Haga clic en la tarjeta a continuación para seguir la cuenta oficial de " CVer "
Mercancías secas pesadas AI/CV, entregadas por primera vez
Haga clic para ingresar —> [Visión artificial y envío en papel] Grupo de intercambio
Mengchen Keleixi enviado desde el Templo Aofei
y reimpreso desde: Qubit (QbitAI)
¡ Nvidia H100 , la mejor GPU para refinar modelos grandes , está agotada !
Incluso si lo solicita ahora, no estará disponible hasta el primer trimestre o incluso el segundo trimestre de 2024 .
Esta es la última noticia revelada al Wall Street Journal por CoreWeave, un proveedor de nube estrechamente relacionado con Nvidia.
La oferta ha sido extremadamente escasa desde principios de abril. En sólo una semana , los plazos de entrega previstos aumentaron desde niveles razonables hasta finales de año .

Amazon AWS, el proveedor de nube más grande del mundo, también confirmó la noticia. El CEO Adam Selipsky dijo recientemente:
A100 y H100 son lo último en tecnología... difíciles de conseguir incluso para AWS .
Anteriormente, Musk también dijo en un programa de entrevistas: la GPU ahora es más difícil de obtener que los dardos .

Si encuentra un "revendedor" para comprar, la prima es tan alta como 25% .
Por ejemplo, el precio en Ebay ha subido de unos 36.000 dólares en fábrica a 45.000 dólares , y la oferta es escasa.
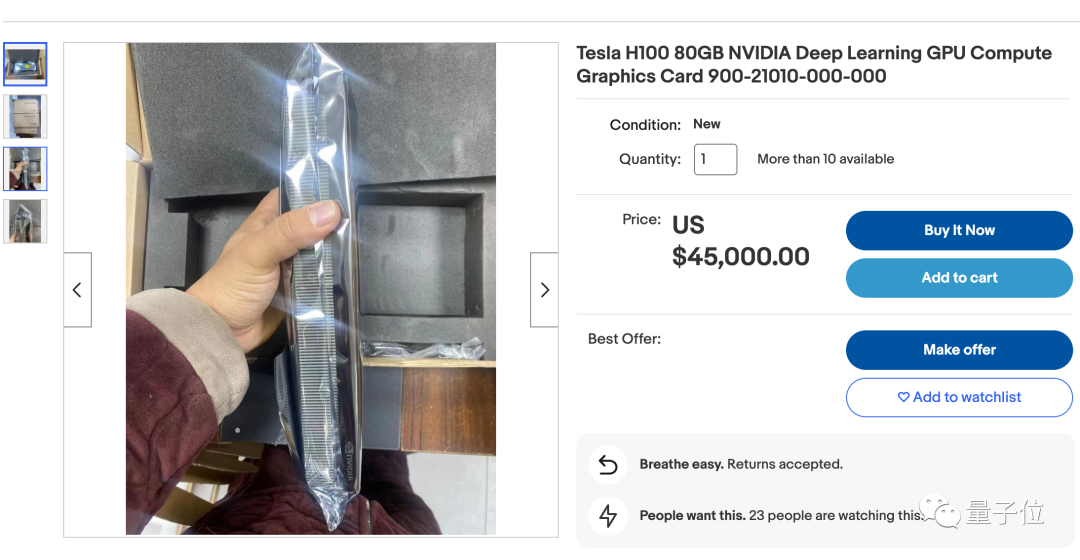
En esta situación, las grandes empresas tecnológicas nacionales como Baidu, Byte, Ali y Tencent también han realizado pedidos de A800 y otros chips por un total de 5.000 millones de dólares a Nvidia.
Entre ellos, solo se pueden entregar 1.000 millones de dólares estadounidenses en bienes dentro de este año, y el otro 80% tendrá que esperar hasta 2024.
Entonces, ¿a quién se venden las GPU de gama alta existentes? ¿Dónde está estancada esta ola de capacidad de producción?
A quién vender el H100, Lao Huang tiene la última palabra
Desde el estallido de ChatGPT, Nvidia A100 y H100, que son buenos para entrenar modelos grandes, se han vuelto populares.
Las empresas de inteligencia artificial representadas por OpenAI y Meta , las empresas de computación en la nube representadas por Amazon y Microsoft , las nubes privadas Coreweave y Lambda, y todo tipo de empresas de tecnología que desean refinar sus propios modelos a gran escala tienen una gran demanda.
Sin embargo, es básicamente el CEO de Nvidia, Huang Renxun, quien tiene la última palabra sobre a quién vender.

