Amazon Kendra es un servicio de búsqueda inteligente impulsado por aprendizaje automático (ML). Amazon Kendra reinventa las capacidades de búsqueda de su sitio web y sus aplicaciones para que sus empleados y clientes puedan encontrar fácilmente contenido disperso en múltiples ubicaciones y repositorios de contenido en toda su organización.
| La comunidad de desarrolladores de tecnología en la nube de Amazon proporciona a los desarrolladores recursos tecnológicos de desarrollo global. Hay documentos técnicos, casos de desarrollo, columnas técnicas, vídeos de formación, actividades y concursos, etc. Ayude a los desarrolladores chinos a conectarse con las tecnologías, ideas y proyectos más avanzados del mundo, y recomiende desarrolladores o tecnologías chinos destacados a la comunidad global de la nube. Si aún no ha prestado atención/favorito, no se apresure cuando vea esto, ¡ haga clic aquí para convertirlo en su tesoro técnico! |
Amazon Kendra admite varios formatos de documentos , como Microsoft Word, PDF y texto de diversas fuentes de datos . En este artículo, nos centramos en las extensiones compatibles con los documentos de Amazon Kendra que permiten buscar imágenes a través del contenido mostrado. A menudo se pueden buscar imágenes utilizando metadatos complementarios, como palabras clave. Sin embargo, agregar metadatos detallados a decenas de miles de imágenes requiere mucho trabajo manual. La IA generativa (GenAI) puede ayudar a automatizar la generación de metadatos. GenAI Caption Prediction proporciona metadatos descriptivos para imágenes generando títulos de texto. Luego, durante la ingesta de documentos, los metadatos resultantes se pueden utilizar para enriquecer el índice de Amazon Kendra, haciendo que las imágenes se puedan buscar sin ningún esfuerzo manual.
Amazon Kendra es un servicio de búsqueda inteligente impulsado por aprendizaje automático (ML). Amazon Kendra reinventa las capacidades de búsqueda de su sitio web y sus aplicaciones para que sus empleados y clientes puedan encontrar fácilmente contenido disperso en múltiples ubicaciones y repositorios de contenido en toda su organización.
Amazon Kendra admite varios formatos de documentos , como Microsoft Word, PDF y texto de diversas fuentes de datos . En este artículo, nos centramos en las extensiones compatibles con los documentos de Amazon Kendra que permiten buscar imágenes a través del contenido mostrado. A menudo se pueden buscar imágenes utilizando metadatos complementarios, como palabras clave. Sin embargo, agregar metadatos detallados a decenas de miles de imágenes requiere mucho trabajo manual. La IA generativa (GenAI) puede ayudar a automatizar la generación de metadatos. GenAI Caption Prediction proporciona metadatos descriptivos para imágenes generando títulos de texto. Luego, durante la ingesta de documentos, los metadatos resultantes se pueden utilizar para enriquecer el índice de Amazon Kendra, haciendo que las imágenes se puedan buscar sin ningún esfuerzo manual.
Por ejemplo, durante la ingesta de imágenes de documentos, se podría utilizar un modelo GenAI para generar una descripción textual para la siguiente imagen "un perro tirado en el suelo bajo un paraguas".

El modelo de reconocimiento de objetos aún puede detectar palabras clave como "perro" y "paraguas", pero el modelo GenAI proporciona una comprensión más profunda de lo que se representa en la imagen al identificar un perro acostado bajo un paraguas. Esto nos ayuda a crear búsquedas más refinadas durante el proceso de búsqueda de imágenes. Las descripciones de texto se agregan automáticamente al índice de búsqueda de Amazon Kendra como enriquecimiento de documentos personalizado (CDE). Un usuario que busque "perro" o "paraguas" podrá encontrar esa imagen, como se muestra en la siguiente captura de pantalla.
