Esta publicación es una exploración de la oferta y la demanda de GPU, específicamente de Nvidia H100. También lanzaremos la canción y el video musical el mismo día de esta publicación.
El artículo se volvió viral. Apareció en HN, techmeme, la portada de muchos boletines informativos por correo electrónico, recibió tweets de Andrej Karpathy y otros, un comentario de Mustafa de Inflection (que pronto tendrá una GPU en línea de $ 100 millones) y de Stability Emad, la canción fue mencionada en El New York Times y varios gestores de activos y fundadores de IA se pusieron en contacto. Si no lo has leído, ¡espero que lo disfrutes!
Introducción #
A partir de <> marzo de 2023, es probable que la IA se vea obstaculizada por el suministro de GPU.
"Una de las razones por las que se subestima el auge de la IA es la escasez de GPU/TPU. Esta escasez conduce a varias limitaciones en el lanzamiento de productos y en la capacitación de modelos, pero estas limitaciones son invisibles. En cambio, lo único que vemos son los picos de precios de Nvidia. Una vez que la oferta se cumple demanda, las cosas se aceleran.— Adam D'Angelo, CEO de Quora, Poe.com, ex CTO de Facebook

Estos son los directores ejecutivos y las empresas que más importan para la oferta y la demanda de GPU, así como para la IA. versión grande
¿Existe realmente un cuello de botella? #
Elon Musk dijo: "En este momento, las GPU son más difíciles de conseguir que los medicamentos" .
Sam Altman afirmó que OpenAI tiene una GPU limitada y está retrasando sus planes a corto plazo (ajustes, capacidad dedicada, ventanas de contexto de 32k, multimodalidad). 2
Los clusters H100 a gran escala de proveedores de nube grandes y pequeños se están quedando sin capacidad. 3
"Todo el mundo quiere que Nvidia fabrique más A/H100" 4 — Mensaje del ejecutivo del proveedor de la nube "Estamos muy escasos de GPU; cuantas menos personas utilicen nuestros productos, mejor" "Nos encantaría que usaran menos, porque nosotros no No tengo suficientes GPU" Sam Altman, director ejecutivo de OpenAI5
Es una voz agradable para recordarle al mundo cuánto aman los usuarios su producto, pero también es cierto que OpenAI necesita más GPU.
Para Azure/Microsoft:
-
Internamente califican al límite de trabajadores de GPU. Tienen que alinearse como las computadoras centrales universitarias en los años 1970. Creo que OpenAI está absorbiendo todo eso ahora mismo.
-
El acuerdo de Coreweave está ligado a su infraestructura de GPU.
- Anónimo
En resumen: sí, las GPU H100 son escasas. Me han dicho que para las empresas que buscan 100 o más de 1000 H100, Azure y GCP se están quedando sin capacidad y AWS está a punto de ser eliminado. 6
Este "déficit de capacidad" se basa en la asignación que les dio Nvidia.
¿Qué queremos saber sobre los cuellos de botella?
-
Qué lo causó (demanda, oferta)
-
cuánto tiempo va a durar
-
¿Qué ayudará a solucionarlo?
Directorio #
-
¿Cuáles son las necesidades más comunes de las startups de LLM?
-
¿Cuáles son los elementos importantes de la formación de LL.M.?
-
¿Cuáles son los otros costos de capacitar y ejecutar un LLM?
-
H100 frente a A100: ¿Cuánto más rápido es el H100 que el A100?
-
¿Cuál es la diferencia entre H100, GH200, DGX GH200, HGX H100 y DGX H100?
-
¿Con cuánta antelación se suele reservar la capacidad fabulosa?
-
¿Cuánto tiempo lleva la producción (producción, embalaje, pruebas)?
-
Si una startup realiza un pedido hoy, ¿cuándo tendrá acceso a SSH?
-
¿La startup compra a fabricantes de equipos originales y revendedores?
-
¿Cuándo construyen las empresas emergentes sus propios centros de datos frente al hosting?
Canción de gráficos #
Bien. . . También lanzamos una canción el mismo día que publicamos este artículo. Es fuego.
Si no has escuchado la canción de GPU, hazte un favor y reprodúcela.
Acabo de ver el video. Muy divertido. Bien hecho. —Mustafa Suleyman, director ejecutivo de Inflexión AI
Está en Spotify , Apple Music y YouTube .
Mira más sobre la canción aquí .
Requisitos para la GPU H100 #
Causa del cuello de botella: demanda
-
Específicamente, ¿qué quiere comprar la gente que no puede?
-
¿Cuántas de estas GPU necesitan?
-
¿Por qué no pueden usar diferentes GPU?
-
¿Cuáles son los diferentes nombres de productos?
-
¿Dónde los compran las empresas y cuánto cuestan?
¿Quién necesita H100? #
"Parece que todo el mundo y sus perros están comprando GPU en este momento" 7 – Elon
¿Quién necesita/tiene 1000+ H100 o A100 #?
-
Formación de startups LLM
-
OpenAI (a través de Azure), Anthropic, Inflection (a través de Azure 8 y Core Weave 9 ), Mistral
-
proveedor de servicios en la nube
-
Los tres grandes: Azure, GCP, AWS
-
Otra nube pública: Oracle
-
Nubes privadas más grandes como CoreWeave, Lambda
¿Quién necesita/tiene 100+ H100 o A100 #?
Startups que realizan ajustes importantes a grandes modelos de código abierto.
¿Para qué se utilizan la mayoría de las GPU de gama alta? #
Para empresas que utilizan nubes privadas (CoreWeave, Lambda), empresas con cientos o miles de H100, casi todos los LLM y algunos modelos de difusión funcionan. Algunos de ellos son ajustes de modelos existentes, pero la mayoría son nuevas empresas que quizás aún no conozcas y que están construyendo nuevos modelos desde cero. Están haciendo contratos de entre 100.000 y 500.000 dólares durante 3 años con cientos o miles de GPU.
Para las empresas que utilizan H100 bajo demanda con una pequeña cantidad de GPU, probablemente todavía sea >50% de uso relacionado con LLM.
Las nubes privadas ahora están comenzando a ver una demanda entrante de empresas que normalmente usarían sus grandes proveedores de nube predeterminados, pero todos están fuera.
¿Los grandes laboratorios de IA están más limitados en cuanto a inferencia o entrenamiento? #
¡Depende de cuánta tracción del producto tengan! Sam Altman dijo que si se le obligara a elegir, OpenAI preferiría tener más capacidades de razonamiento, pero OpenAI todavía está limitado por ambas. 11
¿Qué GPU necesita la gente? #
Principalmente H100. ¿Por qué? Para LLM, es el más rápido para inferencia y entrenamiento (H100 también suele ser el mejor precio/rendimiento para inferencia)
Específicamente: el servidor HGX H100 SXM de 8 GPU.
