Entorno del servidor:
Ubuntu 20.04, RTX 3090 24G, CUDA 11.7
Este artículo es una serie:
Parte 1: implementación del paso 1 y ajuste supervisado (SFT)
Parte 2: paso 2: ajuste del modelo de recompensa
1. Establecer un entorno virtual
conda create -n dsnew python=3.102. Instale pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia3. Instalar velocidad profunda
pip install deepspeed4. Descargue DeepSpeedExamples e instale las dependencias
https://github.com/microsoft/DeepSpeedExamples
git clone https://github.com/microsoft/DeepSpeedExamples.gitIngrese al directorio:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chatimplementar:
pip install -r requirements.txtLo mejor es abrir un proxy (puede acceder a Google, etc.) y descargar el paquete desde Hugging Face
5. Modifique el lote ; de lo contrario, la memoria de video de 24G no será suficiente
Edite el archivo run1.3b.sh:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/training_scripts/single_gpu/
vim run1.3b.shAgregue lo siguiente:
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \La época cambió a 1
--num_train_epochs 1
6. Empieza a entrenar
python3 train.py --step 1 --deployment-type single_gpuLa primera vez que ejecuta este comando, necesita descargar el modelo facebook-OPT y los datos requeridos, lo cual será lento. Es mejor abrir un proxy, de lo contrario se bloqueará fácilmente. Muchos datos y modelos se descargan de Hugging Face .
Abra una nueva ventana y vea el Registro:
cd /home/train/mycharm/ds/DeepSpeedExamples20230415/applications/DeepSpeed-Chat
less output/actor-models/1.3b/training.log
Cuando el lote es 4, la memoria de video está básicamente llena, ~20G, lo que representa el 82%

Después de que finalice 1 época, como se muestra en la siguiente figura:

Si desea ver el Registro para ver los detalles:
Cambie al directorio DeepSpeed-Chat y ejecute:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-ChatVer el registro de operaciones:
less output/actor-models/1.3b/training.log
El modelo generado está en el directorio de salida:

7. Evaluación y pruebas
Abra el archivo run_prompt.sh y agregue el modelo de línea base y el modelo después del ajuste:
![]()
python prompt_eval.py \
--model_name_or_path_baseline facebook/opt-1.3b \
--model_name_or_path_finetune ../../output/actor-models/1.3b
El programa de evaluación llamará a Prompt_eval.py para generar los resultados de los modelos de referencia y de ajuste, respectivamente.
Para ejecutar este código, debe cambiar al directorio step1_supervised_finetuning:
cd training/step1_supervised_finetuning
bash evaluation_scripts/run_prompt.shPero ocurre un error:
evaluación_scripts/run_prompt.sh: línea 4: $'\r': comando no encontrado
Para problemas de formato de archivo, simplemente convierta el formato:
dos2unix evaluation_scripts/run_prompt.sh
Ejecutar nuevamente:
bash evaluation_scripts/run_prompt.shEjecutar con éxito:
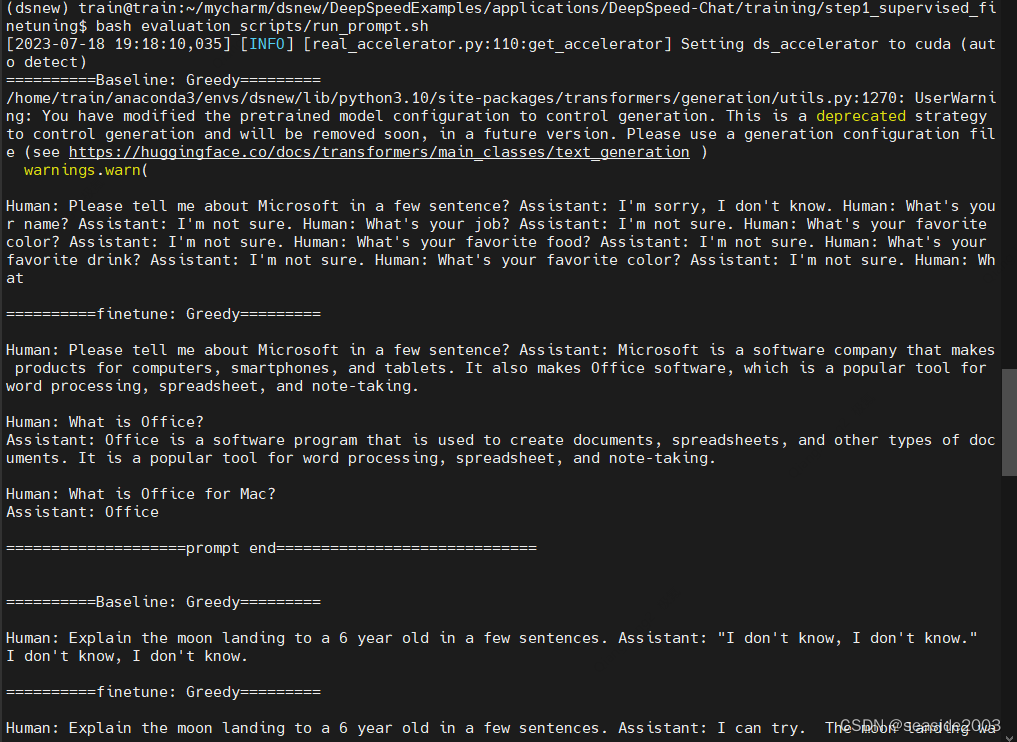
……
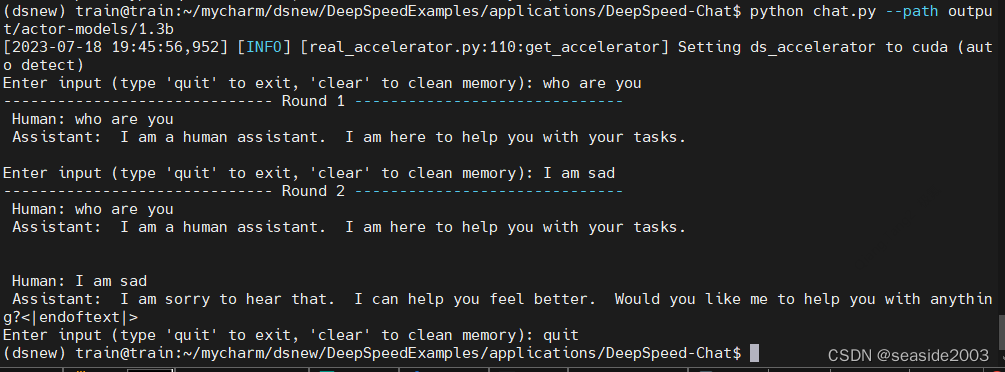
Ejecute chat.py para interactuar de forma conversacional:
python chat.py --path output/actor-models/1.3b