Tabla de contenido
Archivo de encabezado (Circular_Linked_List):
Función declaración de función:
Archivo fuente (Circular_Linked_List):
Función de inicialización (Init_clist):
Función de juicio vacío (IsEmpty):
Obtener la función de longitud efectiva (Get_length):
Función de impresión (Mostrar):
Función de inserción de cabeza (Insert_head):
Función de inserción de cola (Insert_tail):
Insertar función por posición (Insert_pos):
Función de eliminación de cabeza (Delete_head):
Función de eliminación de cola (Delete_tail):
Eliminar función por posición (Delete_pos):
Eliminar función por valor (Delete_val):
Función de complemento de encabezado de prueba:
Función de interpolación de cola de prueba:
Pruebe la función de interpolación posicional:
Número de borrados del cabezal de prueba:
Función de eliminación de cola de prueba:
Pruebe la función de eliminación por posición:
Pruebe la función de eliminación por valor:
Función de destrucción de prueba:
Función de búsqueda de prueba:
introducción:
Directorio de aprendizaje de la estructura de datos:
Aprendizaje de la serie de estructuras de datos (1): una introducción a la estructura de datos
Aprendizaje de series de estructura de datos (2) - tabla de secuencia (Contiguous_List)
Aprendizaje de la serie de estructura de datos (3) - Lista enlazada individualmente (Linked_List)
En el artículo anterior, aprendimos y usamos el lenguaje C para realizar la lista de enlace único sin el nodo principal. En este artículo, implementaremos otra estructura de almacenamiento encadenado: la lista de enlace circular unidireccional en la lista de enlace circular. Aprenda y implementar con código.
estudiar:
Como otra estructura de almacenamiento de almacenamiento enlazado: lista enlazada circular, primero debemos tener claro la diferencia entre una lista enlazada circular unidireccional y una lista enlazada única ordinaria.
Usamos dos diagramas para distinguir estas dos estructuras de almacenamiento:
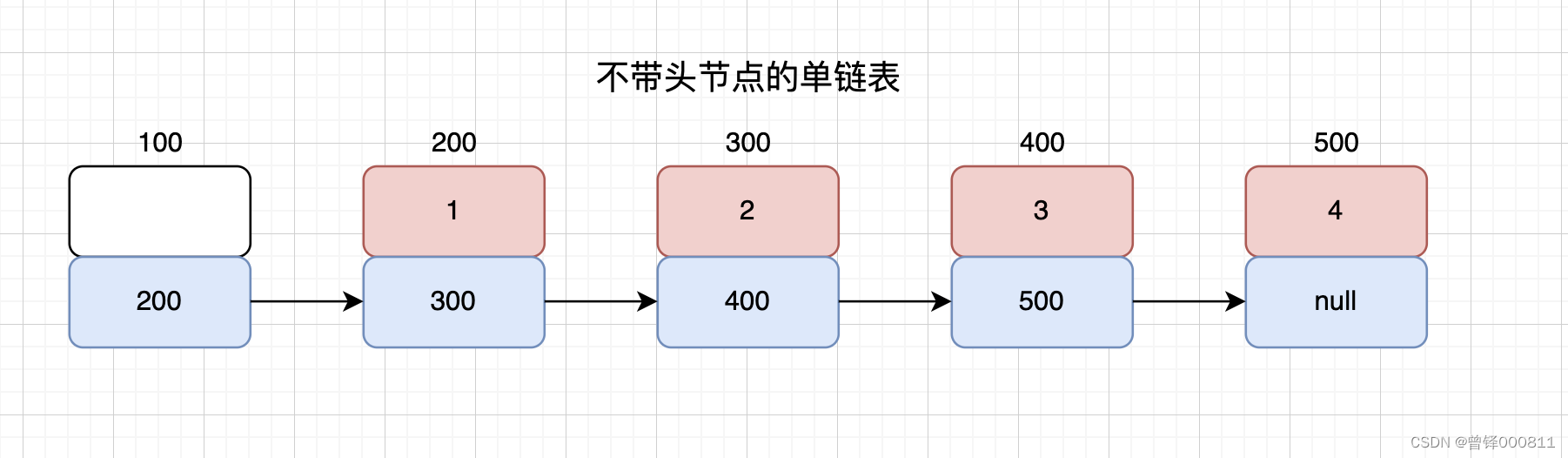
La estructura de una sola lista vinculada sin un nodo principal se muestra en la figura a continuación. No se almacenan datos en el campo de datos del nodo principal de la lista vinculada, y la dirección del siguiente nodo se guarda en el campo del puntero, y y así sucesivamente. Cada nodo guarda la dirección del siguiente nodo y guarda los datos. Hasta que el campo del puntero del último nodo esté vacío.
La estructura de la lista enlazada circular unidireccional se muestra en la siguiente figura. El campo de datos en el nodo principal no almacena datos, y cada nodo almacena la dirección del siguiente nodo. A diferencia de la lista enlazada simple sin el nodo principal, el último nodo en la lista enlazada circular almacena ¿Cuál es la dirección del nodo principal? Toda la lista enlazada forma una estructura de anillo.
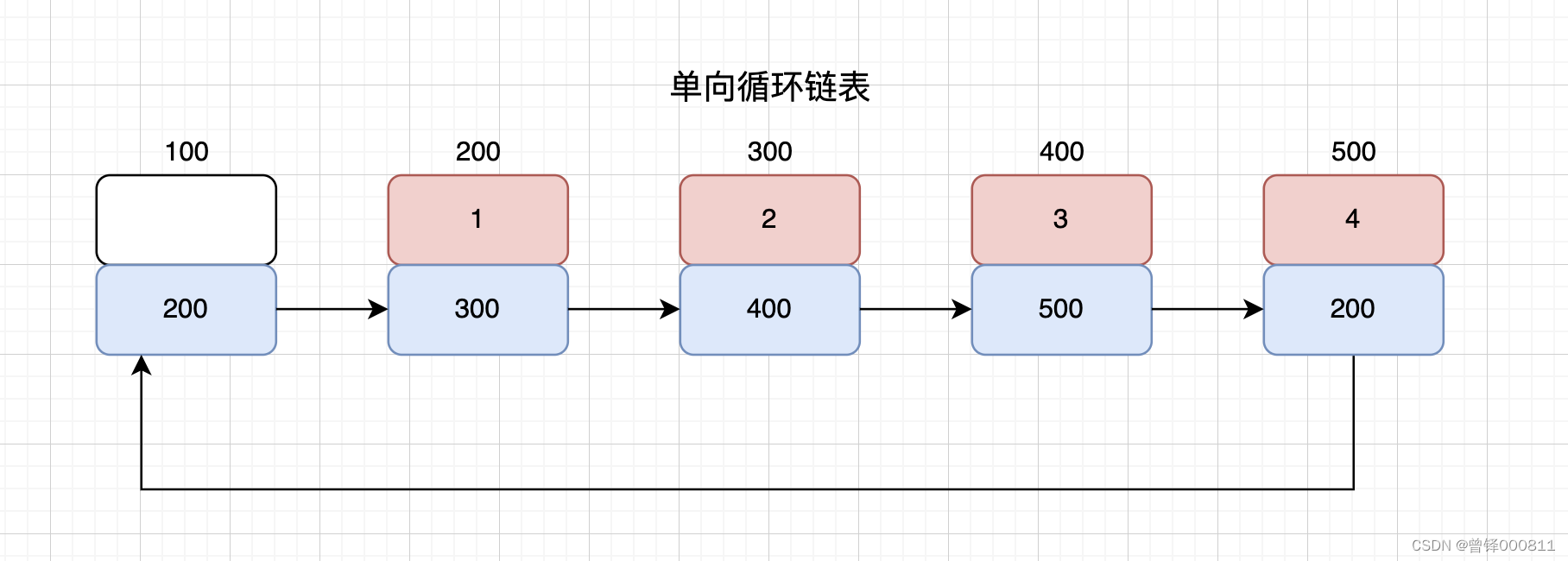
Hemos entendido aproximadamente la distinción estructural entre la lista enlazada circular unidireccional y la lista enlazada simple, entonces, ¿cuál es el significado de la existencia de la lista enlazada circular?
