Tabla de contenido
2. Método de implementación del clúster Hadoop
3.1 Planificación de funciones del clúster
3.2 Preparación básica del entorno del servidor
3.2.1 Inicialización del entorno
3.2.2 Inicio de sesión sin contraseña ssh (ejecutado en hadoop01)
3.2.3 Instalar el entorno JDK 1.8 en cada nodo
3.4 Estructura del directorio del paquete de instalación de Hadoop
3.5 Editar el archivo de configuración de Hadoop
3.6 Distribuir el paquete de instalación síncrona
3.7 Configurar variables de entorno de Hadoop
3.8 Formato NameNode (operación de formateo)
3.9 Inicio y apagado del clúster Hadoop
3.9.1 Iniciar y detener procesos manualmente uno por uno
3.9.2 Inicio y detención del script de shell con un solo clic
3.9.3 Registro de inicio del clúster Hadoop
3.10 Página de interfaz de usuario web de Hadoop
3.10.1 Configurar la asignación de nombres de dominio de Windows
3.10.3 Acceder a la página de interfaz de usuario del clúster YARN
4. Primera experiencia con Hadoop
4.1 Primera experiencia con HDFS
4.1.1 Operación del comando Shell
4.1.2 Operación de la página de la interfaz de usuario web
4.2 Primera experiencia de MapReduce + YARN
4.2.1 Ejecutar el caso oficial MapReduce de Hadoop
1. Introducción al clúster
El clúster Hadoop incluye dos clústeres: clúster HDFS y clúster YARN . Los dos clústeres están lógicamente separados y normalmente físicamente juntos; ambos clústeres son clústeres de arquitectura maestro-esclavo estándar.
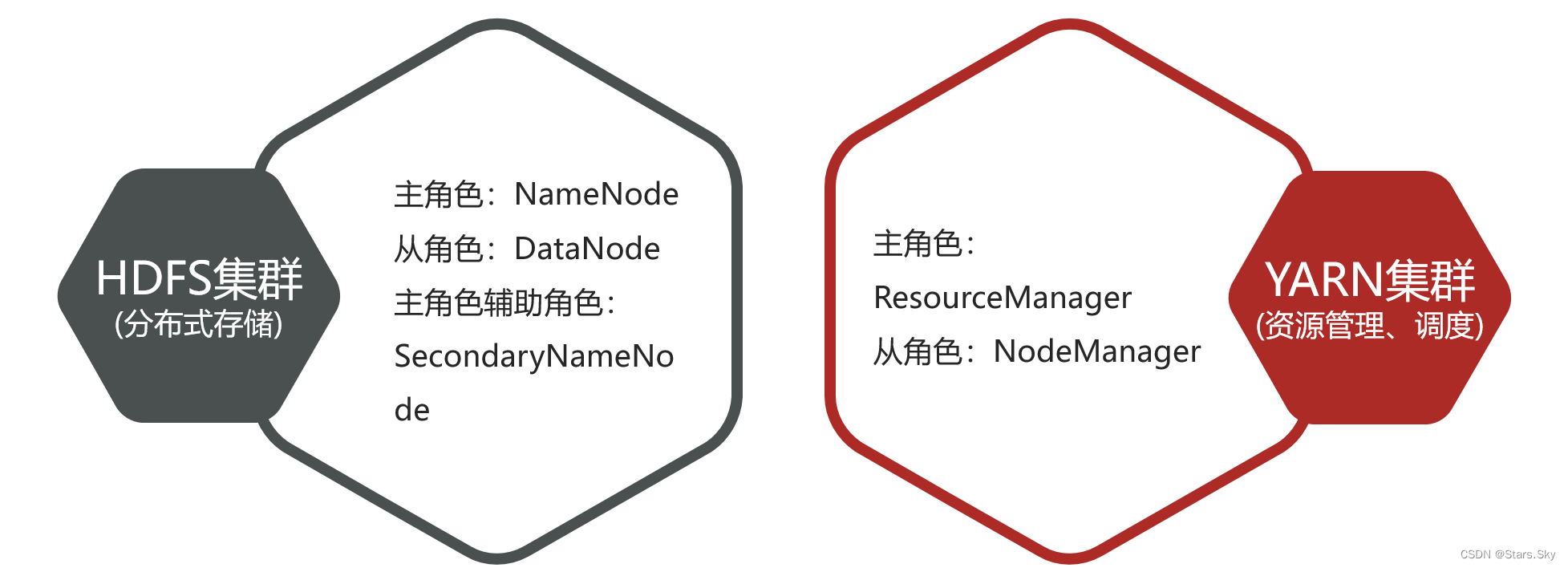
- lógicamente separados
Los dos grupos no dependen el uno del otro y no se afectan entre sí.
