Antecedentes
Para resolver el problema sistémico de la iteración de características y modelos de la empresa y mejorar la eficiencia del desarrollo y la iteración de algoritmos, el departamento estableció el proyecto de plataforma de características. La plataforma de funciones tiene como objetivo resolver problemas como el almacenamiento de datos dispersos, calibres duplicados, extracción compleja y enlaces largos, construir un puente científico entre big data y algoritmos, y proporcionar un sólido soporte de datos de características y muestras. La plataforma realiza ETL de datos rápido desde Hive, Hbase, combinado con capas ODS (almacenamiento de datos operativos) de big data, capas DWD y DWS, como bases de datos relacionales, extrae datos a la plataforma de funciones para su administración y unifica la exportación de datos para científicos de datos. , Los ingenieros de datos y los ingenieros de aprendizaje automático realizan pruebas de datos, capacitación, inferencia y otras aplicaciones de datos de modelos de algoritmos.
Este artículo comparte principalmente la práctica de implementación de la plataforma de funciones flink en K8 y la presenta principalmente en los siguientes aspectos. Primero, este artículo presenta brevemente los conceptos básicos de K8 y el diagrama de ejecución de tareas de Flink, y luego compara varios métodos de implementación de Flink en K8 existentes.
¿Por qué debería implementarse flink en función de los K8?
Principalmente existen las siguientes ventajas:
El entorno del contenedor es fácil de implementar, limpiar y reconstruir: a diferencia de un entorno virtual distribuido e implementado como una imagen, tiene poca dependencia del entorno del sistema subyacente. Todos los paquetes necesarios se pueden integrar en la imagen y reutilizar.
