Iniciar controlador
Cambie al directorio FastChat y ejecute el siguiente comando:
python3 -m fastchat.serve.controller
Aunque se produzca ERROR, más adelante se comprobará que no tiene impacto, así que no te preocupes.
Iniciar trabajador modelo
Abra una nueva ventana y ejecute el siguiente comando. Cuando el proceso complete la carga del modelo, verá "Uvicorn ejecutándose en...". También hay algunos ERRORES a continuación, así que ignórelos:
python3 -m fastchat.serve.model_worker --model-name 'vicuna-7b-v1.1' --model-path /home/train/mycharm/new/vicuna
Enviar mensaje de prueba
Abre una nueva ventana y ejecuta el siguiente comando, aparecerá una línea de texto y finalizará:
python3 -m fastchat.serve.test_message --model-name vicuna-7b-v1.1
Inicie el servidor web de gradio
En esta ventana, ejecute los siguientes comandos. Si hay algunos ERRORES, ignórelos:
python3 -m fastchat.serve.gradio_web_server
La asignación de puertos
En este momento, puede acceder a esta dirección en el servidor, pero el servidor generalmente no tiene una interfaz y necesita ser mapeado.
Abra una nueva ventana y ejecute el siguiente comando:
sudo iptables -t nat -A PREROUTING -p tcp --dport 8080 -j REDIRECT --to-port 7860Luego ejecuta:
sudo service iptables save
Ahora es el momento de presenciar el milagro: puedes abrir el navegador y chatear con la modelo. Puede acceder al servicio a través de la dirección IP de la intranet: número de puerto. La dirección específica y el número de puerto deben modificarse de acuerdo con su propia configuración.
El mío es: http://11.137.12.85:8080/
Después de una operación exitosa, la interfaz se muestra a continuación y podrá tener conversaciones normales:
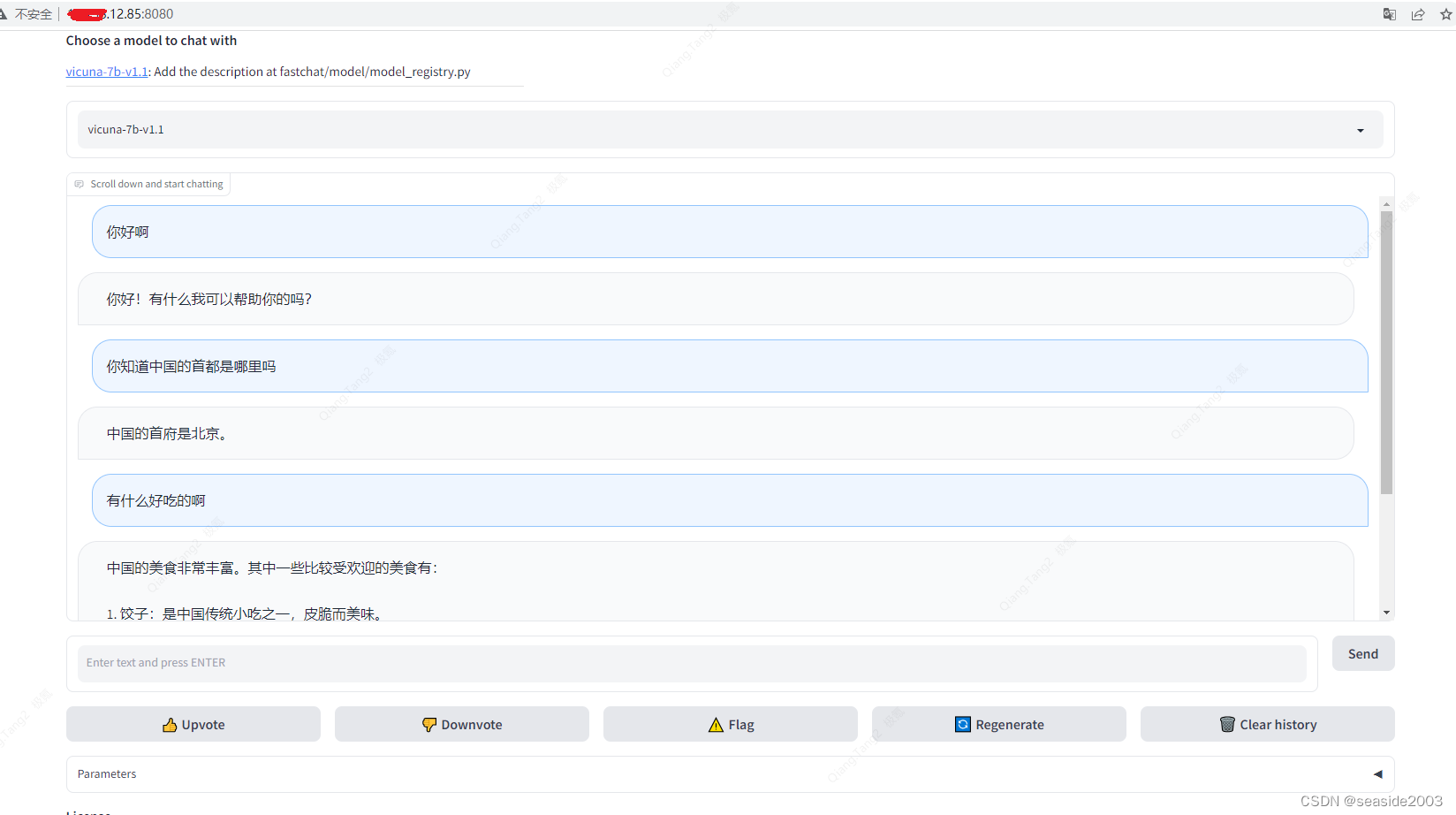
Después de devolver exitosamente el contenido, las tres ventanas responden a la solicitud:



Consumo de recursos de GPU:

¡En este punto, se ha completado todo el trabajo excepto la capacitación y las felicitaciones!
Finalmente me gustaría mencionar que este post no está mal, puedes consultar:
Errores y soluciones:
Se produjo el siguiente error al ejecutar: python3 -m fastchat.serve.controller:
ERROR: [Errno 98] error al intentar vincular la dirección ('127.0.0.1', 21001): la dirección ya está en uso
Principalmente debido a la ocupación del puerto, es necesario encontrar el pid correspondiente al puerto y eliminarlo.

Ejecute el siguiente comando:
sudo netstat -tunlpSe puede observar que el pid correspondiente al puerto 21001 es 810758
Ejecute el siguiente comando:
sudo kill -9 810758Luego, ejecutarlo nuevamente tendrá éxito:
python3 -m fastchat.serve.controller