¿Cuáles son los tipos numéricos soportados de forma nativa por Go?
Los tipos de lenguaje Go se pueden dividir aproximadamente en tres tipos: tipos de datos básicos, tipos de datos compuestos y tipos de interfaz.
Entre ellos, el tipo de datos básico más utilizado en nuestra codificación Go diaria es el tipo de datos básico, y el tipo de datos básico más utilizado es el tipo numérico.
entero
Los números enteros en el lenguaje Go se utilizan principalmente para representar cantidades enteras en el mundo real. Se puede dividir en enteros independientes de la plataforma y enteros dependientes de la plataforma. La principal diferencia entre ellos es si las longitudes de estos tipos de enteros son consistentes en diferentes arquitecturas de CPU o sistemas operativos.
entero independiente de la plataforma
Tienen una longitud fija en cualquier arquitectura de CPU o en cualquier sistema operativo.
La diferencia esencial entre enteros con signo (int8-int64) y enteros sin signo (uint8-uint64) es si el bit binario más alto (bit) se interpreta como un bit de signo, lo que afecta a los enteros sin signo y a los enteros con signo. Tipo rango de valores.
Go utiliza el complemento a 2 (complemento a dos) como método de codificación de bits para números enteros. Por lo tanto, no podemos simplemente considerar el bit más alto como un signo negativo y considerar el valor representado por los bits restantes como el valor detrás del signo negativo. El código complementario de Go se obtiene invirtiendo el código original bit a bit y luego sumando 1.
entero dependiente de la plataforma
Los enteros independientes de la plataforma corresponden a los enteros dependientes de la plataforma y sus longitudes variarán según la plataforma operativa.
El lenguaje Go proporciona de forma nativa tres tipos de enteros relacionados con la plataforma: int, uint y uintptr.
Dado que las longitudes de estos tres tipos dependen de la plataforma, no debemos depender demasiado de las longitudes de estos tipos al escribir código con requisitos de portabilidad.
Si no conoce el tamaño de estos tres tipos en la plataforma operativa de destino, puede obtenerlos a través de la función SizeOf proporcionada por el paquete inseguro.
problema de desbordamiento de enteros
Si el tipo entero está involucrado en una operación y el resultado excede el límite de valor del tipo entero, decimos que ha ocurrido un problema de desbordamiento de entero.
Dado que el tipo entero no puede representar el "resultado" después de que se desborda, el valor de la variable entera correspondiente seguirá estando dentro de su rango de valores después de que se produzca el desbordamiento, pero el valor del resultado no coincide con nuestras expectativas, lo que provoca un error de lógica del programa.
Valores literales y salida formateada.
El lenguaje Go ha heredado la forma gramatical del lenguaje C sobre el valor literal numérico (Number Literal) desde el comienzo de su diseño.
Las versiones anteriores de Go admitían literales numéricos decimales, octales y hexadecimales.
En Go 1.13, Go agregó soporte para literales binarios y dos formas de literales octales.
Para mejorar la legibilidad de los valores literales, la versión 1.13 de Go también admite agregar un separador numérico "_" en los valores literales. El separador se puede utilizar para agrupar números y mejorar la legibilidad.
Por el contrario, también podemos usar la función de salida formateada del paquete fmt en la biblioteca estándar para generar una variable entera en diferentes bases.
punto flotante
representación binaria de punto flotante
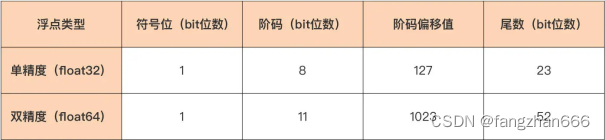
El lenguaje Go proporciona dos tipos de punto flotante, float32 y float64 , que corresponden a tipos numéricos de punto flotante de precisión simple y doble precisión, respectivamente.
Sin embargo, el tipo flotante no se proporciona en el idioma Go .
En otras palabras, los tipos de punto flotante proporcionados por Go son todos independientes de la plataforma.
Ya sea float32 o float64, el valor predeterminado de sus variables es 0.0, la diferencia es que el espacio de memoria que ocupan es diferente y el rango y la precisión de los números de punto flotante que se pueden representar también son diferentes.