Ahora que se ha formado una estructura de anillo, podemos comenzar desde cualquier nodo de la lista enlazada y atravesar todos los nodos de la lista enlazada completa.
Por supuesto, si la estructura de la lista enlazada cambia, las funciones correspondientes también cambiarán aleatoriamente. Debido a que el campo de puntero del nodo final en la lista vinculada circular unidireccional ya no está vacío, sino que almacena la dirección del nodo principal, por lo que cuando inicializamos la lista vinculada, insertamos datos al final, insertamos datos por posición , eliminación de datos en el encabezado, y Al eliminar datos, eliminar datos por posición, eliminar datos por valor, imprimir datos, etc., la implementación de estas funciones debe modificarse en consecuencia.
Código:
Archivo de encabezado (Circular_Linked_List):
Diseño de estructura:
El diseño de la estructura de la lista enlazada circular unidireccional es el mismo que el de la lista enlazada simple. Cambiamos el nombre del tipo de int a Elem_type, definimos una variable de estructura llamada CNode, y sus miembros son el campo de datos de tipo Elem_type y el siguiente del tipo de puntero de estructura.
typedef int Elem_type;//范型定义
typedef struct CNode
{
Elem_type data;
struct CNode *next;
}CNode, *PCnode;//结构体别名Función declaración de función:
Necesitamos implementar la función en una lista enlazada circular unidireccional:
función de inicialización (Init_clist);
función de juicio vacío (IsEmpty);
Función de búsqueda (Buscar);
Obtener la longitud efectiva (Get_length);
Borrar función (Borrar);
Destruir función (Destruir);
Función de destrucción (Destroy1);
función de impresión (Mostrar);
Función de inserción de encabezado (Insert_head);
Función de inserción de cola (Insert_tail);
Interpolar función por posición (Insert_pos);
función de eliminación de cabeza (Delete_head);
Función de eliminación de cola (Delete_tail);
Eliminar función por posición (Delete_pos);
Eliminar función por valor (Delete_val);
código:
void Init_clist(PCnode cplist);
bool IsEmpty(PCnode cplist);
PCnode Search(PCnode cplist,Elem_type val);
int Get_length(PCnode cplist);
bool Clear(PCnode cplist);
bool Destroy(PCnode cplist);//无限头删
bool Destroy2(PCnode cplist);//不借助头节点,有两个辅助指针
void Show(PCnode cplist);
bool Insert_head(PCnode cplist,Elem_type val);
bool Insert_tail(PCnode cplist,Elem_type val);
bool Insert_pos(PCnode cplist,int pos,Elem_type val);
bool Delete_head(PCnode cplist);
bool Delete_tail(PCnode cplist);
bool Delete_pos(PCnode cplist,int pos);
bool Delete_val(PCnode cplist,Elem_type val);Archivo fuente (Circular_Linked_List):
Función de inicialización (Init_clist):
Cuando presentamos la lista enlazada circular unidireccional, dijimos que el nodo final de la lista enlazada circular unidireccional almacena la dirección del nodo principal, por lo que cuando inicializamos, el siguiente campo del nodo inicial en realidad almacena la dirección de el propio nodo inicial.
void Init_clist(PCnode cplist)
{
//问题:如果没有一个有效节点,那么头节点的next域应该指向谁? 答:指向自己
assert(cplist != nullptr);
cplist->next = cplist;
}Función de juicio vacío (IsEmpty):
Si la lista enlazada circular unidireccional está vacía, significa que no se guardan datos válidos en la lista enlazada, es decir, solo existe el nodo principal y no hay datos en el nodo principal. valor como la dirección del nodo principal para guardar Puede estar en el siguiente campo del nodo principal.
bool IsEmpty(PCnode cplist)
{
return cplist->next == cplist;
}Función de búsqueda (Buscar):
Establecemos el valor de retorno de la función de búsqueda como la dirección del valor a buscar. Lo primero que debemos hacer es realizar una operación nula en la lista vinculada. Si la lista vinculada está vacía, entonces establecemos directamente el devolver el valor a la dirección vacía. Defina nuevamente una variable de puntero p de tipo de estructura para que apunte al primer nodo válido después del nodo principal. La condición de terminación del bucle es que p apunte al nodo principal (porque el nodo principal no almacena datos), si el valor a buscado es igual a los datos del nodo señalado por p El valor almacenado en el campo devuelve la dirección del nodo. Si no se encuentra, se devuelve una dirección vacía.
PCnode Search(PCnode cplist,Elem_type val)
{
assert(cplist != nullptr);
if(IsEmpty(cplist)){
return nullptr;
}
PCnode p = cplist->next;
for(;p != cplist;p = p->next){
if(val == p->data){
return p;
}
}
return nullptr;
}Obtener la función de longitud efectiva (Get_length):
Defina una variable de puntero p de tipo de estructura para que apunte al primer nodo válido después del nodo principal y, a continuación, defina un recuento de valores enteros para contar el número de nodos válidos, defina un bucle, la condición de terminación del bucle no apunta al nodo principal, y haga un bucle cada Add 1 al valor de count una vez ejecutado, y establezca el valor de retorno final en count.
int Get_length(PCnode cplist)
{
assert(cplist != nullptr);
PCnode p = cplist->next;
int count = 0;
for(;p != cplist;p = p->next){
count++;
}
return count;
}Borrar función (Borrar):
Vaciar y destruir en la lista enlazada son similares, por lo que podemos llamar directamente a la función destruir en la función borrar.
bool Clear(PCnode cplist)
{
Destroy(cplist);
return true;
}Función Destroy (Destruir):
Cuando cp no esté vacío, ejecute la función de eliminación de cabecera en un bucle hasta que la lista enlazada quede completamente vacía.
bool Destroy(PCnode cplist)//无限头删
{
while(!IsEmpty(cplist)){
Delete_head(cplist);
}
return true;
}Función de impresión (Mostrar):
Defina la variable de puntero p del tipo de estructura para que apunte al primer nodo válido después del nodo principal, defina un bucle sobre el puntero p, la condición de terminación del bucle no apunte al nodo principal e imprima el campo de datos del nodo apuntado a por p cada vez que se ejecuta el bucle, hasta que se completa el ciclo.