- fisicamente juntos
Ciertos procesos de roles a menudo se implementan en el mismo servidor físico.
- ¿Qué pasa con los clústeres de MapReduce ?
MapReduce es un marco informático y un componente a nivel de código, no existe un clúster
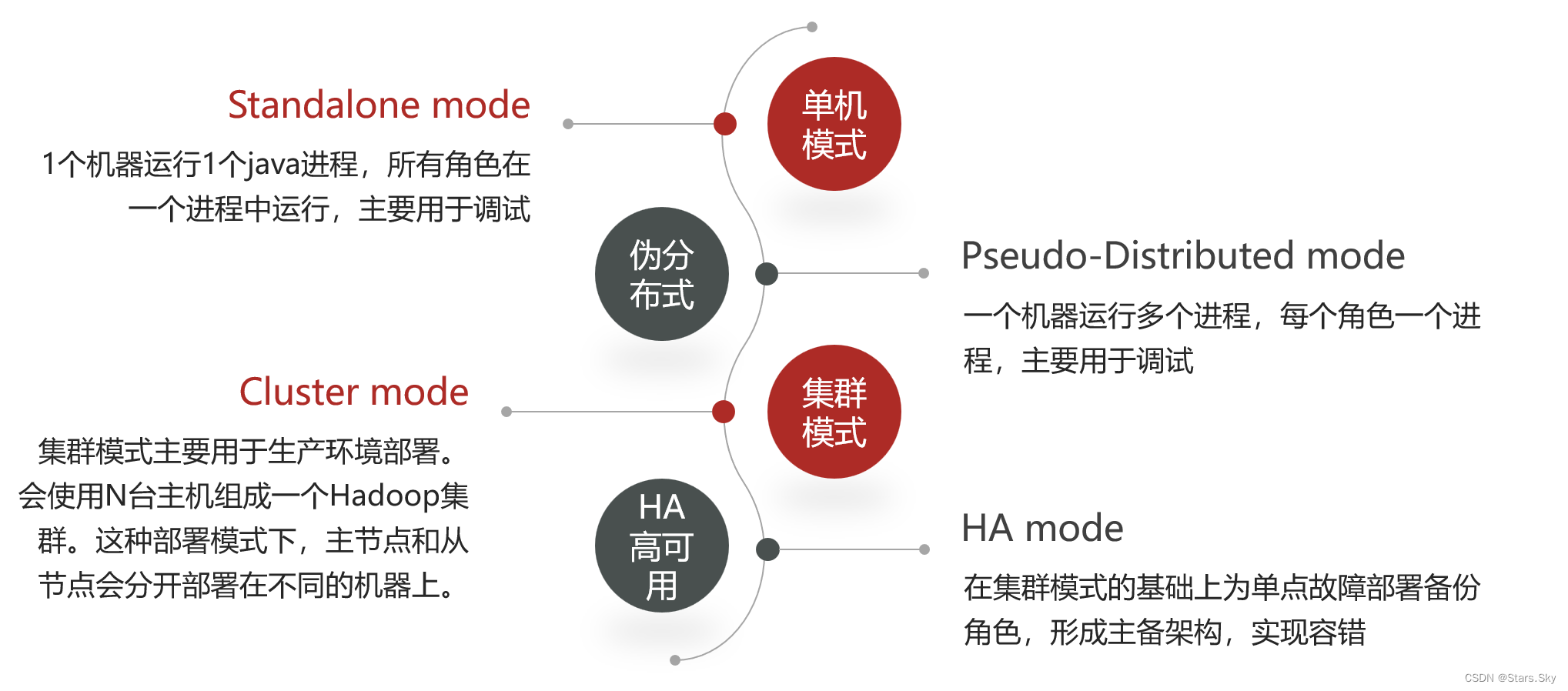
2. Método de implementación del clúster Hadoop
3. Instalación del clúster
3.1 Planificación de funciones del clúster
El modo de clúster se utiliza principalmente para la implementación del entorno de producción, que requiere varios hosts y estos hosts pueden acceder entre sí. Esta vez es para construir un modo de clúster en Centos 7.6, tomando tres hosts como ejemplo, el siguiente es el plan de clúster:
| IP de cada nodo | Nombre de cada nodo | ejecutar rol | Planificación de recursos para cada nodo. |
| 192.168.170.136 | hadoop01 | NameNode、DataNode、ResourceManager、NodeManager |
2 CPU / 4G |
| 192.168.170.137 | hadoop02 | SecondaryNamenode、DataNode、NodeManager |
2 CPU / 4G |
| 192.168.170.138 | hadoop03 | Nodo de datos, administrador de nodos | 2 CPU / 4G |
3.2 Preparación básica del entorno del servidor
3.2.1 Inicialización del entorno
Inicialice el entorno para las tres máquinas, especialmente el mapeo de Hosts: Inicialización de CentOS 7 system_centos7 inicialización_Stars.Sky's blog-CSDN blog
3.2.2 Inicio de sesión sin contraseña ssh (ejecutado en hadoop01)
# 4 个 回车,生成公钥、私钥
[root@hadoop01 ~]# ssh-keygen
