
Escrito por Lu Jianping
Tras el lanzamiento de la GPU A100 en GTC (GPU Technology Conference) en 2020, después de dos años, NVIDIA anunció la H100, que los medios describieron como una GPU " bomba nuclear ", en GTC este año (2022) como se esperaba .
Después del GTC en 2020, muchas startups de GPU en China se esfuerzan por afirmar que pueden superar el A100; la DPU lanzada por NVIDIA en el GTC en 2021 también hace que muchas élites de chips compitan para iniciar negocios e invertir en el desarrollo de DPU, que se llama una tendencia; ¿qué tipo de respuesta provocará el H100 de este año?, y esperemos a ver.
Ha habido muchas introducciones sobre el H100 en los medios de comunicación e informes detallados sobre la tecnología del H100. Por ejemplo, el título principal es " Interpretación en profundidad de la arquitectura GPU de la bomba nuclear de 80 mil millones de transistores, y ¿Se trata de "bienes ensamblados"? ", y " Interpretación en profundidad de la arquitectura de GPU "HOPPER" de NVIDIA " a partir de la observación de la industria de semiconductores , que no se repetirá aquí. El propósito de este artículo es discutir la inspiración de las ideas técnicas y las estrategias de mercado detrás del H100 a China.¿Vale la pena que la industria nacional siga y siga? Para el GTC de 2024, la próxima generación del H100, ¿estaremos aún más atrasados?
1
Interpretando NVIDIA
Nvidia se ha comprometido a afirmar que en la era posterior a Moore, sus nuevos productos aún pueden superar la Ley de Moore tradicional, brindando a la industria más del doble de mejora en el rendimiento en comparación con los productos de hace dos años y diluyendo el costo del aumento del consumo de energía. . Cada generación de productos (Turing, Ampere y Hopper como ejemplos) básicamente se basan en cuatro potenciales de mejora del rendimiento para lograr el objetivo: 1) La mejora del proceso trae un aumento de frecuencia de menos de 1,5 veces; 2) Sin considerar el costo del consumo de energía, el número de unidades informáticas se duplica; 3) el diseño de arquitectura específica de dominio (DSA) duplica el rendimiento, como Turing's Tensor Core, hardware Sparsity de Ampere, Hopper's Transformer Engine; 4) la introducción de nuevos tipos de precisión de datos, reemplazando unidades de alta precisión con baja precisión, como el INT4 de Turing, el TF32 de Ampere y el FP8 de Hopper, ofrece un rendimiento doble.
Combinando estos factores, en teoría, hay 1,5 x 2 x 2 x 2 = 12 entre los productos generacionales de Nvidia, que es un espacio de mejora del rendimiento de orden de magnitud. Sin embargo, limitada por la realidad de la era posterior a la Ley de Moore y las restricciones del muro de poder, la mejora del rendimiento siempre es mucho menor que un orden de magnitud. Usando esta idea, Nvidia afirma que el H100 tiene seis veces el rendimiento del A100 con el siguiente gráfico:
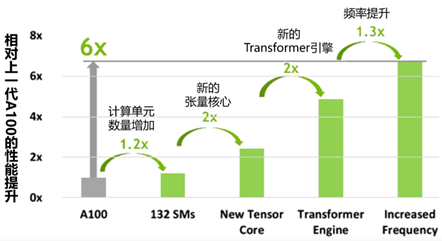
La mejora del rendimiento del H100 con respecto a la generación anterior A100
Sin embargo, es importante tener en cuenta que esta mejora del rendimiento de seis veces es un pico de un pico, un caso especial de un caso especial, no un rendimiento promedio en general. La razón es que este es el rendimiento máximo cuando se ejecuta una red como Transformer, y solo ocurre cuando los datos se pueden representar completamente en FP8. Además, en la era posterior a la Ley de Moore, cuando se trata de rendimiento, también debemos considerar el consumo de energía, y la relación rendimiento-potencia es un indicador más importante.
