1. Introducción
En el artículo anterior, presentamos los procesadores de la serie Cortex-X1 a Cortex-X3 de Arm A fines de mayo de 2023, Arm lanzó la arquitectura de procesador del nuevo año según lo programado, que son Cortex-X4 de núcleo súper grande y A720 de núcleo grande y núcleo pequeño A520. En la industria de los teléfonos inteligentes, Arm siempre ha mantenido un ritmo de actualización de arquitectura de procesador iterativo cada año, para que los usuarios puedan continuar experimentando el diseño de producto más avanzado. Este artículo presenta principalmente los cambios en la nueva arquitectura del procesador en 2023, se centra en el análisis del núcleo Cortex-X4 que ha cambiado mucho y analiza los cambios que merecen atención en la arquitectura del procesador central este año.
2. Introducción general
De los datos promocionales de Arm, se puede ver que las tres arquitecturas de procesador de este año tienen diferentes enfoques. El Cortex-X4 se enfoca en la mejora del rendimiento, que es un 15% superior a la generación anterior Cortex-X3. El A720 y A520 se enfocan en mejorar. Eficiencia energética En comparación con la generación anterior A715 y A520, la eficiencia energética se mejora en un 20 % y un 22 % respectivamente. Vale la pena señalar que el procesador de este año no tiene un proceso actualizado, y estos datos deben calcularse en función del mismo proceso (por ejemplo, TSMC 4nm).

Además de la nueva arquitectura de procesador, Arm también trajo un nuevo conjunto de instrucciones Armv9.2 este año, incluido el nuevo algoritmo QARMA3 PAC, mayores capacidades de punto flotante y mejoras de PMU. El cambio más crítico es que Arm planea abandonar por completo los 32 bits. aplicaciones este año Soporte, los tres nuevos núcleos no son compatibles con aplicaciones de 32 bits.

Arm también actualizó el módulo DSU120 este año para administrar mejor los datos entre los núcleos del procesador y admitir hasta 14 núcleos y hasta 32 MB de diseño de caché L3. Como se puede ver en la imagen a continuación, el diseño del procesador de este año también ha sufrido cambios significativos. El año pasado, el procesador 8Gen2 de Qualcomm adoptó una arquitectura 1+4+3. Este año veremos menos arquitecturas de núcleo pequeño 1+5+2 ( consulte Link 3, procesador Qualcomm 8Gen3), el rendimiento multinúcleo se ha mejorado considerablemente.
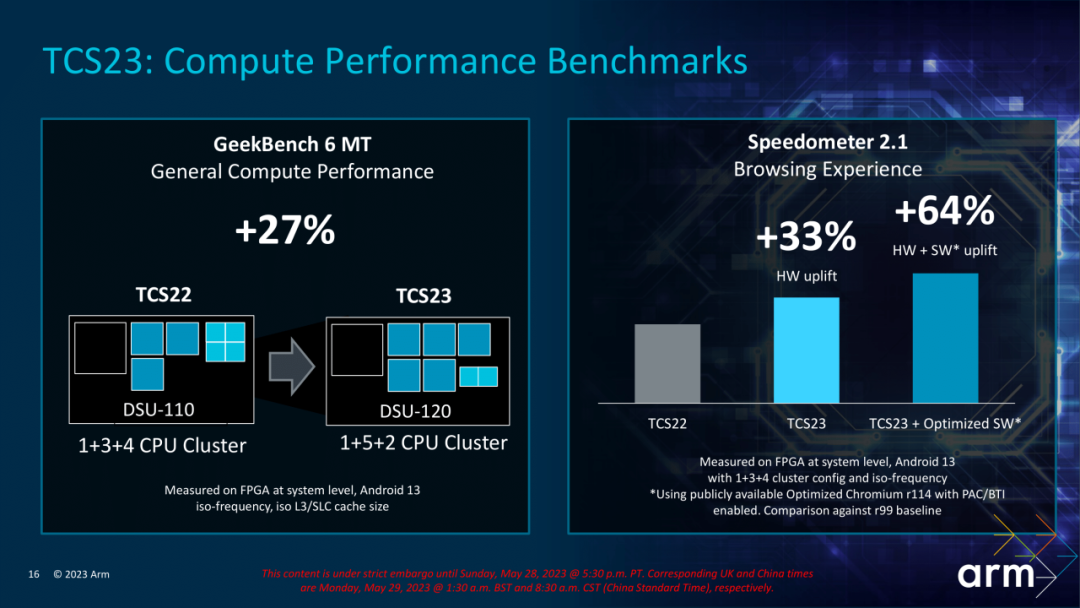
3. Análisis de microarquitectura Cortex-X4
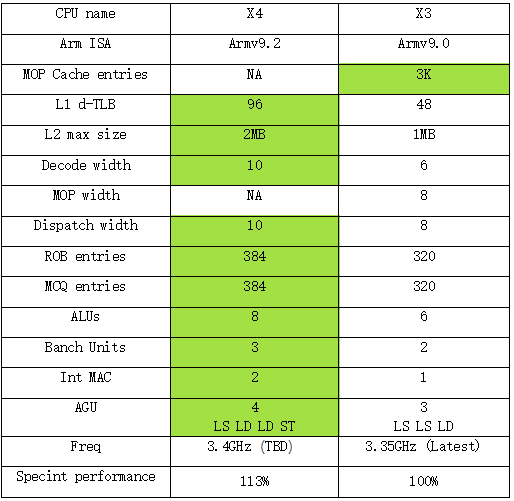
El nombre en clave de Cortex-X4 es Hunter-ELP. La siguiente imagen es el diagrama de microarquitectura de X4. La primera sensación es que se ha vuelto "más grande". El núcleo de X4 es cada vez más grande. Si ha leído lo anterior artículos, debería poder sentir que este diseño de microarquitectura se parece cada vez más a otro procesador líder en la industria. Diferentes rutas conducen al mismo objetivo. A menudo, solo hay una opción para el mejor diseño. A continuación analizaremos el cambios fundamentales este año en detalle.