Mi análisis es que también es más barato ejecutar el mismo trabajo. V100 sería genial si pudieras encontrarlos, no es así. Anónimo Honestamente, ¿no estás seguro [esta es la mejor inversión por tu dinero]? La relación precio/rendimiento de entrenamiento del A100 es más o menos la misma que la del H100. Extrapolando, encontramos que el A10G es más que adecuado y mucho menos costoso. – Ejecutivo de nube privada Esto [A10G es más que suficiente] ha sido cierto por un tiempo. Pero en el mundo del Falcon 40b y Llama 2 70b vemos mucho uso, eso ya no es cierto. Necesitamos A100 para que estos 2xA100 sean exactos. Por lo tanto, la velocidad de interconexión es importante para la inferencia. – (Varios) Ejecutivos de Nube Privada
¿Cuáles son las necesidades más comunes de las startups de LLM? #
Para formación LLM: H100, 3,2 Tb/s InfiniBand.
¿Qué formación y razonamiento en LLM quieren las empresas? #
Para entrenar tienden a querer el H100, por inferencia se trata más de rendimiento por dólar.
Sigue siendo una cuestión de rendimiento por dólar para los H100 frente a los A100, pero los H100 generalmente son los preferidos porque escalan mejor con una mayor cantidad de GPU y brindan tiempos de entrenamiento más rápidos e inician, entrenan o mejoran. La velocidad del modelo/el tiempo de compresión es fundamental para Inauguración.
"Para la capacitación de múltiples nodos, todos solicitan A100 o H100 con red InfiniBand. Las únicas solicitudes que no son A/H100 que vemos son para inferencias en las que la carga de trabajo es una sola GPU o un solo nodo" – Private Cloud Executive
¿Cuáles son los elementos importantes de la formación de LL.M.? #
-
ancho de banda de memoria
-
FLOPS (núcleo tensor o unidad multiplicadora de matriz equivalente)
-
Almacenamiento en caché y latencia de caché
-
Funciones adicionales como los cálculos del 8PM
-
Rendimiento informático (relacionado con la cantidad de núcleos cuda)
-
Velocidad de interconexión (por ejemplo, Infiniband)
El H100 supera al A100 en parte debido a factores como una menor latencia de caché y el cómputo FP8.
Se prefiere el H100 porque es 3 veces más eficiente y cuesta solo (1,5 - 2 veces). Combinado con el costo general del sistema, el H100 produce más rendimiento por dólar (si nos fijamos en el rendimiento del sistema, tal vez entre 4 y 5 veces mejor rendimiento por dólar). — Investigador de aprendizaje profundo
¿Cuáles son los otros costos de capacitar y ejecutar un LLM? #
La GPU es el componente individual más caro, pero existen otros costes.
La RAM del sistema y los SSD NVMe son caros.
Las redes InfiniBand son caras.
Probablemente entre el 10% y el 15% del costo total de funcionamiento de un clúster sea para energía y alojamiento (electricidad, costos de construcción del centro de datos, costos de terreno, personal); aproximadamente dividido entre los dos, podría ser del 5% al 8% de energía y del 5% al 10%. % Otros elementos del coste de alojamiento (terrenos, edificios, personal).
Se trata principalmente de redes y centros de datos confiables. AWS es difícil de usar debido a limitaciones de la red y hardware poco confiable - Deep Learning Researcher