Además, también debemos excluir la mejora de la relación rendimiento-potencia provocada por el proceso para saber exactamente cuánto ha contribuido el H100 a la innovación de la arquitectura en relación rendimiento-potencia en comparación con el A100. Además, en realidad, muchas innovaciones de los productos NVIDIA necesitan tiempo para ser digeridas por la industria, y algunas funciones nuevas necesitan tiempo para ser aceptadas por el mercado, y es posible que el efecto universal final no ocurra, y realmente no tendrá tal gran impacto. Específicamente, la mayoría de los clientes harán la traducción primero al iterar, es decir, moverán directamente el código de la generación anterior a la siguiente generación. Como se puede ver en la siguiente tabla, en comparación con A100, H100 debería aumentar la potencia informática máxima en 3,2 veces en condiciones normales.
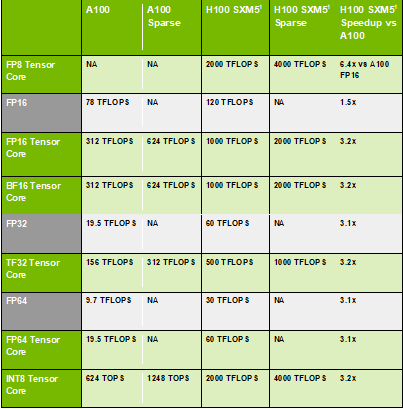
H100 VS A100
Suponiendo que el progreso del proceso N7 a N4 de TSMC haya aumentado la relación rendimiento-potencia en un 26 %, entonces el H100 tiene una mejora en la relación rendimiento-potencia de 3,2 x 350/700 - 1 = 60 % en comparación con el A100 en condiciones normales Si bien filtra la bendición del proceso, la innovación arquitectónica pura solo contribuye (3,2 x 350) / (1,26 x 700) -1 ≈ 30 % de la mejora máxima de la eficiencia de la potencia informática.
Entonces, ¿cuánto pagará el cliente al final a cambio de una mejora del rendimiento/vatio del 60 %? Todavía no sabemos si la relación precio/rendimiento de los productos de la serie H100 ha mejorado al final, pero lo que se sabe es que esta vez GTC no reveló el precio de DGX basado en H100, ni repitió el famoso dicho "el más compras, más ahorras” (“Cuanto más compras, más ahorras”).
2
Análisis técnico de rutas
A continuación analizamos varias rutas técnicas importantes del H100.
¿La GPU tomó la ruta DSA desde el H100?
Al final del informe del material principal, se menciona que el diseño de la H100 es el comienzo del desarrollo de la GPU de NVIDIA en la dirección de DSA (Arquitectura Específica de Dominio). Sin embargo, las GPU tradicionalmente han aceptado DSA, no del H100, que también es clave para la capacidad de NVIDIA para lidiar con calma con los desafíos de DSA. Lo que la gente común, incluidos los maestros de DSA, John Hennessey y el profesor David Patterson, no entienden es que la idea de los arquitectos de GPU siempre ha sido integrar DSA en una arquitectura general. Pero son heterogéneos en el núcleo, no en la parte superior del chip. Esto se puede ilustrar con la siguiente figura.
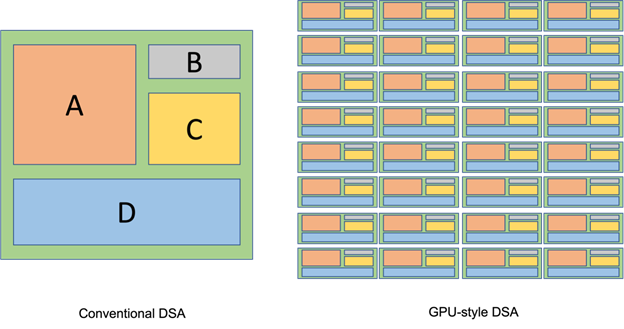
Diagrama de arquitectura DSA tradicional (izquierda) Diagrama esquemático de la arquitectura DSA de fusión de GPU (derecha)
El lado izquierdo de la imagen es un diagrama esquemático de la arquitectura DSA con el que la mayoría de la gente está de acuerdo.El chip de aceleración TPU AI de Google es más o menos así. El lado derecho de la figura es un diagrama esquemático de la arquitectura GPU Fusion DSA, como desde la unidad de textura temprana (Unidad de textura), la unidad de función especial (Unidad de función especial), hasta el núcleo tensor reciente (Núcleo tensor) y la persecución ligera. núcleo (núcleo RT). Estos ejemplos tienen algo en común:
1. Los recursos de hardware diseñados por un DSA se distribuyen uniformemente a cada unidad de cómputo, se referencian en forma de instrucciones especiales o llamadas a programas, y se vuelven parte del núcleo de cómputo general de cada unidad. No se convierte en un procesador independiente en la parte superior. del chip, pero puede ser La extensión natural de la ecología de programación no afecta el método de programación original.
