Tabla de contenido
Conceptos y operaciones básicos:
Método y principio de implementación.
Escenarios de aplicación y precauciones de uso
Análisis de algoritmos y complejidad:
Comparación con otras estructuras de datos:
PD: Si hay algún error u omisión, corríjame.
Conceptos y operaciones básicos:
La lista doblemente enlazada (lista doblemente enlazada) es una estructura de datos común. En comparación con la lista individualmente enlazada, agrega un puntero al nodo predecesor, por lo que cada nodo tiene un puntero al nodo predecesor además del puntero al nodo sucesor. . De esta manera, la lista vinculada se puede recorrer bidireccionalmente, de modo que la lista vinculada se pueda operar de manera más flexible.
Al utilizar una lista doblemente enlazada, podemos implementar operaciones como inserción, eliminación y búsqueda de manera más conveniente. En comparación con la lista enlazada individualmente, la desventaja de la lista doblemente enlazada es que se requiere espacio adicional para almacenar el puntero del nodo predecesor y se requiere más código para mantener la exactitud del puntero.
Los nodos de la lista doblemente enlazada se describen en lenguaje C# como:
namespace DataStructLibrary
{
/// <summary>
/// 双链表节点
/// </summary>
public class DbNode<T>
{
private T data;//数据域
private DbNode<T> prev;//前驱引用域
private DbNode<T> next;//后继引用域
/// <summary>
/// 构造器
/// </summary>
/// <param name="val">数据域</param>
/// <param name="p">后继引用域</param>
public DbNode(T val,DbNode<T> p)
{
data = val;
next = p;
}
/// <summary>
/// 构造器
/// </summary>
/// <param name="p">后继引用域</param>
public DbNode(DbNode<T> p)
{
next = p;
}
/// <summary>
/// 构造器
/// </summary>
/// <param name="val">数据域</param>
public DbNode(T val)
{
data = val;
next = null;
}
/// <summary>
/// 构造器
/// </summary>
public DbNode()
{
data = default(T);
next = null;
}
/// <summary>
/// 数据域属性
/// </summary>
public T Data
{
get { return data; }
set { data = value; }
}
/// <summary>
/// 前驱引用域属性
/// </summary>
public DbNode<T> Prev
{
get { return prev; }
set { prev = value; }
}
/// <summary>
/// 后继引用域属性
/// </summary>
public DbNode<T> Next
{
get { return next; }
set { next = value; }
}
}
}
En la lista doblemente enlazada, el algoritmo de algunas operaciones (como encontrar la longitud, buscar elementos, posicionamiento, etc.) solo involucra el puntero sucesor, y el algoritmo de la lista enlazada es el mismo que el de la lista enlazada individualmente. Pero para las operaciones de inserción y eliminación directa, la lista enlazada bidireccional necesita modificar los dos punteros del borde posterior al mismo tiempo, lo cual es más complicado que la lista enlazada única.
Las siguientes son operaciones de uso común en listas de doble enlace:
-
Inicializar la lista doblemente enlazada: Inicializar la lista doblemente enlazada es crear una lista doblemente enlazada vacía, el proceso de creación se muestra en la siguiente tabla.
| paso | funcionar |
|---|---|
| 1 | Declarar una variable de inicio de tipo nodo |
| 2 | Asigne el valor de la variable de inicio a nulo en el constructor de la lista doblemente enlazada |
2. Operación de inserción: inserte un nuevo nodo en la posición especificada (como el principio, el final o el medio) de la lista vinculada.
2.1 Insertar un nuevo nodo al comienzo de la lista enlazada individualmente
2.2 Insertar un nodo entre dos nodos en la lista vinculada
2.3 Insertar un nuevo nodo al final de la lista vinculada
El proceso de implementación específico es el siguiente.
