Tabla de contenido
Conceptos y operaciones básicos:
Método y principio de implementación:
Escenarios de aplicación y precauciones de uso:
Análisis de algoritmos y complejidad:
Comparación con otras estructuras de datos:
PD: Si hay algún error u omisión, corríjame.
Conceptos y operaciones básicos:
Una lista enlazada circular es una estructura de lista enlazada especial, cuyo último nodo apunta al primer nodo, formando un bucle, de modo que la activación desde cualquier nodo de la lista pueda encontrar otros nodos en la lista. La lista enlazada circular se puede dividir en dos tipos: lista enlazada circular unidireccional y lista enlazada circular bidireccional. El siguiente es un diagrama esquemático de una lista circular individualmente enlazada con un nodo principal.
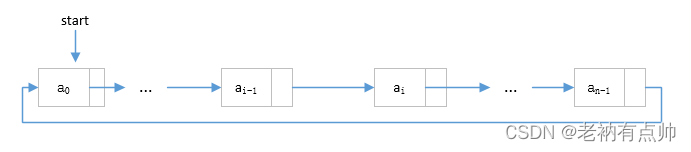
Para una lista enlazada circular, a veces cambiar el puntero a un puntero de cola facilitará la operación. La siguiente figura es un diagrama esquemático de una lista enlazada única circular con un puntero de cola.

Como se puede ver en el diagrama esquemático anterior, la relación lógica de usar una tabla circular para representar una tabla lineal es la misma que la de una lista enlazada individualmente, la diferencia es que el siguiente valor del último elemento no puede ser nulo, pero el primero en la lista enlazada almacenada.La dirección del elemento.
Las siguientes son operaciones comunes en listas circulares enlazadas:
-
Nodo principal: el nodo anterior al primer nodo de la lista enlazada circular, generalmente no almacena datos y su función principal es facilitar el funcionamiento de la lista enlazada circular.
-
Nodo de cola: el último nodo de la lista enlazada circular, cuyo siguiente puntero apunta al nodo principal.
-
Insertar elemento: para insertar un nuevo elemento en una posición especificada, debe modificar el siguiente puntero del nodo anterior y el siguiente puntero del nuevo nodo.
-
Eliminar elemento: para eliminar el elemento en la posición especificada, debe modificar el siguiente puntero del nodo anterior.
-
Buscar elementos: recorra la lista enlazada circular desde el nodo principal hasta encontrar el elemento de destino o recorrer toda la lista enlazada.
-
Atravesar elementos: atravesar todos los elementos de la lista circular enlazada desde el nodo principal se puede implementar mediante un bucle while o un bucle for.
-
Invertir la lista enlazada: invertir el orden de todos los nodos en la lista enlazada circular requiere el uso de tres punteros.
Cabe señalar que al realizar varias operaciones, es necesario garantizar la continuidad y el orden de la lista circular enlazada, es decir, el siguiente puntero de cada nodo apunta al siguiente nodo y el siguiente puntero del último nodo apunta a el nodo principal. Consulte el código C# a continuación para obtener detalles de implementación:
/// <summary>
/// 循环单链表数据结构实现接口具体步骤
/// </summary>
/// <typeparam name="T"></typeparam>
class CLinkedList<T>:ILinarList<T>
{
public SNode<T> tail;
int length;//循环链表长度
public CLinkedList()
{
this.tail = null;
}
/// <summary>
/// 在链表的末尾追加数据元素 data
/// </summary>
/// <param name="data">数据元素</param>
public void InsertNode(T data)
{
SNode<T> node = new SNode<T>(data);
if (IsEmpty())
{
tail = node;
tail.Next = tail;
}
else
{
T firstData = tail.Data;
SNode<T> current = tail;
while (current.Next != null && !current.Next.Data.Equals(firstData))
{
current = current.Next;
}
current.Next = new SNode<T>(data);
current.Next.Next = tail;
}
length++;
return;
}
/// <summary>
/// 在链表的第i个数据元素的位置前插入一个数据元素data
/// </summary>
/// <param name="data"></param>
/// <param name="i"></param>
public void InsertNode(T data, int i)
{
if (i < 1 || i > (length+1))
{
Console.WriteLine("Position is error!");
return;
}
SNode<T> current;
SNode<T> newNode = new SNode<T>(data);
if (i == 1)
{
newNode.Next = tail;
tail = newNode;
length++;
current = tail;
for (int j = 0; j < length; j++)
{
if (j== (length - 1))
{
current.Next = tail;
break;
}
current = current.Next;
}
return;
}
//两个元素中间插入一个元素
current = tail;
SNode<T> previous = null;
int index = 1;
while (current != null && index < i)
{
previous = current;
current = current.Next;
index++;
}
if (index == i)
{
previous.Next = newNode;
newNode.Next = current;
length++;
}
return;
}
/// <summary>
/// 删除链表的第i个数据元素
/// </summary>
/// <param name="i"></param>
public void DeleteNode(int i)
{
if (IsEmpty() || i < 1)
{
Console.WriteLine("Link is empty or Position is error");
}
SNode<T> current = tail;
SNode<T> previus = null;
if (i == 1)