¿Qué pasa con las GPU? #
Una GPU no es un requisito crítico, pero podría ayudar.
No diría que es supercrítico, pero tiene un impacto en el rendimiento. Supongo que depende de dónde esté tu cuello de botella. Para algunas arquitecturas/implementaciones de software, el cuello de botella no es necesariamente la red, pero si es GPUDirect, puede hacer una diferencia del 10-20%, que es un número decente para una ejecución de capacitación costosa. Dicho esto, GPUDirect RDMA es tan omnipresente hoy en día que casi no hace falta decir que es compatible. No creo que el soporte para redes que no sean InfiniBand sea demasiado fuerte, pero la mayoría de los clústeres de GPU optimizados para el entrenamiento de redes neuronales tienen redes/tarjetas Infiniband. Un factor más importante que afecta el rendimiento podría ser NVLink, ya que es más raro que Infiniband, pero sólo es crítico si tiene una estrategia de paralelización específica. Por lo tanto, características como potentes redes y GPUdirect te permiten perder el tiempo y tienes garantizado un software sencillo listo para usar. Sin embargo, si le preocupa el costo o el uso de la infraestructura que ya tiene, este no es un requisito estricto. – Investigador de aprendizaje profundo
¿Qué impide que las empresas de LLM utilicen GPU de AMD? #
En teoría, una empresa podría comprar un montón de GPU AMD, pero llevará tiempo que todo funcione. El tiempo de desarrollo (incluso solo 2 meses) puede significar llegar más tarde al mercado que la competencia. Entonces CUDA es ahora el foso de NVIDIA. - Ejecutivo de nube privada. Sospecho que 2 meses es una diferencia de orden de magnitud, lo que puede no ser una diferencia significativa; consulte Capacitación para LLM con GPU AMD MI250 y MosaicML. - Ingeniero de aprendizaje automático que se arriesgaría a descartar 10 000 GPU AMD o 10 000 inicios aleatorios. ¿Están en riesgo los chips de silicio? Se trata de una inversión de casi 30.000 millones de dólares. – Private Cloud Executive MosaicML/MI250: ¿Alguien ha preguntado sobre la disponibilidad de AMD? AMD no parece estar dándole a Frontier más de lo que necesita, y ahora Nvidia está absorbiendo la capacidad CoWoS de TSMC. MI250 podría ser una alternativa viable, pero no está disponible. – Profesional jubilado de la industria de semiconductores
H100 frente a A100: ¿Cuánto más rápido es el H100 que el A100? #
La inferencia de 3 bits es aproximadamente 5,16 veces más rápida12. Para el entrenamiento de 2 bits, la aceleración es aproximadamente 3,16 veces. 13
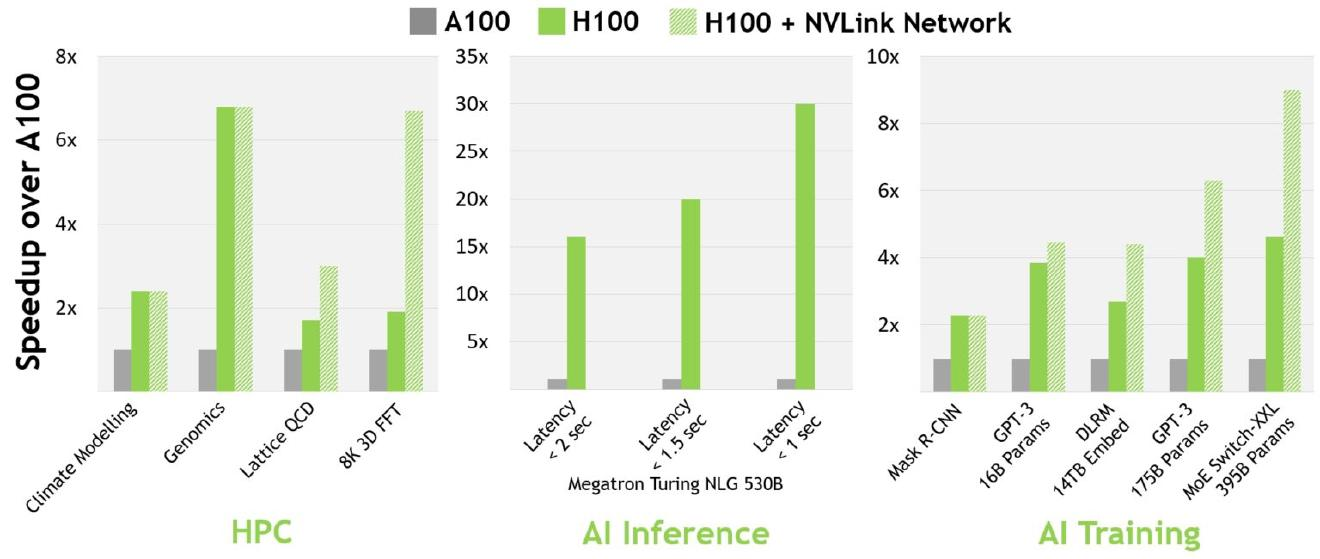
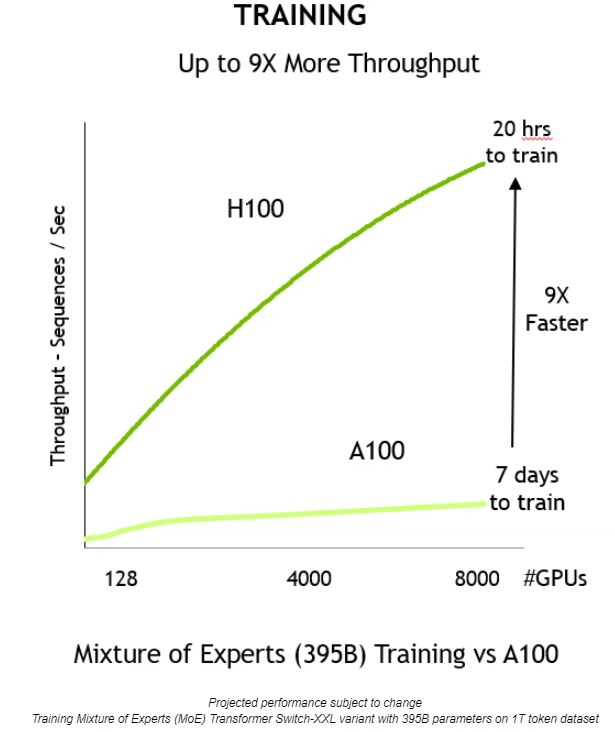
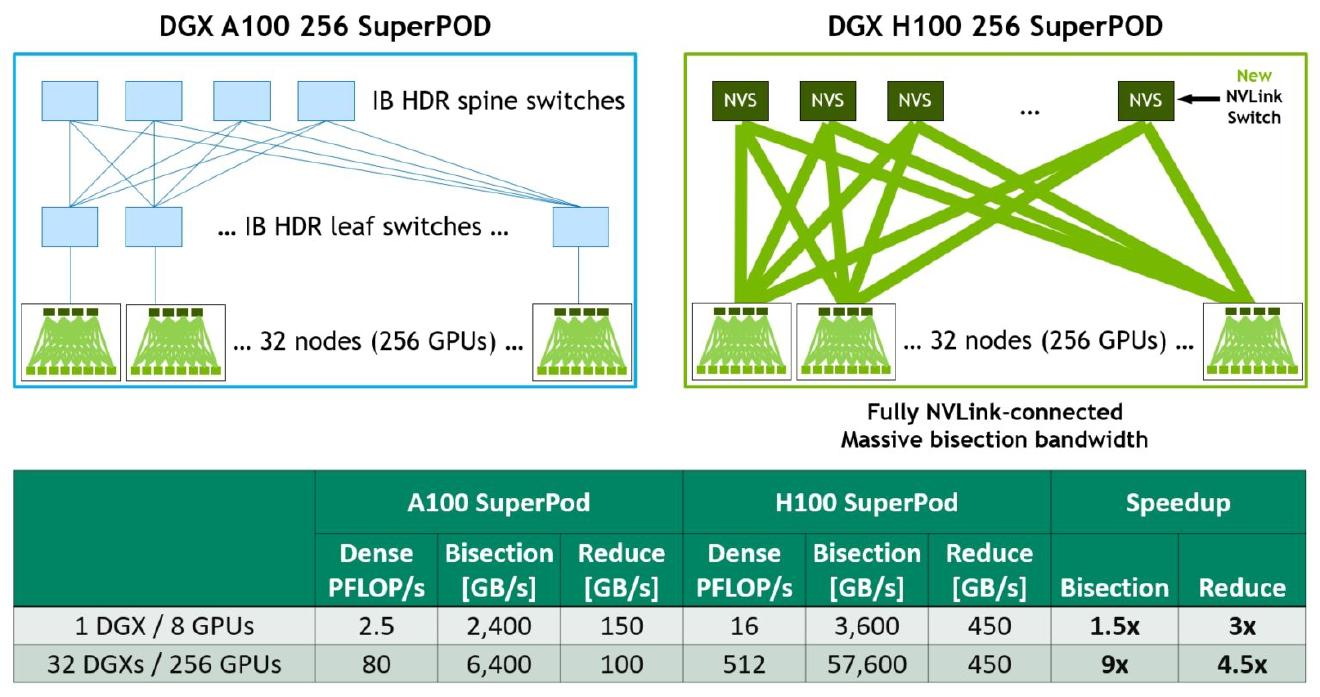
Aquí tienes más lecturas: 1 2 3 .
¿Todo el mundo quiere actualizar del A100 al H100? #
La mayoría de la gente querrá comprar el H100 y usarlo para entrenamiento e inferencia, y cambiar su A100 para usarlo principalmente para inferencia. Sin embargo, algunos pueden dudar en cambiar debido al costo, la capacidad, el riesgo de usar y configurar nuevo hardware y el hecho de que su software existente ya está optimizado para el A100.
