Tabla de contenido
1. Introducción de la lista enlazada circular principal bidireccional
2. La interfaz de la lista enlazada circular principal bidireccional
3. Implementación de la interfaz
3.2 Crear el nodo principal de la lista vinculada devuelta
3.3 Determinar si la lista enlazada está vacía
3.5 Búsqueda de lista doblemente enlazada
3.6 La lista doblemente enlazada se inserta delante de pos
3.6.3 Actualizar el método de escritura de inserción de cabeza y inserción de cola
3.7 La lista doblemente enlazada elimina el nodo en la posición pos
3.7.1 Eliminación de encabezado
3.7.3 Actualizar borrado de cabeza y cola
3.8 Destrucción de listas doblemente enlazadas
1. Introducción de la lista enlazada circular principal bidireccional
Dividimos este tema para extraer tres palabras clave: bidireccional, líder y en bucle. Comencemos con estas tres palabras clave:
La primera es bidireccional : bidireccional significa que este nodo puede encontrar su predecesor y su sucesor, que es esencialmente diferente de la lista de enlaces simples;
El segundo es el líder : el líder muestra que la lista enlazada tiene un nodo principal, que también se puede llamar el nodo principal de la posición centinela.Este nodo es igual a los demás nodos, excepto que su campo de datos se llena con valores aleatorios. (Algunos almacenarán la longitud de la lista enlazada);
El último es el bucle : el bucle muestra que su estructura es un anillo, el nodo predecesor del nodo principal almacena el nodo final y el nodo sucesor del nodo final almacena el nodo principal.

2. La interfaz de la lista enlazada circular principal bidireccional
La función de la lista enlazada circular principal bidireccional es la misma que la de la lista enlazada única, y ambas pueden agregarse, eliminarse, verificarse y modificarse, pero las características de la lista enlazada circular principal bidireccional mejoran en gran medida nuestra eficiencia. al escribir tal función.
// 带头+双向+循环链表增删查改实现
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}ListNode;
// 创建返回链表的头结点
ListNode* ListCreate();
// 双向链表销毁
void ListDestory(ListNode* pHead);
// 双向链表打印
void ListPrint(ListNode* pHead);
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x);
// 双向链表尾删
void ListPopBack(ListNode* pHead);
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x);
// 双向链表头删
void ListPopFront(ListNode* pHead);
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x);
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x);
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos);3. Implementación de la interfaz
3.1 Abrir nodos
Nuestra lista enlazada es una lista enlazada dinámica, por lo que necesitamos malloc un nodo cada vez que lo insertamos, y lo encapsulamos en una función para facilitar la reutilización posterior del código.
ListNode* BuyListNode(LTDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (NULL == newnode)
{
perror("malloc fail:");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}3.2 Crear el nodo principal de la lista vinculada devuelta
Este paso es donde creamos un nodo principal centinela para la lista vinculada. Debido a que es una lista enlazada circular principal bidireccional, dejamos que los punteros anterior y siguiente apunten a nosotros mismos, de modo que incluso si solo hay un nodo principal, también somos una estructura circular bidireccional.
ListNode* ListCreate()
{
ListNode* phead = BuyListNode(-1);
phead->next = phead;
phead->prev = phead;
return phead;
}3.3 Determinar si la lista enlazada está vacía
Este paso es una función de juicio vacío que encapsulamos para eliminaciones posteriores. Cuando la lista enlazada existe, no descarta el caso de que la lista enlazada esté vacía, por lo que encapsulamos esta función para que las interfaces posteriores puedan ser reutilizadas.
bool ListEmpty(ListNode* pHead)
{
assert(pHead);
return pHead->next == pHead;
}3.4 imprimir
Ya estamos familiarizados con la función de impresión, pero debemos prestar atención a la condición de terminación de impresión de la lista enlazada circular principal de dos vías. Aquí ya no está el anterior cur == NULL, sino cur != pHead. Cuando cur llega a pHead , significa que hemos atravesado. Toda la lista enlazada se ha ido.