| paso | funcionar |
|---|---|
| 1 | Asigne memoria para el nuevo nodo y asigne valores a los campos de datos del nuevo nodo
|
| 2 | Si la lista está vacía, se realizan los siguientes pasos para insertar un nodo en la lista: a) Haga que el siguiente campo del nuevo nodo apunte a nulo; b) Hacer que el campo anterior del nuevo nodo apunte a nulo;
|
| 3 | Para insertar un nodo al principio de la lista, realice los siguientes pasos: a) Haga que el siguiente campo del nuevo nodo apunte al primer nodo de la lista; b) Haga que el campo anterior de inicio especifique el nuevo nodo, c) Haga que el campo anterior del nuevo nodo apunte a nulo; d) Deje que comience a especificar el nuevo nodo. |
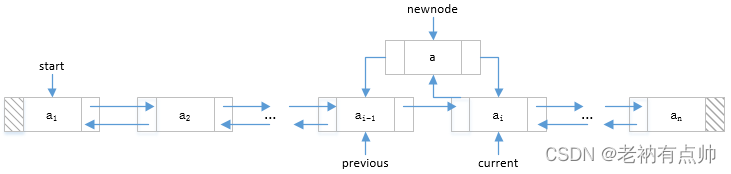
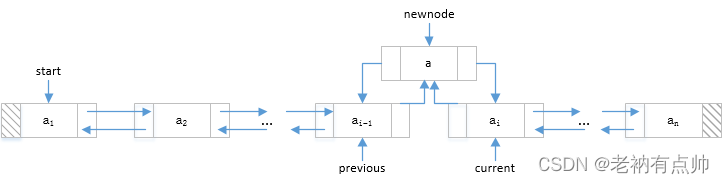
| 4 | Para insertar un nuevo nodo entre dos nodos existentes, realice los siguientes pasos: a) Haga que el siguiente del nuevo nodo apunte al nodo actual
b) Hacer que el anterior del nuevo nodo apunte al nodo anterior
c) Hacer que el anterior del nodo actual apunte al nuevo nodo
d) Hacer que el siguiente del nodo anterior apunte al nuevo nodo
|
| 5 | Inserte el nuevo nodo al final de la lista, al mover el puntero actual al último nodo realice los siguientes pasos: a) Hacer que el siguiente del nodo actual especifique un nuevo nodo; b) Hacer que el anterior del nuevo nodo apunte al nodo actual; c) Hacer nulo el siguiente del nuevo nodo. |



3. Eliminar operación
El algoritmo específico para eliminar un nodo en una lista doblemente enlazada es el siguiente:
| paso | funcionar |
|---|---|
| 1 | Busque el nodo que se eliminará y márquelo como el nodo actual |
| 2 | Si el nodo eliminado es el primer nodo, establezca directamente el punto de inicio en el siguiente nodo del nodo actual |
| 3 | Si el nodo que se va a eliminar es un nodo entre dos nodos, realice los siguientes pasos: a) Hacer que el siguiente campo del nodo anterior apunte al siguiente nodo del nodo actual b) Hacer que el campo anterior del nodo después del nodo actual apunte al nodo anterior
c) Liberar la memoria del nodo marcado como nodo actual
|
| 4 | Si el nodo eliminado es el último nodo, simplemente realice los pasos a) yc) donde el nodo eliminado es un nodo entre dos nodos |


4. Recorra todos los nodos de la lista doblemente enlazada.
Una lista doblemente enlazada le permite recorrer la lista tanto en dirección hacia adelante como hacia atrás. El algoritmo para recorrer una lista hacia adelante es:
El algoritmo para recorrer una lista doblemente enlazada a la inversa es: .
Una lista doblemente enlazada le permite recorrer la lista tanto en dirección hacia adelante como hacia atrás. El algoritmo para recorrer una lista hacia adelante es:
Otras operaciones relacionadas con la tabla lineal, como calcular la longitud de la tabla y juzgar que está vacía, son relativamente simples de implementar en la tabla secuencial. Consulte el siguiente código C# para la lista de doble enlace:
/// <summary>
/// 双链表数据结构实现接口具体步骤
/// </summary>
public class DbLinkList<T>:ILinarList<T>
{
private DbNode<T> start;//双向链表的头引用
private int length;//双向链表的长度
/// <summary>
/// 初始化双向链表
/// </summary>
public DbLinkList()
{
start = null;
}
/// <summary>
/// 在双链表的末尾追加数据元素 data
/// </summary>
/// <param name="data">数据元素</param>
public void InsertNode(T data)
{
DbNode<T> newnode = new DbNode<T>(data);
if (IsEmpty())
{
start = newnode;
length++;
return;
}
DbNode<T> current = start;
while (current.Next!= null)
{
current = current.Next;
}
current.Next = newnode;
newnode.Prev = current;
newnode.Next = null;
length++;
}
/// <summary>
/// 在双链表的第i个数据元素的位置前插入一个数据元素data
/// </summary>
/// <param name="data">数据元素</param>
/// <param name="i">第i个数据元素的位置</param>
public void InsertNode(T data, int i)
{
DbNode<T> current;
DbNode<T> previous;
if (i < 1)
{
Console.WriteLine("Position is error");
return;
}
DbNode<T> newNode = new DbNode<T>(data);
//在空链表或第一个元素前插入第一个元素
if (i == 1)
{
newNode.Next = start;
start = newNode;
length++;
return;
}
//在双链表的两个元素间插入一个元素
current = start;