Mejor aislamiento y seguridad, la implementación de aplicaciones se inicia con pods, los pods son independientes entre sí y el entorno de recursos es más seguro después del aislamiento.
Los clústeres K8 pueden hacer un buen uso de los recursos y muchas tareas, como el aprendizaje automático y los servicios en línea, se pueden implementar de manera mixta.
La tendencia de la nube nativa, el rico ecosistema k8s y la tendencia de la nube nativa en la computación de big data
Introducción
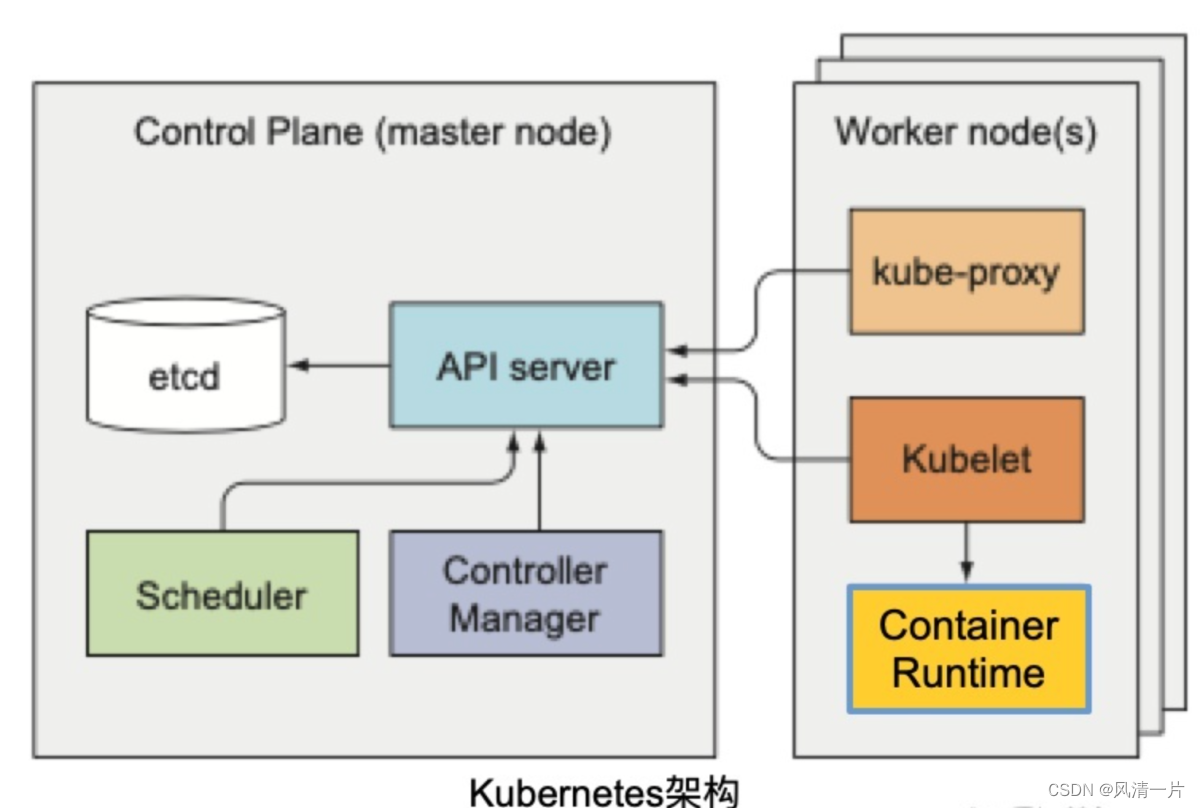
2.1 K8s Introducción
Kubernetes le proporciona un marco que puede ejecutar sistemas distribuidos de manera flexible. Kubernetes cumplirá con sus requisitos de expansión, conmutación por error, modos de implementación, etc. La esencia del proyecto Kubernetes es proporcionar a los usuarios una herramienta universal de orquestación de contenedores.
K8S, conocido como el sistema operativo de la era de la nube (la imagen que contiene es similar a un paquete de instalación de software),
tiene como objetivo proporcionar "implementación y expansión automáticas en clústeres de hosts y una plataforma para ejecutar contenedores de aplicaciones",
programación, gestión de recursos, descubrimiento de servicios, verificación de estado, escalado automático, actualizaciones continuas...
componentes básicos
Pod: la unidad de programación atómica de K8, que es una combinación de uno o más contenedores. Los contenedores comparten la misma red y almacenamiento.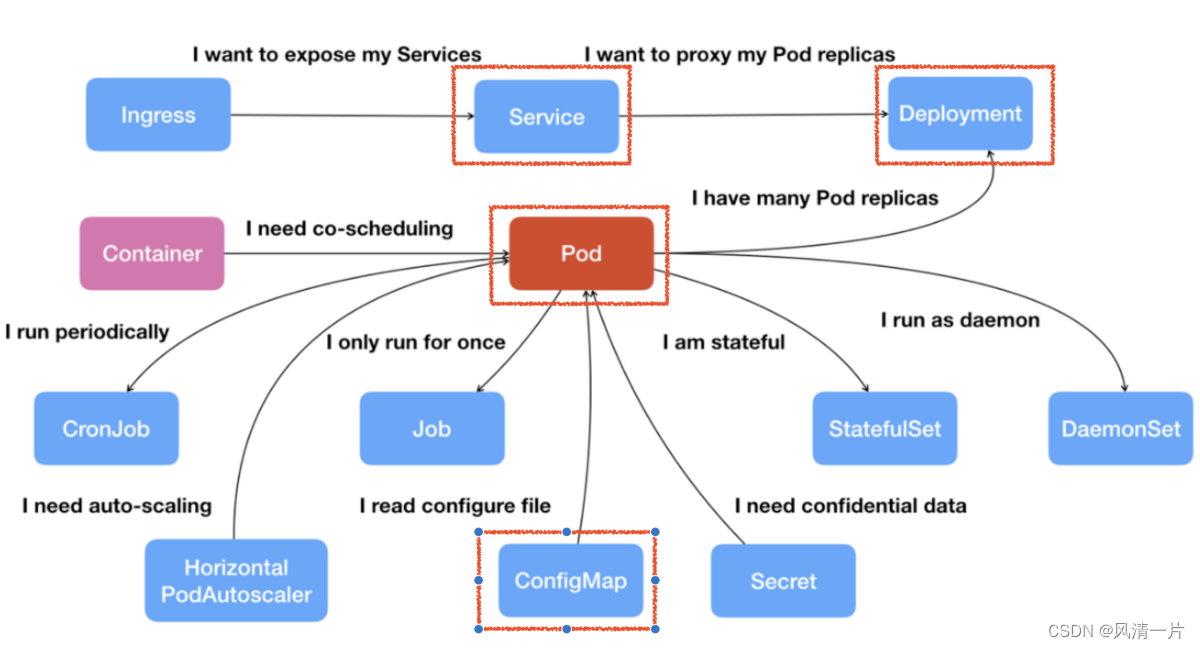
Implementación: una abstracción de alto nivel para un grupo de Pods idénticos que pueden reiniciarse y recuperarse automáticamente para garantizar una alta disponibilidad.