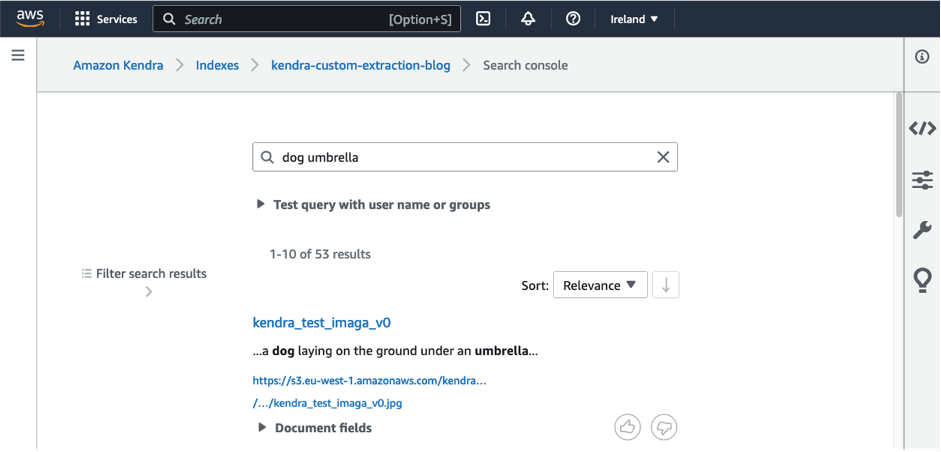
En este artículo, mostramos cómo utilizar CDE en Amazon Kendra con un modelo GenAI implementado en Amazon SageMaker . Demostramos CDE usando un ejemplo simple y proporcionamos una guía paso a paso para que pueda experimentar CDE en su índice de Amazon Kendra en su cuenta de Amazon Web Services. Permite a los usuarios encontrar rápida y fácilmente las imágenes deseadas mediante consultas en lenguaje natural sin etiquetado ni clasificación manual. La solución también se puede personalizar y ampliar según las necesidades de diferentes aplicaciones e industrias.
Subtítulos de imágenes con GenAI
Describir imágenes con GenAI implica el uso de algoritmos ML para generar descripciones textuales de imágenes. El proceso, también conocido como subtítulos de imágenes , se encuentra en la intersección de la visión por computadora y el procesamiento del lenguaje natural (PLN). Tiene aplicaciones en áreas de datos multimodales, como el comercio electrónico, donde los datos contienen metadatos en forma de texto e imágenes, o en la atención médica, donde los datos pueden contener resonancias magnéticas o tomografías computarizadas, así como notas y diagnósticos médicos, para nombrar algunos ejemplos.
Los modelos GenAI aprenden a reconocer objetos y características en imágenes y luego generan descripciones de esos objetos y características en lenguaje natural. Los modelos de última generación utilizan una arquitectura codificador-decodificador, donde la información de la imagen se codifica en capas intermedias de una red neuronal y se decodifica en una descripción textual. Estos pueden verse como dos etapas distintas: extraer características de las imágenes y generar leyendas de texto. En la etapa de extracción de características (codificador), el modelo GenAI procesa imágenes para extraer características visuales relevantes, como la forma, el color y la textura del objeto. En la etapa de generación de subtítulos (decodificador), el modelo genera una descripción en lenguaje natural de la imagen basada en las características visuales extraídas.
Los modelos GenAI generalmente se entrenan con grandes cantidades de datos, lo que los hace adecuados para diversas tareas sin capacitación adicional. También se puede adaptar fácilmente a conjuntos de datos personalizados y nuevos dominios con una pequeña cantidad de aprendizaje. El método de preentrenamiento permite utilizar fácilmente modelos de imágenes y lenguaje de última generación para entrenar aplicaciones multimodales. Estos métodos de entrenamiento previo también le permiten elegir los mejores modelos de visión y lenguaje según sus datos como modelos de subtítulos de imágenes.
La calidad de las descripciones de las imágenes generadas depende de la calidad y cantidad de los datos de entrenamiento, la arquitectura del modelo GenAI y la calidad de los algoritmos de extracción de características y subtítulos. Aunque la descripción de imágenes utilizando GenAI es un área de investigación activa, ha mostrado muy buenos resultados en una amplia gama de aplicaciones, como la búsqueda de imágenes, la narración visual y la accesibilidad para personas con discapacidad visual.