Según The Information, H100 tiene tal escasez que Nvidia asignó una gran cantidad de tarjetas nuevas a CoreWeave y un suministro limitado a empresas de computación en la nube establecidas como Amazon y Microsoft .
(Nvidia también ha invertido directamente en CoreWeave).
El análisis externo se debe a que estas empresas establecidas están desarrollando sus propios chips de aceleración de IA, con la esperanza de reducir su dependencia de Nvidia, por lo que Lao Huang los ayudará.
Lao Huang también controla todos los aspectos de las operaciones diarias de la empresa dentro de Nvidia, incluido incluso "revisar lo que los representantes de ventas van a decir a los pequeños clientes potenciales " .
Alrededor de 40 ejecutivos de la empresa reportan directamente a Lao Huang , que es más que los subordinados directos de Meta Xiaozha y Microsoft Xiaona combinados.
Un ex gerente de Nvidia reveló: "En Nvidia, Huang Renxun es en realidad el director de producto de cada producto ".

Hace un tiempo, también se informó que Lao Huang hizo algo exagerado: pidió a algunas pequeñas empresas de computación en la nube que proporcionaran sus listas de clientes y quería saber quiénes eran los usuarios finales de la GPU.
Según un análisis externo, este movimiento permitirá a Nvidia comprender mejor las necesidades de los clientes para sus productos, y también ha expresado su preocupación de que Nvidia pueda usar esta información para obtener beneficios adicionales.
Algunas personas también piensan que otra razón es que Lao Huang quiere saber quién realmente está usando la tarjeta y quién simplemente la está acumulando y no la está usando.

¿Por qué Nvidia y Lao Huang tienen una voz tan grande ahora?
La razón principal es que la oferta y la demanda de GPU de gama alta están demasiado desequilibradas. Según el cálculo del sitio web GPU Utils, la brecha H100 es de hasta 430.000 .
El autor Clay Pascal estimó la cantidad de H100 que necesitarán varios actores de la industria de la IA en un futuro próximo basándose en información y rumores conocidos.
Para empresas de IA:
OpenAI puede necesitar 50,000 H100 para entrenar GPT-5
Se dice que Meta necesita 100.000
Se ha anunciado el plan de clúster de potencia informática de 22,000 tarjetas de InflectionAI
Las principales empresas emergentes de IA, como Anthropic, Character.ai, MistraAI y HelsingAI en Europa, requieren del orden de 10 000 cada una.
Para empresas de computación en la nube:
En nubes públicas a gran escala, Amazon, Microsoft, Google y Oracle se calculan en 30 000, un total de 120 000
La nube privada representada por CoreWeave y Lambda necesita un total de 100.000
Suma 432.000.
Esto sin contar algunas compañías financieras y otros participantes de la industria, como JP Morgan Chase y Two Sigma, que también han comenzado a implementar sus propios clústeres de potencia informática.
Entonces, la pregunta es, con una brecha de suministro tan grande, ¿no podemos producir más?
Lao Huang también quería hacerlo, pero la capacidad de producción estaba atascada .
¿Dónde está atascada la capacidad de producción esta vez?
De hecho, TSMC ya ha ajustado su plan de producción para Nvidia.
Sin embargo, todavía no pudo llenar un vacío tan grande.
Charlie Boyle, vicepresidente y gerente general del sistema DGX de Nvidia, dijo que esta vez no estaba atascado en la oblea , sino que la capacidad de producción de la tecnología de empaquetado CoWoS de TSMC encontró un cuello de botella.
Es Apple la que compite con Nvidia por la capacidad de producción de TSMC, y obtendrá el chip A17 para el iPhone de próxima generación antes de la conferencia de septiembre.
TSMC declaró recientemente que se espera que tome 1,5 años para que la acumulación del proceso de empaque vuelva a la normalidad.
La tecnología de empaquetado CoWoS es la habilidad de limpieza de TSMC, y la razón por la que TSMC puede vencer a Samsung para convertirse en la fundición de chips exclusiva de Apple depende de ello.
Los productos empaquetados por esta tecnología tienen un alto rendimiento y una gran confiabilidad, por lo que el H100 puede tener un ancho de banda de 3 TB/s (o incluso más).
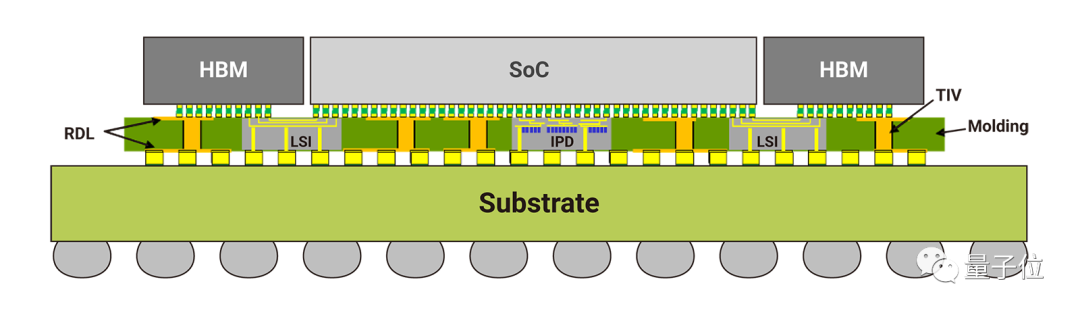
El nombre completo de CoWoS es Chip-on-Wafer-on-Substrate, que es una tecnología de integración de chips a nivel de oblea .
Esta tecnología puede empaquetar varios chips en un intercalador de silicio con un grosor de solo 100 μm .
Según los informes, el área del intercalador de próxima generación alcanzará 6 veces la retícula, que es de aproximadamente 5000 mm².
Hasta ahora, aparte de TSMC, ningún fabricante tiene este nivel de capacidad de empaque.