void Show(PCnode cplist)
{
//判定:使用不需要前驱的for循环
assert(cplist != nullptr);
PCnode p = cplist->next;
for(;p != cplist;p = p->next){
printf("%5d",p->data);
}
printf("\n");
}Función de inserción de cabeza (Insert_head):
Solicite un nuevo nodo en el área del montón a través de la función malloc para asignar espacio de memoria para el nuevo nodo, asigne el valor que se insertará al campo de datos del nuevo nodo, luego reemplace el siguiente campo y asigne la dirección del primero nodo válido después del nodo principal original a En el siguiente campo de pnewnode, reemplace la dirección del primer nodo válido almacenado en el nodo principal original con la dirección de pnewnode, como se muestra en la figura:

bool Insert_head(PCnode cplist,Elem_type val)
{
assert(cplist != nullptr);
PCnode pnewnode = (PCnode) malloc(1 * sizeof(CNode));
assert(pnewnode != nullptr);
pnewnode->data = val;
pnewnode->next = cplist->next;
cplist->next = pnewnode;
return true;
}Función de inserción de cola (Insert_tail):
Solicite un nuevo nodo en el área del montón a través de la función malloc para asignar espacio de memoria para el nuevo nodo, asigne el valor que se insertará al campo de datos del nuevo nodo, defina el puntero p del tipo de estructura para que apunte a la cabeza nodo, defina un bucle, y la condición de terminación del bucle es el puntero p El siguiente campo no es igual al nodo principal (es decir, atraviesa el nodo final), y luego reemplaza el siguiente campo Asignamos la dirección de el nodo principal almacenado originalmente en el siguiente campo del nodo final al siguiente campo de pnewnode, y luego asigne la dirección de pnewnode Asigne el valor al siguiente campo del nodo final original, como se muestra en la figura:
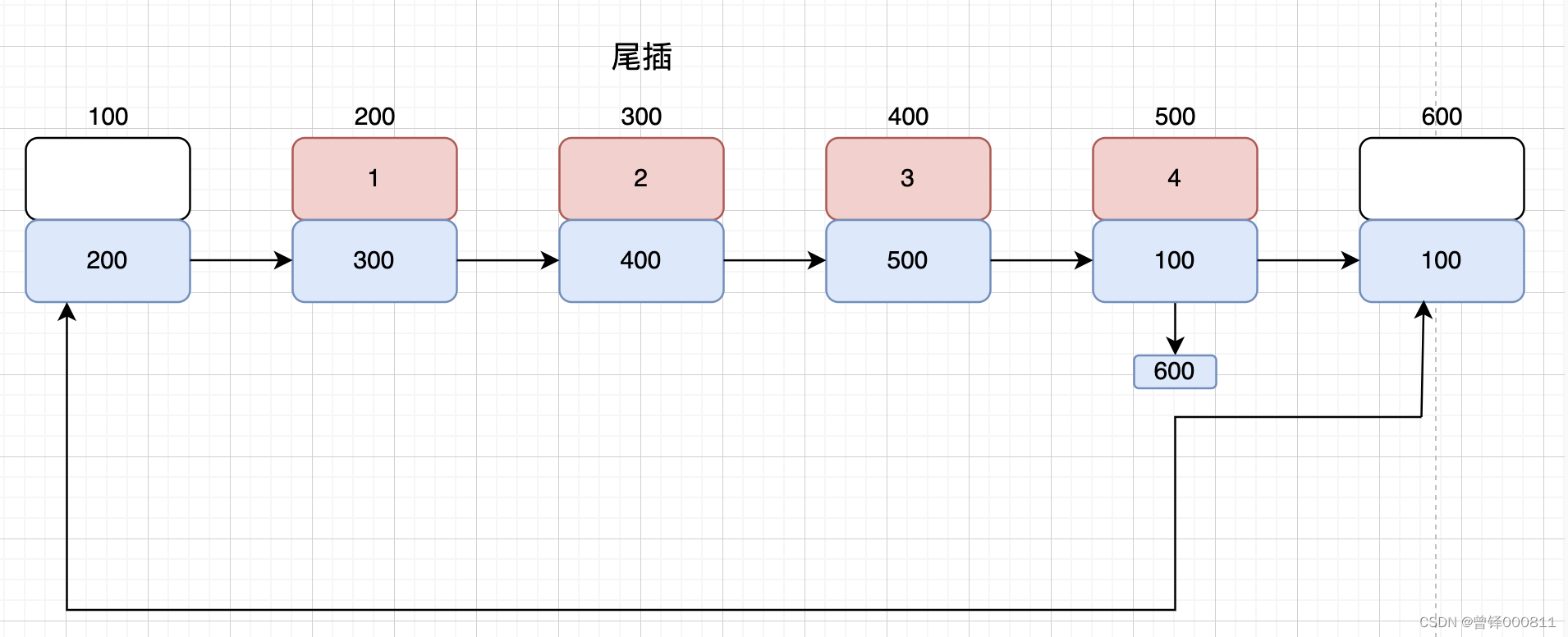
bool Insert_tail(PCnode cplist,Elem_type val)
{
assert(cplist != nullptr);
PCnode pnewnode = (PCnode) malloc(1 * sizeof(CNode));
assert(pnewnode != nullptr);
pnewnode->data = val;
PCnode p = cplist;
for(;p->next != cplist;p = p->next);
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}Insertar función por posición (Insert_pos):
Solicite un nuevo nodo en el área del montón a través de la función malloc para asignar espacio de memoria para el nuevo nodo, asigne el valor que se insertará al campo de datos del nuevo nodo, defina el puntero p del tipo de estructura para que apunte a la cabeza nodo, defina un bucle, y la condición de terminación es i < pos, donde Cuando p apunta al nodo anterior de la posición que se va a insertar, el siguiente campo de p almacena la dirección del nodo que se va a insertar, y luego el siguiente se reemplaza el campo, y la dirección del nodo detrás de la posición que se va a insertar se asigna al siguiente campo de pnewnode, y luego simplemente asigne la dirección de pnewnode al siguiente campo del puntero p que apunta al nodo antes de la posición a ser insertado.