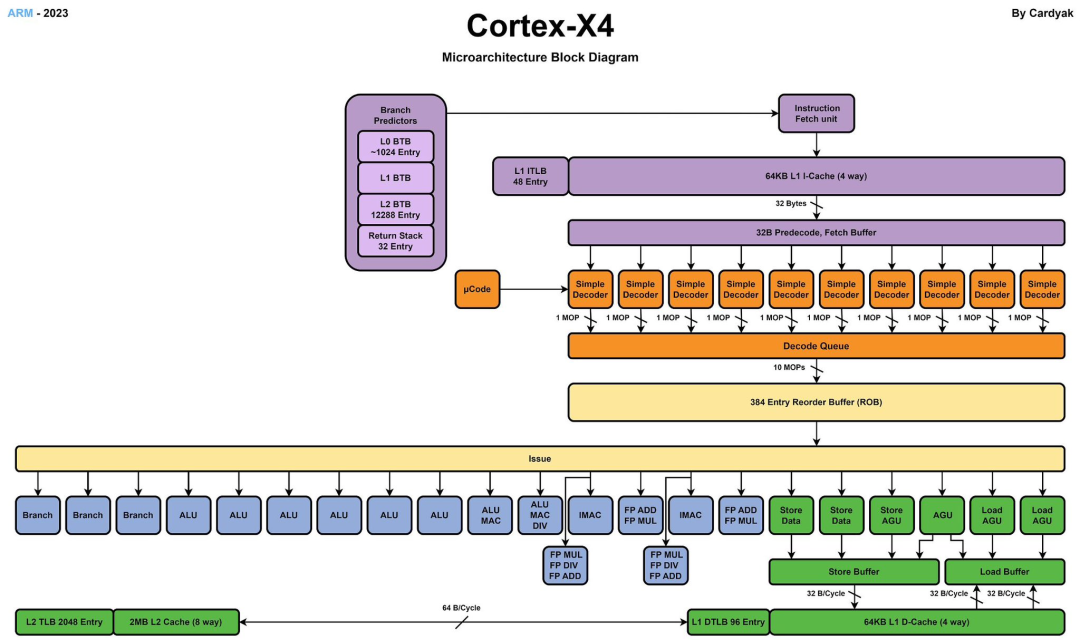
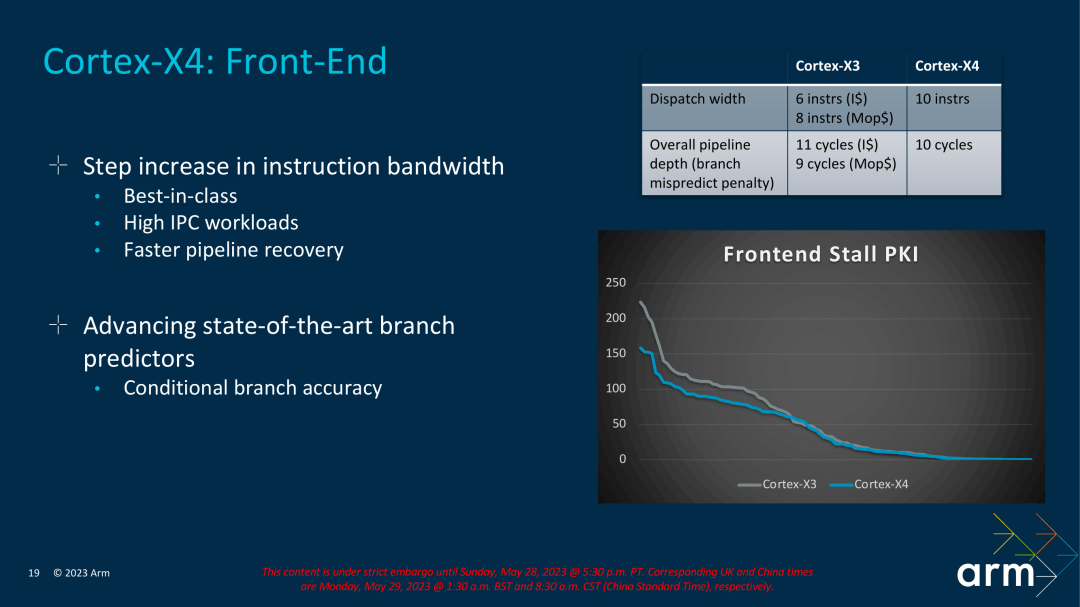
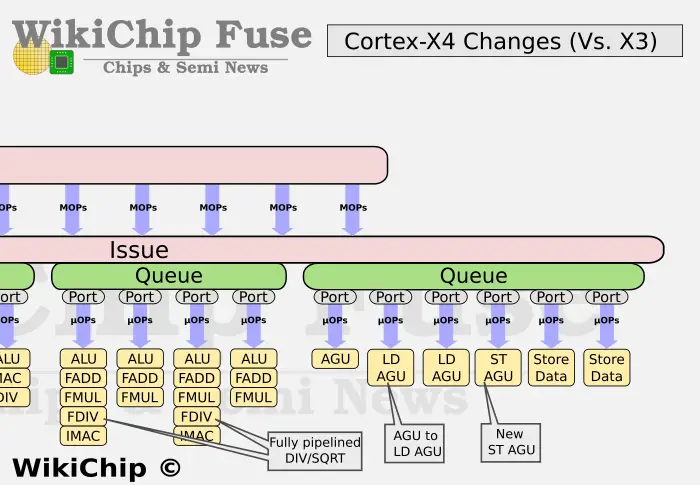
En términos de diseño frontal, X4 cancela la caché MOP de nivel L0. Tenga en cuenta que este cambio comenzó desde el gran núcleo A715. Este es un gran cambio. También muestra que el costo de la caché MOP puede ser muy económico. Para compensar el impacto de cancelar la caché MOP, X4 aumentó la cantidad de decodificadores de 6 a 10 esta vez. En la generación anterior de X3, si los datos obtenidos de MOP Cache tenían un ancho de 8 y los datos obtenidos de L1 tenían un ancho de 6, esta vez el X4 tiene un ancho uniforme de 10. En términos de longitud de canalización, si X3 obtiene datos de L1, se necesitan 11 etapas y si se obtienen datos de MOP, se necesitan 9. Esta vez, debido a la cancelación de MOP, X4 optimizó especialmente la canalización y los datos obtenido de L1 se redujo de 11 etapas a 10 etapas.
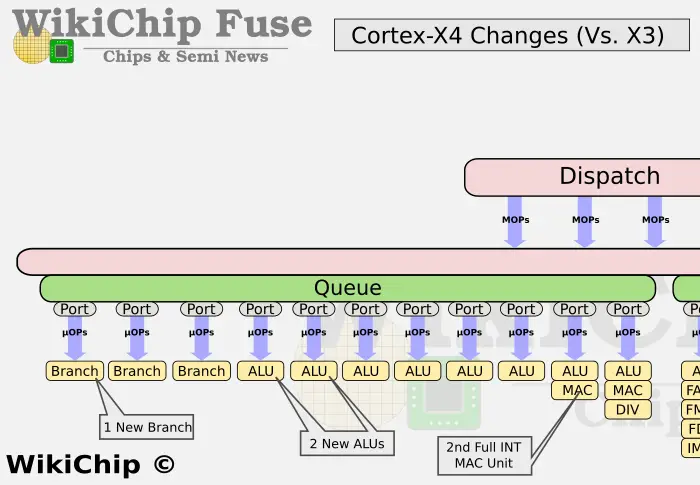
En términos de diseño de back-end, el X4 también ha cambiado mucho esta vez, especialmente la unidad de computación, agregando una nueva unidad Branch, 2 nuevas unidades ALU y proporcionando una segunda unidad MAC ALU completa, que es muy importante para el La mejora del rendimiento general ha sido significativamente útil.
Para admitir los 10 decodificadores y unidades informáticas recientemente agregados, el tamaño del búfer de reordenamiento (ROB) del X4 también se incrementó de 320 a 384, un aumento del 20%.

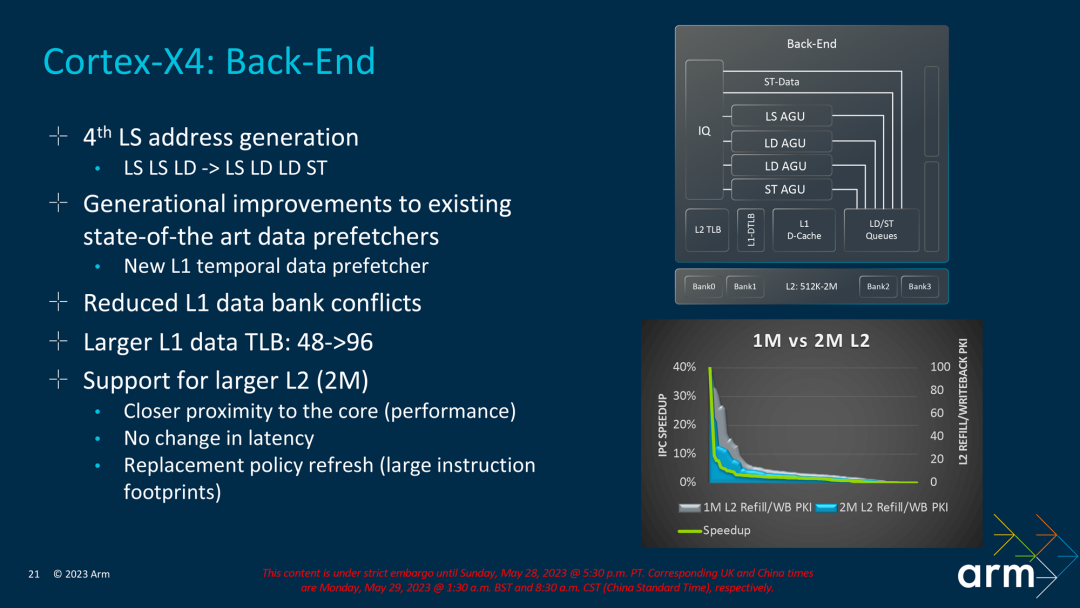
En cuanto a los módulos de almacenamiento, Arm ha reajustado el número de unidades Load and Store, el X3 tiene una AGU LS y una AGU LD, mientras que el X4 se ajusta a una AGU LS, dos AGU LD y una AGU ST. De 3 AGU a 4 AGU, pero las funciones son ligeramente diferentes. Además, el d-TLB de L1 también se incrementó de 48 a 96, lo que mejora la capacidad de procesamiento de datos.
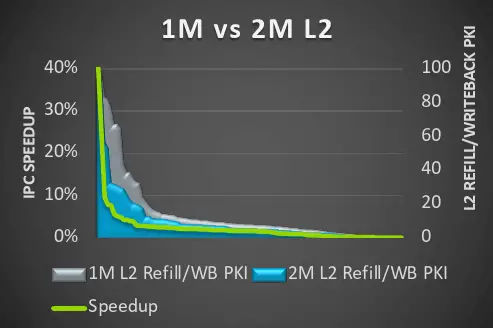
Otra característica del núcleo X4 esta vez es que admite un caché L2 más grande, que se ha actualizado del soporte máximo de X3 a 1 MB al soporte máximo de X4 a 2 MB. Según los datos proporcionados por Arm, el caché L2 de 2 MB puede reducir efectivamente el peso de cada mil instrucciones Tasas de llenado y reescritura, pero no todos los proveedores están dispuestos a aumentar al tamaño máximo de caché porque aumentar el caché aumentará el costo.
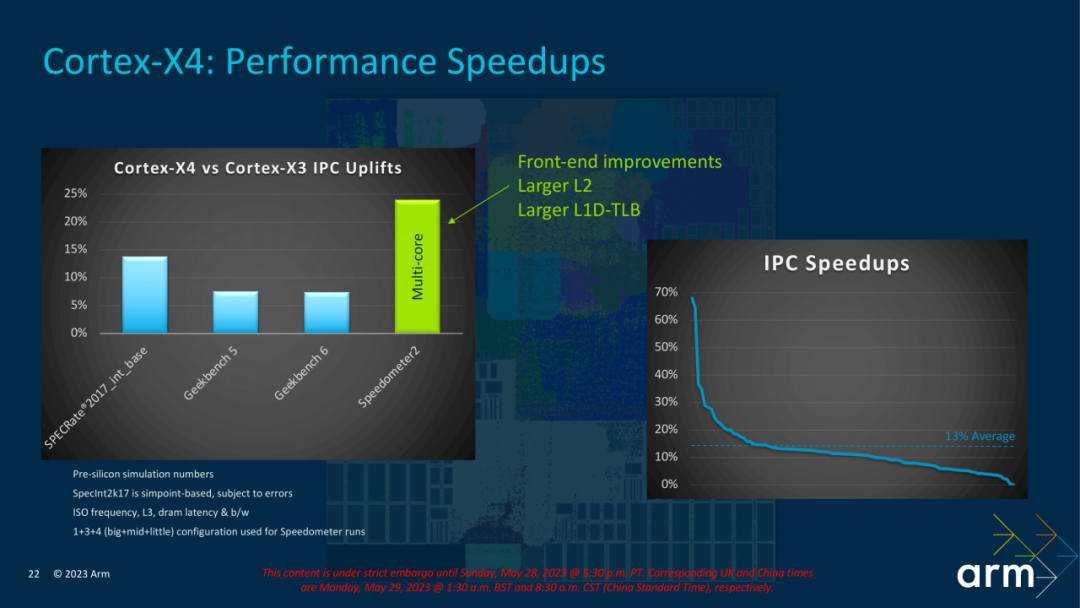
A juzgar por los datos de rendimiento general de X4, Sepcint2K7 ha logrado una mejora de dos dígitos, mientras que la serie Geekbench solo tiene una mejora de un dígito entre 6 y 8 %.Se especula que Geekbench no es muy sensible a L2, pero Sppdometer2, que se basa en la memoria caché L2 La mejora de este punto de referencia es relativamente obvia Tenga en cuenta que los datos de prueba aquí se obtienen utilizando la prueba L2 de 2 MB.