Si bien CoWoS es ciertamente poderoso, ¿no funcionaría sin él? ¿Pueden hacerlo otros fabricantes?
Sin mencionar que Lao Huang ya ha declarado que "no consideraremos agregar una segunda fundición H100".
En realidad, podría no ser posible.
Nvidia ha cooperado con Samsung antes, pero este último nunca ha producido productos de la serie H100 para Nvidia, ni siquiera otros chips de proceso de 5 nm.
En base a esto, algunas personas especulan que el nivel técnico de Samsung puede no ser capaz de satisfacer las necesidades tecnológicas de Nvidia para GPU de última generación.
En cuanto a Intel... sus productos de 5nm no parecen salir todavía.

Dado que no es factible cambiar el fabricante de Lao Huang, ¿qué tal si los usuarios cambian directamente a AMD?
AMD,Sí?
Solo en términos de rendimiento, AMD se está poniendo al día lentamente.
El último MI300X de AMD tiene 192 GB de memoria HBM3, un ancho de banda de 5,2 TB/s y puede ejecutar 80 000 millones de modelos de parámetros.
La DGX GH200 que acaba de lanzar Nvidia tiene una memoria de 141GB de HBM3e y un ancho de banda de 5TB/s.
Pero esto no significa que AMD pueda llenar inmediatamente la vacante de la tarjeta N——