Ejemplo
Los subtítulos de imágenes GenAI son útiles en los siguientes casos de uso:
-
Comercio electrónico : un caso de uso común en la industria donde coexisten imágenes y texto es el comercio minorista. Especialmente el comercio electrónico almacena una gran cantidad de datos, como imágenes de productos y descripciones de texto. Las descripciones de texto o metadatos son muy importantes para mostrar los mejores productos según las consultas de búsqueda. Además, con la tendencia de los sitios web de comercio electrónico a obtener datos de proveedores externos, las descripciones de los productos suelen estar incompletas, lo que requiere muchas horas de trabajo y enormes gastos generales debido al etiquetado de la información correcta en las columnas de metadatos. Los subtítulos de imágenes basados en GenAI son ideales para automatizar este tedioso proceso. Ajustar el modelo a partir de datos de moda personalizados, como imágenes de moda y texto que describe los atributos de los productos de moda, puede generar metadatos para mejorar la experiencia de búsqueda de los usuarios.
-
Marketing : otro caso de uso de la búsqueda de imágenes es la gestión de activos digitales. Las empresas de marketing almacenan grandes cantidades de datos digitales que deben centralizarse, ser fáciles de buscar y escalables, lo que requiere un catálogo de datos. Un lago de datos centralizado con un catálogo de datos rico en información reduce la duplicación de esfuerzos y permite un intercambio más amplio de contenido creativo, manteniendo la coherencia entre los equipos. Para las plataformas de diseño gráfico que se utilizan ampliamente para respaldar la generación de contenido de redes sociales o presentaciones en entornos corporativos, una búsqueda más rápida puede mejorar la experiencia del usuario al presentar las imágenes que los usuarios están buscando y permitirles buscar mediante consultas en lenguaje natural.
-
Fabricación : la fabricación almacena grandes cantidades de datos de imágenes, como planos arquitectónicos de componentes, edificios, hardware y equipos. Poder buscar estos datos permite a los equipos de productos recrear fácilmente diseños desde un punto de partida que ya existe, eliminando así una cantidad significativa de gastos generales de diseño y acelerando el proceso de generación de diseños.
-
Atención médica : los médicos y los investigadores médicos pueden organizar y buscar exploraciones por resonancia magnética y tomografía computarizada, muestras de muestras, imágenes de enfermedades como erupciones cutáneas y deformidades, así como notas médicas, diagnósticos y detalles de ensayos clínicos.
-
Metaverso o realidad aumentada : el merchandising publicitario consiste en crear una historia que los usuarios puedan imaginar y con la que identificarse. Con herramientas y análisis impulsados por IA, es más fácil que nunca crear no solo una historia, sino historias personalizadas para atraer los gustos y sensibilidades únicos de cada usuario. Aquí es donde los modelos de imagen a texto pueden convertirse en la regla del juego. La narración visual puede ayudar a crear personajes, ajustarlos a diferentes estilos y agregarles subtítulos. También podría usarse para impulsar experiencias estimulantes en metaversos o realidad aumentada y contenido inmersivo, incluidos videojuegos. Image Search permite a los desarrolladores, diseñadores y equipos buscar su contenido mediante consultas en lenguaje natural, manteniendo la coherencia del contenido en varios equipos.
-
Accesibilidad al contenido digital para personas con discapacidad visual : esto se logra principalmente a través de tecnologías de asistencia como lectores de pantalla, el sistema Braille (para permitir la lectura y escritura táctiles) y teclados especiales (para navegar por sitios web y aplicaciones en Internet). Sin embargo, las imágenes deben entregarse como contenido de texto y luego comunicarse en forma de voz. Los subtítulos de imágenes que utilizan algoritmos GenAI son una parte clave del rediseño de Internet para que sea más inclusivo y brinde a todos la oportunidad de acceder, comprender e interactuar con el contenido en línea.