{
tail.Data = current.Next.Data;
tail.Next = current.Next.Next;
length--;
return;
}
if (i > length)
{
return;
}
int j = 1;
while (current.Next != null && j < i)
{
previus = current;
current = current.Next;
j++;
}
if (j == i)
{
previus.Next = current.Next;
current = current.Next;
length--;
return;
}
//第i个节点不存在
Console.WriteLine("the ith node is not exist!");
}
/// <summary>
/// 获取链表的第i个数据元素
/// </summary>
/// <param name="i"></param>
/// <returns></returns>
public T SearchNode(int i)
{
if (IsEmpty())
{
Console.WriteLine("List is empty");
return default(T);
}
SNode<T> current = tail;
int j = 1;
while (current.Next != null && j < i && j<=length)
{
current = current.Next;
j++;
}
if (j == i)
{
return current.Data;
}
//第i个节点不存在
Console.WriteLine("the ith node is not exist!");
return default(T);
}
/// <summary>
/// 在链表中查找值为data的数据元素
/// </summary>
/// <param name="data"></param>
/// <returns></returns>
public T SearchNode(T data)
{
if (IsEmpty())
{
Console.WriteLine("List is empty");
return default(T);
}
SNode<T> current = tail;
int i = 1;
bool isFound = false;
while (current != null && i<=length)
{
if (current.Data.ToString().Contains(data.ToString()))
{
isFound = true;
break;
}
current = current.Next;
i++;
}
if (isFound)
{
return current.Data;
}
return default(T);
}
/// <summary>
/// 获取链表的长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return length;
}
/// <summary>
/// 清空链表
/// </summary>
public void Clear()
{
tail = null;
length = 0;
}
public bool IsEmpty()
{
return length == 0;
}
/// <summary>
/// 该函数将链表头节点反转后,重新作为链表的头节点。算法使用迭代方式实现,遍历链表并改变指针指向
/// 例如链表头结点start:由原来的
/// data:a,
/// next:[
/// data:b,
/// next:[
/// data:c,
/// next:[
/// data:a,
/// next:[
/// data:b,
/// next:...
/// ]
/// ]
/// ]
/// ]
///翻转后的结果为:
/// data:c,
/// next:[
/// data:b,
/// next:[
/// data:a,
/// next:[
/// data:c,
/// next:[
/// data:b,
/// next:....
/// ]
/// ]
/// ]
/// ]
/// </summary>
// 反转循环链表
public void ReverseList()
{
if (length == 1 || this.tail == null)
{
return;
}
//定义 previous next 两个指针
SNode<T> previous = null;
SNode<T> next;
SNode<T> current = this.tail;
//循环操作
while (current != null)
{
//定义next为Head后面的数,定义previous为Head前面的数
next = current.Next;
current.Next = previous;//这一部分可以理解为previous是Head前面的那个数。
//然后再把previous和Head都提前一位
previous = current;
current = next;
}
this.tail = previous.Next;
//循环结束后,返回新的表头,即原来表头的最后一个数。
return;
}
}En resumen, la lista enlazada circular es una estructura de lista enlazada especial, que se utiliza ampliamente en aplicaciones prácticas. Cabe señalar que al realizar diversas operaciones, es necesario garantizar la continuidad y el orden de la lista circular enlazada para evitar problemas como la inconsistencia de los datos.
Método y principio de implementación:
Una lista enlazada circular es una estructura especial de lista enlazada unidireccional o bidireccional, el siguiente puntero del último nodo apunta al primer nodo, formando un bucle. He introducido los métodos y principios de implementación de listas enlazadas circulares unidireccionales y bidireccionales en otros artículos.
En resumen, la lista enlazada circular es una estructura de lista enlazada especial y se debe tener cuidado para garantizar la continuidad y el orden de la lista enlazada durante la implementación.
Escenarios de aplicación y precauciones de uso:
Una lista enlazada circular es una estructura de lista enlazada especial, que es adecuada para escenarios que necesitan iterar a través de nodos. Los siguientes son algunos escenarios comunes de aplicación de listas enlazadas circulares:
-
Problema de Joseph: el problema de Joseph es un problema matemático clásico que se puede implementar con una lista enlazada circular. Específicamente, se puede usar una lista circular enlazada para simular un grupo de personas que forman un círculo y luego matar a cada Mésima persona por turno, y la última persona que queda es la ganadora.
-
Algoritmo de eliminación de caché: en el algoritmo de eliminación de caché, se puede utilizar una lista enlazada circular para implementar el algoritmo LRU (menos utilizado recientemente). Específicamente, los datos en el caché se pueden formar en una lista circular vinculada en orden de tiempo de acceso y, cuando el caché esté lleno, eliminar los datos a los que no se ha accedido durante más tiempo.
-
Efecto marquesina: en el desarrollo de una interfaz gráfica, se puede utilizar una lista enlazada circular para lograr el efecto de marquesina, incluso si un fragmento de texto se muestra en forma de desplazamiento circular.