El verdadero "foso" de Nvidia se encuentra en la plataforma CUDA.
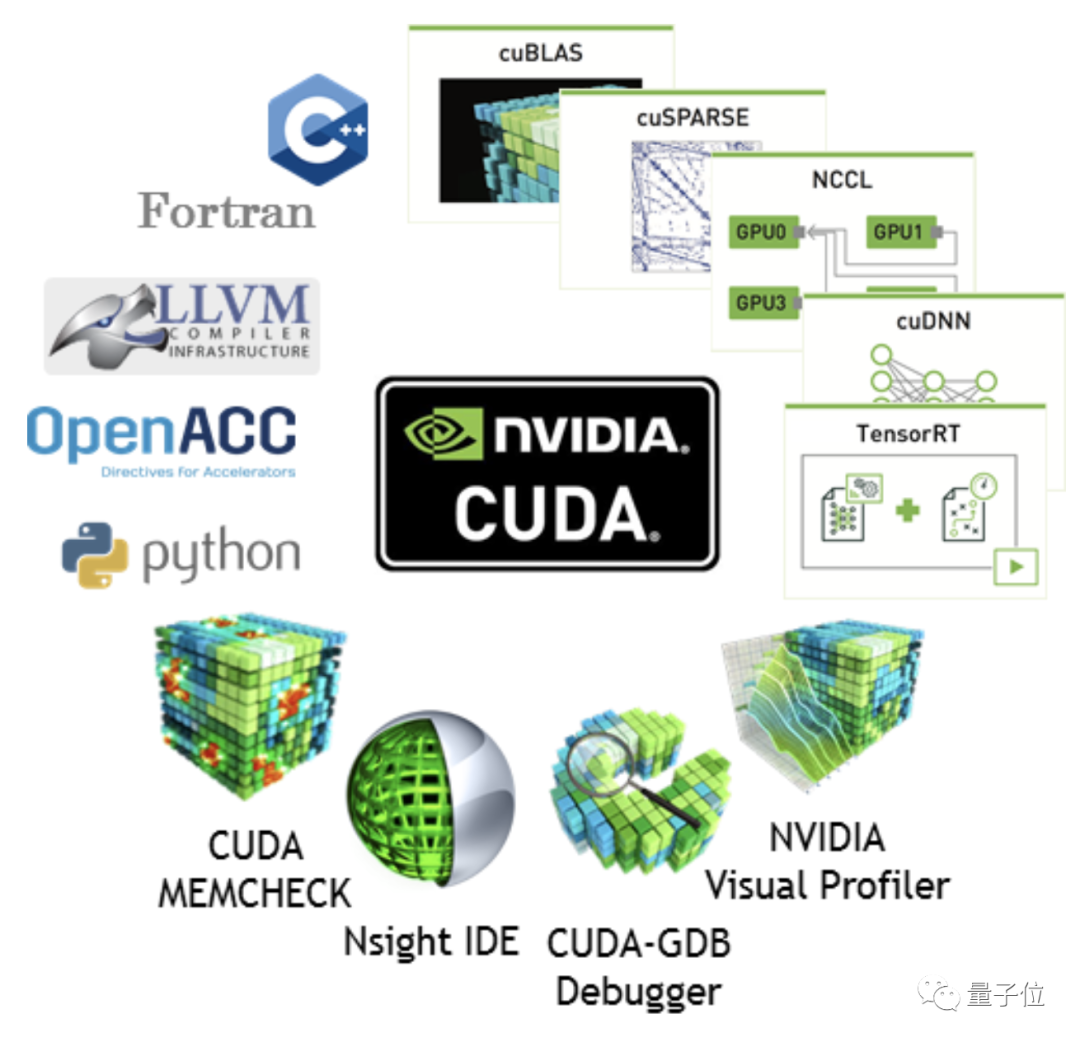
CUDA ha establecido un ecosistema de desarrollo completo, lo que significa que si los usuarios compran productos AMD, la depuración llevará más tiempo.
Un ejecutivo de una empresa de nube privada dijo que nadie se atrevería a gastar $ 300 millones para implementar 10,000 GPU AMD de forma experimental.
El ejecutivo cree que el ciclo de desarrollo y depuración puede demorar al menos dos meses.
En el contexto de la rápida sustitución de los productos de IA, una brecha de dos meses puede ser fatal para cualquier fabricante.

Sin embargo, Microsoft extendió una rama de olivo a AMD.
Anteriormente, hubo rumores de que Microsoft se estaba preparando para desarrollar conjuntamente con AMD un chip de IA con el nombre en código "Athena".
Anteriormente, cuando se lanzó MI200, Microsoft fue el primero en anunciar la compra e implementarla en su plataforma en la nube Azure.
Por ejemplo, la nueva infraestructura de modelo grande RetNet de MSRA se capacitó en 512 AMD MI200 hace un tiempo .