Servicio: defina la entrada de acceso del servicio y vincule el conjunto de réplicas del pod de backend a través del selector de etiquetas. Si hay un servicio dentro de K8 al que se debe acceder externamente, puede exponerlo a través del Servicio usando LoadBalancer o NodePort. Si no desea o necesita exponer el servicio al mundo exterior, puede configurar el servicio en modo IP de clúster o Ninguno.
ConfigMap: datos de estructura KV, el uso habitual es montar ConfigMap en Pod como un archivo de configuración para nuevos procesos en Pod.
Con estado: implementación de aplicaciones con estado
Trabajo vs. Cronjob - Negocios sin conexión
2.2 Introducción a Flink
Apache Flink es un marco y un motor de procesamiento distribuido para cálculo con estado en flujos de datos acotados e ilimitados. Flink se ejecuta en todos los entornos de clúster comunes y computa a la velocidad de la memoria y en cualquier escala.
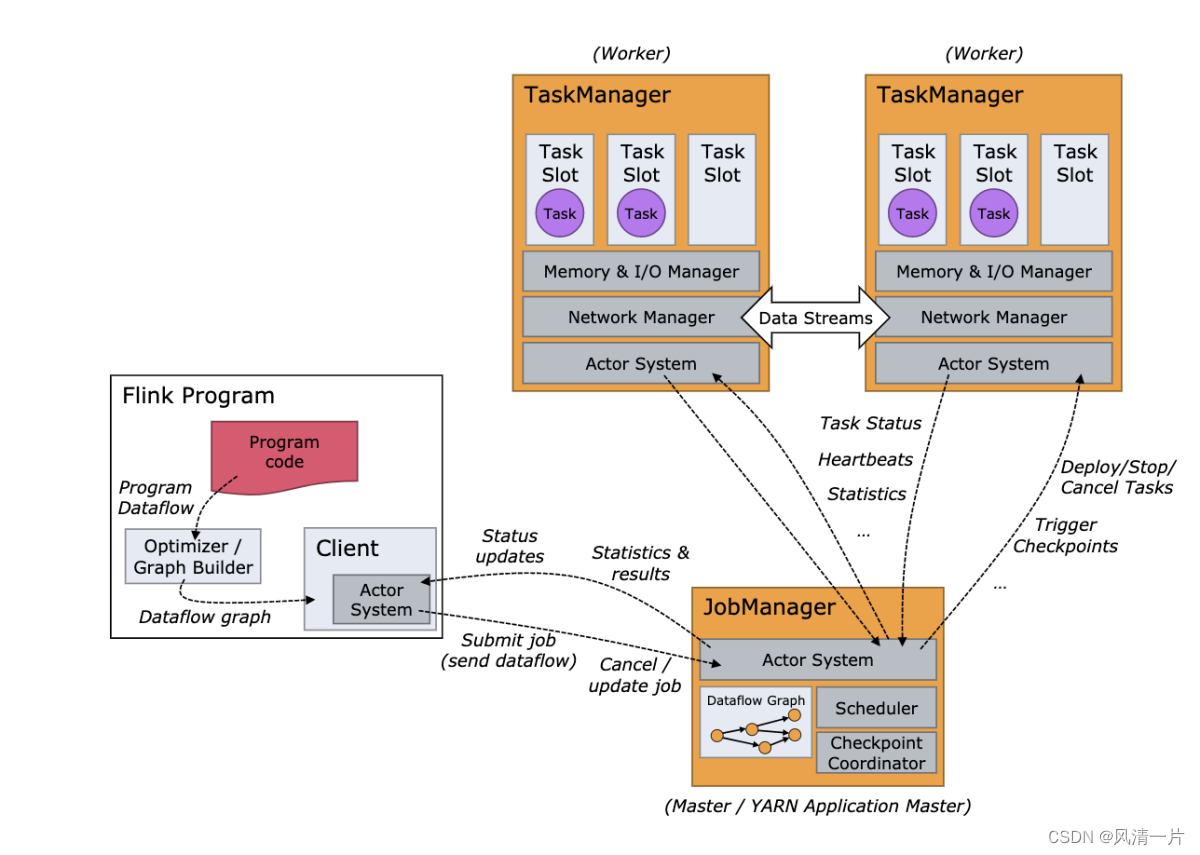
2.2.1 Diagrama de arquitectura de Flink
El diagrama de arquitectura de Flink es similar a las estructuras de big data comunes: todas adoptan la arquitectura principal maestro-esclavo, se puede realizar un JobManager, múltiples TaskManagers y la implementación HA de JobManagers.
El código de Flink necesita pasar por varias conversiones de gráficos desde el envío hasta la ejecución real, el proceso es el siguiente: StreamGraph -> JobGraph -> ExecutionGraph -> Physical Execution Graph
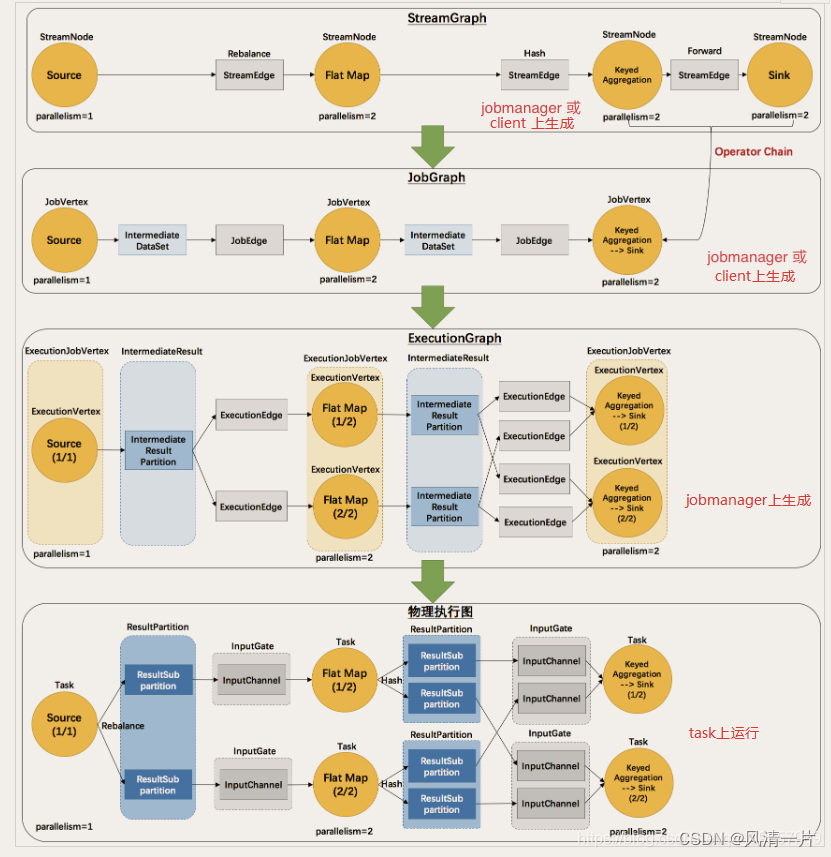
La primera capa de StreamGraph comienza desde el nodo Fuente. Cada transformación genera un StreamNode. Los dos StreamNodes están conectados entre sí a través de StreamEdge para formar un DAG compuesto por StreamNode y StreamEdge.