Cuando utilice una lista enlazada circular, debe prestar atención a los siguientes puntos:
-
El funcionamiento de una lista enlazada circular es similar al de una lista enlazada normal y es relativamente fácil de insertar, eliminar y buscar. Sin embargo, es necesario prestar atención a la continuidad y el orden de la lista circular enlazada para evitar problemas como bucles infinitos o inconsistencias de datos.
-
Los nodos de la lista enlazada circular necesitan almacenar un puntero adicional, por lo que ocupa más espacio que la lista enlazada ordinaria.
-
Cuando se utiliza una lista enlazada circular bidireccional, es necesario prestar atención al procesamiento del nodo principal y del nodo final, para evitar la rotura de la lista enlazada debido a errores de operación.
En resumen, una lista enlazada circular es una estructura de lista enlazada especial, adecuada para escenarios que requieren acceso iterativo a los nodos. En aplicaciones prácticas, es necesario seleccionar una estructura de datos adecuada de acuerdo con las necesidades y escenarios específicos, y prestar atención a sus características y precauciones de uso.
Análisis de algoritmos y complejidad:
Algunos algoritmos básicos para listas enlazadas circulares incluyen:
-
Inserte un elemento en una posición especificada: primero debe encontrar el nodo anterior en la posición de inserción, luego apuntar el siguiente puntero del nuevo nodo al nodo en la posición de inserción y luego apuntar el siguiente puntero del nodo anterior al nodo en la posición de inserción. nuevo nodo. La complejidad del tiempo es O (n).
-
Eliminar un elemento en una posición especificada: debe encontrar el nodo anterior en la posición de eliminación y luego apuntar su siguiente puntero al siguiente nodo en la posición de eliminación. La complejidad del tiempo es O (n).
-
Búsqueda de elementos: es necesario recorrer la lista enlazada circular desde el nodo principal hasta encontrar el elemento de destino o recorrer toda la lista enlazada. La complejidad del tiempo es O (n).
-
Atravesar elementos: atravesar todos los elementos de la lista enlazada circular desde el nodo principal se puede implementar mediante un bucle while o un bucle for. La complejidad del tiempo es O (n).
-
Invertir la lista enlazada: invertir el orden de todos los nodos en la lista enlazada circular requiere el uso de tres punteros. La complejidad del tiempo es O (n).
Cabe señalar que en la lista circular enlazada, las operaciones de inserción y eliminación deben considerar además la modificación del siguiente puntero del último nodo y el puntero anterior del primer nodo. Al mismo tiempo, debido a la naturaleza especial de la lista enlazada circular, al atravesar y buscar elementos, es necesario juzgar si se ha cumplido la condición para el final del ciclo.
En resumen, la lista enlazada circular es una estructura de lista enlazada especial. Al implementar diversas operaciones, es necesario prestar atención a su continuidad y orden, y abordar situaciones especiales en consecuencia. En aplicaciones prácticas, es necesario seleccionar algoritmos y estructuras de datos apropiados de acuerdo con necesidades y escenarios específicos, y hacer concesiones y compromisos.
Comparación con otras estructuras de datos:
La lista enlazada circular es una estructura de lista enlazada especial que, en comparación con otras estructuras de datos, tiene las siguientes ventajas y desventajas:
-
En comparación con las listas enlazadas ordinarias, las listas enlazadas circulares tienen un funcionamiento más flexible y pueden realizar funciones como el acceso iterativo y el recorrido. Sin embargo, en operaciones como inserción, eliminación y búsqueda, su complejidad temporal es la misma que la de una lista enlazada normal.
-
En comparación con las matrices, las listas enlazadas circulares se pueden expandir dinámicamente y admitir operaciones eficientes de inserción y eliminación. Sin embargo, cuando se accede a elementos de forma aleatoria, su complejidad temporal es alta y no es tan eficiente como una matriz.
-
En comparación con las pilas y colas, las listas enlazadas circulares pueden almacenar más elementos y admitir métodos de acceso más flexibles. Sin embargo, al insertar y eliminar elementos, su complejidad temporal es relativamente alta y no es adecuado para operaciones frecuentes de este tipo.
-
En comparación con estructuras de datos complejas como árboles y gráficos, las listas enlazadas circulares son sencillas de implementar, fáciles de entender y mantener. Sin embargo, cuando se busca y atraviesa una gran cantidad de datos, su complejidad temporal es alta, lo que no es adecuado para este tipo de escenarios de aplicación.
-
En comparación con la tabla hash, la eficiencia de búsqueda de la lista enlazada circular es baja y no admite operaciones rápidas de inserción y eliminación. Sin embargo, su implementación es simple y no es necesario lidiar con problemas como las colisiones de hash.
En resumen, la lista enlazada circular es una estructura de lista enlazada especial, que debe seleccionarse de acuerdo con escenarios y requisitos específicos en aplicaciones prácticas. Cabe señalar que existen compensaciones y compromisos entre las diferentes estructuras de datos. Al utilizarlas, es necesario considerar exhaustivamente sus ventajas y desventajas y seleccionar las estructuras de datos y algoritmos adecuados.