siendo el tipo PyQuery
2.3 Encontrar nodos
A continuación, presentaremos algunas funciones de consulta de uso común. Estas funciones se usan exactamente igual que las funciones en jQuery. El
nodo secundario
necesita usar el método find() para encontrar todos los nodos descendientes. El parámetro pasado en este momento es un Selector de CSS Para evitar la redundancia de código, tomemos el HTML anterior como ejemplo:
doc = pq(html)
items = doc('.list')
html = items.find('li')
print(html)
print(type(html))
Seleccionamos el nodo cuya clase es list, y luego seleccionamos todos los nodos descendientes li dentro del nodo.El
resultado de salida es el siguiente:

si solo queremos encontrar los nodos secundarios, entonces podemos usar el método children():
doc = pq(html)
items = doc('.list')
html = items.find('li')
print(html.children())
print(type(html.children()))
Aquí seleccionamos el nodo cuya clase es list, y luego seleccionamos todos los nodos descendientes li dentro del nodo, y finalmente seleccionamos todos los nodos secundarios del nodo
Los resultados de salida son los siguientes:

Además, el método children() también puede pasar selectores de CSS, de la siguiente manera:
items = doc('.list')
html = items.children('.active')
print(html)
Los resultados de salida son los siguientes:

nodo principal
Podemos usar el método parent() para obtener el nodo principal directo de un nodo, de la siguiente manera:
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(container)
print(type(container))
Primero seleccionamos el nodo cuya clase es list, y luego usamos el método parent() para obtener el nodo padre directo del nodo, cuyo tipo sigue siendo PyQuery. Los resultados de salida son los siguientes: Si desea obtener un nodo
antepasado
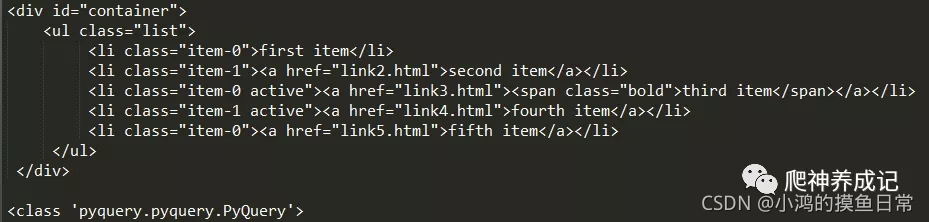
, puede usar el método parent(), de la siguiente manera:
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(parents)
print(type(parents))
De manera similar, el método parent() también puede pasar selectores de CSS, de la siguiente manera:
wrap = items.parents('.wrap')
print(wrap,type(wrap))
Nodos hermanos
Para obtener nodos hermanos, utilice el método brothers(), de la siguiente manera:
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())
El tercer nodo li se selecciona aquí y tiene nodos hermanos 4. Los
resultados de salida del primer, segundo, cuarto y quinto nodo son los siguientes:

de manera similar, el método hermanos () también se puede pasar a un selector CSS para obtener un nodo hermano, de la siguiente manera:
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings('.active'))
La salida es la siguiente:

2.4 Travesía
De lo anterior, podemos observar que el nodo de selección de pyquery puede ser un solo nodo o varios nodos, pero los tipos son todos tipos de PyQuery, en lugar de devolver una lista como Beautiful Soup. Para un solo nodo, se puede imprimir directamente
. También se puede convertir directamente en una cadena, de la siguiente manera:
doc = pq(html)
li = doc('.list .item-0.active')
print(li)
print(str(li))
Los resultados de salida son los siguientes:

Para los resultados de varios nodos, debe atravesar para obtenerlos. Primero use el método items() para convertir el tipo en un tipo de generador, y luego recorra cada nodo li, de la siguiente manera:
doc = pq(html)
lis = doc('li').items()
print(lis)
for li in lis:
print(li,type(li))
Después de llamar a los elementos (), obtendrá un generador que debe atravesarse para obtener los objetos del nodo li uno por uno. El tipo de nodo también es el tipo PyQuery. Los resultados de salida son los siguientes: Extensión: también puede
usar
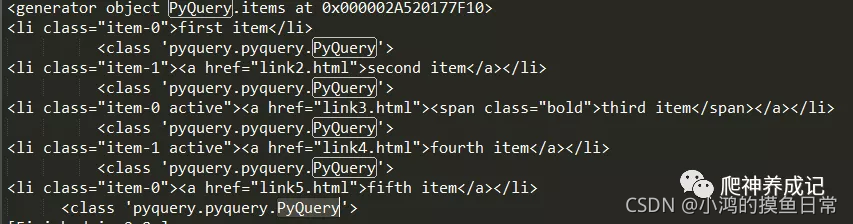
la enumeración () método para atravesar de nuevo, de modo que pueda obtener cada El número de serie del nodo:
doc = pq(html)
lis = doc('li').items()
print(lis)
for i,li in enumerate(lis):
print(i,li,type(li))
La salida es la siguiente:
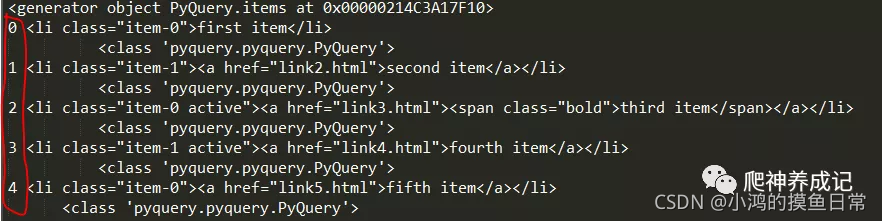
2.5 Acceso a la información
Después de encontrar el nodo, nuestro objetivo final es, por supuesto, extraer la información contenida en el nodo. La información más importante incluye los atributos y la
adquisición
de texto . Después de extraer los atributos a un nodo de tipo PyQuery, el método attr() puede ser llamado para obtener los atributos, de la siguiente manera:
doc = pq(html)
a = doc('.item-0.active a')
print(a,type(a))
print(a.attr('href'))
Los resultados de salida son los siguientes:

los atributos también se pueden obtener llamando al atributo attr
print(a.attr.href)
Los resultados de estos dos métodos son exactamente iguales.
Nota : cuando el resultado devuelto contiene varios nodos, llamar al método attr() solo obtendrá los atributos del primer nodo. Para obtener todos los atributos del nodo, debe usar el ya mencionado
Obtener el texto
Llamar al método text() para obtener el texto interno del nodo, de la siguiente manera:
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())
Los resultados de salida son los siguientes:

si desea obtener el texto HTML dentro de este nodo, debe usar el método html(), de la siguiente manera:
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())
La salida es la siguiente:

3. Operación del nodo
pyquery proporciona una serie de métodos para modificar nodos dinámicamente, como agregar o eliminar un atributo para un nodo, eliminar un nodo, etc. Estas operaciones a veces brindan un gran recorrido para extraer información. AddClass y removeClass Usamos un ejemplo para
sentirlo
:
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)
Los resultados de salida son los siguientes:

Por lo tanto, los métodos addClass() y removeClass() pueden cambiar dinámicamente el atributo de clase del nodo attr
, text y html.text
html = '''
<ul class="list">
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
</ul>
'''
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name','link')
print(li)
li.text('changed data')
print(li)
li.html('<span>changed data</span>')
print(li)
Primero seleccione el nodo li, luego llame al método attr() para modificar el atributo, el primer parámetro de este método es el nombre del atributo, el segundo parámetro es el valor del atributo y luego llame al método text() y al método html() para cambiar el contenido interno del contenido del nodo, imprima
Los resultados de salida son los siguientes:

Nota : si el método attr() solo pasa el nombre del atributo del primer parámetro, es para obtener el valor del atributo, y si se pasa el segundo parámetro, se puede usar para modificar el valor de atributo; el método text() Si el método y html() no pasa parámetros, obtendrá el texto sin formato y el texto HTML en el nodo, de lo contrario, se asignará
.
cierto nodo, lo que a veces trae una gran conveniencia para extraer información:
html = '''
<div class="wrap">
hello,world
<p>this is a paragraph</p>
</div>
'''
doc = pq(html)
wrap = doc('.wrap')
wrap('p').remove()
print(wrap.text())
La salida es la siguiente:
hello,world
4. Selector de pseudo clase
Otra razón importante por la que los selectores de CSS son potentes es que admiten una variedad de selectores de pseudoclase, como seleccionar el primer nodo, el último nodo, nodos pares e impares, nodos que contienen un texto determinado, etc.
from pyquery import PyQuery as pq
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
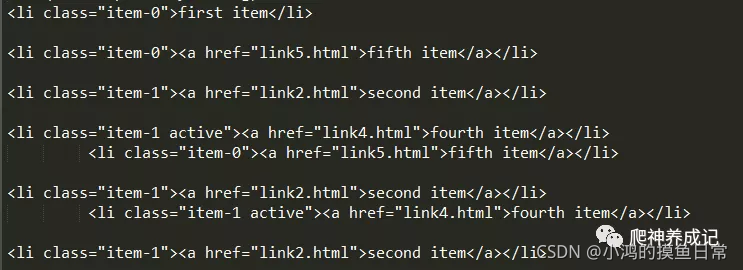
doc = pq(html)
li = doc('li:first-child')
print(li)
li = doc('li:last-child')
print(li)
li = doc('li:nth-child(2)')
print(li)
li = doc('li:gt(2)')
print(li)
li = doc('li:nth-child(2n)')
print(li)
li = doc('li:contains(second)')
print(li)
Aquí se usa el selector de pseudoclase de CSS3, y el primer nodo li, el último nodo li, el segundo nodo li, el nodo li después del tercer li, el nodo li con una posición par y el li que contiene el segundo texto se seleccionan en secuencia
El resultado del es el siguiente:
Resumen
Hasta ahora, se ha introducido el uso común de pyquery y sus funciones son muy potentes. Muchas operaciones no están disponibles en bibliotecas de análisis como lxml y Beautiful Soup. Para obtener más
información uso de selectores CSS, consulte el enlace:
https: //www.w3school.com.cn/css/index.asp
Para obtener más información sobre el uso de la biblioteca de análisis de pyquery, consulte el enlace:
https://pyquery.readthedocs.io
5. Enlace al texto original
Enlace al texto original de mi cuenta pública original: Haga clic en mí para leer el texto original
La originalidad no es fácil, si lo encuentras útil, espero que puedas darle un pulgar hacia arriba, ¡gracias chicos!
6. Información del autor
Autor: Xiaohong's Fishing Daily, Objetivo: ¡Hacer la programación más interesante!
Cuenta pública original de WeChat: " Tecnología Xiaohong Xingkong ", centrada en algoritmos, rastreadores, sitios web, desarrollo de juegos, análisis de datos, procesamiento de lenguaje natural, IA, etc. Esperamos su atención, ¡crezcamos y codifiquemos juntos!
Instrucciones de reimpresión: ¡Este artículo prohíbe el plagio y la reimpresión, y la infracción debe investigarse!