La segunda capa de JobGraph aún comienza desde el nodo Fuente y luego la atraviesa para encontrar operadores que se puedan incrustar juntos. Si se pueden incrustar juntos, se incrustarán juntos. Si no se pueden incrustar juntos, generarán jobVertex por separado. El JobVertex ascendente y descendente se vinculará a través de JobEdge para finalmente formar DAG en el nivel JobVertex.
Después de enviar JobVertex DAG a la tarea, se ordena a partir del nodo Fuente, ExecutionJobVertex se genera en función de JobVertex, IntermediateResult se construye en función del IntermediateDataSet de jobVertex y luego IntermediateResult crea dependencias ascendentes y descendentes para Forme un DAG en el nivel ExecutionJobVertex, es decir, ExecutionGraph.
Finalmente, a través de la capa ExecutionGraph hasta la capa de ejecución física.
Modo de implementación de Flink en K8
3.1 Modo de implementación de Flink [1]
Modo de sesión
Varios envíos de trabajos comparten el mismo JobManager y todos los trabajos han creado y compartido una instancia de Flink Cluster. Las tareas de Flink son enviadas por el cliente, que realiza un trabajo preparatorio y genera JobGraph en el Cliente Flink. La desventaja de este método es que la falla del JobManager causada por un trabajo puede causar la falla de todos los trabajos.
Modo por trabajo
Inicie un JM dedicado para cada envío de trabajo, el JM simplemente ejecutará este trabajo y luego saldrá. Generar JobGraph en el cliente Flink,
Puede entenderse como el modo de aplicación del modo cliente, que aprovecha al máximo las ventajas de los marcos de gestión de recursos, como Yarn, Mesos, etc., para lograr un mayor aislamiento de recursos y las aplicaciones flink no se afectarán entre sí. Un trabajo es una instancia de clúster.
Modo de aplicación
El programa enviado por Flink se considera la aplicación dentro del clúster y el cliente ya no necesita realizar un trabajo de preparación pesado, como ejecutar la función principal.
número, generar JobGraph, descargar dependencias y distribuir a cada nodo, etc.), la función principal se envía al JobManager para su ejecución.
Una aplicación tiene una instancia de clúster.
3.3 Deficiencias de la implementación independiente
Los usuarios deben tener algunos conocimientos básicos de los K8 para garantizar el funcionamiento fluido de Flink en los K8.
Flink no percibe la existencia de K8.
En la actualidad, se utiliza principalmente la asignación de recursos estática. Es necesario confirmar de antemano cuántos TaskManager se necesitan. Si es necesario ajustar la concurrencia del Trabajo, los recursos del TaskManager deben mantenerse al día en consecuencia, de lo contrario la tarea no se puede ejecutar normalmente.
Es imposible solicitar y liberar recursos en tiempo real. Si mantiene un clúster de sesiones relativamente grande, es posible que se desperdicien recursos. Sin embargo, si el clúster de sesión mantenido es relativamente pequeño, es posible que el trabajo se ejecute lentamente o no se ejecute.
3.4 Ventajas de la implementación de Navtive
Método de aplicación de recursos: el cliente de Flink tiene un cliente K8s incorporado. Puede utilizar el cliente K8s para crear un JobManager. Después de enviar el trabajo, si hay una demanda de recursos, el JobManager solicitará recursos. del propio ResourceManager de Flink. En este momento, el ResourceManager de Flink se comunicará directamente con el servidor API de K8s, enviará estos recursos solicitados directamente al clúster de K8s y le dirá cuántos TaskManagers se necesitan y qué tamaño tiene cada TaskManager. Cuando la tarea termine de ejecutarse, también le indicará al clúster K8 que libere los recursos no utilizados. Es equivalente a que Flink conozca la existencia del K8s Cluster de una manera muy nativa y sepa cuándo solicitar recursos y cuándo liberarlos.
Native se compara con Flink. Con la ayuda de los comandos de Flink, puede lograr un estado de autonomía. Puede usar Flink para completar tareas y ejecutarlas en K8 sin introducir herramientas externas.