# 推送到各个节点
[root@hadoop01 ~]# ssh-copy-id root@hadoop01
[root@hadoop01 ~]# ssh-copy-id root@hadoop02
[root@hadoop01 ~]# ssh-copy-id root@hadoop03
3.2.3 Instalar el entorno JDK 1.8 en cada nodo
3.3 Instalar Hadoop
Enlace de descarga oficial de Hadoop 3.2.4: Descargas de Apache
# 创建统一工作目录(3 台机器)
[root@hadoop01 ~]# mkdir -p /bigdata/hadoop/server # 软件安装路径
[root@hadoop01 ~]# mkdir -p /bigdata/hadoop/data # 数据存储路径
[root@hadoop01 ~]# mkdir -p /bigdata/softwares # 安装包存放路径
# 上传、解压安装包(hadoop01)
[root@hadoop01 ~]# cd /bigdata/softwares/
[root@hadoop01 /bigdata/softwares]# ls
hadoop-3.2.4.tar.gz
[root@hadoop01 /bigdata/softwares]# tar -zxvf hadoop-3.2.4.tar.gz -C /bigdata/hadoop/server/
3.4 Estructura del directorio del paquete de instalación de Hadoop
[root@hadoop01 /bigdata/softwares]# cd /bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# ls
hadoop-3.2.4
[root@hadoop01 /bigdata/hadoop/server]# cd hadoop-3.2.4/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share 3.5 Editar el archivo de configuración de Hadoop
3.5 Editar el archivo de configuración de Hadoop
3.5.1 hadoop-env.sh
Los archivos establecidos son las variables de entorno necesarias para que se ejecute Hadoop. Se debe configurar JAVA_HOME, incluso si JAVA_HOME está configurado en nuestro sistema actual, no lo reconoce, porque incluso si Hadoop se ejecuta en la máquina local, todavía considera el entorno de ejecución actual como un servidor remoto.