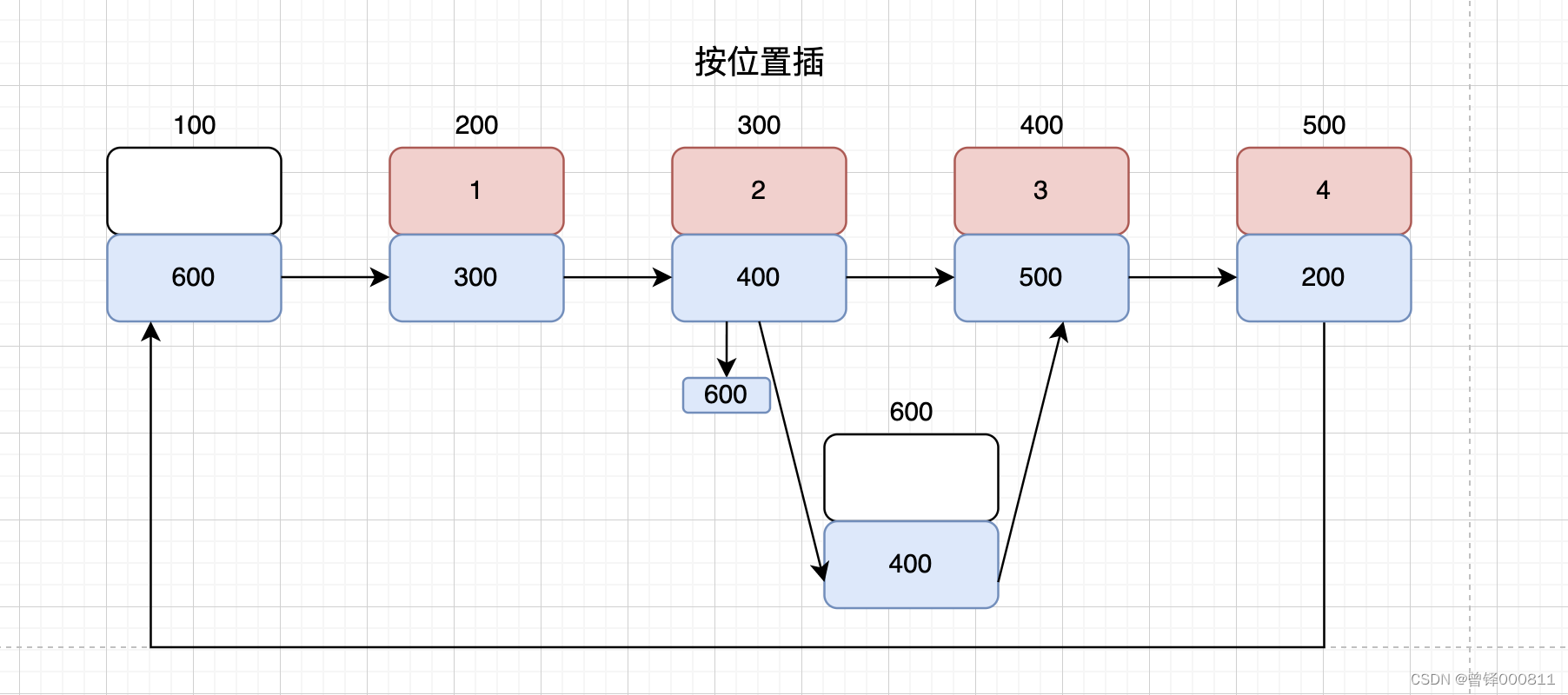
bool Insert_pos(PCnode cplist,int pos,Elem_type val)
{
assert(cplist != nullptr);
PCnode pnewnode = (PCnode) malloc(1 * sizeof(CNode));
assert(pnewnode != nullptr);
pnewnode->data = val;
PCnode p = cplist;
for(int i = 0;i < pos;i++){
p = p->next;
}
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}Función de eliminación de cabeza (Delete_head):
Primero, juzgue la lista enlazada como vacía. Si la lista enlazada está vacía, devolverá falso directamente. Defina una variable de puntero p de tipo de estructura para apuntar al primer nodo válido después del nodo principal (es decir, nuestro nodo que se eliminará ), y reemplace el nodo principal original. Reemplace la dirección del primer nodo válido guardado en , con la dirección del segundo nodo válido, y luego suelte el puntero p, como se muestra en la figura:

bool Delete_head(PCnode cplist)
{
assert(cplist != nullptr);//安全性处理
if(IsEmpty(cplist)){
return false;
}
PCnode p = cplist->next;//找到待删除节点
cplist->next = p->next;//跨越指向
free(p);//释放删除节点
return true;
}Función de eliminación de cola (Delete_tail):
Primero, juzgue la lista enlazada como vacía. Si la lista enlazada está vacía, devolverá falso directamente. Defina una variable de puntero p de tipo de estructura para apuntar al nodo principal, defina un bucle sobre p, y la condición de terminación del bucle es que el siguiente campo de p no es el nodo principal (también es para atravesar el último nodo), y luego defina una variable de puntero q de tipo de estructura para apuntar al nodo principal, defina un bucle sobre q, y la condición de terminación del bucle es que el siguiente campo de q no es p (es decir, atraviesa el nodo al que apunta p Un nodo), copie la dirección del nodo principal almacenada originalmente en el siguiente campo del nodo al que apunta p al siguiente campo del nodo señalado por q, de modo que hemos completado la operación de eliminación de la cola, como se muestra en la figura:
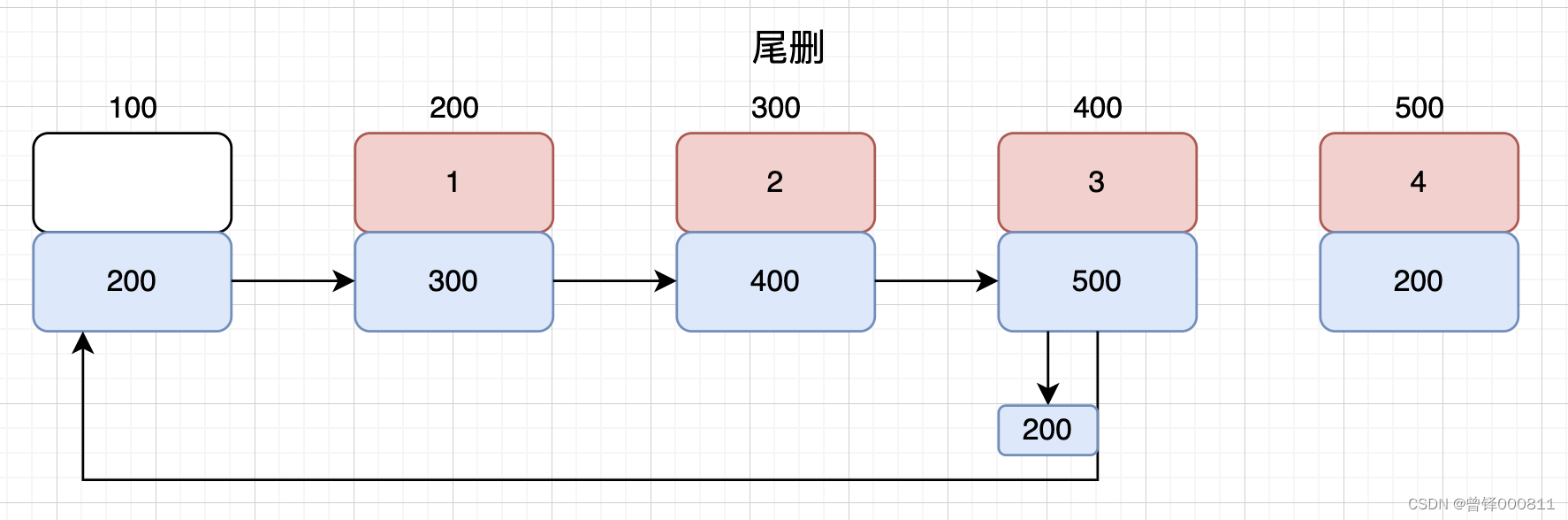
bool Delete_tail(PCnode cplist)
{
assert(cplist != nullptr);
if(IsEmpty(cplist)){
return false;
}
PCnode p = cplist;
for(;p->next != cplist;p = p->next);
PCnode q = cplist;
for(;q->next!=p;q = q->next);
q->next = p->next;
free(p);
return true;
}Eliminar función por posición (Delete_pos):
Primero, juzgue que la lista enlazada está vacía. Si la lista enlazada está vacía, devolverá directamente falso. Defina una variable de puntero q de tipo de estructura para apuntar al nodo principal, defina un bucle y la condición de terminación del bucle es i < pos.. En este momento, lo que apunta q es Eliminar el nodo anterior del nodo, el siguiente campo de q es el nodo a eliminar, y luego definir una variable de puntero p de tipo de estructura para apuntar al siguiente de q, luego el siguiente campo de p es el siguiente nodo del nodo que se eliminará, y luego realizamos una operación de cruce, copiando el siguiente campo de p al siguiente campo de q que originalmente almacenó la dirección del nodo a eliminar y luego suelte el puntero p.

