Este artículo presenta la construcción del entorno de clúster hadoop 3.2.4. Antes de leer este artículo, es mejor leer el enlace del artículo de construcción pseudodistribuido
de la siguiente manera, porque se encuentran algunos problemas cuando se pseudodistribuye, y las soluciones no se repetirán aquí. .
Enlace: Construcción pseudo-distribuida
Directorio de artículos
- prefacio
- 1. Preparar la máquina
- Dos, preparación del entorno Linux.
- 3. Modificación del archivo de configuración de Hadoop
- 4. Inicie el clúster
- 5. Ejecute la demostración de prueba
- 6. Guión de inicio
- 7. Instrucciones de configuración clave
- 8. Resumen
prefacio
En el uso real, la construcción de hadoop debe ser un método de implementación de clústeres, por lo que el método de implementación de clústeres se construye aquí y también estoy familiarizado con la construcción de clústeres de hadoop.
1. Preparar la máquina
Para esta compilación, se prepararon tres máquinas virtuales, a saber,
hadoop1 192.168.184.129
hadoop2 192.168.184.130
Hadoop3 192.168.184.131
Las tres máquinas virtuales deben poder hacer ping entre sí. Estoy usando la configuración de red nat para la máquina virtual aquí. Puede mira tengo otro articulo de como configurarlo. El plan de implementación del nodo de configuración de red virtual nat es el siguiente
| Hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| hdf | Nodo de nombreNodo de datos | Nodo de nombre secundario Nodo de datos | nodo de datos |
| hilo | Administrador de nodos | Administrador de nodos Administrador de recursos | Administrador de nodos |
Dos, preparación del entorno Linux.
Las siguientes operaciones deben realizarse en las tres máquinas,
2.1 Modificar el nombre de host
Vi /etc/hostname```
Modifique el nombre de host para agregar el nombre de host de mapeo de ip para hadoop1, hadoop2, hadoop3 respectivamente
Vi /etc/hosts
192.168.184.129 hadoop1
192.168.184.130 hadoop2
192.168.184.131 hadoop3
2.2 Detener y desactivar el cortafuegos
systemctl stop firewalld.service
systemctl disable firewalld.service
2.3 Configurar inicio de sesión sin contraseña entre máquinas
El diagrama principal del inicio de sesión sin contraseña es el siguiente:
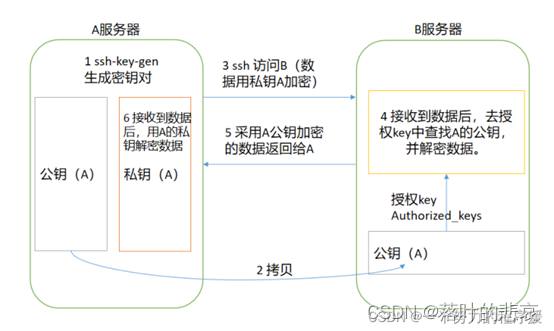
2.3.1 Generar clave pública y clave privada
ssh-keygen -t rsa
2.3.2 Copie la clave pública en la máquina que necesita iniciar sesión sin contraseña
Luego ingresa al directorio cd .ssh
y podrás ver que hay dos archivos
cd .ssh

Son la clave privada y la clave pública respectivamente, y copian la clave pública a hadoop2 y hadoop3
para su ejecución.
ssh-copy-id hadoop2
ssh-copy-id hadoop3
2.3.3 Prueba de inicio de sesión sin contraseña
ssh hadoop2
ssh hadoop3
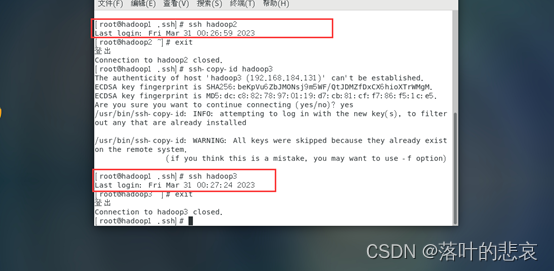
Si no necesita ingresar una contraseña, la modificación es exitosa. De manera similar, puede establecer un inicio de sesión sin contraseña para las otras dos máquinas en hadoop2 y hadoop3. No se muestra aquí, la misma operación.
3. Modificación del archivo de configuración de Hadoop
Modifique los siguientes archivos en el directorio etc/hadoop del directorio de instalación.
3.1 Modificar core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.184.129:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 注意这个目录不存在会导致启动不起来-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/tools/hadoop-3.2.4/data</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3.2 Modificar el archivo hdfs-site.xml
<!-- 设置SecondNameNode进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.184.130:9868</value>
</property>
3.3 Modificar el archivo mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.184.129:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.184.129:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${
HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${
HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${
HADOOP_HOME}</value>
</property>
3.4 Modificar el archivo yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.184.130</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.184.129:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
3.5 Modificar la ficha de trabajadores
192.168.184.129
192.168.184.130
192.168.184.131
3.6 Copiar archivos de configuración a otras máquinas
scp -r /root/tools/hadoop-3.2.4/etc/hadoop root@hadoop2:/root/tools/hadoop-3.2.4/etc/hadoop
scp -r /root/tools/hadoop-3.2.4/etc/hadoop root@hadoop3:/root/tools/hadoop-3.2.4/etc/hadoop
4. Inicie el clúster
注意如果是初次执行启动,需要在每台机器上执行初始化操作
hdfs namenode –format
4.1 Iniciar hdfs en hadoop1
El directorio de instalación es /root/tools/hadoop-3.2.4 y ejecuta las siguientes operaciones.
