
modelo de almacenamiento de datos
Contenido de la columna :
- Análisis del código fuente del kernel de Postgresql
- base de datos manuscrita toadb
- programación concurrente
- biblioteca de código abierto toadb
Página de inicio personal : Mi página de inicio
Lema: Tian Xingjian, un caballero que lucha por la superación personal; Geografía Kun, un caballero que lleva la virtud.
descripción general
En el proceso de desarrollo de las bases de datos, las bases de datos relacionales son una etapa importante y ahora los datos relacionales todavía ocupan una posición importante. En datos relacionales, cada tabla es una relación y cada fila de datos es un registro de la relación. Al almacenar, cada fila de datos se almacena en una posición continua y las filas también se almacenan
consecutivamente;
Manejo del tipo de negocio
Con el auge de Internet, la mejora de la capacidad de almacenamiento y el salto de la potencia informática, cada vez se han añadido a nuestras vidas más dispositivos inteligentes que generan un sinfín de información.
La escala de dicha información ha excedido el límite de capacidad de una sola entidad y se clasifica continuamente. Para los modelos de procesamiento de bases de datos, a menudo se dividen en:
- Modelo de procesamiento de transacciones en línea (OLTP), basado principalmente en la coherencia de las transacciones y datos relacionales;
- El modelo de procesamiento analítico en línea (OLAP) se basa principalmente en análisis y estadísticas, y más es extraer datos de varias dimensiones de una gran cantidad de datos;
Sin embargo, esta división está lejos de satisfacer las necesidades generadas por la explosión de la información. No es una clasificación en blanco y negro con límites claros. Todavía hay una gran cantidad de datos y servicios que tienen las características tanto de OLTP como de OLAP. En este momento, se utiliza un modelo de almacenamiento de base de datos híbrido.
Principio del modelo de almacenamiento de datos.
qué es
Los datos insertados a través de SQL en realidad se almacenan en el disco de la base de datos. En este momento, también debemos considerar la eficiencia de nuestra escritura, la eficiencia de la lectura, cómo generar menos veces IO y en qué formato organizar estos datos. ¿Cómo podemos lograr tal objetivo?
El sistema de archivos que utilizamos lee y escribe dispositivos de almacenamiento físico en unidades de bloques, los tamaños de bloque comúnmente utilizados son 2k, 4k, etc., luego, para mejorar el rendimiento, la base de datos también elige organizar los datos en unidades de bloques, cada vez. por bloque Leer y escribir archivos de datos.
Cada bloque de datos se divide además en: dominio de información del encabezado del bloque, el desplazamiento inicial del dominio de datos y el dominio de datos, que se almacenan continuamente de acuerdo con las filas de la tabla lógica en el dominio de datos.Por supuesto, los datos de fila se dividen en dos métodos de organización diferentes: longitud fija o longitud variable; longitud fija, es decir, cada tipo de datos tiene una longitud fija, por lo que también se determina la longitud de una fila de datos; tipos de longitud variable, como como caracteres, texto, etc. La longitud es variable, por lo que es necesario registrarla al almacenarla.
La mayor diferencia entre ellos es que al actualizar, la longitud fija se puede sobrescribir y actualizar directamente, mientras que la longitud variable requiere una actualización adicional.
¿Por qué es tan importante el modelo de almacenamiento?
Debido a que nuestros datos almacenados en la base de datos persisten en el disco, cuando consultamos y luego leemos desde el disco, aunque
nuestra base de datos y los niveles del sistema operativo se han almacenado en caché, cuando la cantidad de datos es grande, aún generará una gran cantidad de disco IO, y la base de datos es principalmente de acceso aleatorio, el caché no garantiza todos los accesos.En comparación con la velocidad de la memoria, la velocidad del disco es extremadamente baja, pero la memoria a menudo es limitada, por lo que el modelo de almacenamiento es muy importante. Al convertir escrituras aleatorias en escrituras secuenciales, menos IO pueden encontrar datos con precisión y reducir el recorrido. Todo esto puede reducir el número de IO y mejorar el rendimiento.
Tipo de modelo de almacenamiento de datos
modelo NSM
Como su nombre lo indica, tiene la forma de una matriz ordenada por filas de datos. La estructura física de los datos es la misma que su estructura lógica, que es lo que a menudo llamamos modelo de almacenamiento de filas, que también es el modelo de almacenamiento adoptado. por la mayoría de las bases de datos relacionales.
estructura de almacenamiento físico
El disco se compone de bloques de datos uno por uno, por lo que los datos continuos también se dividen en bloques de datos continuos.