2. Es adecuado para aplicaciones maduras en el mercado. Por ejemplo, la computación de texturas se usa para la mayoría de las aplicaciones gráficas, y la computación de tensores se usa para casi todos los algoritmos de IA. La cantidad de recursos invertidos puede basarse en la frecuencia de las aplicaciones, y no estará excesivamente ociosa.
Podemos llamar a la forma de integrar el diseño DSA de GPU como "generalización DSA", que fortalece continuamente las ventajas generales al tiempo que mejora el rendimiento. Esto puede explicar por qué los llamados chips diseñados especialmente para IA, incluido el TPU, no pueden aplastar a la GPU y son completamente corteses con la GPU en términos de versatilidad.
Esta vez, NVIDIA agregó el motor de transformador optimizado para redes de tipo transformador y el formato de datos FP8 correspondiente en el H100, y el conjunto de instrucciones especiales DPX optimizado para programación dinámica, que se puede decir que continúa con la tradición de generalización de DSA. En lo que respecta a Transformer Engine, la red de tipo Transformer ha sido reconocida como universal para varios campos de aplicación, rompiendo con la categoría de procesamiento de lenguaje natural, y Transformer Engine también está configurado en Tensor Core para realizar análisis estadísticos en el datos de capa de red Es posible en el futuro Puede generalizarse a otros tipos de redes.
Para DPX, Nvidia también citó aplicaciones como la secuenciación de genes y la planificación de rutas de robots. A diferencia de la aplicación anterior de los aceleradores DSA para mercados maduros, el ámbito de aplicación de Transformer Engine y DPX aún es relativamente pequeño a corto plazo y no han sido ampliamente aceptados por el mercado. NVIDIA está por delante del mercado esta vez. Se desconoce si esta es la tendencia de generalización de GPU DSA en el futuro. Para Tianshu Zhixin, estamos dispuestos a trabajar en estrecha colaboración con los clientes nacionales para abrir un camino de generalización de DSA que sea adecuado para el mercado nacional y tenga una visión técnica internacional.
H100 mejora la eficiencia informática general con "ejecución asíncrona"
H100 amplía la ruta de ejecución asíncrona iniciada por A100, mejora la eficiencia informática general y agrega Tensor Memory Accelerator (TMA) para abordar el problema de la memoria fuera del chip y la memoria compartida en el núcleo (SMEM) o mover grandes tensores entre SMEM. SMEM está conectado a un SM (Streaming Multiprocessor, la unidad informática de NVIDIA). Ahora, para admitir el movimiento de datos entre SMEM e integrarse en una parte de SMEM, ahora existe una red de interconexión entre SM.
Debido a la diversidad y la rápida evolución de los algoritmos de IA, no podemos tener ambos. En mi opinión, el objetivo final de la dirección de la tecnología de ejecución asíncrona es llenar la brecha de rendimiento entre el propósito general y el propósito especial, para que podamos tener ambos, y hacer que la eficiencia informática de propósito general de la GPU se acerque más a la de ASIC ( IC específico de la aplicación) Tubería dedicada común.
La palabra ASIC ahora está oscurecida casi por completo por DSA, y uso ASIC en lugar de DSA porque este último no está necesariamente centrado en la canalización. La característica especial de la tubería es que el productor y el consumidor continúan trabajando mientras los datos se transfieren del productor (Productor) al consumidor (Consumidor).