bool Delete_pos(PCnode cplist,int pos)
{
assert(cplist != nullptr);
if(IsEmpty(cplist)){
return false;
}
PCnode q = cplist;
for(int i = 0;i < pos;i++){
q = q->next;
}
PCnode p = q->next;
q->next = p->next;
free(p);
return true;
}Eliminar función por valor (Delete_val):
Primero juzgue la lista enlazada como vacía, si la lista enlazada está vacía, devolverá falso directamente, defina una variable de puntero p de tipo de estructura para almacenar el valor de retorno de la función de búsqueda, si el puntero p está vacío, devolverá falso y luego defina un tipo de estructura. La variable de puntero q apunta al nodo principal, define un bucle y la condición de terminación del bucle es que el siguiente campo de q no sea p (es decir, atraviesa el nodo anterior del nodo de valor que se va a eliminado), y luego realiza una operación de cruce, y el siguiente campo original de q Almacene el siguiente campo en el que la dirección del nodo que se eliminará se reemplaza con p, y luego suelte el puntero p.
bool Delete_val(PCnode cplist,Elem_type val)
{
assert(cplist != nullptr);
if(IsEmpty(cplist)){
return false;
}
PCnode p = Search(cplist,val);
if(p == nullptr){
return false;
}
PCnode q = cplist;
for(;q->next != p;q = q->next);
q->next = p->next;
free(p);
return true;
}prueba:
Pruebe las funciones de inicialización, las funciones de interpolación posicional y las funciones de impresión:
#include<cstdio>
#include<cassert>
#include<cstdlib>
#include "Circular_Linked_List.h"
int main()
{
CNode circle;
Init_clist(&circle);
for(int i = 0;i < 10;i++){
Insert_pos(&circle,i,i + 1);
}
printf("原始数据为:\n");
Show(&circle);
/*
其他测试函数添加位置
*/
return 0;
}resultado de la operación:
Función de complemento de encabezado de prueba:
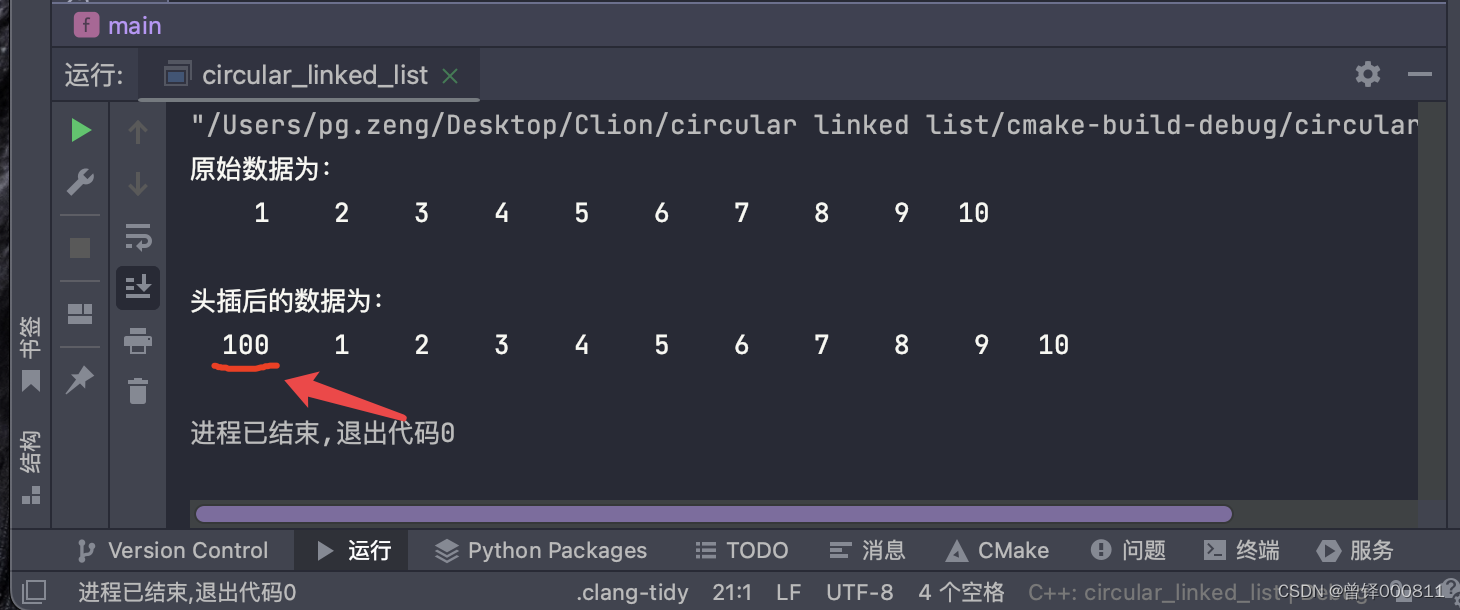
Aquí queremos insertar 100 en el encabezado de la lista enlazada:
Insert_head(&circle,100);
printf("\n头插后的数据为:\n");
Show(&circle);resultado de la operación:
Función de interpolación de cola de prueba:
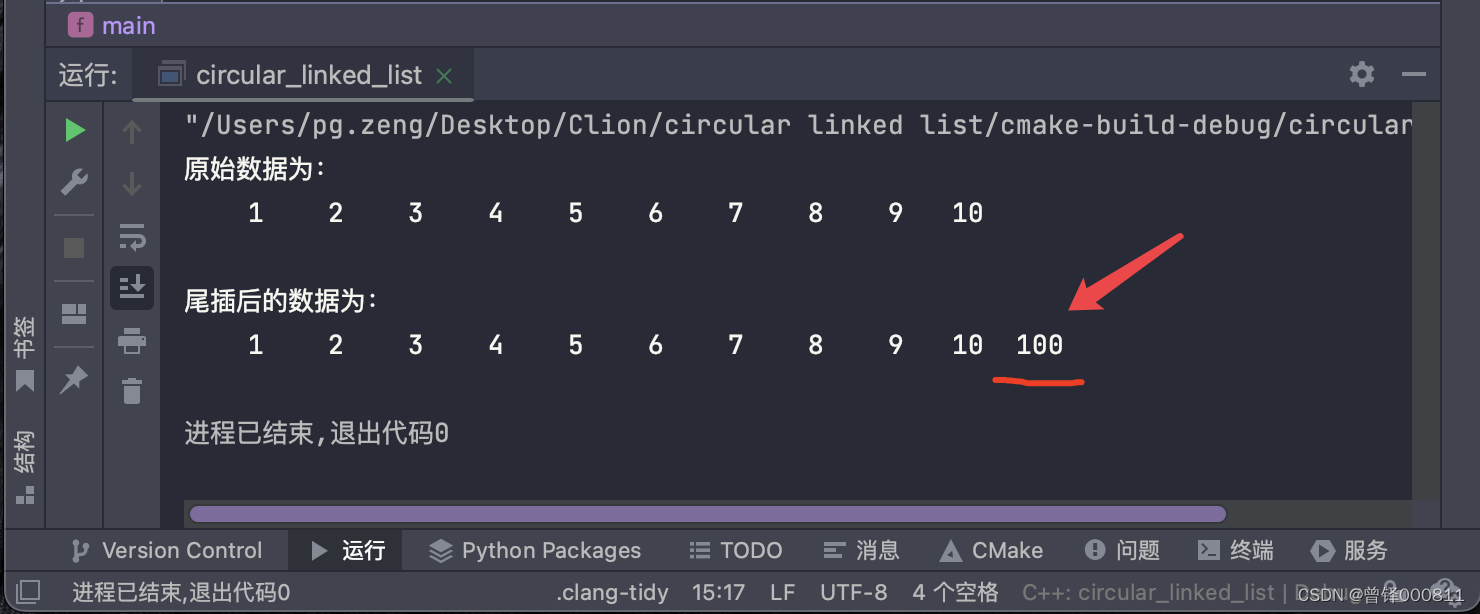
Aquí queremos insertar 100 al final de la lista enlazada:
Insert_tail(&circle,100);
printf("\n头删后的数据为:\n");
Show(&circle);resultado de la operación:
Pruebe la función de interpolación posicional:
Aquí queremos insertar 100 después del segundo nodo válido después del nodo principal:
Insert_pos(&circle,2,100);
printf("\n头删后的数据为:\n");
Show(&circle);resultado de la operación:

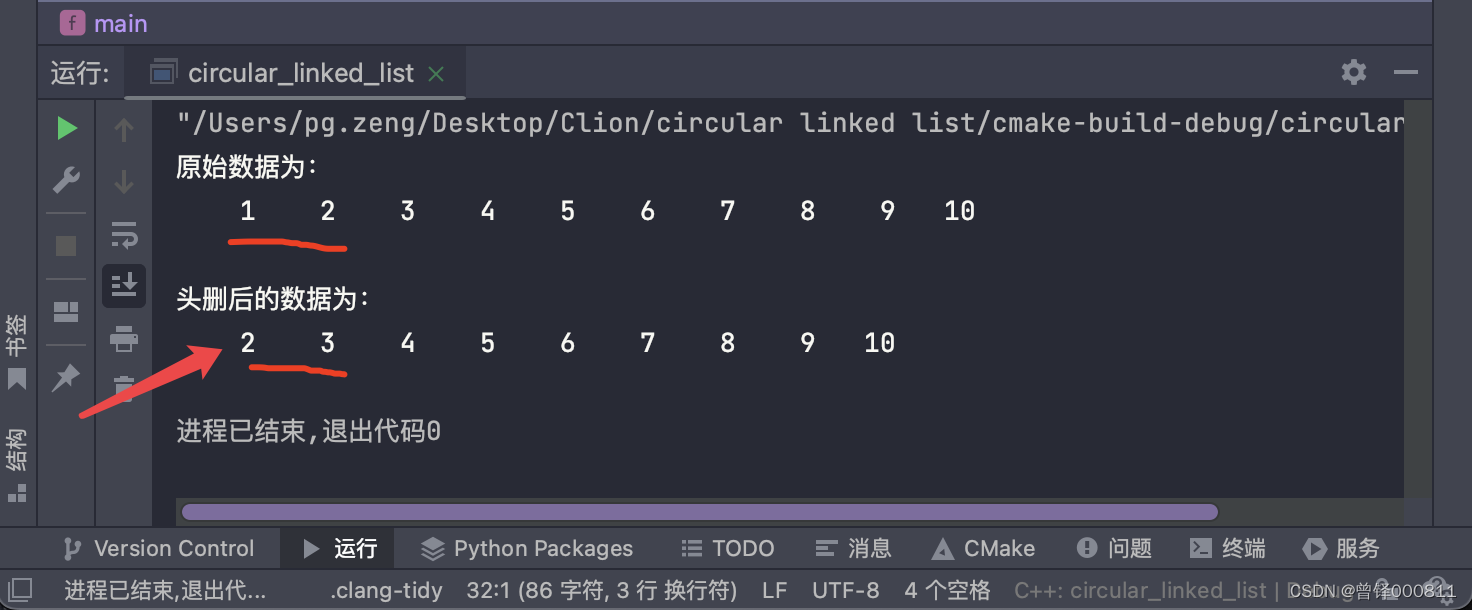
Número de borrados del cabezal de prueba:
Aquí queremos eliminar el primer nodo válido después del nodo principal de la lista enlazada:
Delete_head(&circle);
printf("\n头删后的数据为:\n");
Show(&circle);
return 0;resultado de la operación:
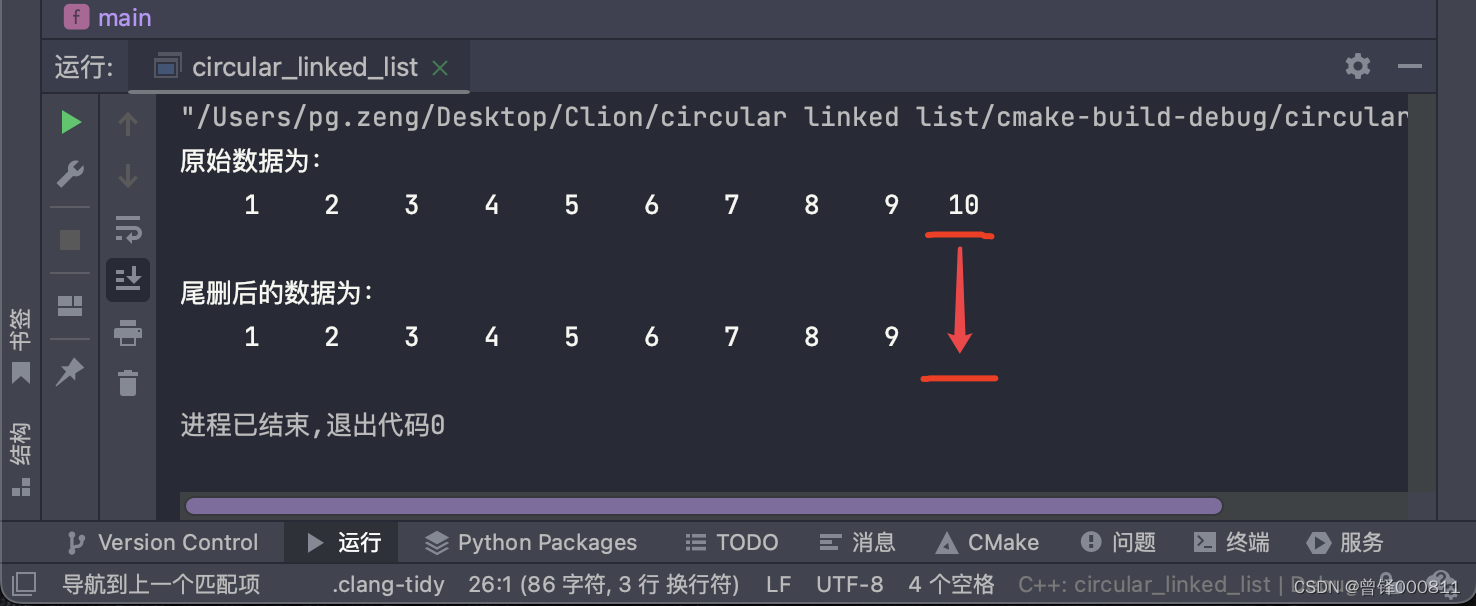
Función de eliminación de cola de prueba:
Aquí queremos eliminar el nodo final de la lista enlazada:
Delete_tail(&circle);
printf("\n尾删后的数据为:\n");
Show(&circle);
return 0;resultado de la operación:
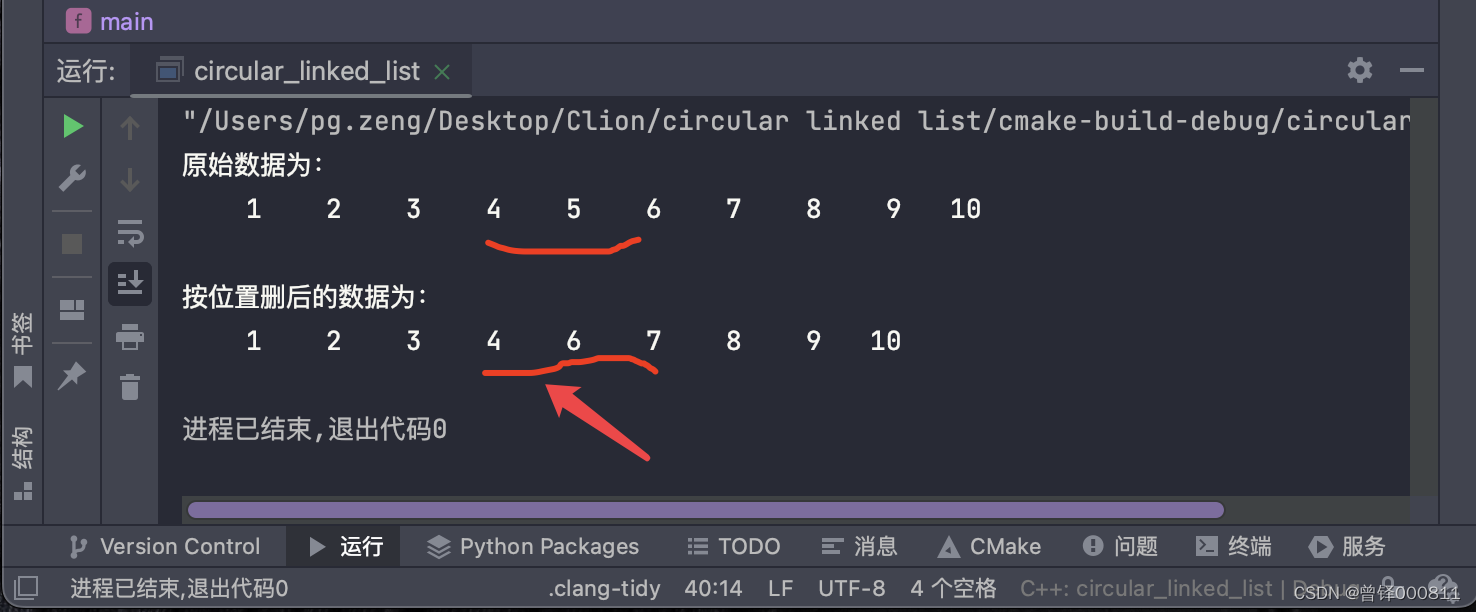
Pruebe la función de eliminación por posición:
Aquí queremos eliminar el nodo después del cuarto nodo válido después del nodo principal en la lista enlazada:
Delete_pos(&circle,4);
printf("\n按位置删后的数据为:\n");
Show(&circle);
return 0;resultado de la operación:
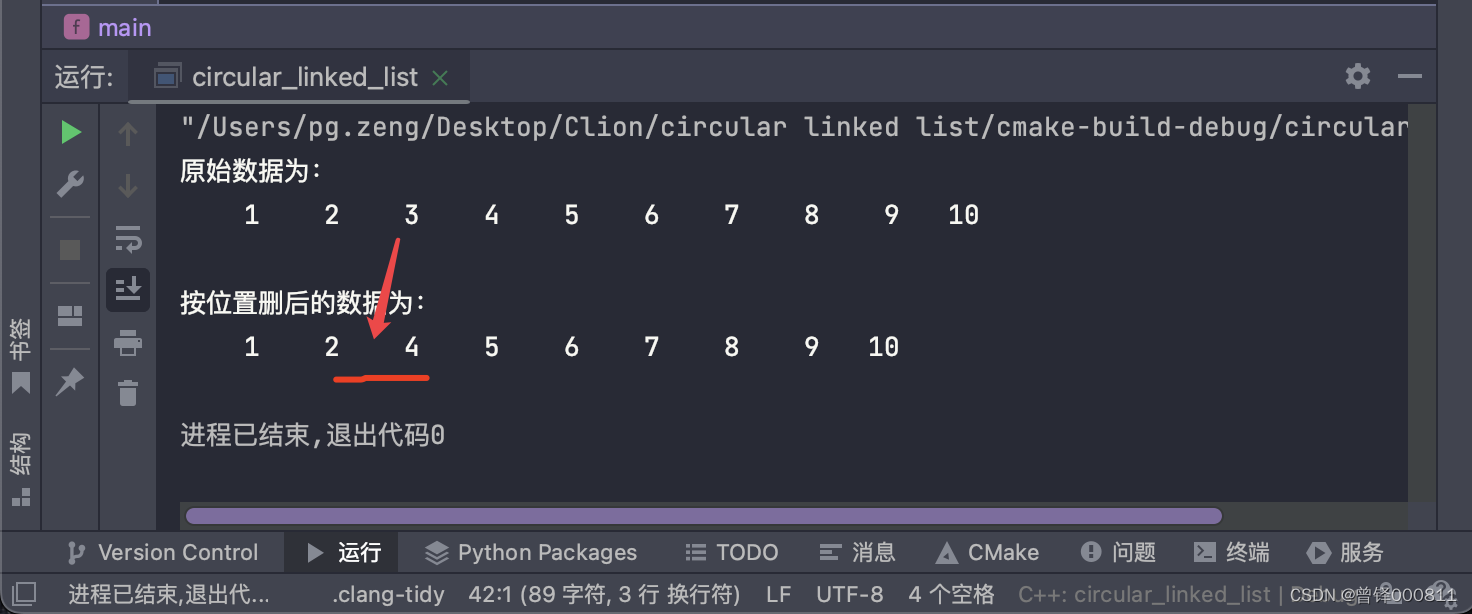
Pruebe la función de eliminación por valor:
Aquí queremos eliminar el valor de 3 en la lista enlazada:
Delete_val(&circle,3);