Además, los datos de Arm muestran que la frecuencia típica de la CPU de X4 puede llegar a alrededor de 3,4 G. Aunque no se ha confirmado la frecuencia real del procesador del fabricante, se especula con la generación anterior Dimensity 9200+ funcionando a 3,35 G que 3,4 G debería ser una comparación que se puede lograr con niveles de alta frecuencia de 4nm.
Resuma los cambios clave de Cortex-X4:
1. Caché MOP cancelado;
2. Aumente el número de Decodificadores de 6 a 10;
3. La línea de montaje está unificada en 10 niveles;
4. Las sucursales aumentaron de 2 a 3;
5. El número de unidades ALU se ha incrementado de 6 a 8;
6. Se agregó una unidad AGU y se ajustaron sus funciones;
7. El tamaño de ROB aumentó de 320 a 384;
8. El d-TLB de L1 se incrementa de 48 a 96;
9. El caché L2 máximo admitido se incrementa de 1 MB a 2 MB;
10. No se admite 32 bits.
El rendimiento general de los parámetros de Sepcint2K7 se ha mejorado entre un 13 % y un 14 %.
4. Análisis de microarquitectura A720
En la sección anterior, enumeramos 10 cambios en la microarquitectura del núcleo del X4. En comparación con los grandes movimientos del X4, los cambios del A720 y el A520 no son tan grandes, pero hay algunos que merecen nuestra investigación y discusión.
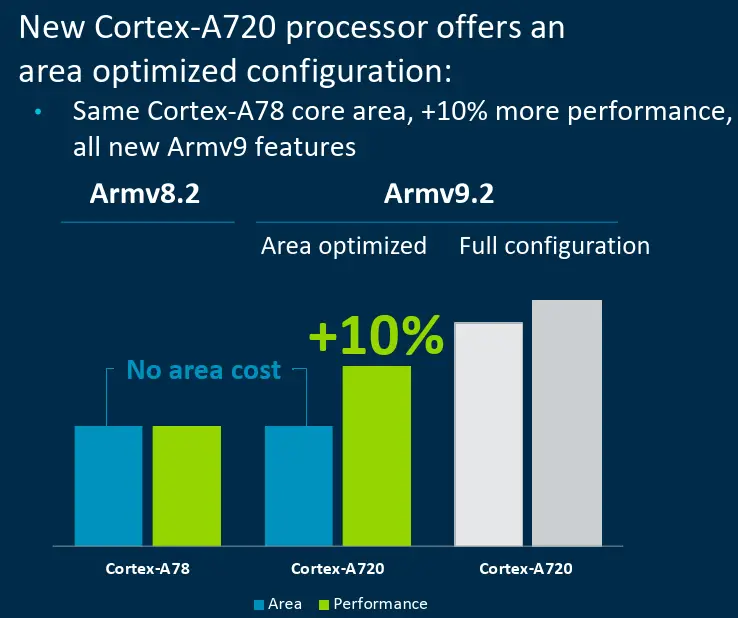
En primer lugar, echemos un vistazo al A720. El nombre en clave del A720 es Hunter. El objetivo del diseño del A720 es mejorar la eficiencia energética en un 20 % en comparación con el A715. Con el mismo consumo de energía, el A720 puede proporcionar una mayor actuación.
La microarquitectura general del A720 no es muy diferente de la del A715. Arm no aumentó el ancho de búsqueda y decodificación, ni aumentó la optimización, como el tamaño de ROB, pero profundizó en los detalles de la microarquitectura para optimizar la eficiencia energética.

En términos de diseño frontal, A720 continúa optimizando la capacidad de predicción de rama, que en términos sencillos es la capacidad de dar un paso y ver dos pasos. El ciclo de recuperación de la predicción errónea de bifurcación del A720 se reduce de ciclos 12 a 11. Esta optimización es muy útil para casos que no se pueden predecir con precisión en escenarios de usuarios reales. En términos de capacidades de predicción de bifurcaciones, el gran núcleo del A710 puede predecir dos bifurcaciones incondicionales por ciclo, el A715 también admite bifurcaciones condicionales y el A720 optimiza aún más el consumo de energía. Arm afirma que puede reducir el consumo de energía sin afectar el rendimiento.

En el diseño de back-end, el A720 mejora la eficiencia energética de la ejecución de instrucciones a través de la clasificación canalizada de unidades FDIV\FSQRT (división y raíz cuadrada). Al mismo tiempo, el A720 optimiza la eficiencia de transmisión de datos en unidades enteras y de punto flotante, reduciendo el retraso de la transmisión de datos y el retraso del almacenamiento de datos. El A720 también mejora la cola de lanzamiento y la unidad de ejecución, y simplifica la transmisión de datos desde el punto de red hasta la AGU.

Una optimización obvia en el módulo de almacenamiento del A720 es reducir el retraso del acceso a L2 de 10 ciclos a 9 ciclos, lo que será más útil para escenarios con mucho acceso a la memoria. Además, la cantidad máxima de caché L2 admitida por el A720 sigue siendo de 512 KB.

Finalmente, presentaré el mayor cambio del A720 este año. Este año, el A720 de Arm no es una sola persona, sino un par de gemelos. Arm proporciona otro núcleo A720min (temporalmente llamado así). Este núcleo es diferente del A720, y el área se ha reducido hasta cierto punto. El área general del núcleo es similar a la del A78, y su rendimiento también es más débil que el A720, pero es aproximadamente un 10% más fuerte que el A720. A78. En resumen, el área de A720min está cerca de la de A78 (el consumo de energía también debería estar cerca), y su rendimiento es un 10% más fuerte que el de A78, que pertenece a una rama de A720.
Finalmente, resuma brevemente los cambios clave del A720:
1. El ciclo de recuperación de la predicción errónea de sucursales se reduce de 12 ciclos a 11 ciclos;
2. La latencia de acceso L2 se reduce de 10 ciclos a 9 ciclos;
3. Proporcione una opción de A720min, el área está cerca de A78 y el rendimiento es un 10% más fuerte que A78.
5. Análisis de microarquitectura A520
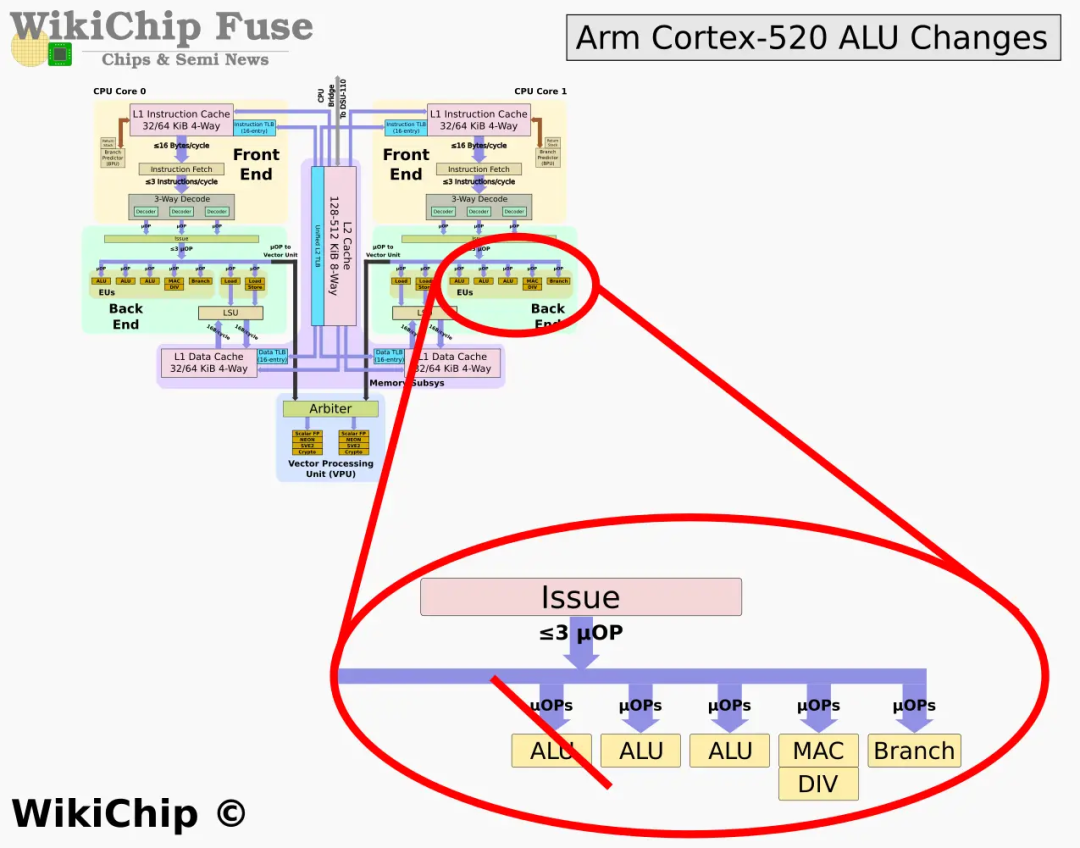
Echemos un vistazo al A520 de núcleo pequeño. El nombre en clave del A520 de núcleo pequeño es Hayes. Todavía no es compatible con la ejecución fuera de orden. El diseño es relativamente simple y se centra en mejorar la eficiencia energética. El A520 todavía hereda el diseño de los dos pequeños núcleos del A510 empalmados para compartir la unidad SIMD. Esta vez, el A520 solo admite 64 bits y ya no admite 32 bits. El A520 proporciona un nuevo algoritmo QARMA3 PAC diseñado para reducir el impacto de PAC en un 1 %.