La representación binaria de números de punto flotante en la memoria (Representación de bits) es mucho más complicada que la de los números enteros:
La representación binaria de un número de punto flotante en la memoria se divide en tres partes: el bit de signo, el exponente (es decir, el exponente convertido) y la mantisa. Un número de coma flotante representado así es igual a: ( − 1 ) s ∗ 1. M ∗ 2 E − offset (-1)^s * 1.M * 2 ^{E-offset}( -1 ) _s∗1.M _∗2mi − apagado se t。 _
Cuando el bit de signo es 1, el valor de punto flotante es negativo;
Cuando el bit de signo es 0, el valor de coma flotante es positivo.
El desplazamiento en la fórmula se denomina valor de desplazamiento del exponente.
Diferencias entre números de punto flotante de precisión simple (float32) y doble precisión (float64) en exponente y mantisa:
El tipo de punto flotante de precisión simple (float32) asigna 1 bit para el bit de signo, 8 bits para el exponente y los 23 bits restantes para la mantisa.
Para el tipo de punto flotante de doble precisión, excepto que la longitud del bit de signo es la misma que la del tipo de punto flotante de precisión simple, la longitud de las otras dos partes es mucho mayor que la del tipo de punto flotante de precisión simple. tipo de punto flotante El número de bits disponibles para el código de pedido es 11 y la mantisa tiene aún más Hay 52 bits.
Valores literales y salida formateada.
Los literales de tipo punto flotante de Go se pueden dividir aproximadamente en dos categorías, una es la forma de valores de punto flotante que se expresan directamente en decimal. En esta categoría, podemos determinar directamente su valor de punto flotante a través del valor literal.
La otra es la forma de notación científica. Para literales de punto flotante expresados en notación científica, necesitamos realizar ciertas conversiones para determinar sus valores de punto flotante. Y aquí, la forma de notación científica se divide en dos tipos expresada en forma decimal y hexadecimal.
Go proporciona dos tipos de números complejos, son complex64 y complex128, la parte real y la parte imaginaria de complex64 son de tipo float32, y la parte real y la parte imaginaria de complex128 son de tipo float64. Si a un número complejo no se le asigna explícitamente un tipo, entonces su tipo predeterminado es complejo128.
En cuanto a la representación de valores literales complejos, en realidad tenemos tres métodos:
Primero, podemos inicializar directamente una variable de tipo complejo con un valor literal complejo: var c = 5 + 6i.
En segundo lugar, Go también proporciona la función compleja, que nos resulta conveniente para crear un valor de tipo complex128: var c = complex(5, 6) // 5 + 6i.
En tercer lugar, también puede utilizar las funciones predefinidas real e imag proporcionadas por Go para obtener las partes real e imaginaria de un número complejo, y el valor de retorno es un tipo de punto flotante:
var c =complex(5,6)// 5 + 6i
r :=real(c)// 5.000000
i :=imag(c)// 6.000000
tipo de cadena
En Go, el tipo de cadena es cadena.
El lenguaje Go unifica la abstracción de "cadenas" mediante el tipo de cadena.
De esta manera, ya sea una constante de cadena, una variable de cadena o un valor literal de cadena que aparece en el código, su tipo se establece uniformemente en cadena.
Los datos de tipo cadena son inmutables, lo que mejora la seguridad de concurrencia y la utilización del almacenamiento de las cadenas.
Composición de las cuerdas de Go
El valor de la cadena en el lenguaje Go también es una secuencia de bytes que acepta valores NULL, y el número de bytes en la secuencia de bytes se denomina longitud de la cadena. Cada byte son solo datos aislados y no expresan significado.
Las cadenas se componen de una secuencia de caracteres que aceptan valores NULL.
tipos de runas y literales de caracteres
Go usa el tipo de runa para representar un punto de código Unicode. Rune es esencialmente un tipo de alias de tipo int32, que es completamente equivalente al tipo int32.
Una instancia de runa es un carácter Unicode y una cadena Go también puede considerarse como una colección de instancias de runa. Podemos inicializar una variable rúnica con un carácter literal.
En Go, hay varias representaciones de caracteres literales, siendo la más común los caracteres literales entre comillas simples.