Detalles del modelo y ajuste del modelo para conjuntos de datos personalizados
En esta solución, aprovechamos el modelo vit-gpt2-image-captioning , disponible en Hugging Face bajo la licencia Apache 2.0, sin realizar más ajustes. Vit es el modelo base para datos de imágenes y GPT-2 es el modelo base para el lenguaje. La combinación multimodal de los dos proporciona la funcionalidad de subtítulos de imágenes. Hugging Face alberga modelos de subtítulos de imágenes de última generación que se pueden implementar en Amazon Cloud Technology con unos pocos clics y proporciona puntos finales de inferencia de implementación fáciles. Aunque podemos usar modelos previamente entrenados directamente, también podemos personalizar los modelos para que se ajusten a conjuntos de datos de dominios específicos, más tipos de datos (como videos o datos espaciales) y casos de uso únicos. Existen varios modelos GenAI, algunos de los cuales funcionan bien en determinados conjuntos de datos, o es posible que su equipo ya esté utilizando modelos de visión y lenguaje. Esta solución brinda la flexibilidad de elegir los modelos de visión y lenguaje con mejor rendimiento como modelos de subtítulos de imágenes reemplazando directamente los modelos que utilizamos.
Para modelos personalizados para aplicaciones industriales únicas, el modelo de código abierto Hugging Face en Amazon Cloud Technology ofrece varias posibilidades. Un modelo previamente entrenado se puede probar en un conjunto de datos específico o entrenarse en una muestra de datos etiquetados para ajustarlo. Los nuevos métodos de investigación también permiten combinar de manera eficiente cualquier modelo de visión y lenguaje y entrenarlo en su conjunto de datos. Este modelo recién entrenado se puede implementar en SageMaker para subtítulos de imágenes como se describe en este documento.
Un ejemplo de búsqueda de imágenes personalizada es la planificación de recursos empresariales (ERP). En ERP, los datos de imágenes recopilados de diferentes etapas de la logística o la gestión de la cadena de suministro pueden incluir recibos de impuestos, pedidos de proveedores, nóminas, etc., que deben clasificarse automáticamente para su revisión por parte de diferentes equipos dentro de la organización. Otro ejemplo es el uso de exploraciones médicas y diagnósticos médicos para predecir nuevas imágenes médicas para su clasificación automática. Los modelos de visión extraen características de imágenes de resonancia magnética, tomografía computarizada o rayos X, y los modelos de texto las subtitulan con diagnósticos médicos.
Descripción general de la solución
El siguiente diagrama muestra la arquitectura de búsqueda de imágenes con GenAI y Amazon Kendra.
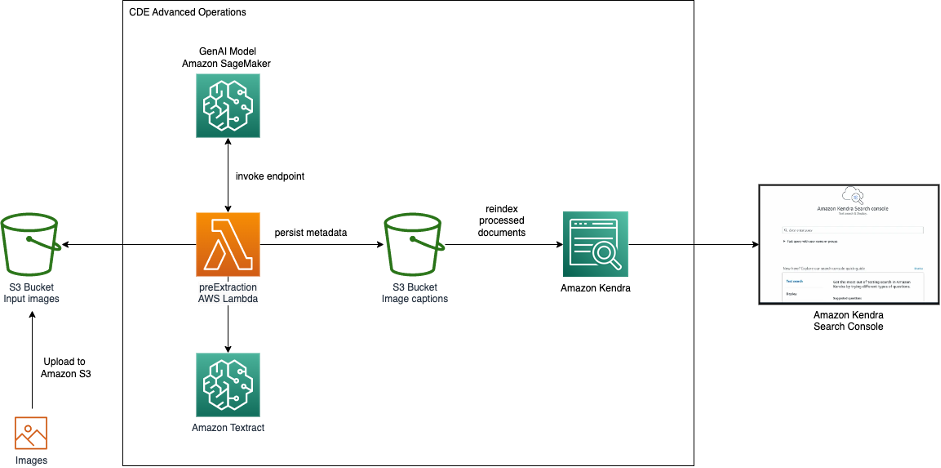
Ingerimos imágenes de Amazon Simple Storage Service (Amazon S3) en Amazon Kendra. Durante la ingesta en Amazon Kendra, se invoca un modelo GenAI alojado en SageMaker para generar descripciones de imágenes. Además, el texto visible en la imagen es extraído por Amazon Textract . Las descripciones de las imágenes y el texto extraído se almacenan como metadatos y están disponibles para la indexación de búsqueda de Amazon Kendra. Una vez ingeridas, las imágenes se pueden buscar a través de Amazon Kendra Search Console, API o SDK .