3.5 Selección final del plan de implementación
A través del análisis de los modos nativo y autónomo de Flink, el autónomo necesita cooperar con la implementación de kubectl + yaml. Flink no puede detectar la existencia del clúster K8 y solicita recursos de forma pasiva. Sin embargo, la implementación nativa solo utiliza el cliente de flink kubernetes-session.sh o flink ejecute la implementación, Flink y K8 solicitan activamente recursos y se convierten en el mejor método de implementación.Además, debido a que las tareas son principalmente procesamiento por lotes fuera de línea, cada aplicación puede contener múltiples trabajos, lo que es más adecuado para las necesidades comerciales.
Implementación real:
aquí solo demostramos el modo de implementación nativa de k8s. La implementación independiente requiere la creación manual de ConfigMap, Servicio, Implementación de JobManager, Implementación de TaskManager, etc., lo cual es problemático.
4.1 Clúster K8s
K8s >= 1.9 o Minikube
KubeConfig (puede ver, crear, eliminar pods y servicios)
Habilitar DNS de Kubernetes
Una cuenta de servicio con permisos RBAC puede crear y eliminar pods
4.2 Imagen de PyFlink
DESDE flink:1.12.1-scala_2.11-java8
Instale python3 y pip3 y las herramientas de depuración necesarias
EJECUTAR apt-get update -y &&
apt-get install -y python3.7 python3-pip python3.7-dev
&& rm -rf /var/lib/apt/lists/*
EJECUTAR rm -rf /usr/bin/python
RUN ln -s /usr/bin/python3 /usr/bin/python
Instalar Python Flink
EJECUTAR pip3 instalar apache-flink == 1.12.1
Si hace referencia a bibliotecas de dependencias de Python de terceros, puede instalar estas dependencias al crear la imagen.
#COPIAR /ruta/a/requisitos.txt /opt/requirements.txt
#EJECUTAR pip3 install -r requisitos.txt
Si se hace referencia a dependencias de Java de terceros, también se pueden agregar al directorio ${FLINK_HOME}/usrlib al crear la imagen.
EJECUTAR mkdir -p $FLINK_HOME/usrlib
COPIAR /ruta/de/externo/jar/dependencias $FLINK_HOME/usrlib/
COPY /path/of/python/codes /opt/python_codes
para copiar
la imagen de pyflink requerida para la implementación de la compilación de Docker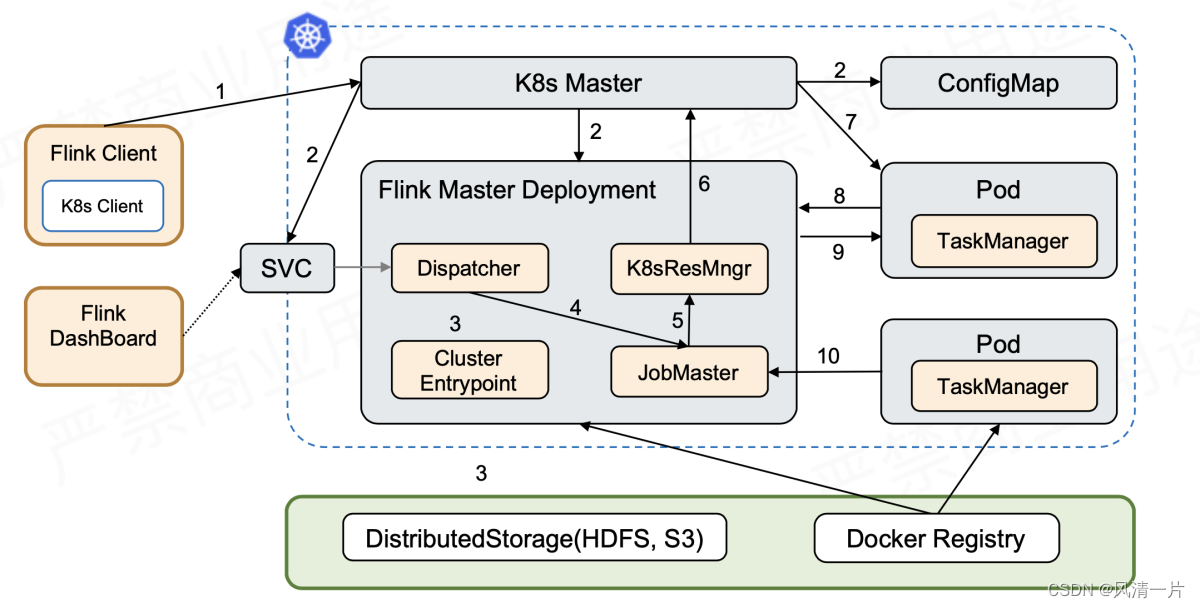
Imagen de Flink -> Imagen de PyFlink -> Imagen de la aplicación PyFlink
4.3 Implementación nativa de la aplicación Flink
Método de operación: la aplicación flink en el modo nativo k8s es muy simple: puede ejecutar y enviar el trabajo en el modo Aplicación con un solo comando.