previous = null;
int j = 1;
while(current != null && j < i)
{
previous = current;
current = current.Next;
j++;
}
if (j == i)
{
newNode.Next = current;
newNode.Prev = previous;
if(current!= null)
{
current.Prev = newNode;
previous.Next = newNode;
}
length++;
}
}
/// <summary>
/// 删除双链表的第i个数据元素
/// </summary>
/// <param name="i"></param>
public void DeleteNode(int i)
{
if(IsEmpty() || i < 1)
{
Console.WriteLine("Link is empty or Position is error!");
}
DbNode<T> current = start;
if(i==1)
{
start = current.Next;
length--;
return;
}
DbNode<T> previous = null;
int j = 1;
while(current.Next != null && j<i)
{
previous = current;
current = current.Next;
j++;
}
if (j == i)
{
previous.Next = current.Next;
if(current.Next!= null)
{
current.Next.Prev = previous;
}
previous = null;
current = null;
length--;
}
else
{
Console.WriteLine("The ith node is not exist!");
}
}
/// <summary>
/// 获得双链表的第i个数据元素
/// </summary>
/// <param name="i"></param>
/// <returns></returns>
public T SearchNode(int i)
{
if (IsEmpty())
{
Console.WriteLine("List is empty!");
return default(T);
}
DbNode<T> current = start;
int j = 1;
while(current.Next != null && j<i)
{
current = current.Next;
j++;
}
if (j == i)
{
return current.Data;
}
else
{
Console.WriteLine("The ith node is not exist!");
return default(T);
}
}
/// <summary>
/// 在双链表中查找值为data的数据元素
/// </summary>
/// <param name="data"></param>
/// <returns></returns>
public T SearchNode(T data)
{
if (IsEmpty())
{
Console.WriteLine("List is Empty");
return default(T);
}
DbNode<T> current = start;
int i = 1;
while (current != null && !current.Data.Equals(data))
{
current = current.Next;
i++;
}
if(current != null)
{
return current.Data;
}
return default(T);
}
/// <summary>
/// 获取双链表的长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return length;
}
/// <summary>
/// 清空链表
/// </summary>
public void Clear()
{
start = null;
}
/// <summary>
/// 判断链表是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if (start == null)
{
return true;
}
return false;
}
/// <summary>
/// 该函数将链表头节点反转后,重新作为链表的头节点。算法使用迭代方式实现,遍历链表并改变指针指向
/// 例如链表头节点start:由原来的
/// data:a,
/// prev:null,
/// next:[
/// data:b,
/// prev:a,
/// next:[
/// data:c,
/// prev:b,
/// next:null
/// ]
/// ]
///翻转后的结果为:
/// data:c,
/// prev:null,
/// next:[
/// data:b,
/// prev:c,
/// next:[
/// data:a,
/// prev:b,
/// next:null
/// ]
/// ]
/// </summary>
public void ReverseList()
{
if (length == 1 || IsEmpty())
{
return;
}
//定义 previous next 两个指针
DbNode<T> previous = null;
DbNode<T> next = null;
DbNode<T> current = this.start;
//循环操作
while (current != null)
{
//定义next为Head后面的数,定义previous为Head前面的数
next = current.Next;
current.Prev = next;
current.Next = previous;//这一部分可以理解为previous是Head前面的那个数。
//然后再把previous和Head都提前一位
previous = current;
current = next;
}
this.start = previous;
//循环结束后,返回新的表头,即原来表头的最后一个数。
return;
}
}Método y principio de implementación.
Al implementar una lista doblemente enlazada, es necesario prestar atención a cuestiones como la corrección del puntero y la gestión de la memoria. Para mejorar el rendimiento y la escalabilidad, se pueden utilizar tecnologías como nodos centinela y listas circulares enlazadas para optimizar la lista doblemente enlazada.
-
Una lista doblemente enlazada es una estructura de datos común. En comparación con una lista simplemente enlazada, agrega un puntero al nodo predecesor, por lo que cada nodo tiene un puntero al nodo predecesor además de un puntero al nodo sucesor. A continuación se presenta el método de implementación y el principio de la lista doblemente enlazada, que incluye principalmente los siguientes aspectos:
-
Definición de nodo: cada nodo en la lista doblemente enlazada debe contener tres elementos básicos, uno es una variable para almacenar datos y los otros dos son punteros a los nodos predecesor y sucesor.
-
Nodo principal y nodo de cola: el nodo principal y el nodo de cola son dos nodos especiales en la lista doblemente enlazada: el nodo principal no tiene un nodo predecesor y el nodo de cola no tiene un nodo sucesor.