Usamos las operaciones de alto nivel de CDE en Amazon Kendra para invocar el modelo GenAI y Amazon Textract durante el paso de ingesta de imágenes. Sin embargo, podemos utilizar CDE en una gama más amplia de casos de uso. Con CDE, puede crear, modificar o eliminar atributos y contenido de documentos cuando los documentos se incorporan a Amazon Kendra. Esto significa que puede manipular e ingerir datos según sea necesario. Esto se puede lograr invocando funciones de Amazon Lambda previas y posteriores a la ingesta durante la ingesta , lo que permite el enriquecimiento o la modificación de los datos. Por ejemplo, al incorporar datos de textos médicos, podemos utilizar Amazon Medical Comprehend para agregar información generada por aprendizaje automático a los metadatos de búsqueda.
Puede utilizar nuestra solución para buscar imágenes a través de Amazon Kendra siguiendo estos pasos:
-
Cargue la imagen en un repositorio de imágenes, como un depósito de S3.
-
Luego, Amazon Kendra indexa el repositorio de imágenes, un motor de búsqueda que se puede utilizar para buscar datos estructurados y no estructurados. Durante el proceso de indexación, se invocará el modelo GenAI y Amazon Textract para generar metadatos de imágenes. Puede activar la indexación manualmente o según un cronograma predefinido.
-
Luego puede buscar imágenes a través de la consola, el SDK o la API de Amazon Kendra mediante consultas en lenguaje natural, como "buscar imágenes de rosas rojas" o "mostrar imágenes de perros jugando en el parque". Estas consultas son procesadas por Amazon Kendra, que utiliza algoritmos de aprendizaje automático para comprender el significado detrás de la consulta y recuperar imágenes relevantes del repositorio indexado.
-
Los resultados de la búsqueda se le presentan junto con las descripciones de texto correspondientes, lo que le permite encontrar la imagen deseada de forma rápida y sencilla.
requisito previo
Debes tener los siguientes requisitos previos:
-
Permiso para aprovisionar e invocar los siguientes servicios a través de Amazon CloudFormation : Amazon S3, Amazon Kendra, Lambda y Amazon Textract.
Costo estimado
El costo estimado de implementar esta solución como prueba de concepto se muestra en la siguiente tabla. Es por eso que utilizamos Amazon Kendra Developer Edition, que no se recomienda para cargas de trabajo de producción pero ofrece una opción de bajo costo para los desarrolladores. Suponemos que la funcionalidad de búsqueda de Amazon Kendra se utiliza 3 horas por día durante 20 días hábiles, calculando así el costo asociado con 60 meses de horas activas.
| Atender | el consumo de tiempo | Costo mensual estimado |
| amazon s3 | Almacene 10 GB de datos, incluida la transferencia de datos | $2.30 |
| amazona kendra | Developer Edition, 60 horas de uso al mes | $67.90 |
| Extracto de texto de Amazon | 100% de detección de texto de documentos en 10,000 imágenes | $15.00 |
| Amazon SageMaker | Implemente inferencia en tiempo real en un punto final por modelo, usando ml.g4dn.xlarge, 3 horas por día durante 20 días. | $44.00 |
| . | . | $129.2 |
Implemente recursos mediante Amazon CloudFormation
La pila de CloudFormation implementa los siguientes recursos:
- Descargue la función Lambda del modelo de título de imagen desde Hugging Face Center y luego cree el recurso del modelo
- Una función Lambda que completa el código de inferencia y los artefactos del modelo comprimido en el depósito S3 de destino.
- Depósito S3 para almacenar artefactos de modelo comprimido y código de inferencia
- Bucket S3 para almacenar imágenes cargadas y documentos de Amazon Kendra
- Índice de Amazon Kendra para títulos de imágenes generadas por búsquedas
- Punto final de inferencia en tiempo real de SageMaker para implementar modelos de subtítulos de imágenes desde Hugging Face
- Función Lambda que se activa cuando el índice de Amazon Kendra se enriquece bajo demanda. Llama a los puntos finales de inferencia en tiempo real de Amazon Textract y SageMaker.