Sí, el A100 será lo que es el V100 hoy en unos años. No conozco a nadie que esté entrenando LLM en el V100 en este momento debido a limitaciones de rendimiento. Pero todavía se utilizan para inferencias y otras cargas de trabajo. Del mismo modo, a medida que más y más empresas de IA trasladen cargas de trabajo al H100, el precio del A100 bajará, pero siempre habrá demanda, especialmente para la inferencia. – Los ejecutivos de la nube privada piensan que también es plausible que algunas nuevas empresas que recaudaron enormes sumas de dinero acaben cerrando y luego muchos A100 regresen al mercado. – (Varios) Ejecutivos de Nube Privada
Con el tiempo, la gente se moverá y el A100 se utilizará más para hacer inferencias.
¿Qué pasa con el V100? Las tarjetas con mayor VRAM son más adecuadas para modelos más grandes, por lo que los grupos más avanzados prefieren la H100 o la A100.
La razón principal para no utilizar V100 es la falta de tipos de datos Brainfloat16 (bfloat16, BF16). Sin él, es difícil entrenar un modelo fácilmente. El bajo rendimiento de OPT y BLOOM se debe principalmente a que no tienen este tipo de datos (OPT se entrenó en float16, la creación de prototipos de BLOOM se realizó principalmente en fp16, lo que no produjo datos generalizados a ejecuciones de entrenamiento realizadas en bf16 Medium) - Investigador de aprendizaje profundo
¿Cuál es la diferencia entre H100, GH200, DGX GH200, HGX H100 y DGX H100? #
-
H100 = 1 GPU H100
-
HGX H100 = Plataforma de referencia de servidores Nvidia para que los OEM construyan servidores de 4 GPU u 8 GPU. Construido por fabricantes de equipos originales de terceros como Supermicro.
-
DGX H100 = Servidor oficial Nvidia H100 con 8 H100. 14 Nvidia es el único proveedor.
-
GH200 = 1 GPU H100 más 1 CPU Grace. 15
-
DGX GH200 = 256x GH200, 16 estarán disponibles a finales de 2023. 17 solo puede ser proporcionado por Nvidia.
También está MGX para las grandes empresas de la nube.
¿Cuál de estos será el más popular? #
La mayoría de las empresas comprarán los servidores HGX H100 de 8 GPU, no los servidores HGX H100 de 18 DGX o 4 GPU.
¿Cuánto cuestan estas GPU? #
El precio de 1 GPU DGX H100 (SXM) y 8 GPU H100 es de 4,6 millones de dólares, incluido el soporte necesario. Se requieren 460.000 dólares de los 100.000 dólares de apoyo. Las especificaciones son las siguientes. Las empresas emergentes pueden obtener un reembolso inicial de alrededor de $ 50 mil y pueden usarse para hasta 8 cajas DGX H100 para un total de 64 H100.

1 GPU HGX H100 (SXM) y 8x H100 cuestan entre 300k y 380k según las especificaciones (red, almacenamiento, RAM, CPU) y el margen y el nivel de soporte de quien las vende. El extremo superior del rango, entre 360.000 y 380.000 dólares incluido el soporte, es lo que se podría esperar con las mismas especificaciones que la DGX H100.
1 GPU HGX H100 (PCIe) y 8x H100 cuestan alrededor de $ 300 000, incluido el soporte, según las especificaciones.
El precio de mercado de una tarjeta PCIe ronda los 30.000-32.000 dólares.
Las tarjetas SXM en realidad no se venden como tarjetas individuales, por lo que es difícil dar precios allí. Por lo general, solo se venden como servidores de 4 GPU y 8 GPU.
Alrededor del 70-80% de la demanda es SXM H100 y el resto es PCIe H100. La demanda en el segmento SXM está aumentando, ya que las tarjetas PCIe fueron las únicas tarjetas disponibles durante los primeros meses. Dado que la mayoría de las empresas compran HGX H100 (SXM) de 8 GPU, el gasto aproximado por 360 H380 es de 8k-100k, incluidos otros componentes del servidor.
El DGX GH200 (como recordatorio, contiene 256x GH200, cada GH200 contiene 1x H100 GPU y 1x Grace CPU) probablemente costará entre 15 mm y 25 mm, aunque esto es una suposición y no se basa en una tabla de precios. 19
¿Cuántas GPU se necesitan? #
-
Es posible que el GPT-4 haya sido entrenado en entre 10.000 y 25.000 A100. 20
-
Meta tiene alrededor de 21.000 A100, Tesla tiene alrededor de 7.000 A100 y Stable AI tiene alrededor de 5.000 A100. veintiuno
-
El Falcon-40B fue entrenado en 384 A100. Veintidós
-
Inflection utiliza 3500 H100 como modelo equivalente GPT-3.5. veintitrés
Por cierto, para marzo tenemos 22.000 en funcionamiento. Y corre más de 5.<>k hoy. —Mustafa Suleyman, director ejecutivo de Inflexión AI
Según Elon, GPT-5 puede requerir entre 30.000 y 50.000 H100. Morgan Stanley dijo en mayo de 2023 que GPT-25 usaría 000,000,2023 GPU, pero también dijeron que ya estaba entrenando a partir de <> mes 2023, Sam Altman en <> año< > mes significa que aún no ha sido entrenado , por lo que la información de MS puede estar desactualizada.
GCP tiene alrededor de 25k H100, Azure tal vez entre 10k y 40k H100. Debería ser similar para Oracle. La mayor parte de la capacidad de Azure estará dedicada a OpenAI.
CoreWeave en el campo durante 35.000-40.000 H100, no en directo, pero según las reservas.
¿Cuántos H100 piden la mayoría de las startups? #
Para LLM: para ajuste fino, decenas o centenas bajas. Para la formación, miles de personas.
¿Cuánto H100 podría querer la empresa? #
OpenAI puede necesitar 50k. El punto de inflexión requiere 22k. 24 Meta podría ser 25k (me han dicho que Meta en realidad quiere 100k o más). Las nubes más grandes pueden requerir 30k (Azure, Google Cloud, AWS y Oracle). Quizás 1 millón para Lambda y CoreWeave y otras nubes privadas. Anthropic, Helsing, Mistral, Character, quizás 10k cada uno. Aproximación y conjeturas totales, algunas de ellas cuentan la nube y los clientes finales que alquilarán desde la nube. Pero eso es alrededor de 432k H100. Alrededor de 35 dólares, 15 dólares cada uno, alrededor de 80 mil millones de dólares en GPU. Esto también excluye a empresas chinas como ByteDance (TikTok), Baidu y Tencent, que quieren mucho H<>.
También hay una serie de empresas financieras que están implementando, comenzando con cientos de A100 o H100, y llegando hasta miles de A/H100: Jane Street, JP Morgan, Two Sigma, Citadel y otros nombres.
¿Cómo se compara esto con los ingresos del centro de datos de Nvidia?
El 28 de abril de 2023 es $<>.<>b de ingresos del centro de datos. Del 25 de agosto al <> 2023, los ingresos de los centros de datos podrían estar en la región de <> mil millones, suponiendo que la mayor parte de la orientación más alta para el trimestre se deba al crecimiento de los ingresos de los centros de datos en lugar de a otros segmentos.