También podemos usar el carácter de escape específico de Unicode \u o \U como prefijo para representar un carácter Unicode.
Dado que la runa que representa el punto de código es esencialmente un número entero, también podemos usar el valor entero para asignar directamente un valor a la variable de runa como un carácter literal.
literal de cadena
Una cadena es una colección de caracteres. Necesitamos reemplazar las comillas simples que representan un solo carácter con comillas dobles que representan una cadena de múltiples caracteres.
El tipo de cadena es en realidad un "descriptor" y en realidad no almacena datos de cadena en sí, sino que solo consta de un puntero al almacenamiento subyacente y el campo de longitud de la cadena.
No generaremos demasiada sobrecarga al pasar el tipo de cadena directamente a través de parámetros de función/método. Porque lo que se pasa es solo un "descriptor", no datos de cadena reales.
Operaciones comunes en tipos de cadenas Go
subíndice
En la implementación de cadenas, es la matriz subyacente la que realmente almacena los datos.
Subíndice una cadena es esencialmente equivalente a subíndice una matriz subyacente.
var s ="中国人"
fmt.Printf("0x%x\n", s[0])// 0xe4:字符“中” utf-8编码的第一个字节
Con los subíndices, obtenemos los bytes de un subíndice particular en la cadena, no los caracteres.
iteración de personajes
Go tiene dos formas de iteración: regular para iteración y para iteración de rango.
Los resultados obtenidos al operar sobre cadenas mediante estas dos formas de iteración son diferentes.
La operación en cadenas a través de la iteración regular es una iteración en perspectiva de bytes. El resultado de cada ronda de iteración es un byte que constituye el contenido de la cadena y el valor del subíndice donde se encuentra el byte, que también es lo mismo que Equivalente a iterando sobre la matriz subyacente de cadenas.
A través de la iteración de rango, lo que obtenemos en cada ronda de iteración es el valor del punto de código del carácter Unicode en la cadena y el valor de desplazamiento del carácter en la cadena.
Podemos obtener la cantidad de caracteres en la cadena a través de tales iteraciones, pero a través de la función incorporada len proporcionada por Go, solo podemos obtener la longitud (número de bytes) del contenido de la cadena.
Una forma más especializada de obtener la cantidad de caracteres en una cadena es llamar a la función RuneCountInString en el paquete UTF-8 de la biblioteca estándar.
concatenación de cadenas
Go admite de forma nativa la concatenación de cadenas mediante los operadores +/+=.
Si bien la experiencia del desarrollador con la concatenación de cadenas mediante +/+= es la mejor, el rendimiento de la concatenación puede no ser el más rápido.
Además de este método, Go también proporciona strings.Builder, strings.Join, fmt.Sprintf y otras funciones para realizar operaciones de concatenación de cadenas .
comparación de cadenas
Los tipos de cadena Go admiten varios operadores de comparación, incluidos ==, !=, >=, <=, > y <.
En la comparación de cadenas, Go utiliza una estrategia de comparación lexicográfica para comparar dos variables de tipo cadena byte a byte desde el principio de cada cadena.
Cuando aparece el primer elemento diferente entre las dos cadenas, la comparación finaliza y el resultado de la comparación de estos dos elementos se utilizará como resultado final de la comparación de las cadenas.
Si dos cadenas tienen longitudes diferentes, la cadena con una longitud menor se llenará con elementos vacíos y los elementos vacíos son más pequeños que otros elementos no vacíos.
Dado que el tipo de cadena Go es inmutable, si las longitudes de dos cadenas no son las mismas, entonces no necesitamos comparar los datos de la cadena específica y también podemos concluir que las dos cadenas son diferentes. Pero si las dos cadenas tienen la misma longitud, es necesario juzgar más a fondo si el puntero de datos apunta a los mismos datos de almacenamiento subyacentes. Si siguen siendo iguales, entonces podemos decir que las dos cadenas son equivalentes. Si son diferentes, entonces necesitamos comparar más a fondo el contenido de los datos reales.
conversión de cadenas
Go admite la conversión bidireccional entre cadenas y fragmentos de bytes, cadenas y fragmentos de runas, y esta conversión no necesita llamar a ninguna función, solo usa una conversión de tipo explícita.