Además, Amazon CloudFormation implementa todos los roles y políticas de Amazon Identity and Access Management (IAM), VPC y subredes, grupos de seguridad y puertas de enlace de Internet necesarios para ejecutar las funciones Lambda de recursos personalizados.
Complete los siguientes pasos para aprovisionar recursos:
- Haga clic en Iniciar pila para iniciar la plantilla de CloudFormation en
us-east-1la zona:
2. Haga clic en Siguiente .
3. En la página Especificar detalles de la pila , deje la URL de plantilla y la URI de S3 del archivo de parámetros como valores predeterminados y haga clic en Siguiente .
4. Continúe haciendo clic en Siguiente en las páginas siguientes .
5. Haga clic en Crear pila para implementar la pila.
Monitorear el estado de la pila. Cuando el estado muestra CREATE_COMPLETE , la implementación está completa.
Ingerir y buscar imágenes de ejemplo
Complete los siguientes pasos para ingerir y buscar imágenes:
-
En la consola de Amazon S3, cree una carpeta con el nombre del depósito S3
us-east-1de la región .kendra-image-search-stack-imagecaptionsimages -
Sube las siguientes imágenes a
imagesla carpeta.




3. Navegue hasta us-east-1la consola de Amazon Kendra de la región.
4. En el panel de navegación, elija Índices y luego elija su índice ( kendra-index).
5. Elija una fuente de datos y luego elija generated_image_captions.
6. Seleccione Sincronizar ahora .
Espere a que se complete la sincronización antes de continuar con el siguiente paso.
7. En el panel de navegación, elija Indexación y luego elija kendra-index.
8. Navegue hasta Search Console.
9. Pruebe las siguientes consultas, solas o en combinación: "perro", "paraguas" y "boletín" para ver qué imágenes ocupan un lugar destacado Amazon Kendra.
No dude en probar sus propias consultas adecuadas para cargar imágenes.
limpiar
Para dar de baja todos los recursos, complete los siguientes pasos:
-
En la consola de Amazon CloudFormation, elija Pilas en el panel de navegación .
-
Seleccione la pila
kendra-genai-image-searchy elija Eliminar .
Espere a que el estado de la pila cambie a DELETE_COMPLETE .
en conclusión
En este artículo, vimos cómo Amazon Kendra y GenAI se combinaron para crear automáticamente metadatos significativos para imágenes. El modelo GenAI de última generación es muy adecuado para generar leyendas de texto basadas en el contenido de la imagen. Esto tiene una amplia gama de casos de uso en industrias como la atención médica y las ciencias biológicas, el comercio minorista y el comercio electrónico, las plataformas de activos digitales y los medios. Los subtítulos de imágenes también son fundamentales para construir un mundo digital más inclusivo y rediseñar Internet, el metaverso y las tecnologías inmersivas para satisfacer las necesidades de las personas con discapacidad visual.
La búsqueda de imágenes con subtítulos hace que el contenido digital para estas aplicaciones se pueda buscar fácilmente sin esfuerzo manual y elimina la duplicación de esfuerzos. Las plantillas de CloudFormation que proporcionamos hacen que la implementación de esta solución sea sencilla e intuitiva para permitir la búsqueda de imágenes a través de Amazon Kendra. La arquitectura simple de almacenar imágenes en Amazon S3 y usar GenAI para crear descripciones textuales de las imágenes se puede usar con CDE en Amazon Kendra para brindar esta solución.
Esta es sólo una aplicación de GenAI y Amazon Kendra. Para obtener una visión detallada de la creación de aplicaciones utilizando GenAI con Amazon Kendra, consulte Creación rápida de aplicaciones de datos empresariales de IA generativa de alta precisión utilizando Amazon Kendra, LangChain y modelos de lenguaje a gran escala . Para crear y escalar aplicaciones GenAI, recomendamos consultar Amazon Bedrock .
Fuente del artículo: https://dev.amazoncloud.cn/column/article/64e5e3785cf856038494b8cf?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN