Prefacio
La pérdida de memoria es un problema que encontramos a menudo al depurar programas, y hay muchos programas de análisis de pérdida de memoria Este artículo analiza principalmente el uso de las herramientas Valgrind.
Introducción e instalación de Valgrind
Descarga desde el sitio web oficial de Valgrind: http://valgrind.org/downloads/current.html#current
La última versión es valgrind 3.15.0, y la descarga en el sitio web oficial es muy lenta. La herramienta se puede instalar directamente desde la fuente de espejo. como sigue:
sudo apt install valgrind
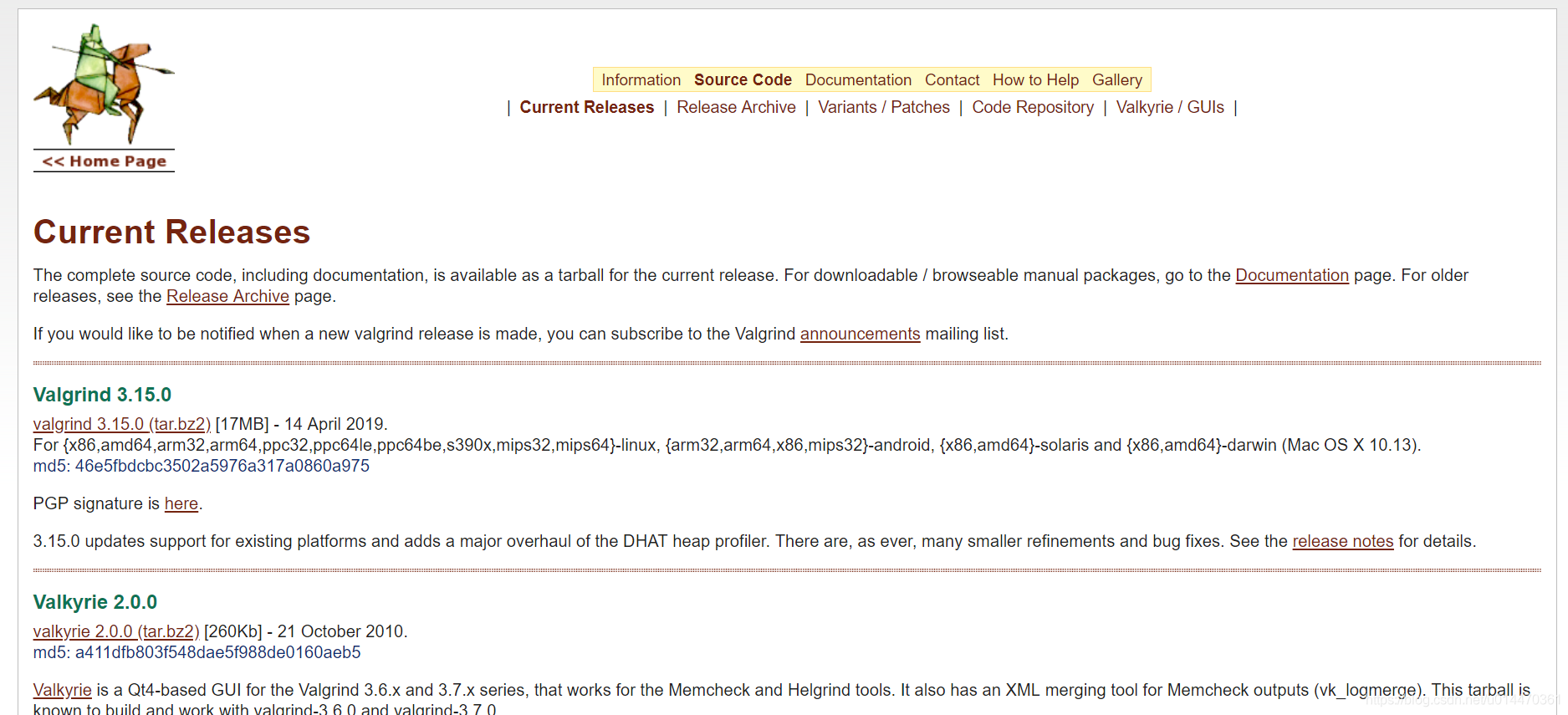
Use el comando valgrind para verificar si la instalación es exitosa.
valgrind ls -l
Uso de Valgrind
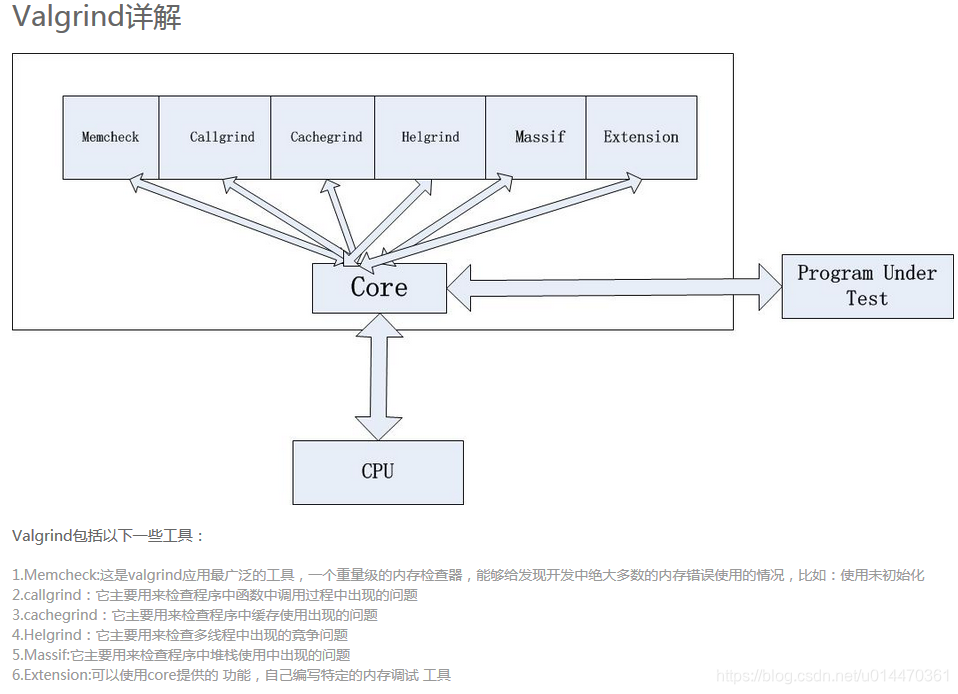
El kit de herramientas de Valgrind contiene varias herramientas, como Memcheck, Cachegrind, Helgrind, Callgrind, Massif.
Memcheck
La herramienta más comúnmente utilizada se utiliza para detectar problemas de memoria en el programa. Se detectarán todas las lecturas y escrituras en la memoria y se capturarán todas las llamadas a malloc () / free () / new / delete. Por tanto, la herramienta Memcheck comprueba principalmente los siguientes errores del programa.
(1) Uso de memoria no inicializada
(2) Uso de memoria liberada Lectura / escritura de memoria después de haber sido liberada
(3) Uso de más espacio de memoria asignado por malloc Lectura / escritura del final de malloc 'd blocks
(4) Acceso ilegal a la pila Lectura / escritura de áreas inapropiadas en la pila
(5) Si se libera el espacio solicitado Fugas de memoria - donde los punteros a bloques mal ubicados se pierden para siempre
(6) malloc / free / new / Uso incorrecto de malloc / new / new [] vs free / delete / delete []
(7) Superposición de punteros src y dst en memcpy () y funciones relacionadas.
Estos problemas suelen ser C / El problema más problemático de los programadores de C ++, Memcheck está aquí para ayudar.
Callgrind
Una herramienta de análisis similar a gprof, pero su observación del funcionamiento del programa es más sutil y puede aportarnos más información. A diferencia de gprof, no requiere opciones especiales adicionales al compilar el código fuente, pero se recomienda agregar opciones de depuración. Callgrind recopila algunos datos cuando el programa se está ejecutando, crea un gráfico de relación de llamadas de función y, opcionalmente, realiza una simulación de caché. Al final de la ejecución, escribirá los datos del análisis en un archivo. callgrind_annotate puede convertir el contenido de este archivo en un formato legible.
Cachegrind
El Analizador de caché, que simula la caché de primer nivel I1, Dl y la caché de segundo nivel en la CPU, puede señalar con precisión las fallas y aciertos de caché en el programa. Si es necesario, también puede proporcionarnos el número de fallos de caché, el número de referencias de memoria y el número de instrucciones generadas por cada línea de código, cada función, cada módulo y el programa completo. Esta es una gran ayuda para optimizar el programa.
Helgrind
Se utiliza principalmente para comprobar problemas de competencia en programas multiproceso. Helgrind busca áreas en la memoria a las que acceden varios subprocesos y que no están bloqueadas de manera constante. Estas áreas suelen ser lugares donde los subprocesos pierden sincronización y pueden dar lugar a errores que son difíciles de descubrir. Helgrind implementó un algoritmo de detección de competencia llamado "Eraser" e hizo más mejoras para reducir el número de errores reportados. Sin embargo, Helgrind todavía se encuentra en la etapa experimental.
Macizo
Analizador de pila, puede medir cuánta memoria usa el programa en la pila, decirnos el bloque de pila, el bloque de gestión de pila y el tamaño de pila. Massif puede ayudarnos a reducir el uso de memoria. En los sistemas modernos con memoria virtual, también puede acelerar la ejecución de nuestros programas y reducir la posibilidad de que los programas permanezcan en el área de intercambio.
Uso: valgrind [opciones] prog-and-args
[opciones]: opciones comunes, aplicables a todas las herramientas de Valgrind
-tool=<name> 最常用的选项。运行 valgrind中名为toolname的工具。默认memcheck。
memcheck ------> 这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。
callgrind ------> 它主要用来检查程序中函数调用过程中出现的问题。
cachegrind ------> 它主要用来检查程序中缓存使用出现的问题。
helgrind ------> 它主要用来检查多线程程序中出现的竞争问题。
massif ------> 它主要用来检查程序中堆栈使用中出现的问题。
extension ------> 可以利用core提供的功能,自己编写特定的内存调试工具
-h –help 显示帮助信息。
-version 显示valgrind内核的版本,每个工具都有各自的版本。
-q –quiet 安静地运行,只打印错误信息。
-v –verbose 更详细的信息, 增加错误数统计。
-trace-children=no|yes 跟踪子线程? [no]
-track-fds=no|yes 跟踪打开的文件描述?[no]
-time-stamp=no|yes 增加时间戳到LOG信息? [no]
-log-fd=<number> 输出LOG到描述符文件 [2=stderr]
-log-file=<file> 将输出的信息写入到filename.PID的文件里,PID是运行程序的进行ID
-log-file-exactly=<file> 输出LOG信息到 file
-log-file-qualifier=<VAR> 取得环境变量的值来做为输出信息的文件名。 [none]
-log-socket=ipaddr:port 输出LOG到socket ,ipaddr:port
Prueba de ejemplo
Escribe un ejemplo:
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
void test()
{
int *ptr = malloc( sizeof(int)* 10);
ptr[10] =100;// 内存越界
memcpy(ptr+1,ptr,5); 踩内存,内存的源地址和目的地址重叠
free(ptr);
free(ptr);// 重复释放
int *p1;
*p1 =10;// 非法指针
}
int main(int argc,char** argv)
{
test();
return 0;
}
gcc -g -o test -fno-inline test.c
-G -fno-inline es una opción de compilación para retener información de depuración; de lo contrario, el siguiente valgrind no puede mostrar el número de línea de error y ejecutarse directamente.
Ejecute directamente. / Indicador de prueba
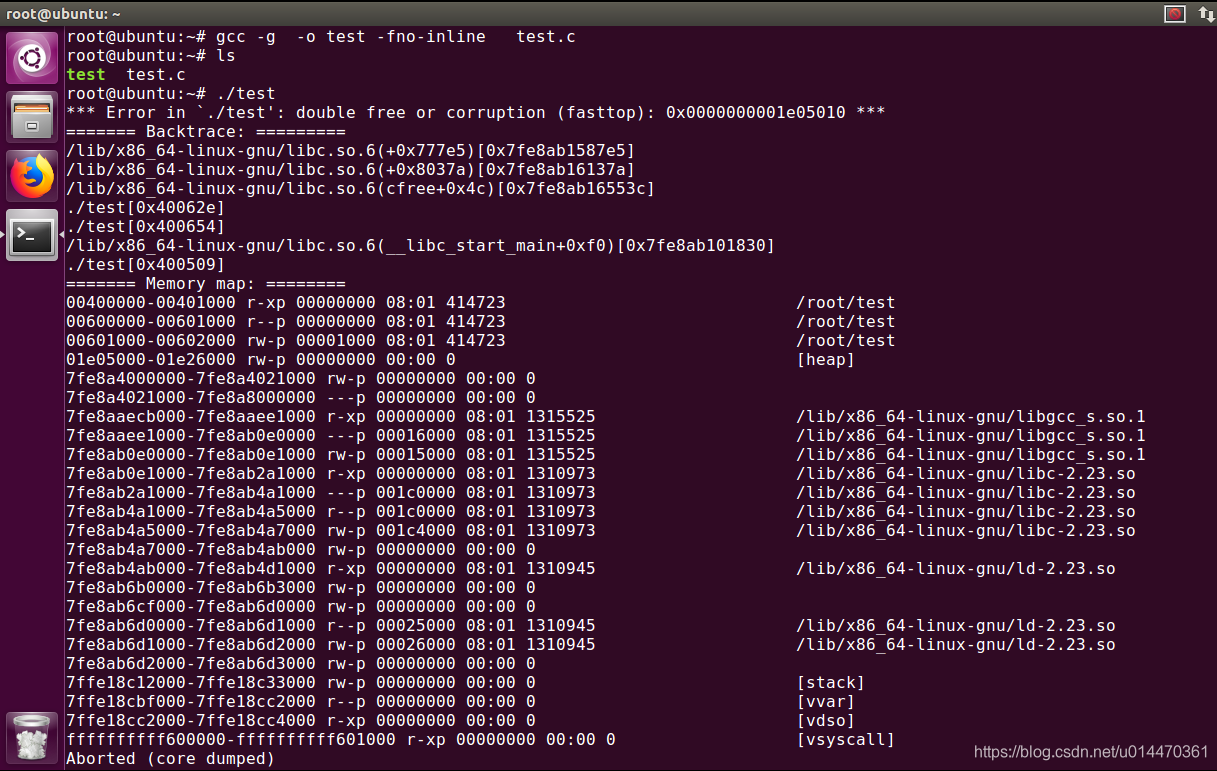
; doble libre o corrupción, informe de error de núcleo descargado.
Usemos la herramienta valgrind para analizar.
valgrind --tool=memcheck --leak-check=full --show-reachable=yes --trace-children=yes ./test
--Leak-check = full se refiere a verificar las fugas de memoria por completo,
--Show-reachable = yes es para mostrar la ubicación de la pérdida de memoria,
-Trace-children = yes es seguir el proceso hijo.
resultado de la operación:
root@ubuntu:~# valgrind --tool=memcheck --leak-check=full --show-reachable=yes --trace-children=yes ./test
==43170== Memcheck, a memory error detector
==43170== Copyright (C) 2002-2015, and GNU GPL'd, by Julian Seward et al.
==43170== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==43170== Command: ./test
==43170==
==43170== Invalid write of size 4 // 无效写入,内存越界了
==43170== at 0x4005F4: test (test.c:8)
==43170== by 0x400653: main (test.c:23)
==43170== Address 0x5204068 is 0 bytes after a block of size 40 alloc'd
==43170== at 0x4C2DB8F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==43170== by 0x4005E7: test (test.c:7)
==43170== by 0x400653: main (test.c:23)
==43170==
==43170== Source and destination overlap in memcpy(0x5204044, 0x5204040, 5)// 内存地址重叠
==43170== at 0x4C32513: memcpy@@GLIBC_2.14 (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==43170== by 0x400615: test (test.c:10)
==43170== by 0x400653: main (test.c:23)
==43170==
==43170== Invalid free() / delete / delete[] / realloc()// 重复释放
==43170== at 0x4C2EDEB: free (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==43170== by 0x40062D: test (test.c:13)
==43170== by 0x400653: main (test.c:23)
==43170== Address 0x5204040 is 0 bytes inside a block of size 40 free'd
==43170== at 0x4C2EDEB: free (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==43170== by 0x400621: test (test.c:12)
==43170== by 0x400653: main (test.c:23)
==43170== Block was alloc'd at
==43170== at 0x4C2DB8F: malloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so)
==43170== by 0x4005E7: test (test.c:7)
==43170== by 0x400653: main (test.c:23)
==43170==
==43170== Use of uninitialised value of size 8 // 使用了未初始化的指针,非法的指针
==43170== at 0x400632: test (test.c:16)
==43170== by 0x400653: main (test.c:23)
==43170==
==43170== Invalid write of size 4
==43170== at 0x400632: test (test.c:16)
==43170== by 0x400653: main (test.c:23)
==43170== Address 0x0 is not stack'd, malloc'd or (recently) free'd
==43170==
==43170==
==43170== Process terminating with default action of signal 11 (SIGSEGV)//由于非法指针赋值导致的程序崩溃
==43170== Access not within mapped region at address 0x0
==43170== at 0x400632: test (test.c:16)
==43170== by 0x400653: main (test.c:23)
==43170== If you believe this happened as a result of a stack
==43170== overflow in your program's main thread (unlikely but
==43170== possible), you can try to increase the size of the
==43170== main thread stack using the --main-stacksize= flag.
==43170== The main thread stack size used in this run was 8388608.
==43170==
==43170== HEAP SUMMARY:
==43170== in use at exit: 0 bytes in 0 blocks
==43170== total heap usage: 1 allocs, 2 frees, 40 bytes allocated
==43170==
==43170== All heap blocks were freed -- no leaks are possible
==43170==
==43170== For counts of detected and suppressed errors, rerun with: -v
==43170== Use --track-origins=yes to see where uninitialised values come from
==43170== ERROR SUMMARY: 5 errors from 5 contexts (suppressed: 0 from 0) //一共5个错误
Segmentation fault (core dumped)
Callgrind utiliza:
una herramienta de análisis similar a gprof, pero que tiene más matices para observar el funcionamiento del programa y nos puede proporcionar más información. A diferencia de gprof, no requiere opciones especiales adicionales al compilar el código fuente, pero se recomienda agregar opciones de depuración. Callgrind recopila algunos datos cuando el programa se está ejecutando, establece un gráfico de relación de llamadas de función y, opcionalmente, realiza una simulación de caché. Al final de la ejecución, escribirá los datos del análisis en un archivo. callgrind_annotate puede convertir el contenido de este archivo en un formato legible.
Ejemplos de uso de cachegrind:
#include <stdio.h>
#include <malloc.h>
void test()
{
sleep(1);
}
void f()
{
int i;
for( i = 0; i < 5; i ++)
test();
}
int main()
{
f();
printf("process is over!\n");
return 0;
}
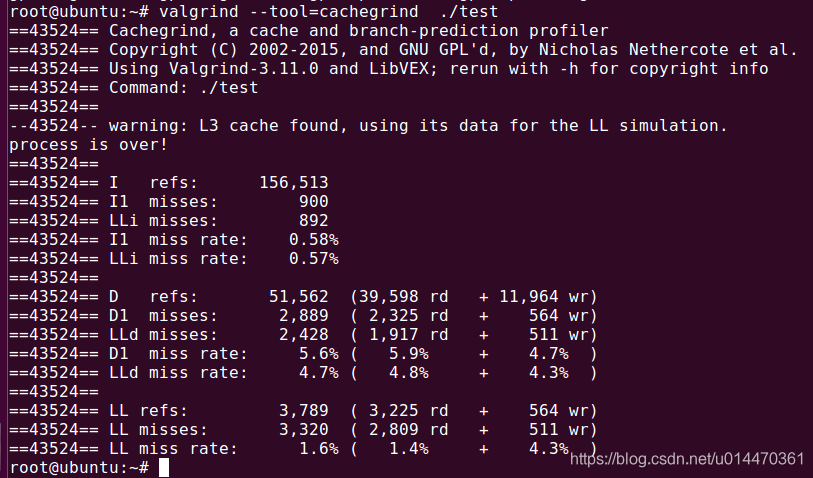
El método de uso es: valgrind --tool = cachegrind ./test
Helgrind
se utiliza principalmente para comprobar problemas de competencia en programas multiproceso. Helgrind busca áreas en la memoria a las que acceden varios subprocesos y que no están bloqueadas de manera constante. Estas áreas suelen ser lugares donde los subprocesos pierden sincronización y pueden dar lugar a errores que son difíciles de descubrir. Helgrind implementó un algoritmo de detección de competencia llamado "Eraser" e hizo más mejoras para reducir el número de errores reportados. Sin embargo, Helgrind todavía se encuentra en la etapa experimental.
Primero demos un ejemplo de competencia:
#include <stdio.h>
#include <pthread.h>
#define NLOOP 50
int contador = 0; / * incrementado por subprocesos * /
void * threadfn (void *);
int main (int argc, char ** argv)
{ pthread_t tid1, tid2, tid3;
pthread_create(&tid1, NULL, &threadfn, NULL);
pthread_create(&tid2, NULL, &threadfn, NULL);
pthread_create(&tid3, NULL, &threadfn, NULL);
/* wait for both threads to terminate */
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
return 0;
}
void threadfn (void vptr)
{ int i, val; for (i = 0; i <NLOOP; i ++) { val = counter; printf ("% x:% d \ n", (unsigned int) pthread_self (), val +1); contador = val + 1; } return NULL; } El estado de carrera de este programa está en las líneas 30 ~ 32. El efecto que queremos es que los tres hilos acumulen la variable global 50 veces, y el valor final de la variable global es 150. Dado que aquí no hay bloqueo, es obvio que la condición de carrera impide que el programa alcance nuestro objetivo. Veamos cómo Helgrind puede ayudarnos a detectar condiciones de carrera. Primero compile el programa: gcc -o test thread.c -lpthread, luego ejecute: valgrind --tool = helgrind ./test La salida es la siguiente: 49c0b70: 1 49c0b70: 2
4666 Se creó el hilo # 3
4666 en 0x412E9D8: clon (clon. S: 111)
4666 por 0x40494B5: pthread_create @@ GLIBC_2.1 (createthread.c: 256)
4666 por 0x4026E2D: pthread_create_WRK (hg_intercepts.c: 257)
4666por 0x4026F8B: pthread_create @ (hg_intercepts.c: 288)
4666 por 0x8048524: main (en /home/yanghao/Desktop/testC/testmem/a.out)
4666
4666 Se creó el hilo # 2
4666 en 0x412E9D8: clon (clon. S: 111)
4666 por 0x40494B5: pthread_create @@ GLIBC_2.1 (createthread.c: 256)
4666 por 0x4026E2D: pthread_create_WRK (hg_intercepts.c: 257)
4666por 0x4026F8B: pthread_create @ (hg_intercepts.c: 288)
4666 por 0x8048500: main (en /home/yanghao/Desktop/testC/testmem/a.out)
4666
4666 Posible carrera de datos durante la lectura de tamaño 4 en 0x804a028 por el hilo # 3
4666 en 0x804859C: threadfn (en /home/yanghao/Desktop/testC/testmem/a.out)
4666 por 0x4026F60: mythread_wrapper (hg_intercepts.c: 221)
4666 por 0x4048E98: start_thread (pthread_create.c: 304)
4666 por 0x412E9ED: clon (clone S: 130)
4666 Esto entra en conflicto con una escritura anterior de tamaño 4 por hilo # 2
4666 en 0x80485CA: threadfn (en /home/yanghao/Desktop/testC/testmem/a.out)
4666 por 0x4026F60: mythread_wrapper (hg_intercepts.c: 221)
4666 por 0x4048E98: start_thread (pthread_create.c: 304)
4666 por 0x412E9ED: clon (clone S: 130)
4666
4666 Posible carrera de datos durante la escritura de tamaño 4 en 0x804a028 por el hilo # 2
4666 en 0x80485CA: threadfn (en /home/yanghao/Desktop/testC/testmem/a.out)
4666 por 0x4026F60: mythread_wrapper (hg_intercepts.c: 221)
4666 por 0x4048E98: start_thread (pthread_create.c: 304)
4666 por 0x412E9ED: clon (clone S: 130)
4666 Esto entra en conflicto con una lectura anterior de tamaño 4 por hilo # 3
4666 en 0x804859C: threadfn (en /home/yanghao/Desktop/testC/testmem/a.out)
4666 por 0x4026F60: mythread_wrapper (hg_intercepts.c: 221)
4666 por 0x4048E98: start_thread (pthread_create.c: 304)
4666 por 0x412E9ED: clon (clone S: 130)
4666
49c0b70: 3
…
55c1b70: 51
4666
4666 Para los recuentos de errores detectados y suprimidos, vuelva a ejecutar con: -v
4666 Utilice --history-level = approx o = none para obtener una mayor velocidad, en
4666 el costo de la precisión reducida de la información de acceso conflictivo
4666 RESUMEN DE ERRORES: 8 errores de 2 contextos (suprimido: 99 de 31)
Helgrind encontró con éxito la posición de la competencia, que se muestra en negrita.
Macizo
Analizador de pila, puede medir cuánta memoria usa el programa en la pila, decirnos el bloque de pila, el bloque de gestión de pila y el tamaño de pila. Massif puede ayudarnos a reducir el uso de memoria. En los sistemas modernos con memoria virtual, también puede acelerar la ejecución de nuestros programas y reducir la posibilidad de que los programas permanezcan en el área de intercambio.
Massif perfila la asignación y liberación de memoria. Los desarrolladores de programas pueden usarlo para comprender profundamente el comportamiento de uso de la memoria del programa y optimizar el uso de la memoria. Esta característica es especialmente útil para C ++, porque C ++ tiene muchas asignaciones y versiones de memoria oculta.
Además, lacayo y nulgrind también proporcionarán. Lackey es una pequeña herramienta que rara vez se usa; Nulgrind solo muestra a los desarrolladores cómo crear una herramienta. No lo presentaremos.
Principio de detección de memoria
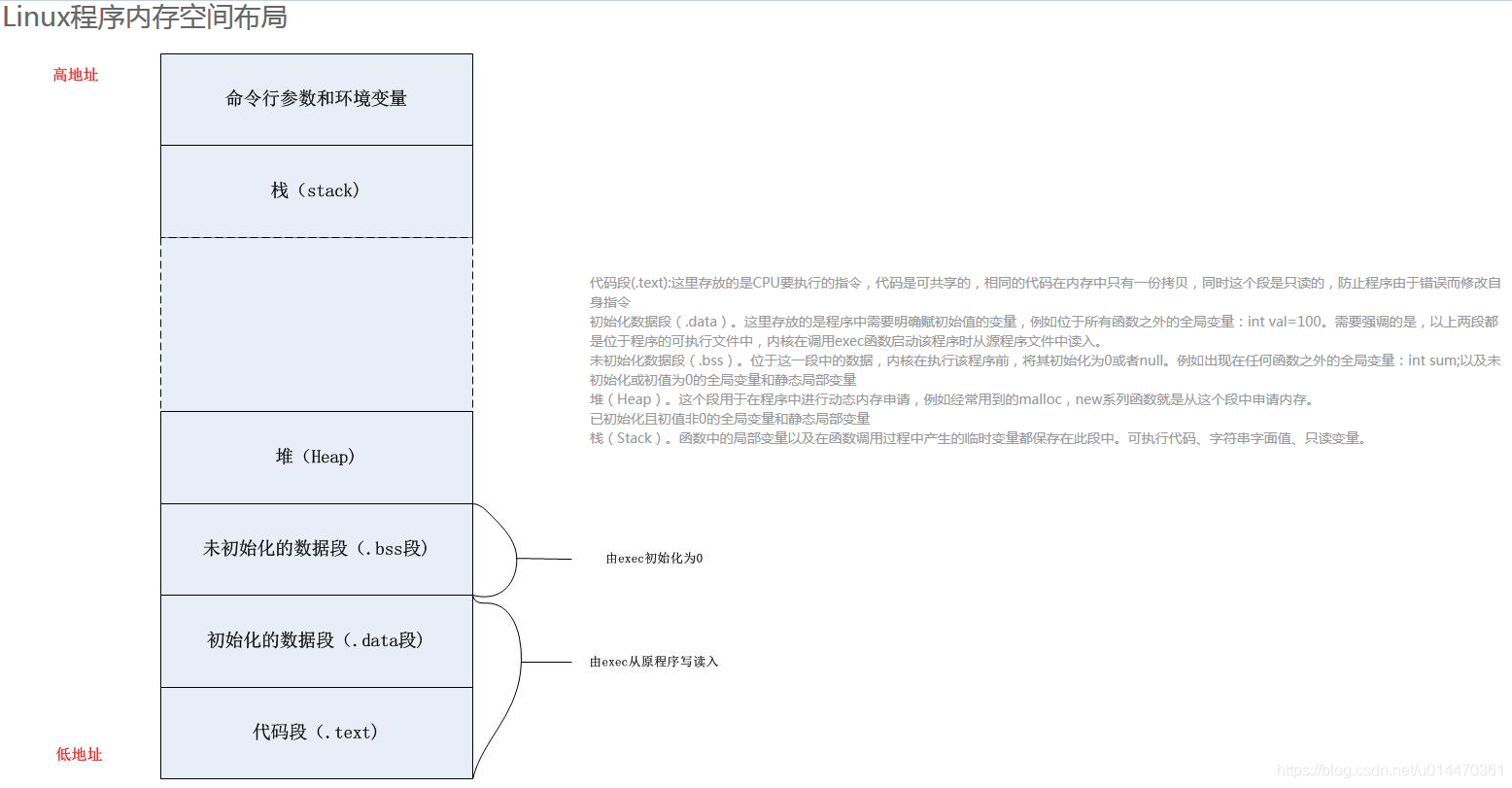
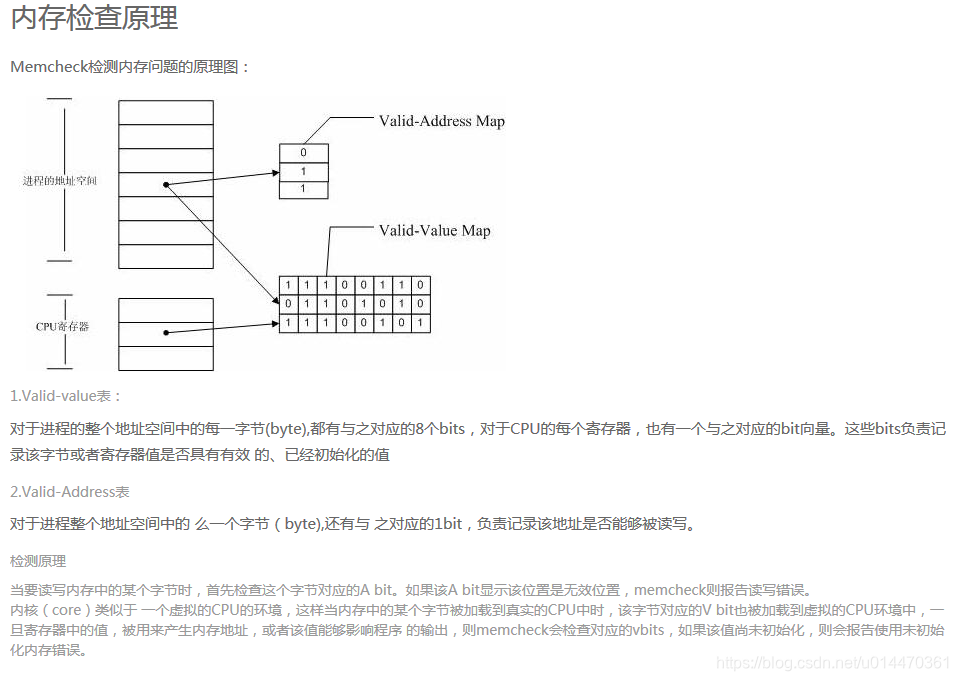
Citado de: https://www.cnblogs.com/AndyStudy/p/6409287.html
https://www.linuxidc.com/Linux/2012-06/63754.htm