./sbin/start-dfs.sh
Inicie dfs e informe el error de la siguiente manera
dfs/name is in an inconsistent state: storage directory does not exist or is not accessible
Solución: reformatear namenode
hdfs namenode –format
Este no es mi problema, es que hay un espacio más delante del camino y el espacio se puede quitar.
Después de un inicio exitoso, visite la página de administración de nodos de nombres
http://192.168.184.129:9870 y podrá ver que los tres nodos de datos están activos
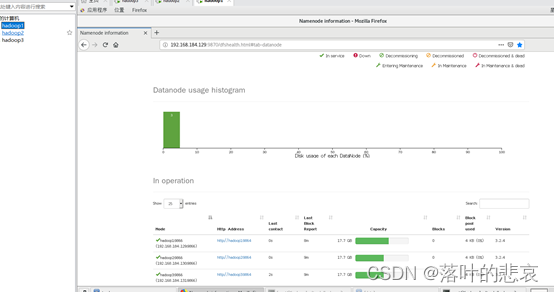
4.2 Iniciar hilo en hadoop2
./sbin/start-yarn.sh
Visite la página de administración del administrador de recursos
http://192.168.184.130:8088
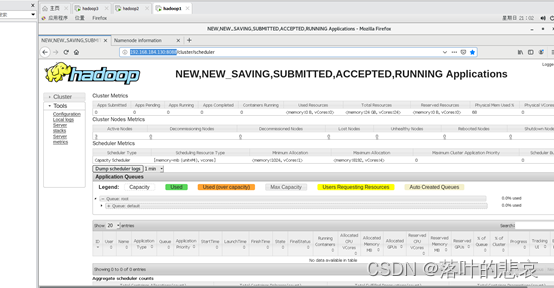
5. Ejecute la demostración de prueba
5.1 Calcular demostración pi
Vaya a la tabla share/mapreduce/directory y ejecute
hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 2 4
El resultado se muestra en la figura.
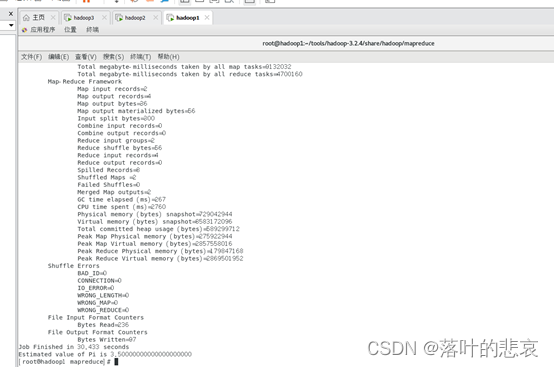
6. Guión de inicio
Es un poco problemático comenzar. Escribí un script que solo necesita ejecutarse una vez para iniciar y apagar el clúster.
hadoop.sh, debe modificar el permiso de ejecución después de modificar el archivo,
chmod 777 hadoop.sh
#!/bin/bash
# 判断参数个数
if [ $# -ne 1 ];then
echo "need one param, but given $#"
fi
# 操作hadoop
case $1 in
"start")
echo " ========== 启动hadoop集群 ========== "
echo ' ---------- 启动 hdfs ---------- '
ssh hadoop1 "/root/tools/hadoop-3.2.4/sbin/start-dfs.sh"
echo ' ---------- 启动 yarn ---------- '
ssh hadoop2 "/root/tools/hadoop-3.2.4/sbin/start-yarn.sh"
;;
"stop")
echo " ========== 关闭hadoop集群 ========== "
echo ' ---------- 关闭 yarn ---------- '
ssh hadoop2 "/root/tools/hadoop-3.2.4/sbin/stop-yarn.sh"
echo ' ---------- 关闭 hdfs ---------- '
ssh hadoop1 "/root/tools/hadoop-3.2.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Param Error ..."
;;
esac
Inicie el clúster, apague el clúster
./hadoop.sh start
./hadoop.sh stop
7. Instrucciones de configuración clave
La configuración clave del nodo es,
7.1 en hilo-sitio.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.184.130</value>
</property>
7.2 hdfs-site.xml, determine la ubicación del programa de nodo de nombre secundario
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.184.130:9868</value>
</property>
7.3 Asegúrese de que el nodo iniciado por yarn sea hadoop2. core-sitio.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.184.129:8020</value>
</property>
Determine la ubicación del namenode, es decir, el nodo de inicio de hdfs es hadoop1
7.4 configuración del archivo de trabajadores,
Es para asegurarse de que todos los nodos de datanode y nodemanage se estén ejecutando.
8. Resumen
Aquí no creo un nuevo usuario para ejecutar el programa hadoop. Estrictamente hablando, no puedo ejecutar el programa hadoop directamente con root. Soy demasiado perezoso para hacerlo aquí, así que solo lo ejecuto con root. El anterior artículo decía cómo ejecutarlo con root.Puedes leer el artículo anterior. Esto muestra el proceso de creación de clústeres de principio a fin y también registra los problemas encontrados. Si te resulta útil, dale me gusta.