Este artículo es la parte 2 de la serie DeepSpeed:
referencia:
tutorial de aprendizaje de velocidad profunda: conozca
Introducción a la tarea: en el tercer paso (Paso 3), la fase de aprendizaje por refuerzo requiere el uso de un modelo de recompensa. El modelo de recompensa calificará las respuestas generadas por el modelo, y el entrenamiento intensivo del Paso 3 optimizará el modelo en función de estos puntajes, de modo que el modelo final pueda generar respuestas con puntajes más altos. El modelo de recompensa también se entrena en función del modelo previamente entrenado, aquí utilizamos el modelo opt 350M.
1. Modifique el archivo de configuración y agregue el siguiente contenido
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/training_scripts/single_gpu
vim run_350m.sh
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--num_train_epochs 1 \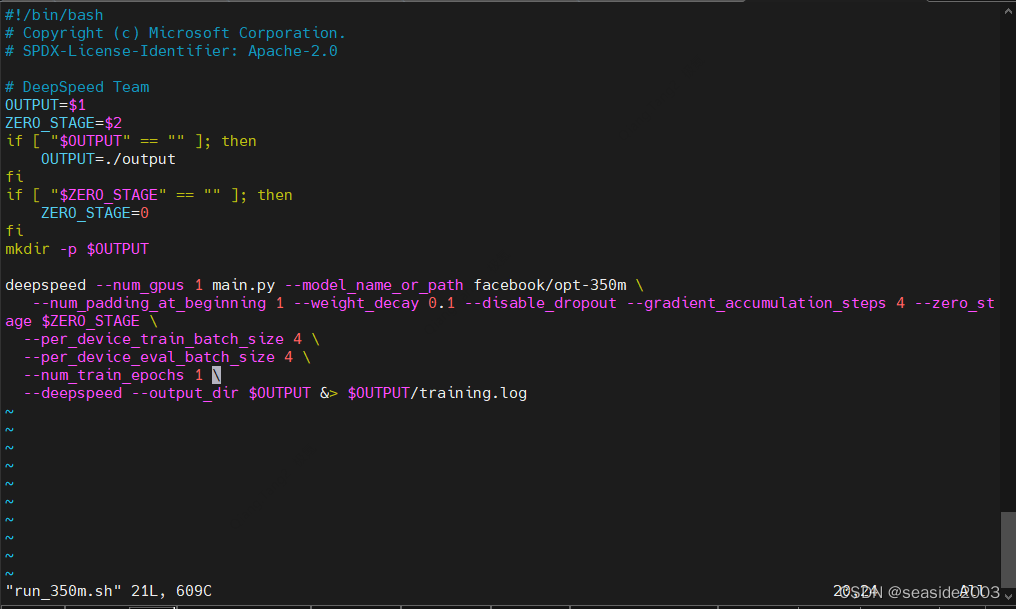
2. Ejecute el guión de entrenamiento.
Cambiar directorios:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-ChatEjecutar entrenamiento:
# Entrenamiento de GPU única
python3 train.py --step 2 --deployment-type single_gpu
Nota: No hay resultados en esta ventana, debe verlos a través del registro. Además, dado que este comando descargará archivos automáticamente, se recomienda cambiar al estado científico en línea.
Una vez completada la capacitación, la interfaz es la siguiente: tomó aproximadamente 30 minutos entrenar 1 época:

Nota: Si tiene varias GPU o varios nodos, puede utilizar el siguiente comando
python3 train.py --step 2 --deployment-type single_node #多GPU训练
python3 train.py --step 2 --deployment-type multi_node #多Node训练3. Datos de entrenamiento
Solo se utilizan datos estáticos de Dahoas/rm durante el entrenamiento de una sola GPU.
El entrenamiento con múltiples GPU utiliza más datos:
Dahoas/rm-static
Dahoas/full-hh-rlhf
Dahoas/synthetic-instruct-gptj-pairwise
yitingxie/rlhf-reward-datasets
openai/webgpt_comparisons
stanfordnlp/SHP4. Abra una nueva ventana para ver el progreso del entrenamiento a través del registro .
less output/reward-models/350m/training.log
……
……
Una vez completada la capacitación, verifique los detalles a través del Registro:

5. Ver el modelo generado.
Los archivos de modelo generados se encuentran en el siguiente directorio:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/output/reward-models/350m![]()

6. Evaluación y pruebas
- Agregar parámetros de posición del modelo
Abra el archivo run_eval.sh y configure el parámetro --model_name_or_path
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/evaluation_scriptsPrimero convierta el formato del archivo; de lo contrario, aún se informará un error
dos2unix run_eval.shMover al directorio step2_reward_model_finetuning
implementar:
bash evaluation_scripts/run_eval.sh