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
printf("guard");
while (cur != pHead)
{
printf("<==>%d", cur->data);
cur = cur->next;
}
printf("<==>\n");
}3.5 Búsqueda de lista doblemente enlazada
No es difícil de encontrar, pero aquí debe tenerse en cuenta que el primer nodo de la lista enlazada líder de dos vías es el nodo centinela, por lo que debemos recorrer la búsqueda desde el siguiente nodo del centinela (cur = pHead-> next), el final del bucle La condición sigue siendo cur != pHead.
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}3.6 La lista doblemente enlazada se inserta delante de pos
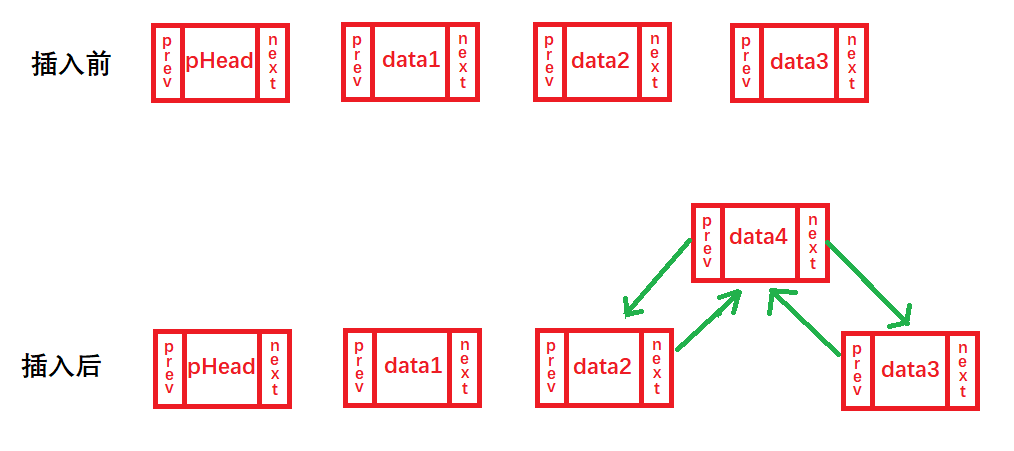
Después de encontrar la posición pos, la insertamos antes de la posición pos y la ejecutamos de acuerdo con el siguiente proceso:
1. Si queremos insertar un data4 antes de data3, primero definimos una variable de puntero de estructura prev, y primero guardamos el nodo data3->prev (data2) en la variable prev;
2. Luego cambie anterior->junto a datos4, y luego cambie datos4->anterior a anterior;
3. Finalmente, configure data4->next = data3, y luego configure data3->prev = data4.
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* prev = pos->prev;
ListNode* newnode = BuyListNode(x);
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}3.6.1 Enchufe
Para la inserción de la cabeza, somos coherentes con la inserción antes de la posición pos, primero guarde el primer nodo y luego inserte.
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newnode = BuyListNode(x);
ListNode* first = pHead->next;//多写这一个变量下面的插入语句就可以无序写
pHead->next = newnode;
newnode->next = first;
newnode->prev = pHead;
first->prev = newnode;
}3.6.2 Tapón trasero
Para la inserción de cola, primero guarde el nodo de cola de la lista vinculada y luego insértelo, que sigue siendo lo mismo que insertar antes de la posición pos.
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* tail = pHead->prev;
ListNode* newnode = BuyListNode(x);
tail->next = newnode;
newnode->prev = tail;
newnode->next = pHead;
pHead->prev = newnode;
}3.6.3 Actualizar el método de escritura de inserción de cabeza y inserción de cola
Comparando el código de inserción, no es difícil encontrar que la lógica de la inserción de la cabeza y la inserción de la cola es la misma que el código insertado antes de la posición pos, y las funciones implementadas básicamente no han cambiado, por lo que podemos reutilizar ListInsert directamente al insertar la cabeza y la cola La interfaz se puede realizar.
1> enchufe
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListInsert(pHead->next, x);
}2> enchufe trasero
Debido a que se inserta antes de la posición pos, la lista enlazada es un ciclo bidireccional, por lo que el primer parámetro que se pasa es pHead, y el nodo antes del nodo centinela es el nodo de cola.