-
添加操作:向双向链表中添加新节点,需要创建一个新节点,并将其插入到链表的合适位置上,同时设置新节点的前驱和后继指针。
-
删除操作:从双向链表中删除节点,需要找到待删除节点的前驱节点和后继节点,然后修改它们的前驱和后继指针,使其不再指向待删除节点。
-
查找操作:查找双向链表中的某个节点,可以从链表的头节点或尾节点开始遍历整个链表,直到找到目标节点或遍历完整个链表。
-
遍历操作:遍历双向链表,可以从链表的头节点或尾节点开始,依次输出每个节点的数据。
-
长度统计:统计双向链表中节点的数量,可以通过遍历链表并计数的方式来实现。
了解单链表的实现方法和原理对于理解链表性能和优化有很大帮助。同时,需要注意在具体实现时要根据实际情况进行合理的设计和优化,以提高代码的效率和可维护性。
应用场景和使用注意事项
单链表是一种常见的数据结构,常用于以下应用场景:
-
实现栈和队列:单链表可以用来实现栈和队列。在栈中,元素只能从栈顶进出;在队列中,元素只能从队尾进,队首出。利用单链表的头插和尾插操作,可以很方便地实现这两种数据结构。
-
内存分配:在计算机内存管理中,单链表常被用作动态内存分配的数据结构。通过链表节点之间的指针连接,可以动态地申请和释放内存块。
-
音频和视频播放列表:单链表可以用来实现音频和视频播放列表。每个节点表示一个音频或视频文件,并保存下一个文件的位置。通过遍历链表,可以依次播放整个列表中的音频和视频。
-
寻找环形结构:单链表也可以用来处理关于环形结构的问题,例如判断一个链表是否有环、找到环的入口等。
-
缓存淘汰策略:在缓存系统中,当缓存空间已满时,需要淘汰一些数据来腾出空间。单链表可以用来维护缓存中的数据项,同时记录它们的使用情况。当需要淘汰数据时,可以选择最近最少使用的数据项进行淘汰,即删除单链表尾部的节点。
在使用单链表时需要注意以下几点:
-
空指针问题:在链表操作中容易出现空指针问题,例如访问空链表或者一个不存在的节点等。为了避免这些问题,需要对输入参数进行判空处理。
-
内存管理问题:在插入和删除节点时需要分配或释放内存空间,如果管理不当容易出现内存泄漏或者重复释放等问题。可以使用垃圾回收机制或手动管理内存空间来解决这些问题。
-
边界条件问题:在进行链表操作时需要处理一些边界条件和异常情况,例如链表为空、插入位置超出范围等情况,以确保链表的正常运行。
-
性能问题:在处理大规模数据时,单链表会存在一些性能问题,例如随机访问速度较慢、空间开销较大等。因此在实际应用中需要根据实际情况选择合适的数据结构。
算法和复杂度分析:
常见的双向链表算法包括插入、删除和查找操作,下面对它们进行简要分析:
-
插入操作:在双向链表中插入一个节点时,需要找到待插入位置的前驱节点和后继节点,并修改它们的指针。时间复杂度为O(n)。
-
删除操作:在双向链表中删除一个节点时,也需要找到待删除节点的前驱节点和后继节点,并修改它们的指针。时间复杂度为O(n)。
-
查找操作:在双向链表中查找一个节点时,可以从头节点或尾节点开始遍历整个链表,直到找到目标节点或遍历完整个链表。时间复杂度为O(n)。
-
排序算法:双向链表可以使用插入排序、冒泡排序等算法进行排序,排序的时间复杂度取决于具体算法实现。
另外,在实际应用中,可以通过使用哨兵节点、循环链表等技术来优化双向链表的性能和扩展性。
总之,双向链表是一种常见的数据结构,具有良好的灵活性和扩展性。在实际使用中,需要根据具体情况选择合适的算法,并注意内存管理和指针操作。
与其他数据结构的比较:
双向链表是一种常见的数据结构,与其他数据结构相比较有以下优点和缺点:
-
与数组比较:双向链表可以动态增加和删除节点,不需要预先分配固定大小的空间,因此具有更好的灵活性。但是,双向链表的访问时间复杂度为O(n),而数组的访问时间复杂度为O(1),因此在随机访问和遍历操作比较频繁的情况下,数组可能更加高效。
-
与队列比较:双向链表和队列都可以实现FIFO(先进先出)的数据结构,但是双向链表相比队列更加灵活,可以支持在任意位置插入和删除节点,而队列只能在头部插入和尾部删除元素。
-
与栈比较:双向链表和栈都可以实现FILO(先进后出)的数据结构,但是双向链表相比栈更加灵活,可以支持在任意位置插入和删除节点,而栈只能在栈顶插入和删除元素。
-
与哈希表比较:双向链表和哈希表都是常用的数据结构,但是它们的应用场景不同。哈希表适用于快速查找和插入键值对的场景,而双向链表适用于需要频繁插入和删除元素的场景。
总之,双向链表具有一些特点,如动态性、灵活性等优点,但是在访问效率等方面可能不如其他数据结构。在实际应用中,需要根据具体情况选择合适的数据结构,并进行合理的权衡和折衷。