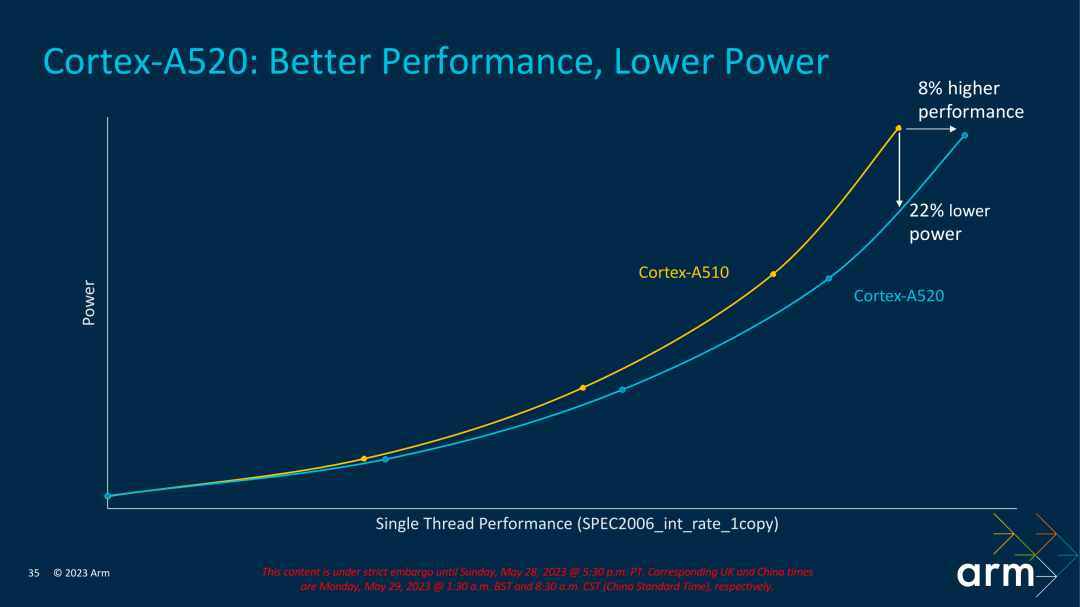
Comparado con el A510, el A520 también ha realizado una sustracción con el fin de mejorar la eficiencia energética, siendo el principal cambio la reducción de la ALU de una unidad de ejecución. El A510 tiene 3 ALU, el A520 solo tiene 2. Por supuesto, Arm dijo que a través de la optimización global, la pérdida de rendimiento se puede compensar. Según los datos proporcionados por Arm, el consumo de energía del A520 se puede reducir en un 22 % con el mismo rendimiento; con el mismo consumo de energía, el rendimiento puede mejorarse en aproximadamente un 8 %, también lo probaremos.
Desafortunadamente, la mejora del rendimiento del 8% todavía tiene una cierta brecha en comparación con la demanda de procesadores insignia. Hemos visto que en el diseño del procesador insignia de este año, los fabricantes de chips continúan reduciendo el uso de núcleos pequeños A520, y algunos fabricantes incluso no usan A520 núcleos pequeños en absoluto.
6. Análisis de DSU120
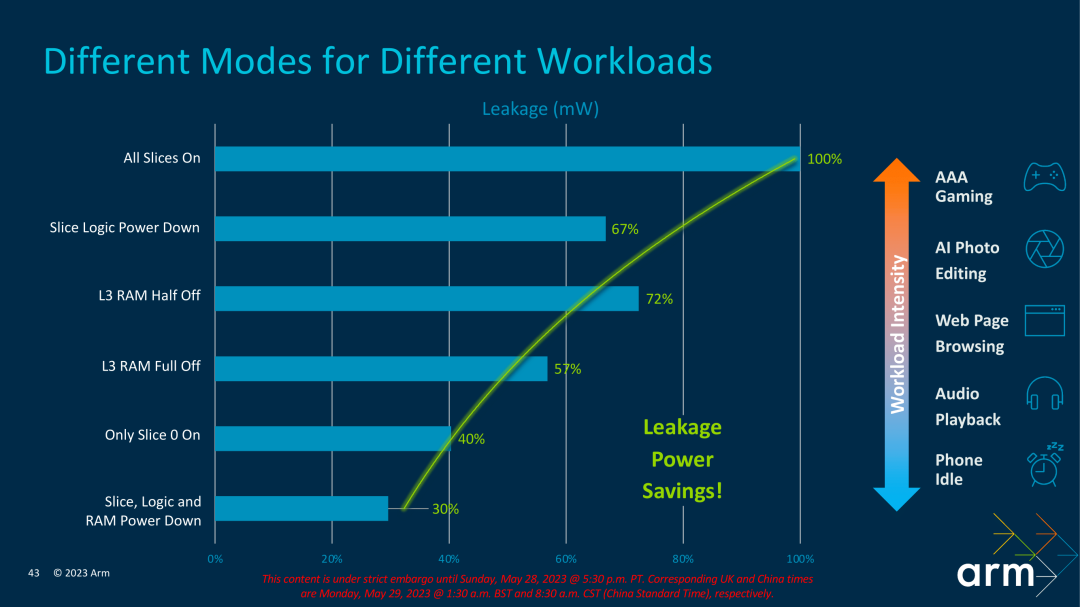
Finalmente, echemos un vistazo al módulo DSU utilizado para coordinar los núcleos del procesador y las cachés. Arm ha actualizado el último módulo DSU120, que puede admitir hasta 14 núcleos en un clúster y admitir hasta 32 MB de administración de caché L3.
DSU120 proporciona una función valiosa A medida que la memoria caché L3 se vuelve más y más grande, la fuga estática se convierte en un factor influyente que debe tenerse en cuenta, lo que afectará el escenario de consumo de energía en espera del teléfono móvil. El DSU120 proporciona una función de apagado parcial de L3. En algunos escenarios que no necesitan usar una memoria caché tan grande, apagar parte de la memoria caché L3 puede reducir la fuga estática.
7. Resumen
Este artículo analiza principalmente las últimas arquitecturas de procesadores, como Cortex-X4, A720 y A520, lanzadas por Arm en 2023. Este año es el procesador de cuarta generación de la serie X lanzado por Arm. A través del análisis anterior, podemos ver que Arm está mejorando continuamente el rendimiento informático de sus procesadores centrales, desafiando el diseño de arquitectura más avanzado de la industria. Al mismo tiempo, Arm también brinda a los usuarios una cartera de productos más competitiva en términos de eficiencia energética de chips al optimizar la eficiencia energética de A720 y A520.
En 2023, los fabricantes de chips no están satisfechos con la configuración de núcleo tradicional y comenzaron a reducir la cantidad de núcleos pequeños y aumentar la actualización de la arquitectura de los núcleos grandes. Podemos ver más diseños de SOC multinúcleo este año, con más mejoras en el rendimiento multinúcleo. Sin duda, la competencia de procesadores en 2023 será más intensa. La introducción de múltiples núcleos también requiere estar atento al riesgo de un mayor consumo de energía y generación de calor. Como desarrollador de chips y terminales de dispositivos inteligentes, es necesario comprender completamente la arquitectura del procesador. y use programación razonable de software y hardware.Diseñe, optimice la eficiencia energética del chip al mejor y brinde a los usuarios el mejor rendimiento sostenible.
Revisión de artículos anteriores:
1. De A76 a A78: aprendizaje de microarquitectura ARM en cambios
2. Serie de aprendizaje de microarquitectura Arm 2: apertura de la era Armv9
3. Serie de análisis de microarquitectura del brazo 3 - Plan X del brazo
Link de referencia:
1, https://www.anandtech.com/show/18871/arm-presenta-armv92-mobile-architecture-cortex-x4-a720-and-a520-64bit-exclusive
2, A720 https://fuse.wikichip.org/news/7531/arm-presentes-the-cortex-x4-its-newest-flagship-performance-core/
3, 8Gen3 https://www.xda-developers.com/qualcomm-snapdragon-8-gen-3/
4, Corteza-X4 https://twitter.com/Cardyak/status/1664753062487941120
5, A720 https://fuse.wikichip.org/news/7529/arm-presentes-a-new-big-core-the-cortex-a720/
6, A520 https://fuse.wikichip.org/news/7527/arm-launches-next-gen-efficiency-core-cortex-a520/
Pasado
Esperar
empujar
recomendar
Arquitectura multiproceso de Chromium, ¿cuánto sabes?
Sobre la importancia de un buen nombre: el cambio de página del kernel de Linux a folio

Mantenga presionado para seguir Kernel Craftsman WeChat
Tecnología Linux Kernel Black | Artículos técnicos | Tutoriales destacados