Por lo tanto, la escasez de oferta puede tardar un tiempo en desaparecer. Pero probablemente todos mis argumentos también sean exagerados, y muchas de estas empresas no comprarán el H100 directamente hoy, sino que lo actualizarán con el tiempo. Además, Nvidia está aumentando activamente su capacidad de producción.
Parece posible. 400k H100 no parece fuera de su alcance, especialmente considerando que todos están realizando implementaciones masivas de H100 de 4 o 5 cifras en estos días. – Ejecutivo de Nube Privada
Resumen: Requisitos H100 #
Lo principal que debe tener en cuenta al pasar a la siguiente sección es que la mayoría de los CSP grandes (Azure, AWS, GCP y Oracle) y las nubes privadas (CoreWeave, Lambda y varios otros) quieren más H100 de los que pueden acceder. La mayoría de las grandes empresas de productos de IA también quieren más H100 de lo que pueden conseguir. Por lo general, quieren una caja HGX H100 de 8 GPU con una tarjeta SXM, que cuesta entre 400.000 y 8.000 dólares por servidor de 300 GPU, según las especificaciones y el soporte. Puede haber un exceso de cientos de miles de GPU H100 (GPU 15b+). Con una oferta limitada, Nvidia puede subir los precios simplemente para encontrar un precio de liquidación, y hasta cierto punto lo está haciendo. Pero es importante saber que, en última instancia, la asignación del H100 depende de a quién prefiere Nvidia dársela.
Suministro de tarjeta gráfica H100 #
Causa del cuello de botella: suministro
-
¿Cuáles son los cuellos de botella en la producción?
-
¿Qué componentes?
-
¿quién los produce?
¿Quién hizo el H100? #
TSMC.
¿Puede Nvidia utilizar otras fábricas de chips para la producción del H100? #
En realidad no, al menos no todavía. Han trabajado con Samsung en el pasado. Pero en H100 y otras GPU de 5 nm, solo usan TSMC. Eso significa que Samsung no ha podido satisfacer su necesidad de una GPU de última generación. Es posible que trabajen con Intel en el futuro, y nuevamente con Samsung, pero nada de eso sucederá pronto de una manera que ayude a reducir el suministro del H100.
¿Cómo se relacionan los diferentes nodos de TSMC? #
Serie TSMC de 5 nm:
-
N5 26
-
4N es adecuado como una versión mejorada de N5 o inferior a N5P
-
N5P
-
4N es adecuado como versión mejorada de N5P o por debajo de N5 como versión mejorada de N5
-
N4
-
N4P
¿En qué nodo de TSMC se fabrica el H100? #
TSMC 4N. Este es un nodo especial de Nvidia, que pertenece a la serie de 5 nm, y es un 5 nm mejorado, no un 4 nm real.
¿Quién más usa este nodo? #
Es Apple, pero en su mayoría se trasladaron a N3 y mantuvieron la mayor parte de la capacidad de N3. Qualcomm y AMD son otros grandes clientes de la familia N5.
¿Qué nodo TSMC utiliza el A100? #
N7 27
¿Con cuánta antelación se suele reservar la capacidad fabulosa? #
No estoy seguro, tal vez más de 12 meses.
Esto se aplica a TSM y sus grandes clientes, lo planifican todo juntos, es por eso que TSM/NVDA probablemente subestimó sus necesidades – Anónimo
¿Cuánto tiempo lleva la producción (producción, embalaje, pruebas)? #
Pasarán 100 meses desde el inicio de la producción del H6 hasta el momento en que el H100 esté listo para venderse a los clientes (comenzó la conversación, esperamos confirmación)
¿Dónde está el cuello de botella? #
El inicio de las obleas no es el cuello de botella de TSMC. El paquete CoWoS (apilamiento 3D) antes mencionado es la puerta de TSMC. – Profesional jubilado de la industria de semiconductores
RAM H100 #
¿Qué afecta el ancho de banda de la memoria en una GPU? #
Tipo de memoria, ancho del bus de memoria y velocidad del reloj de la memoria.
Principalmente HBM. Hacerlo es una pesadilla. La oferta también es mayoritariamente limitada porque HBM es difícil de producir. Una vez que tienes el HBM, el diseño se sigue de forma intuitiva - Deep Learning Researcher
¿Qué memoria se utiliza en los H100? #
En el H100 SXM, es HBM3. 28 En H100 PCIe, en realidad es HBM2e. 29
¿Quién hizo la memoria del H100? #
Nvidia diseña el ancho del bus y la velocidad del reloj como parte de la arquitectura de la GPU.
Para la memoria HBM3, creo que Nvidia usa todo o la mayor parte de SK Hynix. No estoy seguro de si Nvidia usó algo de Samsung en el H100, no creo que sea nada que Micron haya usado en el H100.
En lo que respecta a HBM3, SK Hynix es el que más ha hecho, luego Samsung no se queda atrás y Micron está muy por detrás. Parece que SK Hynix está aumentando la producción, pero Nvidia todavía quiere que produzcan más, Samsung y Micron aún no han logrado aumentar la producción.
¿Qué más usas al hacer una GPU? #
Tenga en cuenta que algunas de estas partes tienen más obstáculos que otras.
-
Elementos metálicos: Estos elementos son fundamentales en la producción de GPU. Incluyen:
-
Cobre: Se utiliza para crear conexiones eléctricas debido a su alta conductividad.
-
Tantalio: A menudo se utiliza en condensadores debido a su capacidad para mantener una carga elevada.
-
Oro: Se utiliza para enchapados y conectores de alta calidad debido a su resistencia a la corrosión.
-
Aluminio: A menudo se utiliza en disipadores de calor para ayudar a disipar el calor.
-
Níquel: A menudo se utiliza como revestimiento para conectores debido a su resistencia a la corrosión.
-
Estaño: Se utiliza para soldar componentes entre sí.
-
Indio: Utilizado en materiales de interfaz térmica por su buena conductividad térmica.
-
Paladio: Utilizado en algunos tipos de condensadores y dispositivos semiconductores.
-
Silicio (metaloide): este es el material principal utilizado para fabricar dispositivos semiconductores.
-
Elementos de tierras raras: estos elementos se utilizan en varias partes de la GPU debido a sus propiedades únicas.
-
Otros metales y químicos: Se utilizan en diversas etapas de producción, desde la creación de las obleas de silicio hasta el ensamblaje final de la GPU.
-
Sustrato: Son los materiales sobre los que se montan los componentes de la GPU.
-
Materiales encapsulantes: Se utilizan para alojar y proteger el troquel de la GPU.
-
Bolas de soldadura y cables de unión: se utilizan para conectar el chip GPU al sustrato y otros componentes.