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# pwd
/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop
# 在文件最后面直接添加下面内容
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hadoop-env.sh
# 配置 JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_381
# 设置用户以执行对应角色 shell 命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3.5.2 sitio central.xml
El archivo de configuración principal de Hadoop tiene un elemento de configuración predeterminado core-default.xml. Las funciones de core-default.xml y core-site.xml son las mismas. Si no hay una propiedad configurada en core-site.xml, automáticamente obtendrá el valor de la misma propiedad en core-default.xml.
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim core-site.xml
<configuration>
<!-- 默认文件系统的名称。通过 URI 中 schema 区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs 文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- hadoop 本地数据存储目录 format 时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/data/tmp</value>
</property>
<!-- 在 Web UI 访问 HDFS 使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>3.5.3 sitio-hdfs.xml
El archivo de configuración principal de HDFS configura principalmente los parámetros relacionados de HDFS y tiene el elemento de configuración predeterminado hdfs-default.xml. Las funciones de hdfs-default.xml y hdfs-site.xml son las mismas: si no hay ninguna propiedad configurada en hdfs-site.xml, el valor de la misma propiedad en hdfs-default.xml se obtendrá automáticamente.
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hdfs-site.xml
<configuration>
<!-- 设定 SNN 运行主机和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
</property>
</configuration>3.5.4 sitio mapeado.xml
Como archivo de configuración principal de MapReduce, Hadoop tiene solo un archivo de plantilla mapred-site.xml.template de forma predeterminada, que debe usarse para copiar un archivo mapred-site.xml.
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim mapred-site.xml
<configuration>
<!-- mr 程序默认运行方式。yarn 集群模式 local 本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master 环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask 环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask 环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>3.5.5 sitio-hilado.xml
El archivo de configuración principal de YARN, agregue la siguiente configuración en la etiqueta <configuration> del archivo.
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim yarn-site.xml
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>3.5.6 trabajadores
El archivo de trabajadores registra el nombre de host del clúster. Generalmente, hay dos funciones:
- Coopere con scripts de inicio con un solo clic, como start-dfs.sh y stop-yarn.sh, para iniciar el clúster. En este momento, la marca de host en el archivo esclavo es la máquina donde se encuentra la función del nodo esclavo.
- Puede cooperar con el atributo dfs.hosts en hdfs-site.xml para formar un mecanismo de lista blanca.
dfs.hosts especifica un archivo que contiene una lista de hosts que pueden conectarse al NameNode. Se debe especificar la ruta completa del archivo para que todos los hosts de los trabajadores puedan unirse al clúster. Si el valor está vacío, se permiten todos los hosts.
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim workers
hadoop01
hadoop02
hadoop033.6 Distribuir el paquete de instalación síncrona
Sincronice el paquete de instalación de Hadoop scp en la máquina hadoop01 con otras máquinas:
[root@hadoop01 /bigdata/hadoop]# cd /bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# scp -r hadoop-3.2.4 root@hadoop02:/bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# scp -r hadoop-3.2.4 root@hadoop03:/bigdata/hadoop/server/
3.7 Configurar variables de entorno de Hadoop
Configure las variables de entorno de Hadoop en las tres máquinas :
[root@hadoop01 /bigdata/hadoop/server]# vim /etc/profile
# hadoop
export HADOOP_HOME=/bigdata/hadoop/server/hadoop-3.2.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载环境变量
[root@hadoop01 /bigdata/hadoop/server]# source /etc/profile
# 验证环境变量是否生效
[root@hadoop01 /bigdata/hadoop/server]# hadoop3.8 Formato NameNode (operación de formateo)
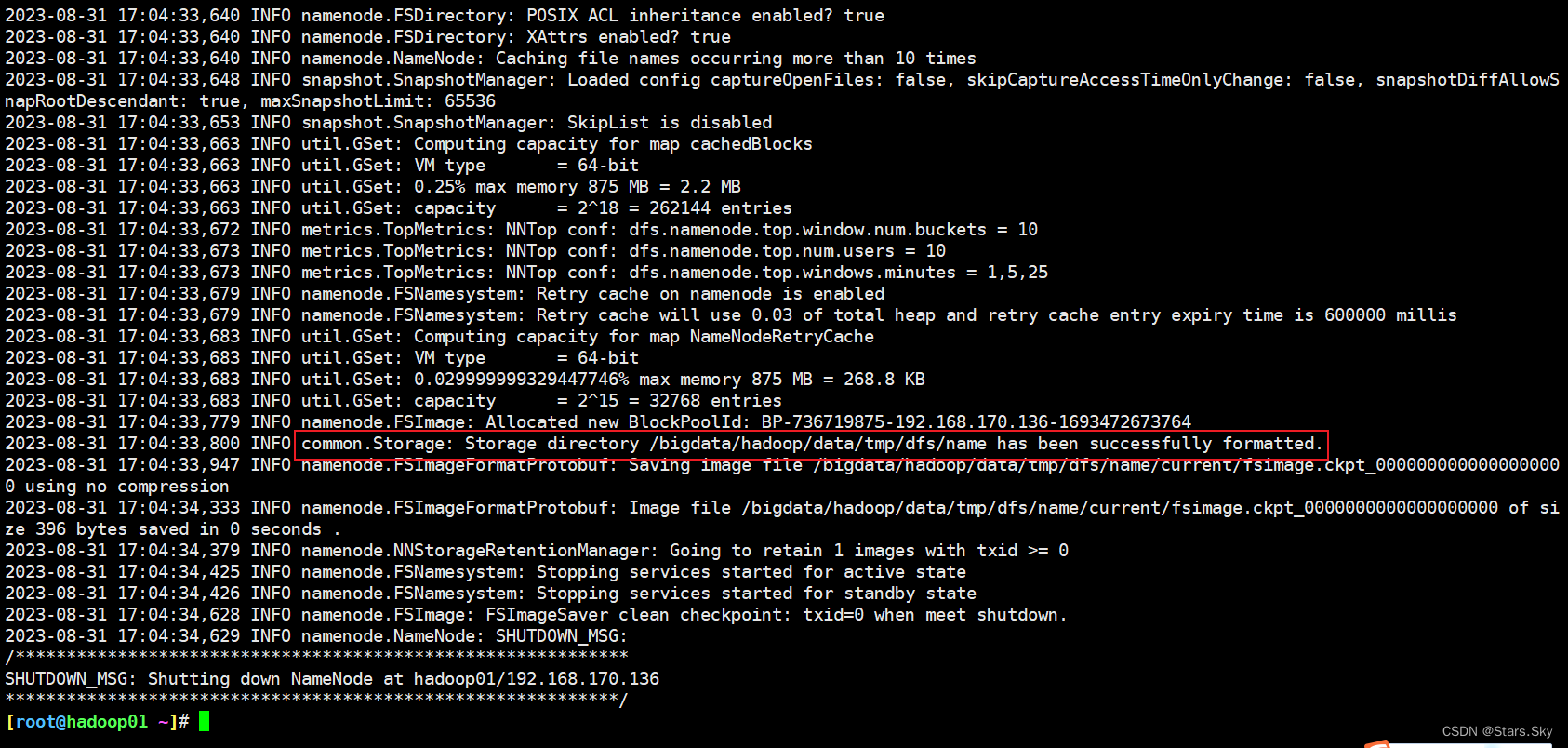
Al iniciar HDFS por primera vez, se debe formatear . El formato es esencialmente trabajo de inicialización , limpieza de HDFS y trabajo de preparación.
# 仅在 hadoop01 上执行
[root@hadoop01 ~]# hdfs namenode -format
[root@hadoop01 ~]# ll /bigdata/hadoop/data/tmp/dfs/name/current/
总用量 16
-rw-r--r-- 1 root root 396 8月 31 17:04 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 8月 31 17:04 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 8月 31 17:04 seen_txid
-rw-r--r-- 1 root root 218 8月 31 17:04 VERSION
fsimage_0000000000000000000: Esta es una imagen del sistema de archivos (Imagen del sistema de archivos), que contiene una instantánea de toda la estructura del sistema de archivos de HDFS (como directorios y metadatos de archivos).fsimage_0000000000000000000.md5: Esta esfsimagela suma de comprobación MD5 correspondiente al archivo, utilizada para verificar la integridad del archivo.seen_txid: Este archivo contiene el ID de transacción más grande visto (es decir, procesado) desde el último inicio de NameNode.VERSION: Este archivo contiene varias versiones e información de configuración relacionada con NameNode, como el número de versión de Hadoop, la versión de diseño, etc.
3.9 Inicio y apagado del clúster Hadoop
3.9.1 Iniciar y detener procesos manualmente uno por uno
Cada vez que un proceso de rol se inicia y se cierra manualmente en cada máquina.
- Clúster HDFS
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode- Grupo de hilos
yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager3.9.2 Inicio y detención del script de shell con un solo clic
En hadoop01 , utilice el script de shell que viene con el software para iniciarlo con un solo clic . Premisa: configurar archivos de trabajo y de inicio de sesión sin contraseña SSH entre máquinas .
- Clúster HDFS
inicio-dfs.sh
parada-dfs.sh
- Grupo de hilos
inicio-hilado.sh
parada-hilo.sh
- Clúster de Hadoop
empezar-todo.sh
detener-todo.sh
[root@hadoop01 ~]# start-all.sh
Starting namenodes on [hadoop01]
上一次登录:五 9月 1 14:24:35 CST 2023pts/0 上
Starting datanodes
上一次登录:五 9月 1 14:25:14 CST 2023pts/0 上
Starting secondary namenodes [hadoop02]
上一次登录:五 9月 1 14:25:17 CST 2023pts/0 上
Starting resourcemanager
上一次登录:五 9月 1 14:25:23 CST 2023pts/0 上
Starting nodemanagers
上一次登录:五 9月 1 14:25:30 CST 2023pts/0 上3.9.3 Registro de inicio del clúster Hadoop
# 启动完毕之后可以使用 jps 命令查看进程是否启动成功
[root@hadoop01 ~]# jps
22337 NodeManager
21798 DataNode
22203 ResourceManager
22669 Jps
21662 NameNode
[root@hadoop02 ~]# jps
21114 NodeManager
21005 DataNode
21213 Jps
[root@hadoop03 ~]# jps
21010 DataNode
21219 Jps
21119 NodeManager
# Hadoop 启动日志
[root@hadoop01 ~]# ll /bigdata/hadoop/server/hadoop-3.2.4/logs/
总用量 184
-rw-r--r-- 1 root root 36069 8月 31 17:54 hadoop-root-datanode-hadoop01.log
-rw-r--r-- 1 root root 692 8月 31 17:54 hadoop-root-datanode-hadoop01.out
-rw-r--r-- 1 root root 43819 8月 31 17:54 hadoop-root-namenode-hadoop01.log
-rw-r--r-- 1 root root 692 8月 31 17:54 hadoop-root-namenode-hadoop01.out
-rw-r--r-- 1 root root 40045 8月 31 17:55 hadoop-root-nodemanager-hadoop01.log
-rw-r--r-- 1 root root 2264 8月 31 17:55 hadoop-root-nodemanager-hadoop01.out
-rw-r--r-- 1 root root 47741 8月 31 17:55 hadoop-root-resourcemanager-hadoop01.log
-rw-r--r-- 1 root root 2280 8月 31 17:54 hadoop-root-resourcemanager-hadoop01.out
-rw-r--r-- 1 root root 0 8月 31 17:04 SecurityAuth-root.audit
drwxr-xr-x 2 root root 6 8月 31 17:54 userlogs3.10 Página de interfaz de usuario web de Hadoop
3.10.1 Configurar la asignación de nombres de dominio de Windows
- Abra el archivo de hosts en el directorio C:\Windows\System32\drivers\etc como administrador
- Agregue el siguiente nombre de dominio de mapeo y relación de mapeo de IP al final del archivo

3.10.2 Acceder a la página de interfaz de usuario del clúster HDFS
Dirección: http://namenode_host:9870
Donde namenode_host es el nombre de host o ip de la máquina donde se ejecuta namenode .
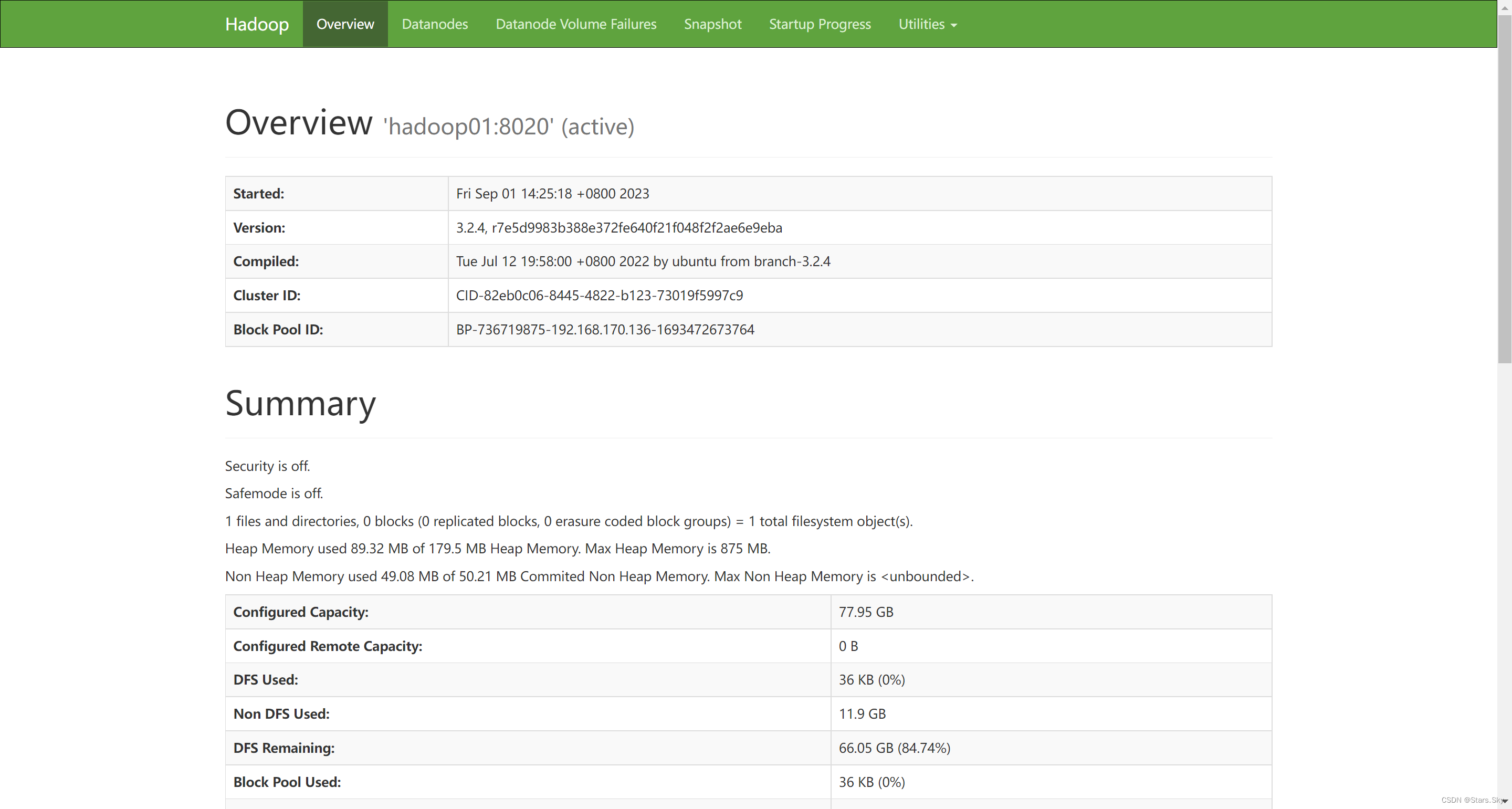
Navegación de páginas web del sistema de archivos HDFS :

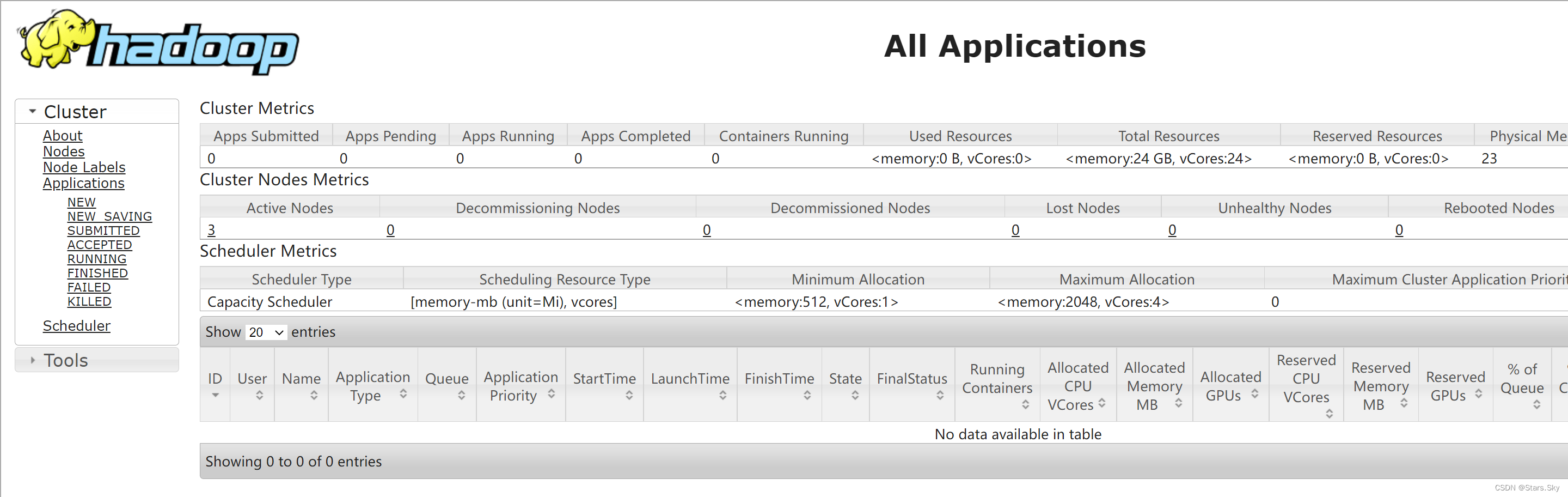
3.10.3 Acceder a la página de interfaz de usuario del clúster YARN
Dirección: http ://resourcemanager_host:8088
Donde Resourcemanager_host es el nombre de host o la IP de la máquina donde se ejecuta Resourcemanager .
Cuarto, primera experiencia con Hadoop
4.1 Primera experiencia con HDFS
4.1.1 Operación del comando Shell
[root@hadoop01 ~]# hadoop fs -mkdir /test1
[root@hadoop01 ~]# hadoop fs -put jdk-8u381-linux-x64.tar.gz /test1
[root@hadoop01 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2023-09-01 14:43 /test14.1.2 Operación de la página de la interfaz de usuario web
 4.2 Primera experiencia de MapReduce + YARN
4.2 Primera experiencia de MapReduce + YARN
4.2.1 Ejecutar el caso oficial MapReduce de Hadoop
Evalúe el valor de pi :
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/mapreduce/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/mapreduce]# hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 2 4