./bin/flink ejecutar-aplicación -p 2 -t kubernetes-application
-Dkubernetes.cluster-id=app-cluster
-Dtaskmanager.memory.process.size=4096m
-Dkubernetes.taskmanager.cpu=2
-Dtaskmanager.numberOfTaskSlots=4
-Dkubernetes.container.image=demo-pyflink-app:1.12.1
-pyfs /opt/python_codes
-pym new_word_count
Copiar
diagrama de flujo de inicio:
Después de crear primero los recursos de Service, Master y ConfigMap, Flink Master Deployment ya contiene un Jar de usuario. En este momento, Cluster Entrypoint extraerá o ejecutará el archivo principal del usuario desde el Jar del usuario y luego generará JobGraph. Luego envíelo a Dispatcher, que generará Master y luego solicitará recursos de ResourceManager. La lógica posterior es la misma que la de Session.
La mayor diferencia entre este y Session es que se envía en un solo paso. Debido a que no es necesario realizar un envío en dos pasos, si no necesita acceder a la interfaz de usuario externa después de iniciar la tarea, no necesita un servicio externo. Las tareas se pueden ejecutar directamente mediante un envío de un solo paso. Se puede acceder a la interfaz de usuario web de Flink a través del reenvío de puerto local o utilizando algunos servidores proxy de K8s ApiServer. En este punto, el Servicio Externo ya no es necesario, lo que significa que no es necesario ocupar un LoadBalancer o NodePort.
4.4 Proceso de producción
El proceso de redacción de la aplicación Flink es el siguiente:

这块产品主要是采用flink sql去完成 功能,运行模式比较统一,注册source、sink、 执行sq,因此可以采用同一份代码,提供给用户sql编辑框或者用户界面上选择所需要读取的库表字段后端组合成sql语句,最终统一任务运行形成一个离线计算平台,通过动态传递参数进行flink应用的提交和执行。
El backend configura los tipos de origen y receptor y la información de conexión en la base de datos y los expone al frontend.
La interfaz selecciona la fuente de datos correspondiente, como mysql y hive, luego selecciona la tabla de la biblioteca que debe leerse, muestra el esquema de la tabla y el usuario puede seleccionar los campos de la tabla de la biblioteca que deben leerse. Al mismo tiempo, seleccione el receptor de datos que debe almacenarse, como elasticsearch, mysql, etc. Después de obtener estos parámetros dinámicos, cree un trabajo a través del cliente java k8s para enviar la aplicación flink.
Cuando se inicia la aplicación flink, obtiene estos campos de base de datos, información de la tabla de la biblioteca y tabla de la biblioteca y los pasa al programa Flink. El programa flink se construye en flinksql para ejecutar la aplicación. La ejecución específica no se detalla.
5. Resumen
Este artículo comparte la experiencia práctica de la implementación de flink en K8, presenta brevemente los conceptos básicos de K8 y el diagrama de ejecución de Flink, compara diferentes métodos de implementación de Flink y utiliza demostraciones específicas para analizar los componentes en el proceso de implementación de Pyflink en K8. El proceso de coordinación entre ellos ayuda a todos a comprender el proceso de ejecución subyacente al comenzar.