-
Componentes pasivos: incluyen condensadores y resistencias, que son fundamentales para el funcionamiento de la GPU.
-
Placa de circuito impreso (PCB): Es la placa de circuito en la que se montan todos los componentes de la GPU. Proporciona conexión eléctrica entre componentes.
-
Compuestos térmicamente conductores: se utilizan para mejorar la transferencia de calor entre el chip y el disipador de calor.
-
Equipos de fabricación de semiconductores: incluidas máquinas de fotolitografía, equipos de grabado, equipos de implantación de iones, etc.
-
Instalaciones de sala limpia: son necesarias para la producción de GPU para evitar la contaminación de las obleas de silicio y otros componentes.
-
Equipos de prueba y control de calidad: se utilizan para garantizar que la GPU cumpla con los estándares de rendimiento y confiabilidad requeridos.
-
Software y firmware: son fundamentales para controlar el funcionamiento de la GPU y la interfaz con el resto del sistema informático.
-
Materiales de Embalaje y Envío: Son necesarios para entregar el producto final al cliente en perfectas condiciones.
-
Herramientas de software: las herramientas de software para diseño asistido por computadora (CAD) y simulación son esenciales para diseñar la arquitectura y probar la funcionalidad de la GPU.
-
Consumo de energía: debido al uso de maquinaria de alta precisión, el proceso de fabricación de chips GPU requiere mucha electricidad.
-
Gestión de residuos: La producción de GPU genera residuos que deben gestionarse y eliminarse adecuadamente, ya que muchos de los materiales utilizados pueden ser perjudiciales para el medio ambiente.
-
Capacidad de prueba: equipos de prueba personalizados/especializados para verificar la funcionalidad y el rendimiento.
-
Empaquetado de chips: ensamblaje de obleas de silicio en paquetes de componentes que pueden usarse en sistemas más grandes.
Perspectivas y pronósticos #
¿De qué está hablando Nvidia? #
Nvidia reveló que tienen más oferta en la segunda mitad del año, pero aparte de eso, no dijeron mucho ni lo cuantificaron.
"Hoy estamos analizando la oferta para el trimestre, pero también hemos obtenido mucha oferta para la segunda mitad del año". "Creemos que nuestra oferta para la segunda mitad del año será significativamente mayor que la del primer semestre". Colette Kress, directora financiera de Nvidia, en 2023 <> mes a <> llamada de ganancias mensuales
¿Que sigue? #
Creo que ahora podemos tener un ciclo que se refuerza a sí mismo en el que la escasez hace que la capacidad de GPU se vea como un foso, lo que conduce a un mayor acaparamiento de GPU, lo que exacerba la escasez. – Ejecutivo de Nube Privada
¿Cuándo habrá un sucesor del H100? #
Es posible que no se anuncie hasta finales de 2024 (mediados de 2024 hasta principios de 2025), según el momento histórico entre las arquitecturas de Nvidia.
Hasta entonces, la H100 será la GPU de gama alta de Nvidia. (GH200 y DGX GH200 no se cuentan, no son GPU puras, ambos usan H100 como GPU)
¿Habrá una mayor memoria de vídeo H100? #
Quizás un H100s de 120 GB refrigerado por líquido.
¿Cuándo terminará la escasez? #
Un grupo con el que hablé mencionó que en realidad estarán agotados para finales de 2023.
Compra de H100 #
¿Quién vende H100? #
OEM como Dell, HPE, Lenovo, Supermicro y Quanta venden el H100 y el HGX H100. 30
Cuando necesite InfiniBand, deberá hablar directamente con Mellanox de Nvidia. 31
Por lo tanto, las nubes de GPU como CoreWeave y Lambda se compran a fabricantes de equipos originales y se las alquilan a empresas emergentes.
Los hiperescaladores (Azure, GCP, AWS, Oracle) trabajan más directamente con Nvidia, pero a menudo también trabajan con OEM.
Incluso para DGX, seguirás comprando a través de OEM. Puedes hablar con Nvidia, pero comprarás a través de OEM. No realiza un pedido directamente a Nvidia.
¿Qué tal el tiempo de entrega? #
El tiempo de entrega en el servidor HGX de 8 GPU es terrible, mientras que el tiempo de entrega en el servidor HGX de 4 GPU es bueno. ¡Todo el mundo quiere un servidor de 8 GPU!
Si una startup realiza un pedido hoy, ¿cuándo tendrá acceso a SSH? #
Este será un despliegue escalonado. Digamos que este es un pedido de 5000 GPU. Es posible que obtengan 2000 o 4000 en 4 meses y luego el resto en aproximadamente 6 meses en total.
¿La startup compra a fabricantes de equipos originales y revendedores? #
No. Las empresas emergentes suelen acudir a grandes nubes como Oracle, que alquilan acceso, o a nubes privadas como Lambda y CoreWeave, o a proveedores que trabajan con OEM y centros de datos como FluidStack.
¿Cuándo construyen las empresas emergentes sus propios centros de datos frente al hosting? #
Cuando se trata de construir un centro de datos, las consideraciones son cuándo se necesitará construir el centro de datos, si se cuenta con el personal y la experiencia con el hardware y si es un gasto de capital costoso.
Más fácil de alquilar y colocar servidores. Si desea construir su propio centro de distribución, debe instalar una línea de fibra oscura en su ubicación para conectarse a Internet: 100.000 dólares por kilómetro. Gran parte de la infraestructura ya se construyó y pagó durante el auge de las puntocom. Ahora puedes alquilarlo, bastante barato - Private Cloud Executive
El espectro desde el arrendamiento hasta la propiedad es: nube bajo demanda (arrendamiento puro utilizando servicios de nube), nube reservada, colo (comprar servidores, trabajar con un proveedor para alojarlos y administrarlos), autohospedaje (comprar y alojar servidores usted mismo).
La mayoría de las startups que necesitan una gran cantidad de H100 utilizarán una nube reservada o una colo.
¿Cómo se compara Big Cloud? #
Se cree que la infraestructura de Oracle es menos confiable que las tres grandes nubes. A cambio, Oracle proporcionará tiempo y asistencia técnica adicional.
100%. Un montón de clientes descontentos jajaja – ejecutivo de nube privada Creo que [Oracle] tiene una mejor red – ejecutivo de nube privada (diferente)
Generalmente, las startups eligen a quien ofrece la mejor combinación de soporte, precio y capacidad.
Las principales diferencias de Big Cloud son:
-
Redes (AWS y Google Cloud han tardado más en adoptar InfiniBand ya que tienen sus propios enfoques, aunque la mayoría de las nuevas empresas que buscan grandes clústeres A100/H100 buscan InfiniBand)
-
Disponibilidad (el H100 de Azure es principalmente para OpenAI. GCP está trabajando arduamente para obtener el H100.