Fortalezco aún más esta dirección técnica como "gráficos computacionales", porque la tubería de gráficos, como se muestra en el lado izquierdo de la siguiente figura, es el trabajo representativo de la tubería dedicada. Aunque los nodos intermedios han sido reemplazados por programas de sombreado que se ejecutan en el grupo de computación general, su estructura de tubería aún existe. La ejecución asincrónica se acerca a la eficiencia de las canalizaciones dedicadas al no perder el tiempo esperando las transferencias de datos. Ante la llegada de la era posterior a la Ley de Moore, la computación general que toma prestado el espíritu de la canalización dedicada estilo ASIC es una ruta que debe seguirse.

tubería de gráficos
Los gráficos tradicionales no pueden utilizar completamente el poder de cómputo de IA de H100
De los 66 TPC en la versión H100 SMX y los 57 TPC en la versión PCIe, solo dos TPC son compatibles con gráficos. Este diseño puede deberse a que, aunque el área de hardware específico de gráficos no es grande en un TPC, después de multiplicarlo por unas 30 veces, es insoportable cuando el área y el consumo de energía ya han superado la tabla.
Debido a que los gráficos del H100 son tan desproporcionados para la informática de uso general, podemos llamar al H100 una GPU de uso general. Es concebible que una GPU de propósito general como la H100 deba tener capacidades gráficas equivalentes.La premisa es que los gráficos deben hacer un uso completo de la potencia informática de la IA y simplificar el hardware específico de gráficos sin reducir las funciones y el rendimiento.

Simplifique los gráficos con sombreadores de malla
Con múltiples nodos en la canalización de gráficos siendo reemplazados por programas de sombreado que se ejecutan en un grupo de computación de uso general, ¿por qué no reducir algunos nodos de sombreado? Como se muestra en la figura anterior, en el estándar de gráficos avanzados, el nuevo sombreador de malla que usa más funciones informáticas puede reemplazar el sombreador de vertex shader por sombreador de geometría, de modo que la cantidad de nodos de canalización de gráficos se puede reducir en gran medida sin reducir la función. Retire algunos nodos de conexión de hardware especializados. El rendimiento también puede mejorar debido a la flexibilidad que tienen los sombreadores de malla. Este es el primer paso para simplificar el gráfico.
En el modelo de metaverso/gemelo digital de NVIDIA, la serie de GPU de propósito general H100 y las GPU de gráficos RTX desempeñan sus funciones respectivas. Sin embargo, la GPU de gráficos necesita soporte informático general para admitir las operaciones de simulación física requeridas por el gemelo digital, y también requiere IA para realizar superresolución y reducción de ruido para el seguimiento de la luz. Por el contrario, las GPU de uso general requieren renderizado para participar ampliamente en la generación de contenido basado en IA y el modelado 3D.
Mi opinión es que las GPU gráficas y de uso general deberían converger. Pero el H100 no hizo esto porque el H100 como GPU de propósito general ya está altamente optimizado para IA. Una afirmación más correcta es que la computación tensorial ha evolucionado desde el papel del coprocesamiento hasta el centro de potencia informática de las GPU de uso general, porque la IA está dominada por la computación tensorial.
Sin embargo, los algoritmos de sombreado de renderizado de gráficos tradicionales no se basan en tensores. Esto significa que la única forma en que las GPU de uso general que admiten la computación de tensor para lograr gráficos coincidentes es poder integrar gráficos e IA, por lo que los sombreadores de representación de gráficos también deben usar algoritmos basados en IA. Llamo a esta tendencia "Computacionalización de gráficos".
Esto es difícil para NVIDIA, como líder del mercado en tarjetas gráficas, porque la elección y escritura de los algoritmos de sombreado depende del desarrollador de la aplicación gráfica. Para Tianshu Zhixin, el objetivo de nuestros gráficos es admitir la representación en la nube del metaverso/gemelo digital y tener la oportunidad de desarrollar un ecosistema que pertenezca a China con los clientes, de modo que el desarrollo de aplicaciones gráficas se base en IA, y está optimizado para computación tensorial.La GPU de uso general también puede mostrar su talento en el campo de los gráficos.