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListInsert(pHead, x);
}3.7 La lista doblemente enlazada elimina el nodo en la posición pos
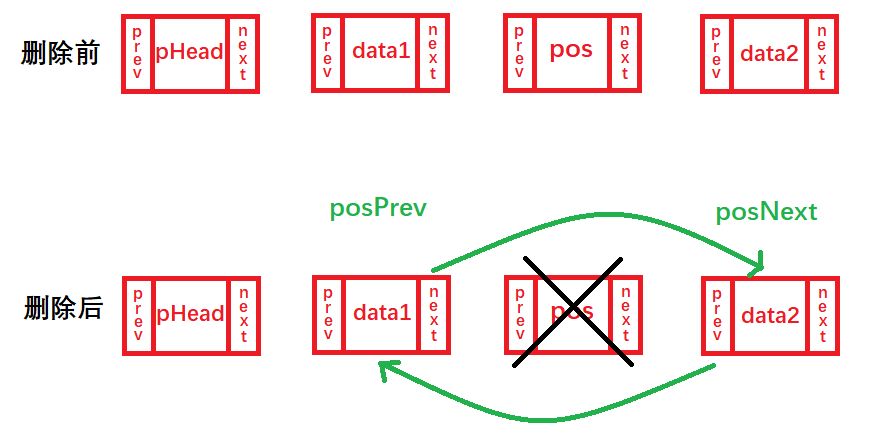
Después de encontrar el nodo pos, eliminamos el nodo pos y ejecutamos el siguiente proceso:
1. Defina dos variables de puntero de estructura posPrev y posNext, y almacene los nodos antes y después de la posición pos en las variables de puntero posPrev y posNext respectivamente;
2. Configure posPrev->siguiente = posNext, luego configure posNext->prev = posPrev;
3. Liberar el nodo pos, free(pos).
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* posPrev = pos->prev;
ListNode* posNext = pos->next;
posPrev->next = posNext;
posNext->prev = posPrev;
free(pos);
}3.7.1 Eliminación de encabezado
Si se elimina la cabeza, primero guardamos pHead->siguiente nodo y pHead->siguiente->siguiente nodo, conectamos el nodo centinela al siguiente nodo del nodo principal y luego liberamos el nodo principal.
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListNode* first = pHead->next;
ListNode* second = first->next;
pHead->next = second;
first->prev = pHead;
free(first);
}3.7.2 Eliminación de cola
Si se elimina la cola, primero guardamos el nodo pHead->prev y el nodo pHead->prev->prev, conectamos el nodo centinela con el nodo anterior del nodo tail y luego liberamos el nodo tail.
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListNode* tail = pHead->prev;
ListNode* tailPrev = tail->prev;
tailPrev->next = pHead;
pHead->prev = tailPrev;
free(tail);
}Resumen : antes de eliminar la cabeza y la cola, es necesario juzgar si la lista enlazada está vacía.
3.7.3 Actualizar borrado de cabeza y cola
Al comparar el código de eliminación, no es difícil encontrar que la lógica del código para eliminar la eliminación principal y la eliminación final es la misma que para eliminar el nodo de posición pos, y las funciones implementadas básicamente no han cambiado, por lo que podemos reutilizar ListErase directamente al eliminar la cabeza y la cola.La interfaz se puede realizar.
1> eliminar cabeza
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListErase(pHead->next);
}2> eliminación de cola
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListErase(pHead->prev);
}3.8 Destrucción de listas doblemente enlazadas
La destrucción de la lista enlazada es principalmente para atravesar la lista enlazada una vez, comenzando desde cur = pHead->siguiente, la condición de finalización del ciclo es cur != pHead, después de atravesar, el nodo centinela se libera y toda la lista enlazada es liberado.
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(pHead);
}4. Código completo
El código completo está en el almacén de códigos, entrada: C language: C language learning code, revise más - Gitee.com
5. Prueba de funcionamiento