Nvidia parece inclinarse hacia mejores asignaciones para nubes que no construyen chips de aprendizaje automático competitivos. (Todo esto es especulación, no una dura verdad. Las tres grandes nubes están desarrollando chips de aprendizaje automático, pero las alternativas de AWS y Nvidia de Google ya están disponibles y es posible que ya le cuesten dólares a Nvidia.
También son conjeturas, pero estoy de acuerdo en que a Nvidia le gusta Oracle por este motivo – Private Cloud Exec
Algunas nubes grandes tienen mejores precios que otras. Como señaló un ejecutivo de nube privada: "Por ejemplo, a100 es mucho más caro en AWS/Azure que GCP.
Oracle me dijo que tendrán "cientos de los miles de H10" disponibles a finales de este año. Se jactan de su especial relación con Nvidia. pero. . . En términos de precios, son mucho más altos que los demás. No me pusieron el precio del H100, pero por el A100 de 80 GB me cotizaron cerca de $4 por hora, que es casi el doble de lo que GCP cotizó por el mismo hardware y el mismo compromiso. - Anónimo
Las nubes más pequeñas tienen mejores precios, excepto en algunos casos en los que una de las nubes grandes hace un trato extraño a cambio de acciones.
Podría ser algo como esto: Oracle y Azure > Relación GCP y AWS. Pero eso son sólo conjeturas.
Oracle fue el primero en lanzar el A100 y se asoció con Nvidia para alojar un clúster basado en Nvidia . Nvidia también es cliente de Azure .
¿Qué gran nube tiene la mejor red? #
Azure, CoreWeave y Lambda usan InfiniBand. Oracle tiene una buena red, es de 3200 Gbps, pero es Ethernet y no InfiniBand, que puede ser entre un 15 y un 20 % más lento que IB para casos de uso como la capacitación LLM con un alto número de parámetros. La conexión en red de AWS y GCP no es tan buena.
¿Qué grandes nubes utilizan las empresas? #
En un punto de datos privado de unas 15 empresas, las 15 son AWS, GCP o Azure, cero Oracle.
La mayoría de las empresas seguirán con su nube actual. Dondequiera que vayan las startups desesperadas, hay oferta.
¿Qué pasa con DGX Cloud y con quién trabaja Nvidia? #
"NVIDIA está trabajando con proveedores líderes de servicios en la nube para alojar la infraestructura en la nube DGX, comenzando con Oracle Cloud Infrastructure (OCI)". Usted maneja las ventas de Nvidia, pero la alquila a través de su proveedor de nube existente (comience con Oracle, luego Azure y luego Google Cloud). en lugar de lanzar con AWS) 32 33
"La combinación ideal es 10% de nube Nvidia DGX y 90% de nube CSP", dijo Jensen en la última conferencia telefónica sobre resultados.
¿Cuándo lanzará Dayun su vista previa del H100? #
CoreWeave fue el primero. 34 Nvidia les dio una asignación más temprana, presumiblemente para ayudar a aumentar la competencia entre las grandes nubes (ya que Nvidia es un inversor).
Azure anunció el 13/100 que H<> está disponible para versión preliminar. 35
Oracle anunció el 21/21 que H<> tiene un número limitado. 36
Lambda Labs anunció el 21/21 que H<> se agregará al comienzo de <>. 37
AWS anunció el 21/21 que H<> estará disponible en versión preliminar en unas semanas. 38
Google Cloud anunció el 100 de octubre que comenzó a proporcionar una vista previa privada de H<>. 39
¿Qué empresas utilizan qué nubes? #
-
IA abierta: Azure.
-
Variaciones: Azure y CoreWeave.
-
Humanos: AWS y Google Cloud.
-
Cohere: AWS y Google Cloud.
-
Cara de abrazo: AWS.
-
IA de estabilidad: CoreWeave y AWS.
-
Personaje.ai: Google Cloud.
-
X.ai: Oráculo.
-
Nvidia: azul. 35
¿Cómo puede una empresa o proveedor de servicios en la nube conseguir más GPU? #
El principal obstáculo es conseguir asignaciones de Nvidia.
¿Cómo funciona la asignación de Nvidia? #
Tienen una cuota asignada a cada cliente. Pero, por ejemplo, que Azure diga "oye, queremos que Inflection use 10,000 H100" no es lo mismo que Azure diga "oye, queremos que la nube de Azure use 10,000 H100". A Nvidia le importa quién es el cliente final, así que si Nvidia está entusiasmada En cuanto a los clientes finales, la nube puede obtener asignaciones adicionales para clientes finales específicos. Nvidia también quiere saber lo más posible sobre quién es el cliente final. Prefieren clientes con marcas hermosas o nuevas empresas con un pedigrí sólido.
Sí, ese parece ser el caso. A NVIDIA le gusta garantizar el acceso a las GPU para las empresas emergentes de IA (muchas de las cuales tienen estrechos vínculos con ellas). Consulte Inflection, la empresa de inteligencia artificial en la que invirtieron, que prueba un enorme clúster H100 en CoreWeave, en el que también invirtieron. – Ejecutivo de Nube Privada
Si la nube trae a Nvidia un cliente final y dice que está listo para comprar el xxxx H100, si Nvidia se entusiasma con el cliente final, generalmente le otorgan una asignación, lo que efectivamente aumenta la capacidad total que Nvidia asigna a esa nube, porque no 't Cuenta para la asignación original de Nvidia a esa nube.
Esta es una situación única porque Nvidia está proporcionando una gran asignación para nubes privadas: CoreWeave tiene más H100 que GCP.
Nvidia se muestra reacia a conceder grandes subvenciones a empresas que intentan competir directamente (AWS Inferentia y Tranium, Google TPU, Azure Project Athena).
Pero al final, si pones órdenes de compra y dinero frente a Nvidia, prometes mayores ofertas y más dinero, y demuestras que tienes un perfil de bajo riesgo, obtendrás más asignaciones que los demás.
Epílogo #
Actualmente, estamos vinculados a GPU. Aunque estamos en lo que Sam Altman llama "el fin de una era en la que estarán estos modelos gigantes".
Es como una burbuja o no, dependiendo de dónde se mire. Algunas empresas como OpenAI tienen productos como ChatGPT que se adaptan bien al mercado y no pueden obtener suficientes GPU. Otros están comprando o reservando capacidad de GPU para acceso futuro, o capacitando a LLM que probablemente no se ajusten al mercado de productos.
Nvidia es ahora el rey verde del castillo.
Seguimiento del recorrido de la oferta y la demanda de GPU
El producto LLM con mayor ajuste entre producto y mercado es ChatGPT. Aquí está la historia de los requisitos de GPU relacionados con ChatGPT:
-
A los usuarios les encanta ChatGPT. Podría generar ingresos recurrentes de 500 millones de dólares++ al año.
-
ChatGPT se ejecuta en las API GPT-4 y GPT-3.5.
-
Las API GPT-4 y GPT-3.5 requieren una GPU para ejecutarse. mucho. A OpenAI le gustaría lanzar más funciones para ChatGPT y su API, pero no pueden porque no tienen acceso a suficientes GPU.
-
Compran muchas GPU Nvidia a través de Microsoft/Azure. Específicamente, su GPU más buscada es la GPU Nvidia H100.
-
Para fabricar la GPU H100 SXM, Nvidia utiliza TSMC para la fabricación, utiliza la tecnología de empaquetado CoWoS de TSMC y utiliza HBM3 principalmente de SK Hynix.
OpenAI no es la única empresa que quiere una GPU (pero es la que tiene el mejor ajuste entre producto y mercado). Otras empresas también quieren entrenar grandes modelos de IA. Algunos de estos casos de uso tienen sentido, pero otros están más impulsados por la publicidad y es menos probable que resulten en una adecuación del producto al mercado. Esto aumenta la demanda. Además, a algunas empresas les preocupa no tener acceso a GPU en el futuro, por lo que realizan pedidos ahora incluso si aún no las necesitan. Así que "la expectativa de que la escasez de suministro genere más escasez de suministro" está sucediendo.
Otro contribuyente importante a la demanda de GPU proviene de empresas que desean crear nuevos LLM. Aquí hay una historia sobre la necesidad de GPU de las empresas que desean crear nuevos LLM:
-
Los ejecutivos o fundadores de empresas saben que existen grandes oportunidades en el campo de la inteligencia artificial. Tal vez sea una empresa que quiera formar un LLM con sus propios datos y utilizarlos externamente o vender acceso, o tal vez sea una startup que quiera crear un LLM y vender acceso.
-
Sabían que necesitaban GPU para entrenar modelos grandes.
-
Hablaron con algunos chicos de las grandes nubes (Azure, Google Cloud, AWS) que intentaban conseguir muchos H100.
-
Descubrieron que no podían obtener mucha asignación de las grandes nubes y que algunas de las grandes nubes no tenían buenas configuraciones de red. Entonces hablaron con otros proveedores como CoreWeave, Oracle, Lambda, FluidStack. Si quieren comprar las GPU ellos mismos y poseerlas, tal vez hablen con los OEM y también con Nvidia.
-
Al final, obtuvieron muchas GPU.
-
Ahora, intentan lograr que el producto se ajuste al mercado.
-
Si no fuera obvio, este camino no es tan bueno; recuerde, OpenAI logró que el producto se adaptara al mercado en modelos más pequeños y luego los amplió. Sin embargo, para que el producto se ajuste al mercado ahora, debe adaptarse al caso de uso del usuario mejor que el modelo de OpenAI, por lo que, en primer lugar, necesitará más GPU que las que OpenAI tenía al principio.
Se espera que al H100 le falten cientos o miles de implementaciones hasta al menos finales de 2023. La situación se aclarará a finales de 2023, pero por ahora, parece probable que la escasez continúe también hasta 2024.

Un recorrido por la oferta y la demanda de GPU. versión grande
ponte en contacto #
Autor: Arcilla Pascal. Las preguntas y notas se pueden enviar por correo electrónico .
Nuevas publicaciones: reciba notificaciones sobre nuevas publicaciones por correo electrónico .
Ayuda: mira aquí .
La siguiente pregunta natural: ¿qué pasa con las alternativas a Nvidia? #
La siguiente pregunta natural es "bueno, ¿qué pasa con la competencia y las alternativas? Estoy explorando alternativas de hardware además de enfoques de software. Envíe lo que debería explorar como alternativas a este formulario . Por ejemplo, TPU, Inferentia, LLM ASIC en el hardware Y otros productos, y Mojo, Triton y otros productos en el lado del software, y cómo se ve usando hardware y software AMD. Estoy explorando todo, aunque centrándome en lo que está disponible hoy. Si eres autónomo y quieres ayudar Llama 2 en ejecución en hardware diferente, envíeme un correo electrónico. Hasta ahora hemos ejecutado TPU e Inferentia en AMD, Gaudi, con la ayuda de personas de AWS Silicon, Rain, Groq, Cerebras y otros.
confirmar #
Este artículo contiene una cantidad sustancial de información patentada e inédita. Cuando vea personas preguntándose sobre la productividad de la GPU, indíqueles la dirección de este artículo.
Gracias a un puñado de ejecutivos y fundadores de empresas privadas de nube de GPU, algunos fundadores de IA, ingenieros de aprendizaje automático, investigadores de aprendizaje profundo, algunos otros expertos de la industria y algunos lectores no pertenecientes a la industria que brindaron comentarios útiles. Gracias a Hamid por la ilustración.

A100 \ H100 es básicamente cada vez menos en China continental, y A800 actualmente está dando paso a H800. Si realmente necesita A100 \ A800 \ H100 \ H800GPU, se recomienda no ser exigente. Para la mayoría de los usuarios, la diferencia entre HGX y La versión PCIE no es muy grande y puedes comprarla tan pronto como esté disponible.
En cualquier caso, elija fabricantes de marcas habituales para cooperar. En la situación actual del mercado donde la oferta y la demanda están desequilibradas, la mayoría de los comerciantes en el mercado no pueden suministrar e incluso proporcionar información falsa. Si se trata de un servidor de investigación científica, Fenghu Yunlong Scientific El servidor de investigación es la primera opción, la minería, la calidad y el servicio postventa están garantizados.
Bienvenido a comunicarse con el Gerente Chen【173-1639-1579】
¿Cuál es la relación y diferencia entre el aprendizaje automático, el aprendizaje profundo y el aprendizaje por refuerzo? - Zhihu (zhihu.com) Principales campos de aplicación y tres formas de inteligencia artificial (IA): inteligencia artificial débil , inteligencia artificial fuerte y súper inteligencia artificial . ¿Es rentable comprar un servidor de hardware o alquilar un servidor en la nube? - Zhihu (zhihu.com) Un resumen completo de los puntos de conocimiento del aprendizaje automático de aprendizaje profundo - Zhihu (zhihu.com) Sitio web de autoestudio sobre aprendizaje automático, aprendizaje profundo e inteligencia artificial, consulte aquí - Zhihu (zhihu.com) GPU de aprendizaje profundo 2023 Recomendado referencia para la configuración del servidor (3) -Zhihu (zhihu.com)

Se ha centrado en servidores informáticos científicos durante muchos años, preseleccionado para plataformas de minería política, H100, A100, H800, A800, RTX6000 Ada, un servidor de núcleo único de 192 sockets duales está disponible para la venta.

Se ha centrado en servidores informáticos científicos durante muchos años, preseleccionado para plataformas de minería política, H100, A100, H800, A800, RTX6000 Ada, un servidor de 192 núcleos de doble socket único está disponible para la venta.