3
Una gran alianza de profunda cooperación y sana competencia
La pregunta que más preocupa a todos es, ¿cómo nos acercamos o incluso superamos a Nvidia? Como se analizó anteriormente, en circunstancias normales, después de filtrar factores como el proceso y el consumo de energía, la innovación en la arquitectura H100 contribuye en aproximadamente un 30 % a la mejora del rendimiento en comparación con el A100. Si queremos superar a NVIDIA en 2024, tomaremos un camino diferente. En la ruta técnica, debemos:
1. Cooperar con los clientes nacionales para hacer que la generalización de DSA sea adecuada para el mercado nacional para continuar con la ventaja general
2. Con gráficos informáticos, mejore el rendimiento informático general, comparable a la canalización de gráficos
3. Cooperar con el ecosistema doméstico para unir directamente los estándares de gráficos avanzados a través de la computación de gráficos y permitir que las GPU de uso general que se especializan en computación de tensor muestren sus talentos en el campo de los gráficos.
No podemos ignorar la importancia del "desarrollo totalmente autónomo y la tecnología ampliamente utilizada" en la pista de GPU. Solo al insistir en la innovación independiente, el diseño y el desarrollo independientes desde el hardware subyacente hasta el software de nivel superior, y no tomar el atajo de comprar IP de GPU extranjera, podemos garantizar derechos de propiedad intelectual completamente independientes y romper la situación nacional a largo plazo como un agente de PI extranjero. Solo la arquitectura, el núcleo informático, el conjunto de instrucciones y la pila de software básico completamente desarrollados por ellos mismos pueden responder de inmediato a las demandas del mercado que cambian rápidamente y lograr un desarrollo sostenible e independiente sin estar restringido por IP extranjera. Además, la prueba abierta de diferentes niveles técnicos requeridos por los clientes puede garantizar fundamentalmente la seguridad del uso y la información de los clientes.
Como The Information me citó en un informe titulado "La 'pequeña Nvidia' de China tiene un gran secreto: su chip de IA de cosecha propia no lo es", "El único camino a seguir es escribir código línea por línea para implementar las funciones principales de la GPU . La única forma de ser autónomo". Una vez que hayamos desarrollado chips de GPU completamente independientes con una amplia gama de tecnologías, también debemos poder comparar con NVIDIA en términos de pruebas, adaptación del cliente, suministro estable, producción en masa exitosa y aplicaciones a gran escala, y solo cintas y iluminación, se puede decir que es la etapa inicial de la pista.
Finalmente, también necesitamos explorar la importancia fundamental de tomar prestado de Nvidia. Queremos ver una empresa, en términos de poder de cómputo, abarcando chips, tableros, servidores, clústeres pequeños, clústeres grandes para centros de datos e incluso centros de poder de cómputo, y en la red, cubriendo chips, chips, chasis y clústeres. , así como en la aplicación, ¿se basa en la fuerza de los chips, que se utilizan ampliamente en medicina, Internet, fábricas, conducción autónoma y biomedicina?
Lo que China necesita puede ser una gran alianza que sea comparable a Nvidia en términos de profundidad y amplitud técnica, y que se base en una cooperación profunda y una competencia sana.

Lv Jianping, director de tecnología (CTO) de Tianshu Zhixin. Se graduó de la Universidad de Yale con un doctorado en Ciencias de la Computación. Ha ocupado cargos importantes en gigantes multinacionales de semiconductores como Nvidia, Intel y Samsung. Es un reconocido experto en el campo de GPU.
(Este artículo se publica con permiso. Original :
https://mp.weixin.qq.com/s/rtO8PxRj08GVimT3bfbplA)
Combatiendo la complejidad del sistema de software: estratificación adecuada, ni más ni menos
Lanzamiento de OneFlow v0.7.0: una nueva interfaz distribuida, LiBai, Serving, etc. están disponibles

Este artículo se comparte desde la cuenta pública de WeChat: OneFlow (Tecnología OneFlow).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Proyecto OSC Yuanchuang ", le invitamos a unirse y compartir con nosotros.