En la situación en la que Nvidia ocupa casi todo el mercado de IA, es posible que alguien deba tomar la iniciativa y todo el clúster de potencia informática de AMD a gran escala debe ser prototipo antes de que alguien se atreva a seguir.
Sin embargo, en un corto período de tiempo, Nvidia H100 y A100 siguen siendo las opciones más populares.
Una cosa más
Hace un tiempo, cuando Apple lanzó el nuevo chip M2 Ultra que admite hasta 192 GB de memoria , muchos practicantes disfrutaron usándolo para afinar modelos grandes.
Después de todo, la memoria y la memoria de video de los chips de la serie M de Apple están unificadas. 192 GB de memoria son 192 GB de memoria de video , que es 2,4 veces la de 80 GB H100 u 8 veces la de 24 GB RTX4090.
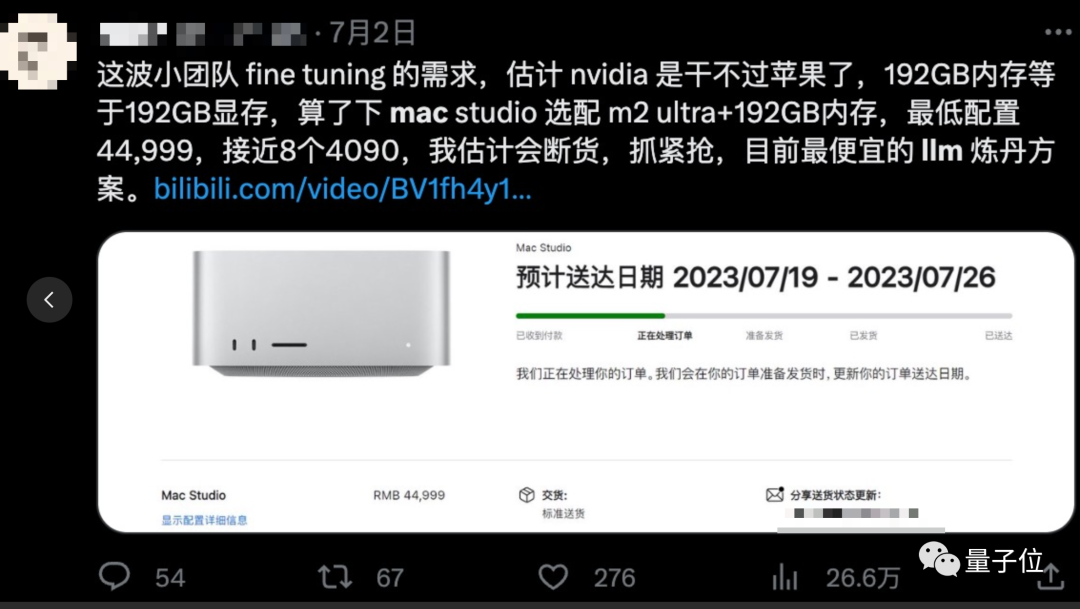
Sin embargo, después de que alguien realmente compró esta máquina, la prueba real y la velocidad de entrenamiento no son tan buenas como Nvidia RTX3080TI , el ajuste fino no es rentable, y mucho menos el entrenamiento.
Después de todo, la potencia informática de los chips de la serie M no está específicamente optimizada para la informática de IA, y la memoria de video Everbright es inútil.
Parece que depende principalmente de H100 para refinar el modelo grande, y H100 es algo que no se puede pedir.
Ante esta situación, incluso hay una mágica "canción de GPU" que circula en Internet .
Muy lavado de cerebro, entrar con precaución.
La canción de GPU
https://www.youtube.com/watch?v=YGpnXANXGUg
Nota:
[1]https://www.barrons.com/articles/nvidia-ai-chips-coreweave-cloud-6db44825
[2]https://www.ft.com/content/9dfee156-4870-4ca4- b67d-bb5a285d855c
[3]https://www.theinformation.com/articles/in-an-unusual-move-nvidia-wants-to-know-its-customers-customers
[4]https://www.theinformation. com/articles/ceo-jensen-huang-runs-nvidia-with-a-strong-hand
[5]https://gpus.llm-utils.org/nvidia-h100-gpus-supply-and-demand/#which -gpus-do-people-need
[6]https://3dfabric.tsmc.com/english/dedicatedFoundry/technology/cowos.htm
[7]https://developer.nvidia.com/blog/cuda-10-features -revelado/
[8]https://www.theverge.com/2023/5/5/23712242/microsoft-amd-ai-processor-chip-nvidia-gpu-athena-mi300
[9]https://www.amd.com/en/press-releases/2022-05-26-amd-instinct-mi200-adopted-for-large-scale-ai-training-microsoft-azure
Haga clic para ingresar —> [Visión artificial y envío en papel] Grupo de intercambio
ICCV/CVPR 2023 Descarga de papel y código
Respuesta de antecedentes: CVPR2023, puede descargar la colección de documentos CVPR 2023 y codificar documentos de código abierto
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号No es fácil de organizar, dale me gusta y mira![]()