printf("\n按位置删后的数据为:\n");
Show(&circle);
return 0;resultado de la operación:
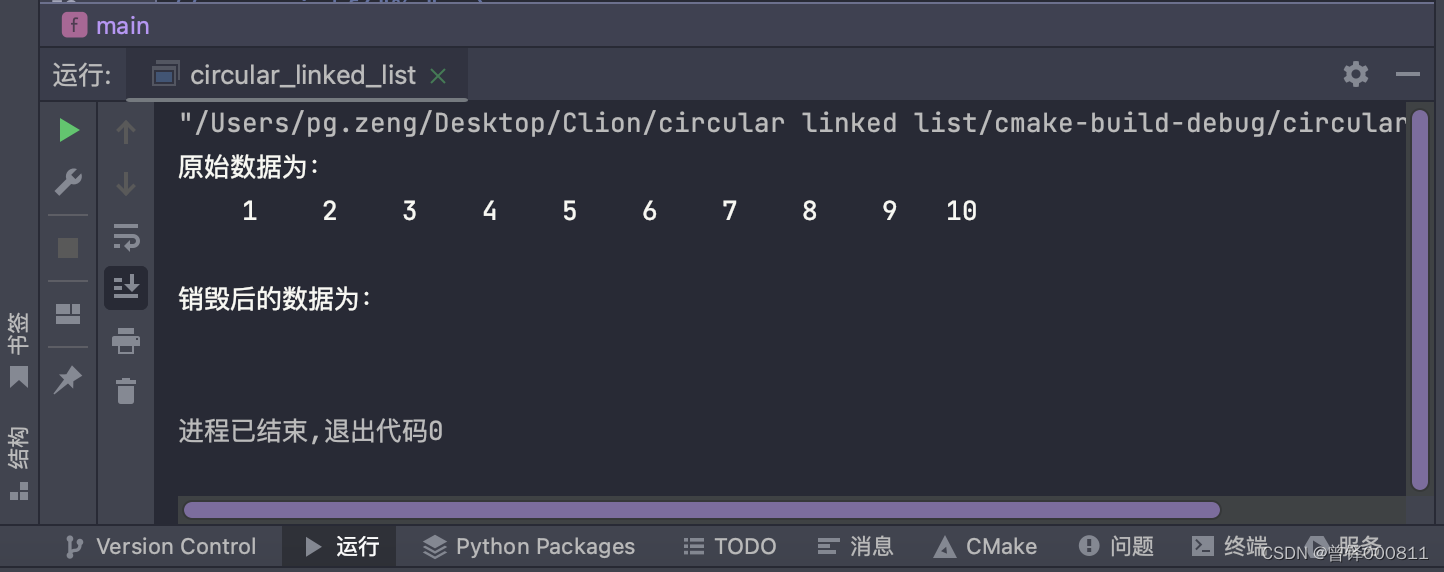
Función de destrucción de prueba:
Destroy(&circle);
printf("\n头删后的数据为:\n");
Show(&circle);resultado de la operación:
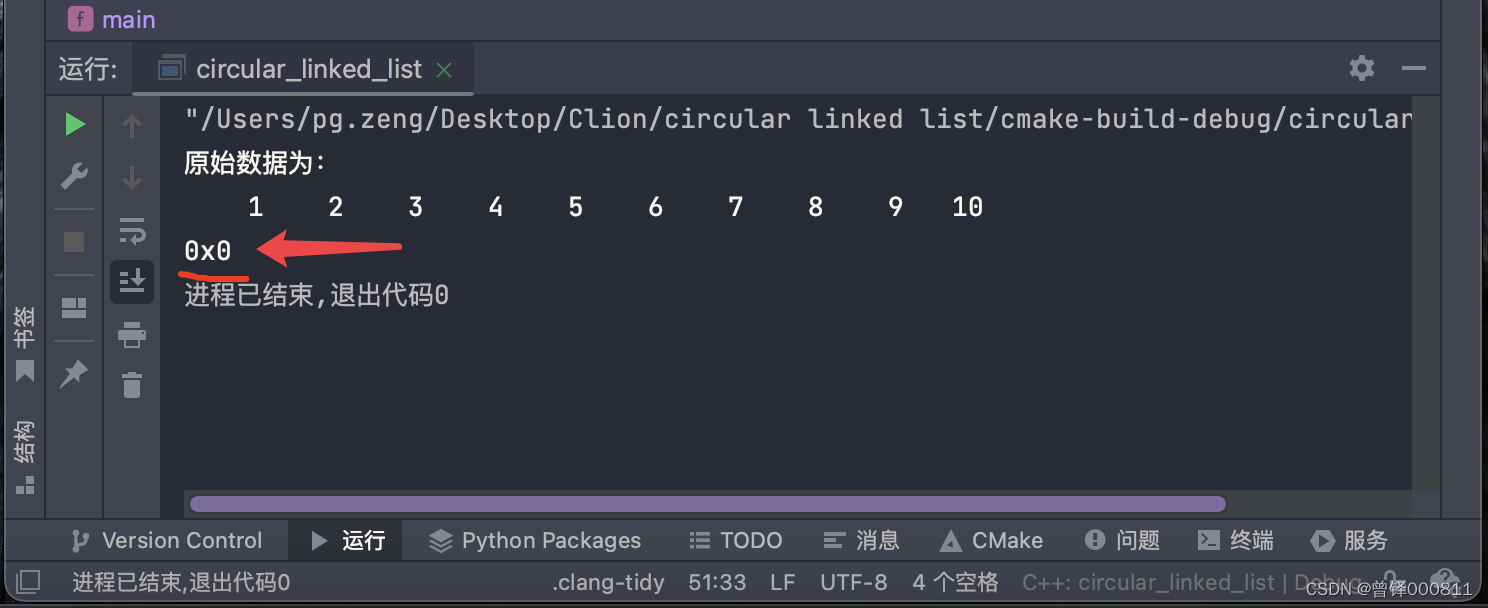
Función de búsqueda de prueba:
PCnode p = Search(&circle,5);
printf("%p",p);
return 0;resultado de la operación:

Si reemplazamos el valor que estamos buscando con un valor que no existe en la lista enlazada, esto devuelve una dirección vacía, que es nullptr:
Resumir:
La lista enlazada circular unidireccional es generalmente muy similar a la lista enlazada simple sin un nodo principal.Antes de escribir el código, debemos clasificar la estructura de la lista enlazada circular unidireccional y aclarar la diferencia entre las dos. De esta forma, es más eficiente a la hora de escribir código.
pensar:
/*面试笔试喜欢问的问题:
* 第一题:单链表怎么进行逆置?
* 第二题:单链表如何获取倒着打印的数据?
* 第三题:如何判断两个单链表是否存在交点?如果存在相交点则找到第一个相交点?
* 第四题:如果判断一个单链表是否存在环?如果存在环,则找到入环点。
* 第五题:给一个随机节点的地址,如何在O(1)时间内删除这个节点?(这个随机节点不能是尾节点)
* 第六题:如何判断一个单链表是否是回文链表
*/7 noviembre 2022 a las 23:00