Cada bloque de datos se divide en información de encabezado de bloque, que registra el desplazamiento inicial de los datos en el bloque, y cada fila de datos se divide en elementos de desplazamiento de datos de fila, que se almacenan continuamente desde la parte posterior del encabezado del bloque, y el real Los datos de la fila, que comienzan desde el final del bloque, se almacenan continuamente hacia el encabezado, lo que facilita la gestión del espacio libre.Los datos de la tabla corresponden a la estructura de almacenamiento físico como se muestra en la siguiente figura:
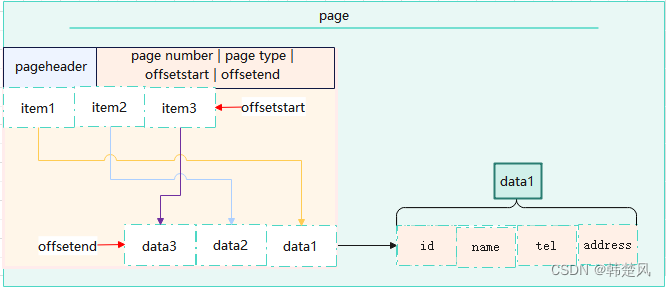
Escenario de aplicación
- Su ventaja es que la consulta de datos asociados es muy rápida, por ejemplo, se puede leer al mismo tiempo una serie de información como nombre y dirección en función del número de documento de identidad.
Sobre esta base, resulta muy ventajoso para uniones anidadas complejas, porque sus columnas de datos están todas juntas.
no adecuado para la escena
- Para las empresas que solo buscan parte de los datos de atributos de la columna, el costo de IO aumentará, lo que requiere la lectura de toda la fila de datos. Para el diseño según 3NF, o una tabla grande y ancha, no se puede evitar la reducción de la eficiencia de la caché.
modelo DSM
Modelo de almacenamiento descompuesto, es decir, almacena cada campo en una fila en diferentes unidades de datos. Cuando se necesita una columna de datos, solo se carga una parte de los datos desde el disco. Si se necesita toda la fila de datos, la cantidad total de Se cargan los datos y luego la fila Ensamblar.
Cada columna se puede almacenar por separado o se puede dividir de forma irregular según las necesidades comerciales. Por ejemplo, si hay tres columnas que a menudo se consultan al mismo tiempo, estas tres columnas se pueden almacenar juntas y las columnas restantes se pueden almacenar. por separado.
estructura de almacenamiento físico
Los formatos comunes son:
- PAZ
- RCFile (archivo de columnas de registro)
- Apache ORC
- Parquet (un almacenamiento en columnas abierto para Hadoop)
Entre ellos, más se inclinan por el almacenamiento analítico en columnas, que puede manejar una gran cantidad de series temporales y datos de transmisión, y algunos se inclinan por el tipo híbrido de fila y columna, y cada formato tiene aplicaciones de productos maduros.
Escenario de aplicación
Sus escenarios son más analíticos, como la serie hdoop, usando ORC, Parquet.
Modelo de almacenamiento de datos híbrido
Para combinar las ventajas de NSM y DSM anteriores y complementarse entre sí, algunas bases de datos han adoptado algunos modelos de almacenamiento mixto.
Prácticas comunes de modelos mixtos
- redundancia de datos
Al almacenar datos, simplemente almacene en dos formatos al mismo tiempo, uno se almacena por fila y el otro se almacena por separado por columna, lo que evita la complejidad de las bandas de conversión e intercambia espacio por rendimiento; en el motor de optimización, puede elegir una ruta de formato más adecuada de;
- tipo de conversión de datos
Debido a que el almacenamiento en filas debe traer amplificación IO, el almacenamiento en columnas también se usa para el almacenamiento real y se ensambla en datos de filas lógicas cuando se usa; la dificultad de este modelo radica en cómo encontrar con precisión cada campo en la fila lógica, principalmente usando La forma de agrupación mencionada en PAX.
dificultad
En el procesamiento de big data, ya no se limita a datos relacionales, sino a datos más no relacionales, como texto y datos json. Cómo convertirlos en datos de columnas, que se pueden buscar rápidamente, será un problema que enfrentará el híbrido. Desafío del modelo de almacenamiento.
La cantidad de datos vectoriales que han surgido recientemente corresponde a la dimensión del modelo grande, y el almacenamiento de la base de datos subyacente necesita almacenar cada tipo de datos por separado.
fin
Muchas gracias por tu apoyo. No olvides dejar tus valiosos comentarios mientras navegas. Si crees que es digno de aliento, dale me gusta y márcalo como favorito, ¡trabajaré más duro!
Correo electrónico del autor: [email protected]
Si hay errores u omisiones, indíquelos y aprendan unos de otros.
Nota: ¡No reimprima sin consentimiento!